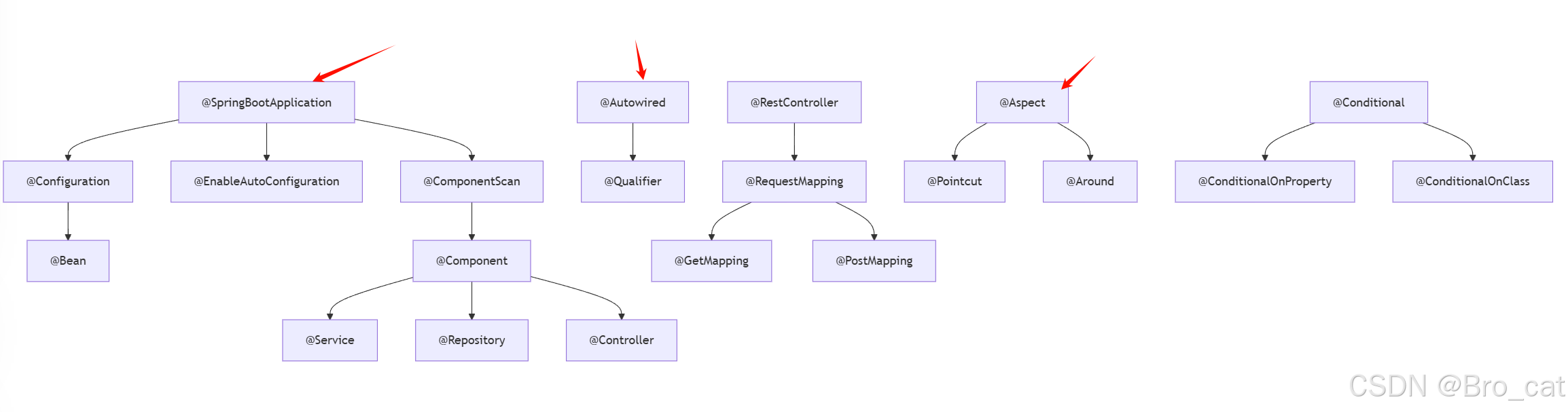
AI大模型(二)基于Deepseek搭建本地可视化交互UI
DeepSeek开源大模型在榜单上以黑马之姿横扫多项评测,其社区热度指数暴涨、一跃成为近期内影响力最高的话题,这个来自中国团队的模型向世界证明:让每个普通人都能拥有媲美GPT-4o的智能体,不再是硅谷巨头的专利。随着DeepSeek的爆火和出圈、以及社区的完善和上手门槛的降低,AI大模型与普通人的距离也越来越近,对AI大模型的使用在未来很可能会成为一项主流的工作技能。基于此,本系列文章将以DeepSeek为例,从本地大模型部署、可视化服务UI、本地知识库搭建、大模型部署调优、破除大模型限制以及角色定制、酒馆使用等方面进行保姆级教学(前两篇免费公开,后续文章请移步付费专栏或知识星球观看),让你轻松玩转大模型,享受大模型带来的便利与乐趣。

在本文开始之前,我们先简单回顾下上篇文章的内容,在上篇文章中我们详细介绍了基于DeepSeek的本地大模型部署教程,在文章结尾处我们已经能够在本地命令行中实现与大模型的对话服务。但是我们发现这种原始的交互方式非常不友好,并且功能和拓展都比较单一,难以满足我们的需求。因此本文将在此基础上,通过多种方式搭建基于Deepseek的本地可视化交互UI,并实现功能拓展。大家可以在下面Open WebUI、ChatBox和Page Assist插件三种方式中选择一种进行实现即可。
一. Open WebUI
Open WebUI 官网: https://docs.openwebui.com/
Open WebUI GitHub: https://docs.openwebui.com/
Open WebUI(前身为Ollama WebUI)是一个开源、可扩展、功能丰富且用户友好的 AI 大模型托管平台,它提供了丰富、易用的用户界面,并支持各种 LLM 提供商(如 Ollama)和与 OpenAI 兼容的 API,还内置 RAG 推理引擎等丰富拓展功能,使其成为强大的 AI 部署解决方案之一,尤其是与Ollama具有较好的兼容性。
1. 环境准备
Open WebUI的部署过程比较复杂,其主要有Docker和Python两种搭建方式,鉴于网上对于Docker搭建方式的教程比较多,因此本文将以Pyhton搭建方式为主进行讲解。在安装Open WebUI之前,我们首先需要在本地安装好Python 3.11版本环境(建议使用uv或conda管理),对于Python环境的安装这里就不再展开,网上相关教程很多且安装也较为简单,大家可以自行了解。需要注意的是: Python 3.12 似乎可以运行,但尚未经过全面测试;Python 3.13 完全未经测试(使用时风险自负)。

2. 安装Open WebUI
在终端中执行以下命令,由于需要下载安装大量依赖组件和模型(语音模型、向量嵌入模型、图像识别模型等),这个过程可能会比较久,请耐心等待;注意如果进度条长时间卡着不动,尝试多按几下回车试试:
pip install open-webui

3. 启动Open WebUI
等待安装完成后,接着通过以下命令启动Open WebUI服务,命令行输出Open WebUI符号即为启动成功:
open-webui serve

4. 访问Open WebUI
服务启动完成后,在浏览器输入地址并访问http://localhost:8080,会看到如下界面(注意后台Python运行窗口不要关掉,否则Open WebUI服务会停止),然后点击“开始使用”后需要创建账号才可使用,这里账号仅会存储在本地管理:


5. 使用Open WebUI
创建账号并登陆完成后,后有一个短暂的页面空白期,Open WebUI会自动连接本地Ollama端口(请确保Ollama服务已开启),连接完成后会出现完整的对话窗口和本地模型列表:

(1)基本对话服务

(2)高级系统设置
- 提示词与模型参数

- 修改外部链接

- 开启联网搜索

二. Chatbox AI
Chatbox AI 官网: https://chatboxai.app/zh
Chatbox AI GitHub: https://github.com/Bin-Huang/chatbox
类似于Open WebUI,Chatbox AI同样也是开源、可拓展的适用于AI大模型(GPT、Claude、Gemini、Ollama…)的用户友好型桌面客户端应用程序,支持本地模型托管和众多先进AI模型的API接入,可在 Windows、MacOS、Android、iOS、Linux 甚至网页版上直接使用,相比Open WebUI来说,Chatbox AI的使用更加简单、无需额外准备任何环境。

1. 配置Ollama服务
点击“启动网页版”后会进入Chatbox AI的主界面,这里会让你选择大模型提供商(包括Chatbox API、OpenAI API、Ollama API等),我们需要选择Ollama API来连接本地部署的Ollama服务,但是此时浏览器是无法直接访问本地部署的Ollama API的(涉及跨域问题),因此我们需要在之前配置的基础上,再添加对跨域支持的系统环境变量OLLAMA_ORIGINS = *:

环境变量添加完成后同样需要重启电脑或Ollama服务才可生效,然后我们重新进入Chatbox AI的设置中,可以发现已可以正确检测到Ollama API和本地模型,选择模型并保存即可:

2. 使用Chatbox AI
配置Ollama服务完成后,跟Open WebUI的使用类似,我们可以直接在对话页面与本地大模型进行交互,并支持对系统提示词或大模型参数进行调整,其他的区别可能就是一些功能丰富性上的差异,大家可以自行探索。注意这里如果是英文,可以到设置中更改为简体中文显示:


三. Page Assist
Page Assist 插件: https://chromewebstore.google.com/detail/page-assist
Page Assist Github: https://github.com/n4ze3m/page-assist
除了上述的Open WebUI和Chatbox AI之外,我们这里再介绍一个更加轻量级的可视化工具Page Assist,它是一个浏览器插件形式的开源大模型用户交互与管理应用,该插件可兼容的浏览器类型如下:

我们直接在浏览器商店中下载并安装Page Assist 插件后,点击插件即可进入Page Assist主界面,如果展示Ollama is running即表示Ollama服务已连接成功(可在右上角设置中修改为简体中文),注意在左上角还需要选择模型来进行对话 :

除此之外,要使用Page Assist还需要在设置>RAG页面里选择一个文本嵌入模型,这里可以使用专业的嵌入模型(需在Ollama下载)或者直接使用deepseek-r1:7b作为嵌入模型,不过建议使用更专业的嵌入模型比如nomic-embed-text,在RAG中效果会更好;并且Page Assist也支持联网搜索、上传文档/图片等操作:















![[吾爱出品]CursorWorkshop V6.33 专业鼠标光标制作工具-简体中文汉化绿色版](https://i-blog.csdnimg.cn/direct/346117dfcd3a47d0871280fb9a1d7641.jpeg)



