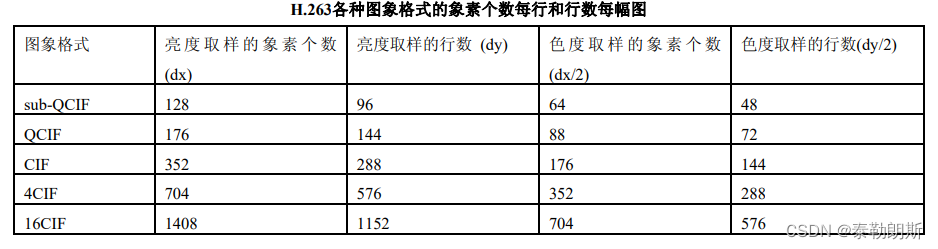
H263码流尺寸规格有限,只有以下几种:
H263码流有四个分层:
1、图像层
2、块组
3、宏块
4、块
下面分别介绍:

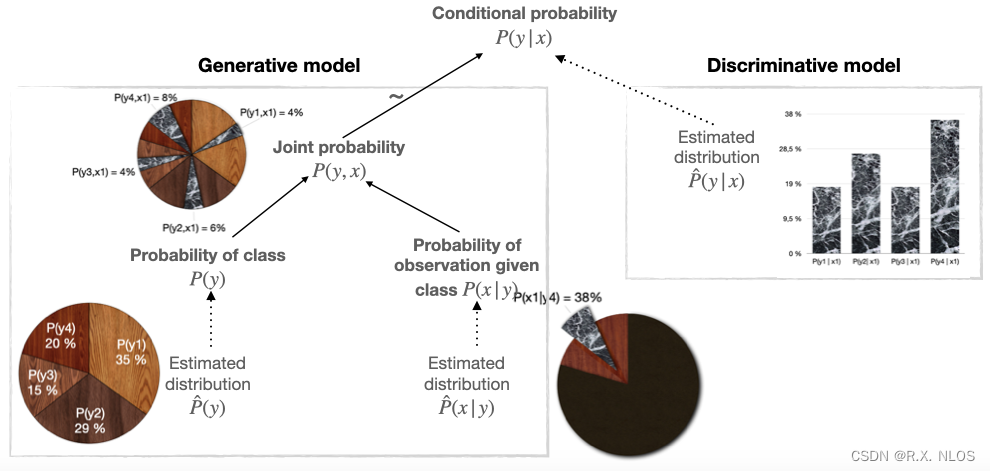
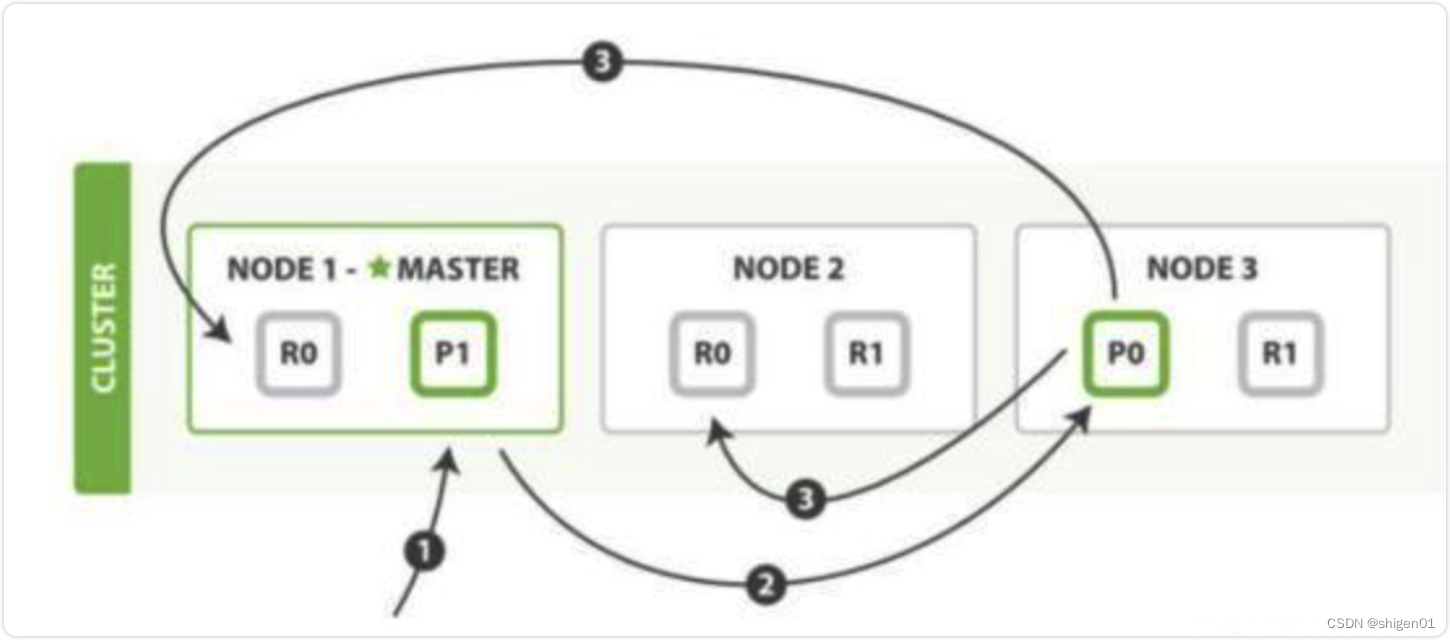
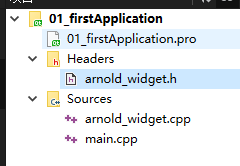
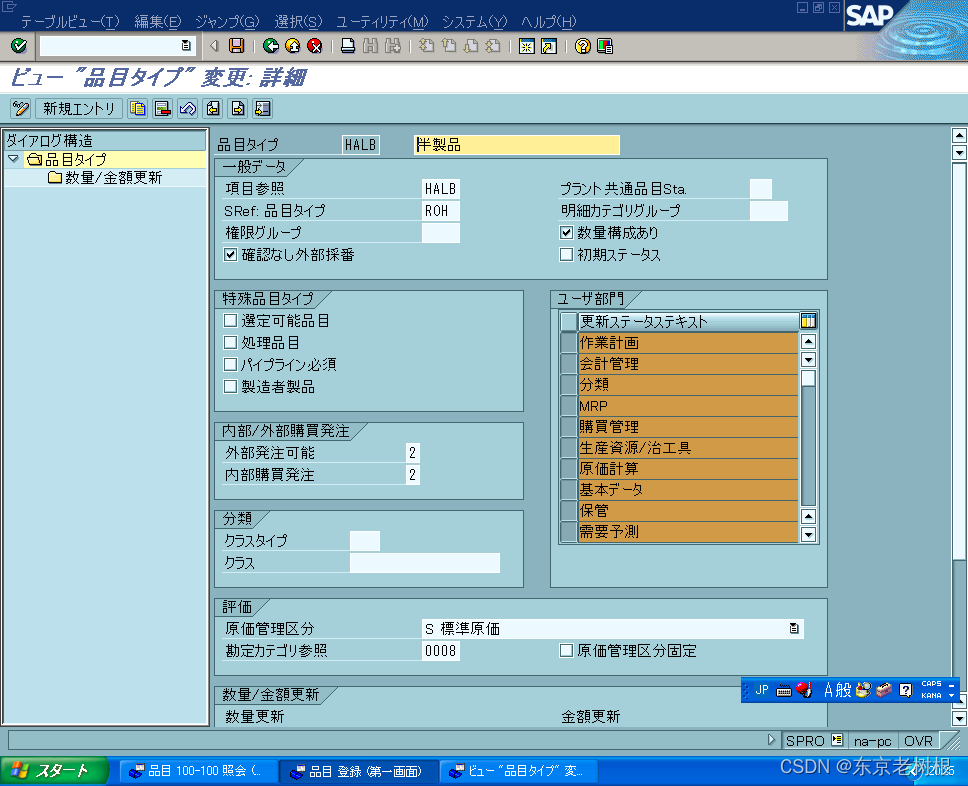
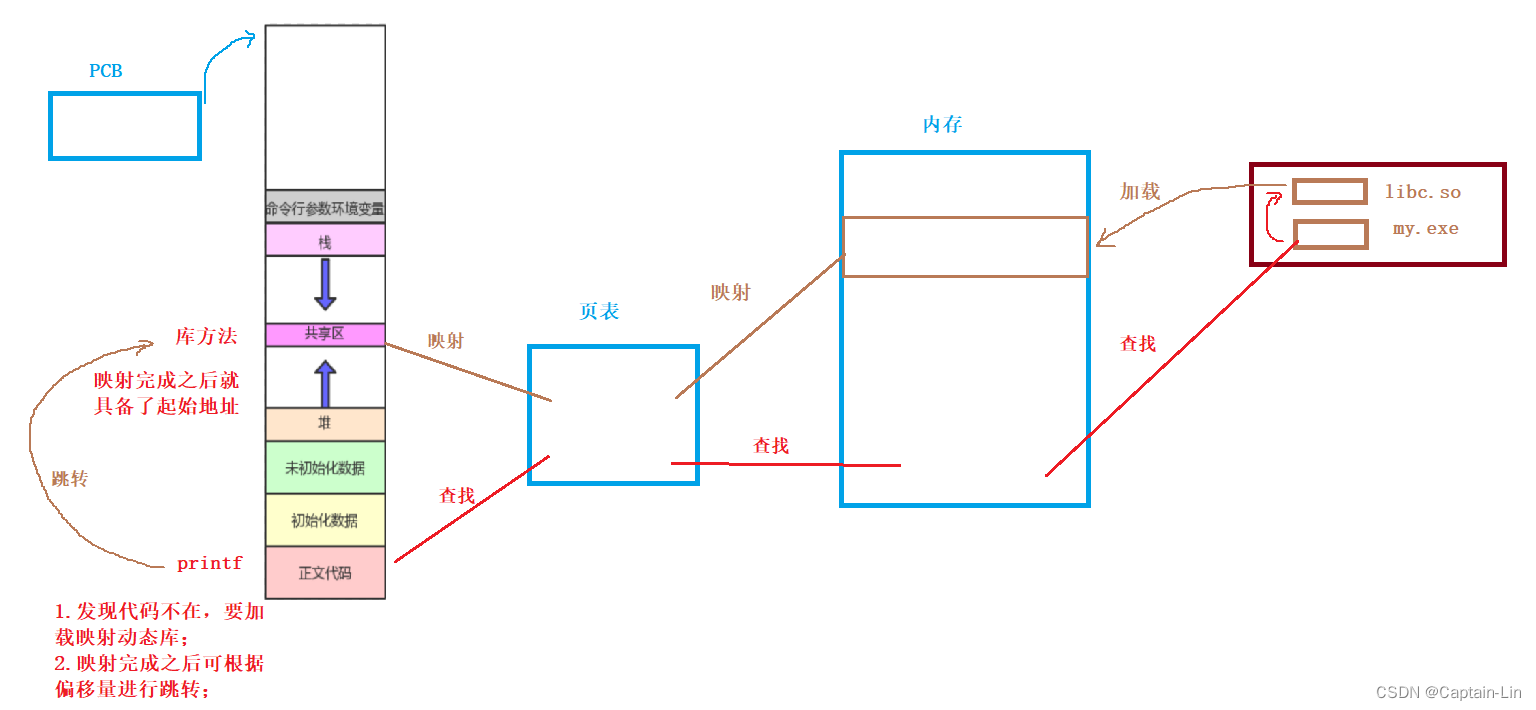
具体介绍如下,5.1.3中红色框选部分就是压缩码流的宽高指示:
图像层



上面就是H263的图像层,块组层在图像层里面。
块组层

上图红色框中的Group of Blocks为块组层。

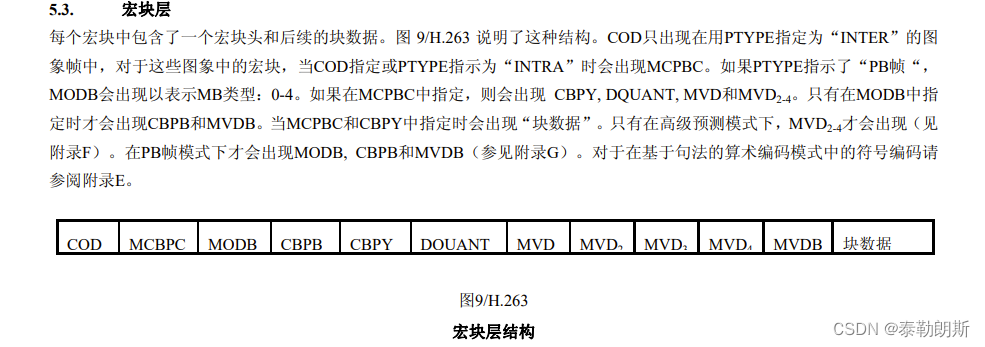
宏块层

上图中的红框为宏块层。
因为我们本章主要介绍如何将连续的H263分解为一帧一帧的packet,并且实时求出每个packet中的宽高,所以我们本次只分析图像层即可。
我们继续回顾图像层:

| 名称 | bit | 说明 |
|---|---|---|
| 图像开始码(PSC) | 22bit | PSC 是一个 22 比特的字。它的值是 0000 0000 0000 0000 1 00000。所有的图象开始码都应该以字节对齐。这应该通过在开始码之前插入 PSTUF 来完成,因此开始码的第一位是一个字节中的第一位(也是最重要的一位) |
| 时域参照 (TR) | 8bit | 一个 8 比特的数可以有 256 种可能值。通过将它在前一帧传送的图象头中的值加 1 再加未传送的帧数(以 29.97 Hz 计)来形成这个值。只对 8 个 LSB 进行计算。在可选的 PB 帧模式下,TR 只指定 P 帧地址;对于 B 帧的时域参照请查看 5.17 部分。 |
| 类别信息1(PTYPE) | 位1 | 始终为“1”,为了避免混淆开始码 |
| 类别信息2(PTYPE) | 位2 | 始终为“0”,与 H.261 相区别 |
| 类别信息3(PTYPE) | 位3 | 屏幕分割指示位,“0”关,“1”开 |
| 类别信息4(PTYPE) | 位4 | 文件相机指示器,“0”关,“1”开 |
| 类别信息5(PTYPE) | 位5 | 静止图象释放位,“0”关,“1”开 |
| 类别信息6-8(PTYPE) | 位6-8 | 信源格式,“000”禁止,“001”sub-QCIF,“010”QCIF,“011”CIF, “100” 4CIF, “101” 16CIF, “110” 保留, “111”保留 |
| 类别信息9(PTYPE) | 位9 | 图象编码类型,“0” INTRA (I-picture),“1” INTER (P-picture) |
| 类别信息10(PTYPE) | 位10 | 可选无限制矢量模式,“0”关,“1”开 |
| 类别信息11(PTYPE) | 位11 | 可选基于句法的编码模式,“0”关,“1”开 |
| 类别信息12(PTYPE) | 位12 | 可选高级预测模式,“0”关,“1”开 |
| 类别信息13(PTYPE) | 位13 | 可选 PB 帧模式,“0”关,“1”开 |
| 量化器信息 (PQUANT) (5 bits) | 5bit | 这是一个固定长度为 5 比特的码字,它指示了为图象使用量化器 QUANT 直到被更新为 GQUANT 或 DQUANT。这个码字以二进制方式表示了 QUANT 的半步距,即从 1 到 31 |
| 连续出现的多点 (CPM) | 1 bit | 这是一个只有一个比特位的码字,它通知了是否使用可选的连续出现多点模式(CPM);“0”关,“1”开。关于 CPM 的使用请参见附录 C |
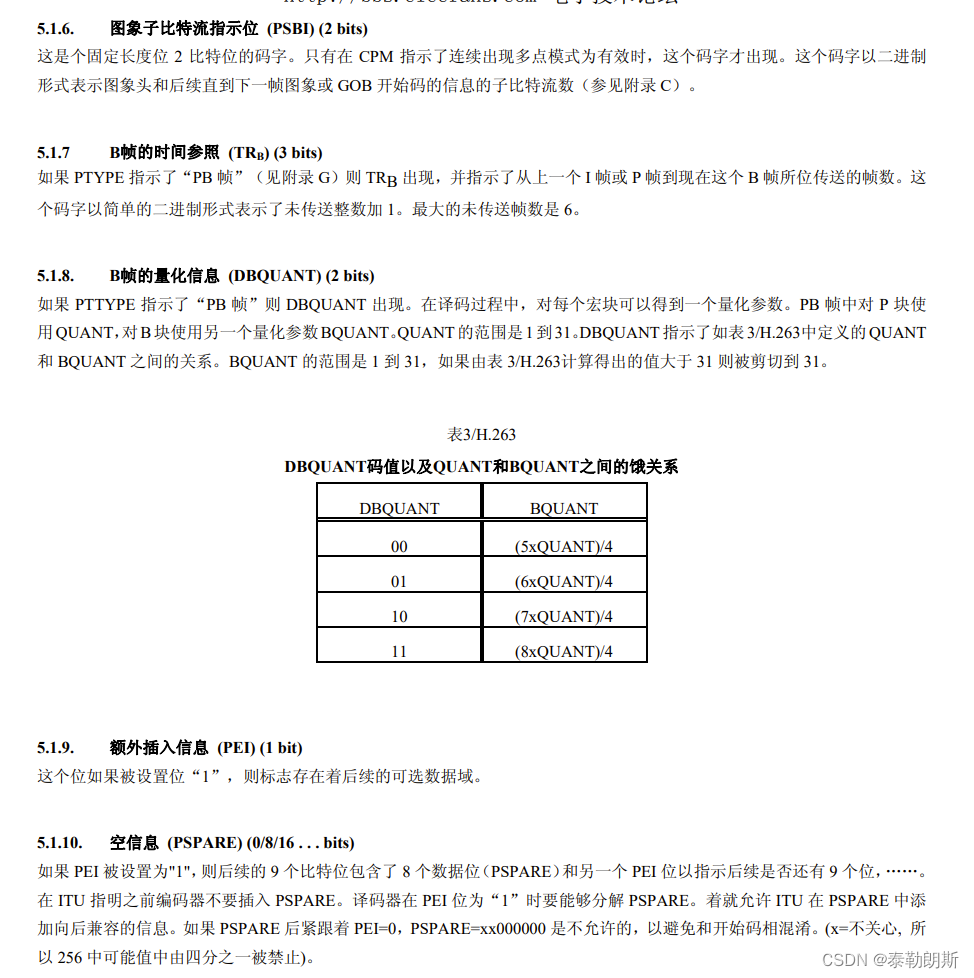
| 图象子比特流指示位 (PSBI) | 2bit | 这是个固定长度位 2 比特位的码字。只有在 CPM 指示了连续出现多点模式为有效时,这个码字才出现。这个码字以二进制形式表示图象头和后续直到下一帧图象或 GOB 开始码的信息的子比特流数(参见附录 C) |
| B帧的时间参照 (TRB) | 3 bit | 如果 PTYPE 指示了“PB 帧”(见附录 G)则 TRB 出现,并指示了从上一个 I 帧或 P 帧到现在这个 B 帧所位传送的帧数。这个码字以简单的二进制形式表示了未传送整数加 1。最大的未传送帧数是 6 |
| B帧的量化信息 (DBQUANT) | 2 bit | 如果 PTTYPE 指示了“PB 帧”则 DBQUANT 出现。在译码过程中,对每个宏块可以得到一个量化参数。PB 帧中对 P 块使用QUANT,对B块使用另一个量化参数BQUANT。QUANT的范围是1到31。DBQUANT指示了如表3/H.263中定义的QUANT和 BQUANT 之间的关系。BQUANT 的范围是 1 到 31,如果由表 3/H.263计算得出的值大于 31 则被剪切到 31 |
| 额外插入信息 (PEI) | 1 bit | 这个位如果被设置位“1”,则标志存在着后续的可选数据域 |
| 空信息 (PSPARE) | (0/8/16 . . . bits) | 如果 PEI 被设置为"1",则后续的 9 个比特位包含了 8 个数据位(PSPARE)和另一个 PEI 位以指示后续是否还有 9 个位,……。在 ITU 指明之前编码器不要插入 PSPARE。译码器在 PEI 位为“1”时要能够分解 PSPARE。着就允许 ITU 在 PSPARE 中添加向后兼容的信息。如果 PSPARE 后紧跟着 PEI=0,PSPARE=xx000000 是不允许的,以避免和开始码相混淆。(x=不关心, 所以 256 中可能值中由四分之一被禁止) |
| 填塞 (ESTUF) | (变长) bit | 这是一个长度可变的包含由少于 8 个“0”位的码字。编码器可以直接在 EOS 码字前插入这个码字。如果有 ESTUF 则 ESTUF的最后一位应该是该字节的最后一位(最不重要)。所以 EOS 码字的开始处是字节对齐的。译码器应被设计成可抛弃 ESTUF |
| 序列结束 (EOS) | 22 bit | 这个码字由 22 个比特位。它的值为 0000 0000 0000 0000 1 11111。由编码器来决定是否插入这个码字。EOS 可以是字节对齐的。在开始码前插入 ESTUF 可使开始码字节对齐 |
| 填塞 (PSTUF) | (变长) bit | 这是一个长度可变的包含由少于 8 个“0”位的码字。编码器应将这个码字插入在下一个 PSC 之前以实现字节对齐。PSTUF的最后一位应该是该字节的最后一位(最不重要),因此包含 PSTUF 的视频比特流到 H.263 比特流开始处的偏移比特数是 8的倍数。译码器应该能够抛弃 PSTUF如果由于某些原因编码器停止编码了一段时间后又继续进行编码,编码器停止之前应发送 PSTUF,以防止出现将上一帧图象编码的最后几位(最多可达 7 位)保留到重新编码开始 |
为了将连续的h263压缩码流分割为一个个以帧为单位的packet,我们就要找到每一帧的起始位置和结束位置,为了简单考虑,我们抛弃图像层不重要的部分,只关心起始和结束的几个关键位:

上图是两帧h263,通过观察发现,我们只要找到PSC就可以了。
具体代码如下:
#define END_NOT_FOUND (-100)int ff_h263_find_frame_end(ParseContext *pc, const uint8_t *buf, int buf_size) {int vop_found, i;uint32_t state;vop_found = pc->frame_start_found;state = pc->state;i = 0;if (!vop_found) {for (i = 0; i < buf_size; i++) {state = (state << 8) | buf[i];if (state >> (32 - 22) == 0x20) {i++;vop_found = 1;break;}}}if (vop_found) {for (; i < buf_size; i++) {state = (state << 8) | buf[i];if (state >> (32 - 22) == 0x20) {pc->frame_start_found = 0;pc->state = -1;return i - 3;}}}pc->frame_start_found = vop_found;pc->state = state;return END_NOT_FOUND;
}
至于宽高,则只要解析类信息的第6-8位再查表即可,不再赘述。

![智慧水利整体解决方案[43页PPT]](https://img-blog.csdnimg.cn/img_convert/fac9d85bb599af888c0454fe96fa7ff1.jpeg)