文章目录
- Kafka概念
- 消息中间件对比
- 消息中间件对比-选择建议
- Kafka常用名词介绍
- Kafka入门
- 1. Kafka安装配置
- 2.Kafka生产者与消费者关系
- 3.Kafka依赖
- 4.生产者发消息
- 5.消费者接受消息
- 6.Kafka高可用性设计
- 6.1集群
- Kafka备份机制(Reolication)
- 7.kafka生产者详解
- 7.1 发送类型
- 7.2参数详解
- 8.kafka消费者详解
- 8.1消费者组
- 8.1消息有序性
- 7.3 提交和偏移量
Kafka概念
- Kafka 是一种高性能、可扩展的分布式流处理平台,用于处理实时数据流。它最初由 LinkedIn 公司开发,现已成为 Apache 软件基金会的顶级项目。
以下是 Kafka 的一些重要概念:
- Topic(主题):Kafka 使用主题来组织和分类消息。每个主题都是一个具有特定名称的消息流。
- Producer(生产者):生产者负责将消息发布到 Kafka 集群的指定主题中。它可以是任何发送消息的应用程序。
- Consumer(消费者):消费者订阅一个或多个主题,并从 Kafka 集群中读取消息流。消费者可以按照自己的需求以不同的速率消费消息。
- Broker(代理):Kafka 集群中的每个服务器节点称为代理。它们负责接收来自生产者的消息,并将消息存储在磁盘上。代理还处理消费者的请求,将消息传递给消费者。
- Partition(分区):每个主题可以分成多个分区。分区是消息在 Kafka 集群中的物理单元,用于水平扩展和提高并发性能。
- Offset(偏移量):偏移量是消息在分区中的唯一标识符。消费者可以跟踪其当前位置,以便从指定的偏移量处继续消费消息。
- Consumer Group(消费者组):消费者可以组成一个消费者组,共同消费一个主题的消息。每个消费者组中的消费者将共享分区,以实现负载均衡和故障恢复。
- Replication(副本):Kafka 使用副本来提供数据冗余和容错性。每个分区可以有多个副本,位于不同的代理上。副本之间通过复制日志保持数据一致性。
- Kafka 的设计目标是具有高吞吐量、可持久化、分布式存储和实时处理的能力。它被广泛应用于构建实时数据管道、日志收集和分析、事件驱动架构等场景。
消息中间件对比
| 特性 | ActiveMQ | RocketMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 开发语言 | java | erlang | java | scala |
| 单击吞吐量 | 万级 | 万级 | 10万级 | 100万级 |
| 时效性 | ms | us | ms | ms以内 |
| 可用性 | 高(主从) | 高(主从) | 非常高(分布式) | 非常高(分布式) |
| 功能特性 | 成熟的产品、较全的文档、各种协议支持好 | 并发能力强、性能好、延迟低 | MQ功能比较完善,扩展性佳 | 只支持主要的MQ功能,主要应用于大数据领域 |
消息中间件对比-选择建议
| 消息中间件 | 建议 |
|---|---|
| Kafka | 追求高吞吐量,适合产生大量数据的互联网服务的数据收集业务 |
| RocketMQ | 可靠性要求很高的金融互联网领域,稳定性高,经历了多次阿里双11考验 |
| RabbitMQ | 性能较好,社区活跃度高,数据量没有那么大,优先选择功能比较完备的RabbitMQ |
Kafka常用名词介绍
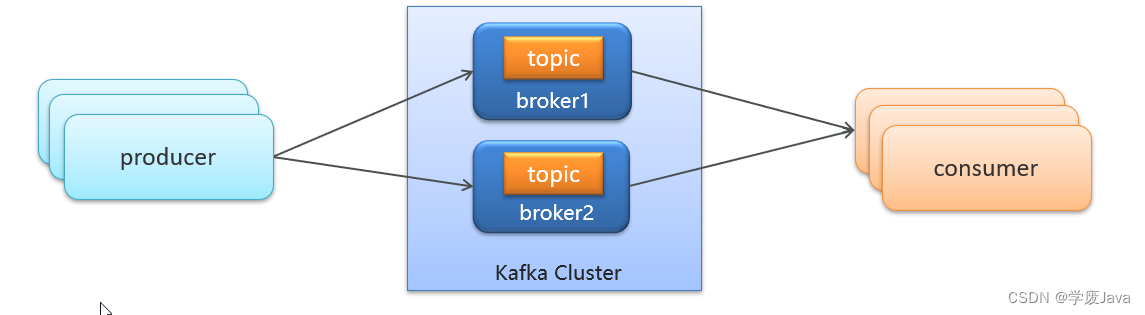
- producer:发布消息的对象称之为主题生产者(Kafka topic producer)
- topic:Kafka将消息分门别类,每一类的消息称之为一个主题(Topic)
- consumer:订阅消息并处理发布的消息的对象称之为主题消费者(consumers)
- broker:已发布的消息保存在一组服务器中,称之为Kafka集群。集群中的每一个服务器都是一个代理(Broker)。 消费者可以订阅一个或多个主题(topic),并从Broker拉数据,从而消费这些已发布的消息。
Kafka入门
1. Kafka安装配置
Kafka对于zookeeper是强依赖,保存kafka相关的节点数据,所以安装Kafka之前必须先安装zookeeper
- Docker安装zookeeper
- 下载镜像
docker pull zookeeper:3.4.14 - 创建容器
docker run -d --name zookeeper -p 2181:2181 zookeeper:3.4.14 - Docker安装kafka
- 镜像下载:
docker pull wurstmeister/kafka:2.12-2.3.1 - 创建容器
docker run -d --name kafka \
--env KAFKA_ADVERTISED_HOST_NAME=192.168.200.130 \
--env KAFKA_ZOOKEEPER_CONNECT=192.168.200.130:2181 \
--env KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.200.130:9092 \
--env KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
--env KAFKA_HEAP_OPTS="-Xmx256M -Xms256M" \
--net=host wurstmeister/kafka:2.12-2.3.1
2.Kafka生产者与消费者关系
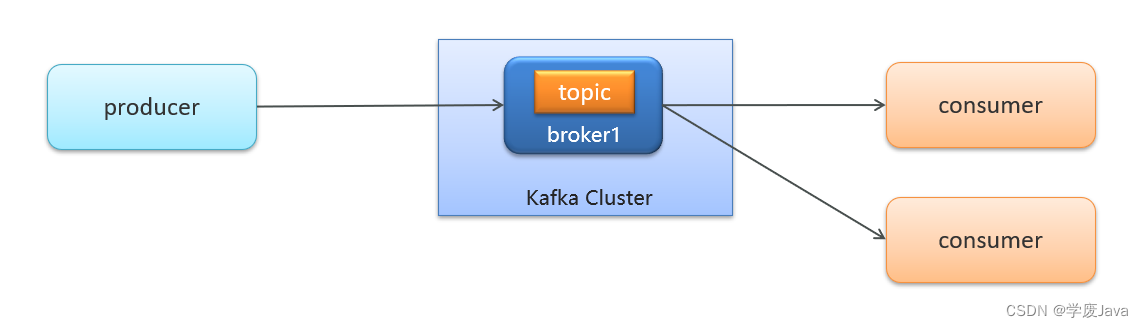
- 生产者发送消息,多个消费者只能有一个消费者接收到消息
- 生产者发送消息,多个消费者都可以接收到消息
3.Kafka依赖
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId>
</dependency>
4.生产者发消息
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;import java.util.Properties;/*** 生产者*/
public class ProducerQuickStart {public static void main(String[] args) {//1.kafka的配置信息Properties properties = new Properties();//kafka的连接地址properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.200.130:9092");//发送失败,失败的重试次数properties.put(ProducerConfig.RETRIES_CONFIG,5);//消息key的序列化器properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");//消息value的序列化器properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");//2.生产者对象KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);//封装发送的消息ProducerRecord<String,String> record = new ProducerRecord<String, String>("itheima-topic","100001","hello kafka");//3.发送消息producer.send(record);//4.关闭消息通道,必须关闭,否则消息发送不成功producer.close();}}5.消费者接受消息
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;import java.time.Duration;
import java.util.Collections;
import java.util.Properties;/*** 消费者*/
public class ConsumerQuickStart {public static void main(String[] args) {//1.添加kafka的配置信息Properties properties = new Properties();//kafka的连接地址properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.200.130:9092");//消费者组properties.put(ConsumerConfig.GROUP_ID_CONFIG, "group2");//消息的反序列化器properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");//2.消费者对象KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);//3.订阅主题consumer.subscribe(Collections.singletonList("itheima-topic"));//当前线程一直处于监听状态while (true) {//4.获取消息ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println(consumerRecord.key());System.out.println(consumerRecord.value());}}}}
总结
- 生产者发送消息,多个消费者订阅同一个主题,只能有一个消费者收到消息(一对一)
- 生产者发送消息,多个消费者订阅同一个主题,所有消费者都能收到消息(一对多)
6.Kafka高可用性设计
6.1集群
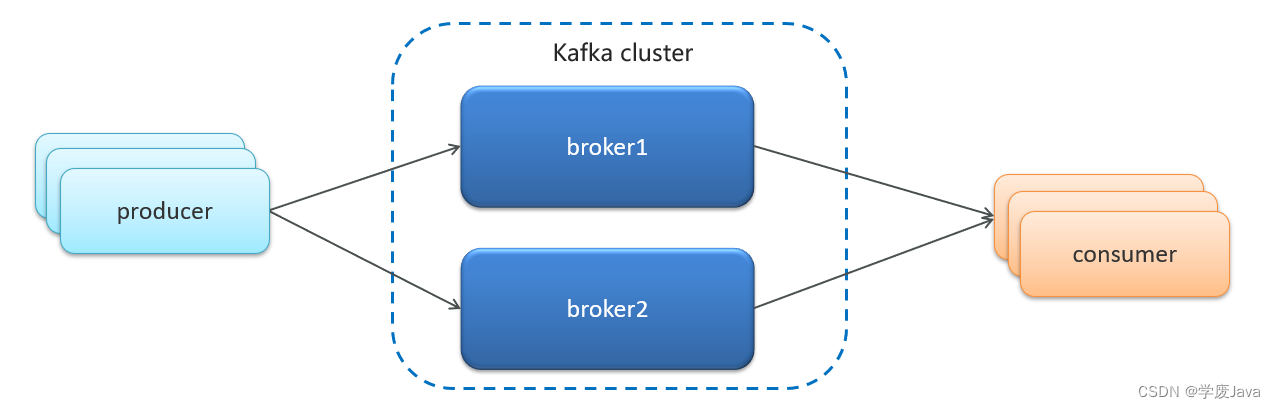
- Kafka 的服务器端由被称为 Broker 的服务进程构成,即一个 Kafka 集群由多个 Broker 组成
- 这样如果集群中某一台机器宕机,其他机器上的 Broker 也依然能够对外提供服务。这其实就是 Kafka 提供高可用的手段之一
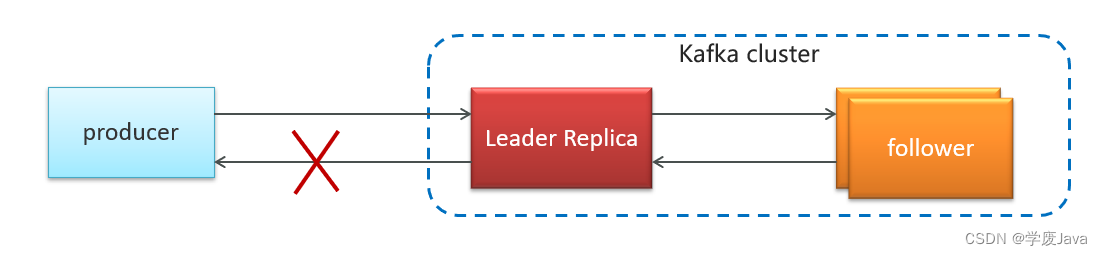
Kafka备份机制(Reolication)
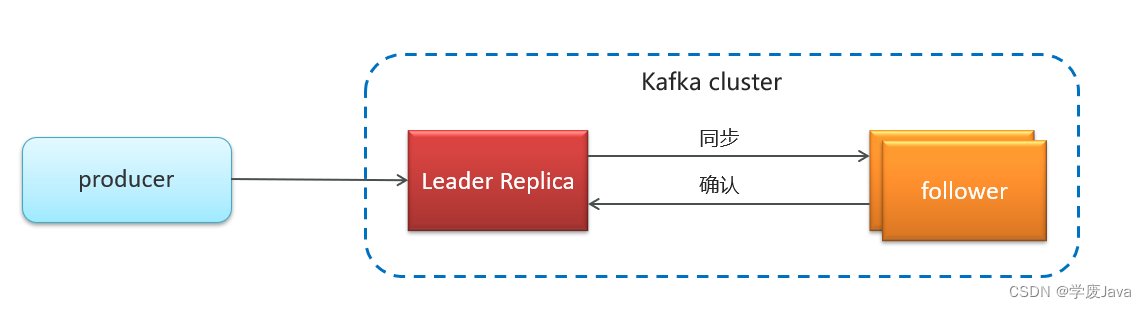
Kafka 中消息的备份又叫做 副本(Replica)
Kafka 定义了两类副本:
- 领导者副本(Leader Replica)
- 追随者副本(Follower Replica)
同步方式
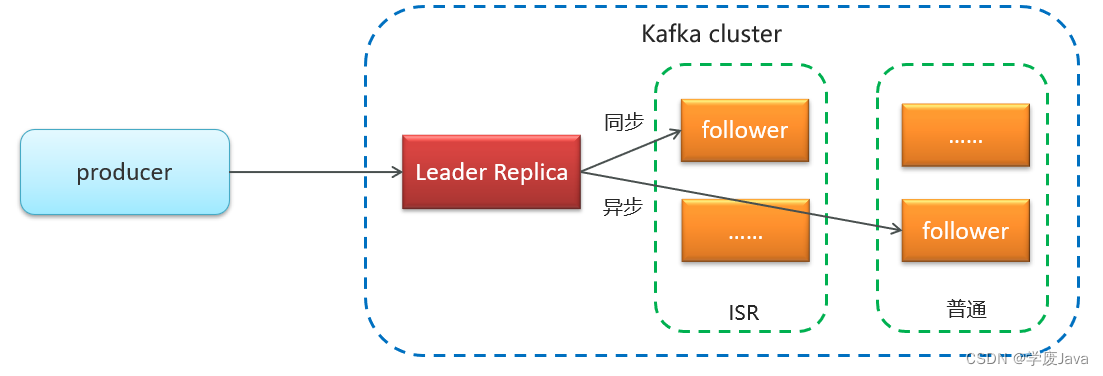
ISR(in-sync replica)需要同步复制保存的follower
如果leader失效后,需要选出新的leader,选举的原则如下:
第一:选举时优先从ISR中选定,因为这个列表中follower的数据是与leader同步的
第二:如果ISR列表中的follower都不行了,就只能从其他follower中选取
极端情况,就是所有副本都失效了,这时有两种方案
第一:等待ISR中的一个活过来,选为Leader,数据可靠,但活过来的时间不确定
第二:选择第一个活过来的Replication,不一定是ISR中的,选为leader,以最快速度恢复可用性,但数据不一定完整
7.kafka生产者详解
7.1 发送类型
- 同步发送
- 使用send()方法发送,它会返回一个Future对象,调用get()方法进行等待,就可以知道消息是否发送成功
RecordMetadata recordMetadata = producer.send(kvProducerRecord).get();
System.out.println(recordMetadata.offset());
- 异步发送
-
- 调用send()方法,并指定一个回调函数,服务器在返回响应时调用函数
//异步消息发送producer.send(kvProducerRecord, new Callback() {@Overridepublic void onCompletion(RecordMetadata recordMetadata, Exception e) {if(e != null){System.out.println("记录异常信息到日志表中");}System.out.println(recordMetadata.offset());}});
7.2参数详解

- ack
- 代码配置
/ack配置 消息确认机制
prop.put(ProducerConfig.ACKS_CONFIG,"all");
参数的选择说明
| 确认机制 | 说明 |
|---|---|
| acks=0 | 生产者在成功写入消息之前不会等待任何来自服务器的响应,消息有丢失的风险,但是速度最快 |
| acks=1(默认值) | 只要集群首领节点收到消息,生产者就会收到一个来自服务器的成功响应 |
| acks=all | 只有当所有参与赋值的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应 |
- retries在这里插入图片描述
生产者从服务器收到的错误有可能是临时性错误,在这种情况下,retries参数的值决定了生产者可以重发消息的次数,如果达到这个次数,生产者会放弃重试返回错误,默认情况下,生产者会在每次重试之间等待100ms
- 代码中配置方式:
//重试次数
prop.put(ProducerConfig.RETRIES_CONFIG,10);
- 消息压缩
默认情况下,消息发送时不会被压缩
代码配置
//数据压缩
prop.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"lz4");
| 压缩算法 | 说明 |
|---|---|
| snappy | 占用较少的 CPU, 却能提供较好的性能和相当可观的压缩比, 如果看重性能和网络带宽,建议采用 |
| lz4 | 占用较少的 CPU, 压缩和解压缩速度较快,压缩比也很客观 |
| gzip | 占用较多的 CPU,但会提供更高的压缩比,网络带宽有限,可以使用这种算法 |
| 使用压缩可以降低网络传输开销和存储开销,而这往往是向 Kafka 发送消息的瓶颈所在。 |
8.kafka消费者详解
8.1消费者组
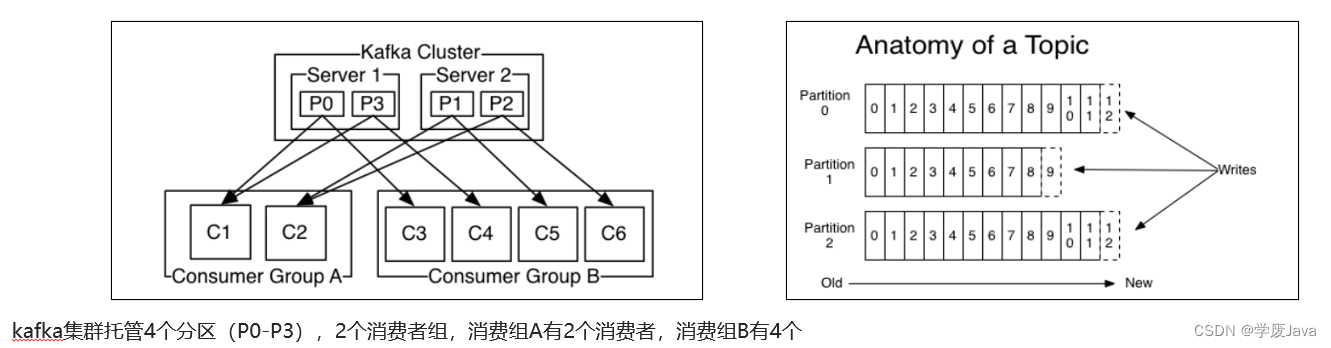
- 消费者组(Consumer Group) :指的就是由一个或多个消费者组成的群体
- 一个发布在Topic上消息被分发给此消费者组中的一个消费者
- 所有的消费者都在一个组中,那么这就变成了queue模型
- 所有的消费者都在不同的组中,那么就完全变成了发布-订阅模型
8.1消息有序性
- 即时消息中的单对单聊天和群聊,保证发送方消息发送顺序与接收方的顺序一致
- 充值转账两个渠道在同一个时间进行余额变更,短信通知必须要有顺序
topic分区中消息只能由消费者组中的唯一一个消费者处理,所以消息肯定是按照先后顺序进行处理的。但是它也仅仅是保证Topic的一个分区顺序处理,不能保证跨分区的消息先后处理顺序。 所以,如果你想要顺序的处理Topic的所有消息,那就只提供一个分区。
7.3 提交和偏移量
kafka不会像其他JMS队列那样需要得到消费者的确认,消费者可以使用kafka来追踪消息在分区的位置(偏移量)
消费者会往一个叫做_consumer_offset的特殊主题发送消息,消息里包含了每个分区的偏移量。如果消费者发生崩溃或有新的消费者加入群组,就会触发再均衡
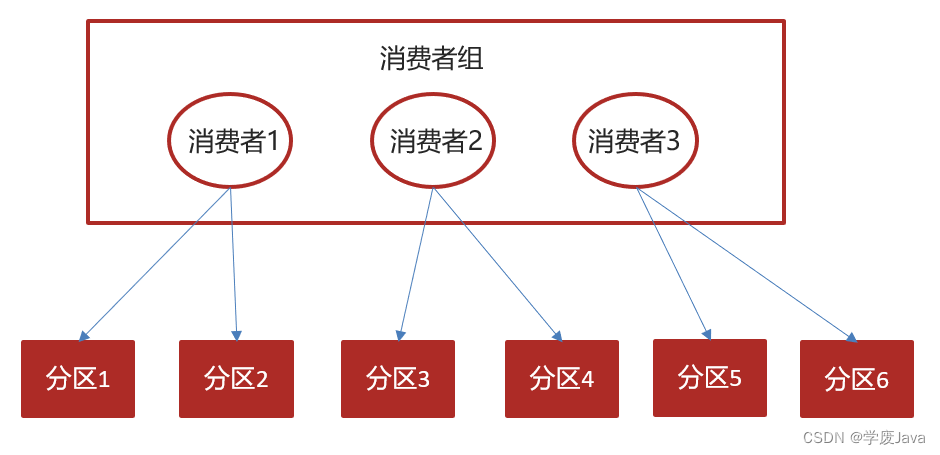
正常的情况
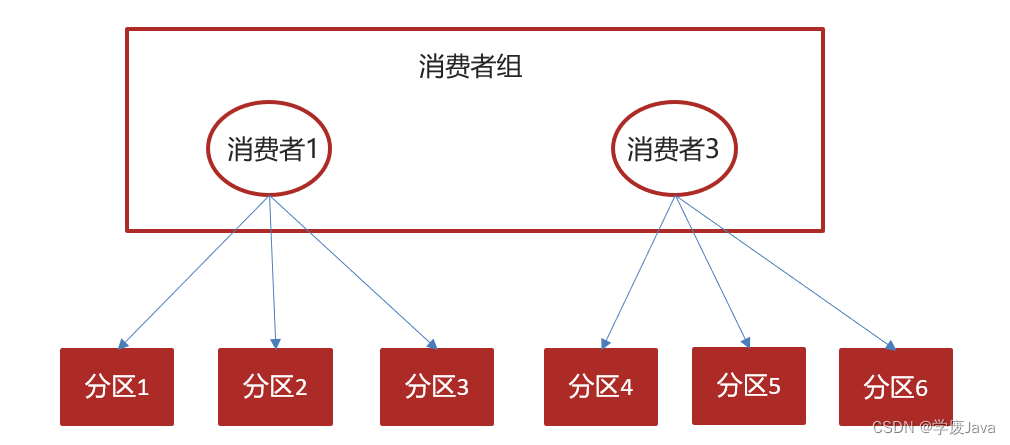
如果消费者2挂掉以后,会发生再均衡,消费者2负责的分区会被其他消费者进行消费
再均衡后不可避免会出现一些问题
问题一:
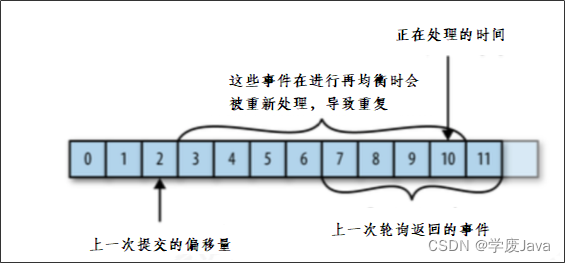
如果提交偏移量小于客户端处理的最后一个消息的偏移量,那么处于两个偏移量之间的消息就会被重复处理。
问题二:
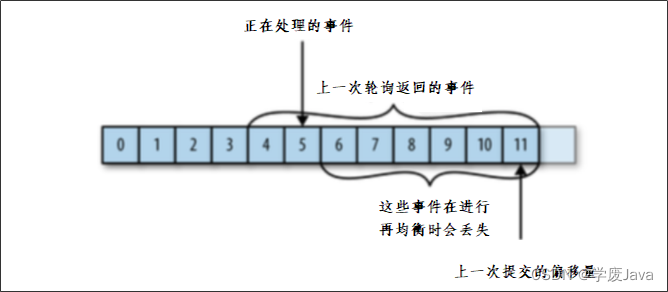
如果提交的偏移量大于客户端的最后一个消息的偏移量,那么处于两个偏移量之间的消息将会丢失。
- 自动提交偏移量
当enable.auto.commit被设置为true,提交方式就是让消费者自动提交偏移量,每隔5秒消费者会自动把从poll()方法接收的最大偏移量提交上去
- 手动提交 ,当enable.auto.commit被设置为false可以有以下三种提交方式
- 提交当前偏移量(同步提交)
- 异步提交
- 同步和异步组合提交
1.提交当前偏移量(同步提交)
把enable.auto.commit设置为false,让应用程序决定何时提交偏移量。使用commitSync()提交偏移量,commitSync()将会提交poll返回的最新的偏移量,所以在处理完所有记录后要确保调用了commitSync()方法。否则还是会有消息丢失的风险。
只要没有发生不可恢复的错误,commitSync()方法会一直尝试直至提交成功,如果提交失败也可以记录到错误日志里。
while (true){ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> record : records) {System.out.println(record.value());System.out.println(record.key());try {consumer.commitSync();//同步提交当前最新的偏移量}catch (CommitFailedException e){System.out.println("记录提交失败的异常:"+e);}}
}
2.异步提交
手动提交有一个缺点,那就是当发起提交调用时应用会阻塞。当然我们可以减少手动提交的频率,但这个会增加消息重复的概率(和自动提交一样)。另外一个解决办法是,使用异步提交的API。
while (true){ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> record : records) {System.out.println(record.value());System.out.println(record.key());}consumer.commitAsync(new OffsetCommitCallback() {@Overridepublic void onComplete(Map<TopicPartition, OffsetAndMetadata> map, Exception e) {if(e!=null){System.out.println("记录错误的提交偏移量:"+ map+",异常信息"+e);}}});
}
3.同步和异步组合提交
异步提交也有个缺点,那就是如果服务器返回提交失败,异步提交不会进行重试。相比较起来,同步提交会进行重试直到成功或者最后抛出异常给应用。异步提交没有实现重试是因为,如果同时存在多个异步提交,进行重试可能会导致位移覆盖。
举个例子,假如我们发起了一个异步提交commitA,此时的提交位移为2000,随后又发起了一个异步提交commitB且位移为3000;commitA提交失败但commitB提交成功,此时commitA进行重试并成功的话,会将实际上将已经提交的位移从3000回滚到2000,导致消息重复消费。
try {while (true){ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> record : records) {System.out.println(record.value());System.out.println(record.key());}consumer.commitAsync();}
}catch (Exception e){+e.printStackTrace();System.out.println("记录错误信息:"+e);
}finally {try {consumer.commitSync();}finally {consumer.close();}
}