论文链接:https://www.researchgate.net/publication/371661341_Social_bot_detection_in_the_age_of_ChatGPT_Challenges_and_opportunities
目录
摘要:
引言
1.2. The rise of AI-generated chatbots like ChatGPT
1.4. Scope and objectives of the paper
2.1. Early detection methods based on simple heuristics
2.2. The incorporation of machine learning and natural language processing
2.3. Deep learning and neural network-based approaches
2.4. The impact of large language models on detection techniques
3.1. Increasingly sophisticated AI-generated content
3.2. Adversarial attacks and evasion tactics
3.3. Scalability and real-time detection
3.4. Ethical considerations and privacy concerns
4. Opportunities and emerging trends
4.1. Leveraging transfer learning and unsupervised learning
4.2. Multimodal approaches to detection
4.3. Collaborative and federated learning for detection
4.4. Explainable AI and interpretability in detection techniques
4.5. Combining multiple detection techniques
4.6. Constantly updating and fine-tuning models
4.7. Generative agents as source of synthetic data
5. Case studies: Social bot detection in real-world applications
5.1. Election interference and political manipulation
5.3. Financial scams and cryptocurrency manipulation
6. Conclusions
6.3. Final remarks and potential research directions
摘要:
我们全面概述了在复杂的基于人工智能的聊天机器人兴起的背景下社交机器人检测的挑战和机遇。通过研究社交机器人检测技术的最新水平和迄今为止更突出的现实世界应用,我们确定了该领域的差距和新兴趋势,重点是解决人工智能生成的对话和行为所带来的独特挑战。
我们建议社交机器人检测方面潜在的有前途的机会和研究方向,包括(i)使用生成代理进行合成数据生成、测试和评估; (ii) 需要基于协调和影响的网络和行为特征进行多模式和跨平台检测;; (iii) 将机器人检测扩展到非英语和资源匮乏的语言环境的机会; (iv) 开发协作、联合学习检测模型的空间,这些模型可以帮助促进不同组织和平台之间的合作,同时保护用户隐私。
引言
人工智能(AI)和自然语言处理(NLP)技术的激增催生了先进的社交机器人,给在线通信和网络安全带来了新的挑战。这些机器人模仿人类行为并跨平台交互,通常可能带有恶意意图,例如传播虚假信息或操纵公众情绪。 ChatGPT 等人工智能生成的聊天机器人的出现放大了这些问题,使得社交机器人检测和缓解成为一项势在必行的任务。
回顾
本文对社交机器人检测进行了深入回顾,概括了该领域的挑战、前景和新兴趋势。我们追踪机器人检测技术的演变,从最初的启发式方法到机器学习、NLP 和深度学习方法的使用。还讨论了检测技术上的高级语言模型(例如 ChatGPT)。然后,我们解决社交机器人检测的复杂性,例如人工智能生成内容的复杂性、对抗性策略、可扩展性、实时检测以及道德和隐私考虑。
未来研究方向
同时,我们强调了未来的方向,例如在检测方法中使用迁移学习、无监督学习、多模式方法、协作学习和可解释的人工智能。
真实世界应用案例
此外,我们还介绍了现实世界的案例,展示了机器人检测在选举干扰、虚假信息活动、在线阴谋论和金融欺诈等领域的应用。我们还讨论了生成代理和合成数据在推进该领域的潜在作用。
总结
总之,我们提出了社交机器人检测的最佳实践。这涉及集成不同的检测技术、数据源和模式,定期完善模型,在联合环境中维护隐私,以及利用生成代理和合成数据。
1.1. Background on social bots and their role in society
社交机器人或在社交媒体平台上模仿人类行为的自动化软件,通过从简单脚本到复杂人工智能的算法进行操作,参与任务或在线对话(Ferrara 等,2016)。随着社交媒体的兴起,它们的使用(无论是善意的还是恶意的)都在增长。
良性
良性社交机器人有助于实现内容共享、新闻聚合、客户服务和支持的自动化,从而帮助企业管理其社交媒体存在并提高用户参与度(Ferrara,2020;Mønsted 等,2017;Brandtzaeg 和 Følstad,2017)。
恶意
相反,恶意社交机器人因其对在线社区的潜在危害和操纵公众情绪的能力而受到更多关注,它们参与了虚假信息传播、在线阴谋扩散和政治干预(Bessi 和 Ferrara,2016 年;Shao 等人) .,2018;费拉拉,2020;Wang 等人,2023)。因此,它们的检测和缓解变得至关重要。
社交机器人的复杂性已从早期基于规则、关键字驱动的交互发展到机器学习和自然语言处理的结合,从而实现更真实的类人交流(Chu 等人,2010 年;Chang 和 Ferrara,2022 年) )。例如,一些机器人采用基于马尔可夫链的模型来生成文本,模仿人类生成的内容(Hwang 等人,2012 年;Pozzana 和 Ferrara,2020 年)。
深度学习和神经网络的进步进一步增强了机器人的语言能力(Radziwill 和 Benton,2017)。人工智能驱动的机器人,例如 OpenAI 的 ChatGPT,可以掌握复杂的人类通信模式,生成与实际人类对话越来越难以区分的响应,从而提升社交机器人的能力。
1.2. The rise of AI-generated chatbots like ChatGPT
先进人工智能技术的引入促进了复杂聊天机器人的创建,例如 OpenAI 的 ChatGPT。 ChatGPT 基于 GPT-4 架构(原始 GPT 的扩展)(Radford 等人,2018),生成与人类对话非常相似的连贯且上下文感知的文本。该架构采用了称为 Transformer 的深度学习模型(Vaswani 等人,2017 年),对于涉及自然语言理解和生成的任务非常有效。
由于其大规模和广泛的训练数据,ChatGPT 接受了数千亿个单词的训练,并使用人类反馈的强化学习 (RLFH) 进行微调(OpenAI,2021)。无监督预训练和基于强化学习的微调相结合,使 ChatGPT 能够生成适合上下文且符合人类需求的响应。
ChatGPT 和其他大型语言模型(例如 BERT(Devlin 等人,2018)和 XLNet(Yang 等人,2019))在自然语言生成方面取得的进展大大增强了社交机器人的能力。这使得用户交互更加复杂和细致,开辟了新的人工智能应用机会,但也加剧了滥用的可能性,从而使社交机器人检测变得复杂。
1.3. The importance of social bot detection
识别并区分人类用户和社交机器人对于维护在线社区和社交媒体平台的完整性至关重要。有效的社交机器人检测可以减少恶意机器人的影响,例如虚假信息传播、舆论操纵和有害内容放大。
· 恶意社交机器人利用社交媒体平台传播虚假信息并影响公共话语(Ferrara,2017;Shao 等,2018)。在选举等政治场景中,这些机器人会传播虚假信息来操纵公众情绪(Bessi 和 Ferrara,2016;Howard 和 Kolanyi,2016)。可靠的社交机器人检测可以帮助发现和抵制这些虚假信息活动,促进透明和民主的在线空间。
社交机器人也延续了在线阴谋论(Samory 和 Mitra,2018;Muric 等,2021)。这些机器人可以放大破坏性内容并开展有针对性的活动。采用强大的机器人检测机制可以帮助保护用户免受此类恶意活动的侵害,确保安全和包容的在线环境。
社会媒体平台的政策禁止的自动帐户的恶意活动或操纵平台的指标,如喜欢的股份,并追随者(Ferrara,2022年). 执行这些政策要求有效地检测和消除社会的机器人,因此增强了用户体验真实性。此外,社交机器人可能会通过未经授权的数据收集或监视来侵犯用户隐私(Gorwa 和 Guilbeault,2020),这凸显了强大的社交机器人检测的重要性。
虽然社交机器人检测技术多种多样,从简单的基于规则的方法和特征工程方法(Chu,et al.,2010;Subrahmanian,et al.,2016)到先进的机器学习和深度学习技术(Ferrara,et al.,2016) ;Z. Yang 等,2019),ChatGPT 等人工智能驱动的聊天机器人的复杂性带来了新的检测挑战,强调了该领域正在进行的研究的重要性(Abdullah 等,2022;Hajli 等, 2022)。
1.4. Scope and objectives of the paper
这篇观点论文旨在在 ChatGPT 等人工智能生成的聊天机器人日益复杂的背景下,对社交机器人检测进行详细分析。它将重点关注新一代聊天机器人为机器人检测带来的挑战和机遇,强调创新解决方案和利益相关者协作的必要性。
机器人检测的挑战:ChatGPT 等人工智能驱动的聊天机器人的复杂性给传统机器人检测技术(例如基于规则的系统和特征工程方法)带来了重大障碍(Cresci 等人,2020)。研究人员正在转向先进的机器学习和深度学习技术来解决这个问题(Yang 等人,2019 年;Varol 等人,2017 年)。本文将深入研究现有的检测局限性并讨论可能的解决方案。
最佳实践和未来方向:本文将重点介绍社交机器人检测的最佳实践,包括混合不同的检测技术、持续的模型更新以及解决检测方法中的道德考虑。它还将探索社交机器人检测的潜在未来趋势,例如采用可解释的人工智能技术(Adadi 和 Berrada,2018)以及人机交互方法的集成(Holzinger,2016)。
2. The evolution of social bot detection techniques
2.1. Early detection methods based on simple heuristics
在社交机器人检测的早期阶段,研究人员主要依靠简单的启发式和基于规则的系统来识别机器人(Ferrara, et al., 2016;Cresci, 2020;Orabi, et al., 2020)。这些技术侧重于利用易于观察的模式和特征来指示类似机器人的行为。
帐户活动:与人类用户相比,机器人通常会表现出高频的消息传递和帐户活动。通过分析每单位时间的帖子、转发或消息数量,研究人员能够识别潜在的机器人(Benevenuto 等,2010)。
帐户元数据:与用户个人资料相关的某些元数据,例如帐户创建日期、关注者数量以及关注者与关注者比率,可以指示机器人行为。例如,机器人通常具有不成比例的高关注者比率和较短的帐户生命周期(Chu,et al.,2010;Wang,et al.,2012)。
基于内容的功能:机器人通常会生成重复的、包含特定关键字或源自有限来源的内容。通过分析内容的多样性、某些关键词的存在以及来源的分布,研究人员可以识别潜在的机器人(Ratkiewicz 等人,2011 年;Lee 等人,2011 年)。
基于网络的特征:机器人通常表现出不同的网络模式,例如形成紧密连接的群体或几乎没有互惠关系。通过分析关注者和朋友网络的结构,研究人员可以检测潜在的机器人帐户(Stringhini 等,2010)。
虽然这些早期检测方法为识别社交机器人提供了基础,但它们适应机器人行为不断发展的复杂性的能力有限。更先进的机器人可以通过模仿人类行为、调整其活动模式或生成不同的内容来轻松规避这些基于启发式的方法(Chang 和 Ferrara,2022)。
此外,对手动制定的规则和功能的依赖使得这些方法容易受到误报和误报的影响,因为真正的用户可能会表现出类似机器人的行为,反之亦然。这种限制导致了更先进技术的发展,这些技术结合了机器学习和自然语言处理,以提高检测准确性和适应性(Subrahmanian 等人,2016 年;Ferrara 等人,2016 年)。
2.2. The incorporation of machine learning and natural language processing
随着社交机器人变得越来越复杂,检测方法不断发展,包括机器学习和自然语言处理 (NLP) 技术。这些创新方法旨在通过分析机器人行为、语言使用和网络特征的细微差别模式来识别机器人,从而与传统的启发式方法相比提高准确性和适应性。
机器学习算法,例如决策树、支持向量机、逻辑回归和随机森林,被用来根据账户在线行为的不同特征将账户分类为机器人或人类(Subrahmanian 等人,2016 年;Ferrara 等人)等,2016)。通过在经过验证的机器人和人类账户的数据集上训练模型,研究人员设计了可以泛化到不熟悉的实例并适应社交机器人不断发展的行为的分类器。
基于机器学习的检测的有效性很大程度上取决于分类特征的质量,其中包括帐户元数据、基于内容的特征和基于网络的属性。还使用了机器人生成内容的语言特征,例如情感分数、词汇多样性和主题分布(Davis 等人,2016 年;Kudugunta 和 Ferrara,2018 年)。
在标记数据有限或获取成本高昂的情况下,研究人员转向无监督和半监督学习技术来检测机器人。聚类、异常值检测和标签传播等技术试图通过分析固有的数据结构和模式来识别机器人,而不需要显式标签(Chavoshi 等人,2016 年;Cao 等人,2014 年)。这些方法可以发现监督学习技术忽视的新颖的机器人行为和模式。
此外,研究人员应用 NLP 技术来分析机器人生成文本的语言特征。情感分析、主题建模和句法解析能够提取更高级别的语言模式和结构(Beskow 和 Carley,2018;Addawood 等人,2019)。通过将 NLP 功能集成到机器学习模型中,研究人员可以更有效地区分机器人生成的内容和人类生成的内容。
2.3. Deep learning and neural network-based approaches
深度学习和神经网络技术的出现彻底改变了社交机器人检测领域。这些先进的技术可以从原始数据中学习复杂的模式和特征,从而消除了手动特征工程的需要。它们已用于检查与用户配置文件和活动相关的文本内容和元数据,提供比传统机器学习和 NLP 方法更强的检测功能。
卷积神经网络 (CNN) 已被部署来检查文本内容并从单词或字符序列中提取复杂的特征。这些网络由多层卷积和池化操作组成,可以识别数据中的局部模式和层次结构(Zhang 等,2015)。研究人员利用 CNN 通过研究社交机器人生成内容中的文本模式和特征来检测社交机器人(Min 等人,2017 年;Cresci 等人,2017 年)。循环神经网络 (RNN) 和长短期记忆 (LSTM) 网络(Hochreiter 和 Schmidhuber,1997 年;Chung 等人,2014 年)已用于分析社交机器人生成的内容中的时间依赖性和序列。这些网络擅长学习远程依赖性和捕获上下文数据,使其成为分析文本序列、用户活动或时间序列数据的理想选择。它们已被用来根据社交机器人生成的内容和时间活动的模式和结构来识别社交机器人(Kedugunta 和 Ferrara,2018)。图神经网络(GNN)已被用来对在线平台上的网络结构和用户之间的交互进行建模。这些网络旨在检测图结构数据中的复杂关系模式和依赖性,已用于根据网络属性和关系模式检测社交机器人(Guo 等人,2021)。
最后,研究人员利用迁移学习和预训练语言模型,例如 BERT、GPT 和 RoBERTa(Devlin 等人,2018 年;Radford 等人,2018 年;Liu 等人,2019 年)来进行社交机器人检测。这些模型在广泛的文本语料库上进行了预训练,并针对特定任务进行了微调,可以从文本中提取丰富的语义和句法信息。利用这些预先训练的模型可以增强检测能力,并有助于区分人类和机器人生成的内容(Heidari 和 Jones,2020;Guo 等人,2021)。迁移学习在使现有机器人检测模型适应低资源语言设置、即使在严格的数据约束下也能提高检测性能方面表现出了希望(Haider 等人,2023 年)。
2.4. The impact of large language models on detection techniques
ChatGPT 等人工智能生成的聊天机器人的兴起给社交机器人检测带来了新的挑战。这些复杂的模型可以生成具有显着连贯性、流畅性和上下文感知能力的类人文本(Radford 等,2019)。因此,依赖于语言模式或基于内容的特征的传统检测方法可能难以区分人工智能生成的内容和人类生成的内容(Gehrmann 等人,2019 年;Zellers 等人,2019 年;Grimme 等人,2022 年) )。
研究人员已开始开发创新的检测方法和技术,以应对 ChatGPT 和类似的人工智能生成的聊天机器人带来的挑战。是寻找特定于模型训练数据或架构的对抗性示例或工件。通过研究生成文本中的异常和偏差,研究人员可以找出表明人工智能生成内容的模式或特征(Ippolito 等人,2020 年;Solaiman 等人,2019 年)。此外,在包含人工智能生成和人类生成内容的数据集上微调预训练的语言模型可以提高这些模型的检测能力(Guo 等人,2021)。
随着人工智能生成的文本变得越来越复杂,研究人员正在将基于文本的社交机器人与生成逼真的、经过操纵的图像或视频的深度伪造技术进行比较。为深度伪造检测开发的技术,如取证特征、集成学习和对抗训练,可能适用于检测 AI 生成的文本(Afchar 等人,2018 年;Li 等人,2020 年)。研究人员正在探索可解释的人工智能 (XAI) 技术和特征归因方法,例如 LIME、SHAP 和集成梯度(Ribeiro 等人,2016 年;Lundberg 和 Lee,2017 年;Sundararajan 等人,2017 年),以更好地理解深度学习模型的决策过程并增强其检测能力。通过揭示影响模型预测的因素,这些方法可以帮助识别表明人工智能生成内容的新特征和模式,从而为更有效的检测技术的设计提供信息。
随着人工智能生成的聊天机器人不断发展,它们可能会用于多模式环境中,例如同时生成文本和图像或参与交互式对话。研究人员已经开始研究能够分析和整合来自各种模态的信息以提高检测准确性的多模态检测技术(Cao 等人,2023)。
3. Novel challenges in social bot detection
在本节中,我们讨论由于人工智能和自然语言处理技术的进步而在社交机器人检测中出现的新挑战。这些挑战包括日益复杂的人工智能生成内容、恶意行为者采用的对抗性攻击和规避策略、对可扩展和实时检测方法的需求,以及必须解决的道德考虑和隐私问题。通过研究这些挑战,我们的目标是更深入地了解数字时代检测和减轻社交机器人影响所涉及的复杂性。
3.1. Increasingly sophisticated AI-generated content
先进的人工智能生成的聊天机器人(例如 ChatGPT 及其后继者)的出现可以导致社交机器人生成的内容的复杂性显着增加。依赖基于内容的特征或浅层学习方法的传统检测技术可能难以将人类生成的内容与人工智能生成的内容区分开。
最近的几项研究强调了复杂的人工智能生成内容在社交机器人检测背景下带来的挑战:
GLTR 研究(Gehrmann 等人,2019)发现,即使像 GPT-2 这样简单的语言模型也可以生成以下文本:即使对于专家注释者来说,也很难将其与人类书写的文本区分开来。据推测,基于 GPT 的语言模型(包括 ChatGPT 和 GPT-4)的未来迭代已经缩小了人类生成的内容和人工智能生成的内容之间的差距,这对基于语言模式或基于内容的特征的检测技术提出了挑战。
GROVER 研究(Zellers 等,2019)证明,人工智能生成的文本可以非常有效地逃避人类和自动分类器的检测。研究人员发现,预训练的语言模型在针对生成和检测虚假帐户的任务进行微调时,在生成误导性内容方面更有效,并且对对抗性攻击更稳健。
由于需要集成和分析来自多种模态的信息,在多模态环境中检测人工智能生成的内容(例如图像标题或视频描述)提出了额外的挑战。为了应对这些挑战,研究人员已经开始探索新颖的检测技术和方法,以有效地区分人类生成的内容和人工智能生成的内容。识别特定于模型训练数据或架构的对抗性示例或工件可以帮助检测 AI 生成的内容(Solaiman 等人,2019 年;Wolff 和 Wolff,2020 年;Ippolito 等人,2020 年)。
利用预训练语言模型(例如 BERT、GPT 和 RoBERTa)中包含的知识,可以通过捕获文本中丰富的语义和句法信息来增强分类器的检测能力(Cresci 等人,2017 年;Heidari 和 Jones, 2020;郭等人,2021)。采用可解释的人工智能技术和特征归因方法可以深入了解影响模型预测的因素,有助于识别表明人工智能生成内容的新颖特征和模式。
3.2. Adversarial attacks and evasion tactics
随着社交机器人检测技术的发展,恶意行为者逃避检测的策略也在不断发展。社交机器人越来越擅长通过采用对抗性攻击和规避策略来避免检测,这给该领域的研究人员和从业者带来了重大挑战。该领域的一些关键策略和挑战包括:
模仿人类行为:社交机器人可以越来越多地调整其行为以模仿人类用户,从而使它们更难以使用行为模式或基于网络的功能进行检测(Chang 和 Ferrara,2022)。情感分析、主题建模和用户分析等技术已被用来更好地区分真实的人类行为和机器人行为(Chavoshi 等人,2016 年;Cresci 等人,2017 年)。
动态内容生成:社交机器人可以采用更加多样化和复杂的内容生成策略,利用 ChatGPT 等先进人工智能生成的聊天机器人的功能来生成上下文感知、连贯且类似人类的文本(Zellers 等,2019)。这就需要开发新颖的基于内容的检测技术,该技术可以识别人工智能生成的文本并将其与人类生成的内容区分开来。
对抗性机器学习:恶意行为者可以通过制作旨在欺骗分类器的对抗性示例来利用基于机器学习的检测技术的漏洞(Biggio 等人,2013 年)。研究人员需要开发更强大、更有弹性的检测技术,能够抵御对抗性攻击,采用对抗性训练、集成学习和数据增强等方法(Szegedy, et al., 2013; Goodfellow, et al., 2014; Tramèr, et al. .,2017)。
伪装和混淆:社交机器人可能采用各种伪装和混淆策略,例如改变其发布模式、改变其网络结构或使用不同的通信渠道以避免检测(Ferrara 等人,2016 年;Grimme 等人,2018 年) )。研究人员必须不断监控和调整他们的检测方法来应对这些不断变化的威胁,结合新功能并根据需要更新他们的模型。
3.3. Scalability and real-time detection
在大规模动态在线环境中检测社交机器人在可扩展性和实时检测方面提出了重大挑战。流行的社交媒体平台会生成大量数据,需要能够快速有效地处理和分析这些信息的检测技术。此外,社交网络上信息的快速传播需要实时或近实时检测,以在恶意社交机器人的活动造成重大损害之前减轻其影响。对于有害内容尤其如此,因为负面、煽动性和虚假谣言传播得更快(Ferrara 和 Yang,2015;Stella 等,2018;Vosoughi 等,2018)。
许多先进的检测技术,特别是基于深度学习和神经网络的技术,需要大量的计算资源,并且训练和执行可能非常耗时。例如,训练大规模 Transformer 模型(例如 BERT 或 GPT)涉及大量计算开销,因此很难部署这些模型进行实时社交机器人检测(Devlin 等人,2018 年;Radford 等人, 2019)。为了应对这些挑战,研究人员探索了各种方法来提高社交机器人检测技术的可扩展性和效率:
模型压缩和蒸馏:模型剪枝、量化等技术知识蒸馏可用于减少深度学习模型的规模和计算复杂性,从而能够在实时检测场景中更有效地部署(Buciluǎ,et al.,2006)。这些方法可以帮助保持模型的准确性,同时减少与训练和推理相关的计算开销。
增量学习和在线算法:增量学习技术和在线算法可以适应新数据,从而在动态环境中进行更有效的检测(JafariAsbagh 等,2014)。这些方法可以逐步更新模型,减少昂贵的重新训练的需要,并实现社交机器人的实时或近实时检测。
并行和分布式处理:并行和分布式处理技术可用于利用多个处理器或机器的计算能力,从而实现大规模社交媒体数据的高效处理和分析(Gao等人,2015)。这些方法可以帮助扩展社交机器人检测技术,以处理流行社交媒体平台生成的海量数据。
基于流的处理和数据缩减:基于流的处理技术可用于实时分析生成的数据,从而可以更有效地检测动态在线环境中的社交机器人(Morstatter 等人,2013 年;JafariAsbagh)等,2014;高等,2015)。数据缩减技术,例如采样、草图和聚合,也可用于最大限度地减少需要处理和存储的数据量,从而提高检测技术的效率。
3.4. Ethical considerations and privacy concerns
社交机器人检测技术应对复杂的道德和隐私环境。确保检测和缓解恶意机器人不会侵犯真正用户的权利或损害他们的个人信息至关重要。因此,在社交机器人检测技术的开发和部署过程中,必须解决道德和隐私相关的挑战。
社交机器人检测的一个主要问题是误报的风险,即合法用户被错误地识别为机器人。这可能会给无辜用户带来不公正的后果,比如账户被暂停或内容被删除,潜在地侵犯了他们的言论自由和获取信息的权利。为了最大限度地降低这种风险,研究人员必须专注于开发极其准确且在多样化和代表性数据集上经过广泛验证的检测技术。此外,决策过程的透明度和可解释性对于确保公平公正地检测和缓解社交机器人至关重要(Ribeiro 等,2016)。
检测社交机器人通常涉及分析用户生成的内容、元数据和行为模式,这引发了重大的隐私和数据保护问题。为了保护用户隐私,检测技术应符合欧盟通用数据保护条例(GDPR)等数据保护法规,并应尽量减少敏感个人信息的收集、存储和处理。使用差分隐私和联邦学习等隐私保护技术可以帮助在分析过程中保护用户数据(Dwork,2006;Ezzeldin,et al.,2021),但也有局限性(Fung,et al.,2020)。
人工智能生成内容的快速发展为社交机器人检测带来了机遇和挑战。虽然这些模型可以提高检测技术的准确性和稳健性,但它们也可能被恶意行为者滥用来创建更先进和难以捉摸的社交机器人。因此,研究人员和从业者需要确保用于社交机器人检测的人工智能生成内容的开发和部署符合道德和负责任的方式进行,并采取适当的保障措施来防止滥用。
4. Opportunities and emerging trends
在本节中,我们将探讨塑造社交机器人检测未来的机遇和新兴趋势。这些发展提供了创新的方法来应对日益复杂的人工智能生成内容和社交机器人采用的对抗策略所带来的挑战。我们将讨论迁移学习和无监督学习的潜力、多模式检测方法、协作和联合学习的作用,以及可解释的人工智能和可解释性在检测技术中的重要性。我们还将讨论结合多种检测技术并随着时间的推移微调模型的机会。最后,我们提出使用生成代理作为合成训练数据源的想法。通过强调这些机会,我们的目标是为研究人员和从业者提供一个路线图,以利用这些进步并提高社交机器人检测的有效性。
4.1. Leveraging transfer learning and unsupervised learning
迁移学习案例
迁移学习是一种允许模型利用从预训练模型或相关任务中获得的知识的技术,可以对其进行微调以检测社交机器人(Pan 和 Yang,2010)。例如,预训练语言模型,如 BERT (Devlin, et al., 2018) 和 GPT (Radford, et al., 2019),已经证明了迁移学习在自然语言处理任务中的有效性。通过在较小的、特定于任务的数据集上微调这些模型,研究人员可以利用预训练期间捕获的丰富语义和句法信息来识别机器人生成的内容。这种方法可以帮助提高分类器的准确性,同时减少对大量标记训练数据的需求。此外,迁移学习可以帮助减轻域转移的影响,当用于训练的数据分布与目标数据的分布不同时,就会发生域转移(Torrey 和 Shavlik,2010)。通过利用预先训练的模型,研究人员可以更有效地适应社交机器人不断变化的行为和策略,正如 Yang 等人的工作所证明的那样。 (2020) 使用基于 BERT 的模型检测机器人。
无监督学习技术案例(自编码器)
无监督学习技术不需要标记数据,可用于识别数据中可能指示社交机器人活动的模式、异常或集群(Chandola 等,2009)。聚类、降维和自动编码器等混合方法可以帮助捕获数据的底层结构并揭示潜在的类似机器人的行为,而无需依赖标记的示例。例如,降维技术,如 t 分布随机邻域嵌入 (tSNE),可用于可视化高维数据,促进用户行为模式和异常的识别(van der Maaten 和 Hinton,2008)。与自动编码器(一种神经网络)相结合,它们可以用于无监督特征学习,捕获可能被证明对检测机器人有用的数据的潜在表示(Haider 等人,2023)。
总之,利用迁移学习和无监督学习方法可以解决与数据稀缺、昂贵的注释过程以及适应社交机器人检测任务中机器人不断变化的行为相关的挑战。通过利用预训练模型和无监督技术捕获的丰富知识,研究人员可以开发更准确、更稳健的检测方法。
4.2. Multimodal approaches to detection
多模态方法结合了文本、图像和网络特征等不同类型的数据,可以提供对用户行为更全面、更稳健的理解,从而改进社交机器人的检测。通过整合不同的信息源,这些技术可以捕获数据中复杂而微妙的模式,而单模态方法可能会忽略这些模式。
多模态方法研究(文本与图像)
最近,人们对使用多模态数据进行社交机器人检测越来越感兴趣。一个有前途的方向是文本和图像分析的集成。例如,吴等人(2019)提出了一种通过联合建模文本和视觉信息来检测假新闻的多模式方法。他们的方法使用分层注意力网络来捕获文本和视觉特征之间的依赖关系,使模型能够识别通过文本和视觉内容传播误导性信息的机器人。同样,Besel 等人 (2018) 提出了一种结合文本和视觉线索来检测 Twitter 上的社交机器人的模型,证明了多模式方法在捕获补充信息方面的有效性。
多模态方法研究(网络,时间与内容)
多模态方法的另一个方向是网络特征的结合。社交机器人检测可以受益于分析用户交互和网络结构,这可以揭示可疑的交互模式或网络结构,这些交互模式或网络结构可能表明协调的机器人活动(Pacheco 等人,2020 年;Pacheco 等人,2021 年)。 Sharma 等人(2021)提出了一种将时间特征与基于内容的特征相结合以协调社交媒体平台上的影响力活动的方法,证明了时间特征的价值。
多模式方法还可以扩展到其他数据类型,例如音频或视频,以进一步提高社交机器人检测能力。例如,音频或视频分析可用于识别生成或分发深度伪造内容的机器人,这对在线平台构成重大威胁(Rössler 等人)。结合这些不同的信息源可以产生更准确、更强大的检测方法,更好地应对社交机器人不断发展的性质。
总之,社交机器人检测的多模式方法对于提高检测方法的效率具有很大的希望。通过结合不同类型的数据,例如文本、图像和网络特征,研究人员可以捕获数据中可能被单模态方法忽略的复杂而微妙的模式。这可以带来更准确、更强大的社交机器人检测技术,从而更有效地减轻社交机器人对在线平台的负面影响。
4.3. Collaborative and federated learning for detection
协作和联合学习方法可以实现多个组织或平台之间的联合学习和知识共享,同时保护数据隐私。这些方法允许在分布式数据源上训练模型,而不需要集中数据,这有助于克服隐私问题和数据共享限制。通过汇集不同组织的集体知识和资源,这些方法可以带来更准确、更强大的社交机器人检测技术,可以跨不同平台和领域部署。
联邦学习是一种分布式机器学习方法,使多个客户端能够协作训练共享模型,同时将数据保存在本地(McMahan 等,2016)。这种方法对于社交机器人检测特别有用,因为它允许基于各个组织的集体知识创建全局模型,而不会损害用户数据的隐私。在联合学习设置中,每个组织使用其数据训练本地模型,并仅与中央服务器共享模型更新(例如梯度),中央服务器聚合这些更新以改进全局模型。这个过程不断重复,直到收敛,从而形成一个受益于参与组织的不同经验的模型。
联邦学习的相关研究
多项研究探讨了联邦学习在社交机器人检测方面的潜力。例如,冯等人(2020)提出了一种联合学习方法,用于检测在线社交网络中的社交机器人。他们证明,他们的方法可以有效地检测机器人,同时保护数据隐私,即使在客户端之间存在非 IID(独立同分布)数据的情况下也是如此。同样,Nguyen 等人 (2021)提出了一种用于社交机器人检测的联邦学习框架,该框架利用分层注意力机制来捕获用户特征、内容特征和社交网络特征之间的关系。
协作学习
协作学习是分布式学习的另一种方法,它使多个组织能够在保护隐私的同时共同从数据中学习(Veale 等人,2018)。联邦学习依赖中央服务器来聚合模型更新,与之相反,协作学习技术通常依赖去中心化协议(例如八卦学习或点对点网络)来交换信息并相互学习。在没有可信中央服务器的情况下或者当组织想要保持对其数据和学习过程的控制时,协作学习特别有用。
最后,协作和联合学习方法在改善跨多个组织和平台的社交机器人检测同时保护数据隐私方面具有巨大潜力(Ezzeldin 等,2021)。通过在不需要集中数据的情况下实现联合学习和知识共享,这些方法可以帮助克服传统机器学习技术的局限性,并带来更准确、更强大的社交机器人检测方法。
4.4. Explainable AI and interpretability in detection techniques
可解释的人工智能 (XAI) 和可解释性在提高社交机器人检测技术的可信度、透明度和问责制方面发挥着至关重要的作用。通过了解人工智能模型的底层决策过程,利益相关者可以深入了解有助于检测社交机器人的因素,从而做出更明智的决策并促进检测方法的改进。此外,可解释性可以帮助解决对偏见和道德影响的担忧,这在在线平台和社交媒体的背景下尤为重要。
可解释的模型,例如决策树、线性模型和基于规则的系统,本质上是可解释的,因为它们的决策过程很容易被人类理解(Ribeiro, et al., 2016)。例如,决策树允许决策过程的可视化,节点表示特征分割,叶节点表示类别决策(Quinlan,1986)。在社交机器人检测的背景下,决策树可以帮助识别表明机器人行为的关键特征和决策规则(Ferrara 等,2016)。
可解释性技术
然而,许多最先进的机器学习模型,例如深度神经网络,由于其复杂的架构和大量的参数,通常被认为是黑盒模型(Adadi 和 Berrada,2018)。为了使这些模型更具可解释性,人们提出了几种技术,包括局部可解释模型不可知解释(LIME)和 SHapley 加性解释(SHAP)。
LIME 是一种解释技术,旨在为黑盒模型的个体预测提供局部解释(Ribeiro 等,2016)。它的工作原理是使用可解释的模型(例如线性模型或决策树)来近似模型的局部决策边界。在社交机器人检测中,LIME 可以帮助识别对于将特定用户分类为机器人或人类最重要的特征,从而提供对底层决策过程的洞察。
SHAP 是另一种解释技术,它基于合作博弈论,通过计算每个特征对给定实例的预测的贡献来为每个特征分配重要性值(Lundberg 和 Lee,2017)。通过计算每个特征的 Shapley 值,SHAP 可以在所有特征之间提供一致且公平的预测贡献分配。在社交机器人检测的背景下,SHAP 可以帮助发现有助于检测机器人的最有影响力的特征,从而促进对检测方法的理解和改进。
总之,可解释的人工智能和可解释性对于提高社交机器人检测技术的可信度、透明度和问责制至关重要。通过提供对人工智能模型决策过程的洞察,利益相关者可以做出更明智的决策,改进检测方法,并解决对偏见和道德影响的担忧。未来的研究应侧重于开发更多可解释和可解释的社交机器人检测模型,并探索可解释性和模型性能之间的相互作用。
4.5. Combining multiple detection techniques
有效检测社交机器人需要一种综合方法,考虑这些恶意实体采用的不同行为和策略。集成多种检测技术可以带来更准确、更稳健的结果,解决更广泛的机器人特征和行为。在本节中,我们将探讨各种检测技术及其集成,同时参考相关研究论文。
机器学习与自然语言处理技术集成
社交机器人检测中广泛采用的一种方法是机器学习和自然语言处理技术的结合。通过结合监督和无监督学习算法以及自然语言处理方法,研究人员可以分析社交机器人生成的内容,并识别将其与人类用户区分开来的模式和特征(Ferrara 等,2016)。例如,杨等人(2019)提出了一种基于深度学习的方法,结合卷积神经网络(CNN)和递归神经网络(RNN)来分析机器人检测的内容和特征,实现高精度和召回率。
网络结构与用户信息集成,时间动态与发文集成
·网络分析是检测社交机器人的另一项重要技术,因为它侧重于分析机器人帐户的社交网络结构和交互模式。通过调查这些模式,研究人员可以识别异常行为并发现协调的活动,例如 astroturfing 活动和虚假信息活动(Ratkiewicz 等,2011)。时间分析也被证明是揭示社交机器人行为的宝贵工具。通过研究机器人活动的时间动态,例如发布频率和互动时间,研究人员可以识别可能表明自动化行为的异常模式(Chavoshi 等,2016)。 Chavoshi 等人在他们的研究中 (2016) 通过检查用户活动和内容生成之间扭曲的相关性,应用时间分析来检测 Twitter 上的社交机器人。他们的方法成功地识别了具有高精度和召回率的机器人,证明了时间分析在机器人检测中的有效性。
跨平台框架
跨平台分析是社交机器人检测的另一种有前景的技术,因为它涉及检查多个社交媒体平台上可疑机器人帐户的行为。通过检测协调活动并提高检测技术的通用性,研究人员可以开发更有效、适应性更强的机器人检测方法(Zhou 和 Zafarani,2018)。舒,等人。 (2018)引入了一个名为 FakeNewsNet 的跨平台框架,用于研究假新闻的传播以及社交机器人在其传播中的作用。通过收集大量被标记为虚假或真实的新闻文章数据集,并分析跨平台的社交机器人的活动,他们能够识别虚假新闻传播的模式以及参与传播虚假新闻的机器人的特征。
总之,结合多种检测技术,包括机器学习和自然语言处理、网络分析、时间分析和跨平台分析,可以带来更准确、更稳健的社交机器人检测结果。
4.6. Constantly updating and fine-tuning models
为了有效应对社交机器人不断发展的格局,在检测模型的开发和部署中保持积极主动的方法至关重要。这需要不断更新和微调模型,以响应机器人操作员不断变化的战术和策略。在本节中,我们参考相关研究论文,深入探讨模型维护和改进的各个方面。
收集新的数据集很重要
确保用于机器学习算法的训练数据是最新的并代表当前的机器人环境对于维持检测模型的有效性至关重要。这可能涉及收集新数据、重新标记现有数据或合并外部数据源,例如来自其他研究人员或组织的标记数据集(Ruchansky 等,2017)。例如,克雷西等人 (2017) 证明了使用多样化的最新数据集来训练和评估社交机器人检测模型的重要性。他们对多个数据集进行了系统比较,发现在较旧的数据集上训练的模型的性能明显低于在较新的和多样化的数据上训练的模型的性能。
模型适应平台变化很重要
适应平台变化是维护检测模型的另一个重要方面。社交媒体平台不断发展,API 或用户界面的更新可能会影响某些功能的可用性或引入新的机器人行为模式。监控这些变化并相应地调整检测技术可以帮助确保检测模型的持续有效性(Gorwa 等人,2020)。例如,Echeverria 和 Zhou(2017)研究了 Twitter API 速率限制对社交机器人检测的影响,发现施加的限制降低了某些检测功能的准确性,强调需要调整模型以适应平台变化。
微调模型参数
微调模型参数是维持检测模型有效性的重要组成部分。定期评估这些模型的性能并调整其参数以优化准确性、召回率和其他相关指标可以改善结果。这可能涉及使用不同的特征集、算法或参数值进行实验,并进行交叉验证以评估模型的稳健性。 Kudugunta 和 Ferrara (2018) 引入了一种基于上下文 LSTM 网络的深度学习模型来检测 Twitter 上的社交机器人。他们对模型的各种超参数进行了微调,并通过交叉验证评估了其性能,证明了参数优化对于获得最佳结果的重要性。
纳入反馈循环
纳入反馈循环是维护检测模型的另一个重要实践。建立反馈机制来收集用户对机器人检测结果准确性的输入可以帮助完善模型并提高其性能。这可能涉及众包、专家验证或其他形式的用户参与,以收集见解并评估检测技术的有效性。例如,杨等人。 (2022) 开发了一种名为 Botometer 的系统,它将基于机器学习的机器人检测与用户反馈相结合,以提高其性能。该系统允许用户报告误报和漏报,并且输入用于微调底层检测模型。
总之,不断更新和微调社交机器人检测模型对于保持领先于社交机器人不断发展的格局至关重要。通过采用更新训练数据、适应平台变化、微调模型参数以及纳入反馈循环等实践,研究人员和从业者可以开发更有效、更有弹性的检测技术,更好地保护在线信息生态系统。
4.7. Generative agents as source of synthetic data
社交机器人检测领域可以极大地受益于利用合成数据,尤其是使用可信的人类行为代理生成的数据。我们讨论了生成代理(模拟可信人类行为的计算软件代理)的潜力,通过提供基于大型语言模型的丰富的合成数据源来增强社交机器人检测技术。
最近的文献中对生成代理进行了探索,旨在通过以自然语言存储代理经验的完整记录,将记忆随着时间的推移合成更高层次的反射,并动态检索它们来规划行为,从而表现出类人行为。 Park 等人,2023)。这些代理可以产生可信的个人和突发社交行为(见图 1),使它们成为训练和评估社交机器人检测模型的宝贵合成数据来源。
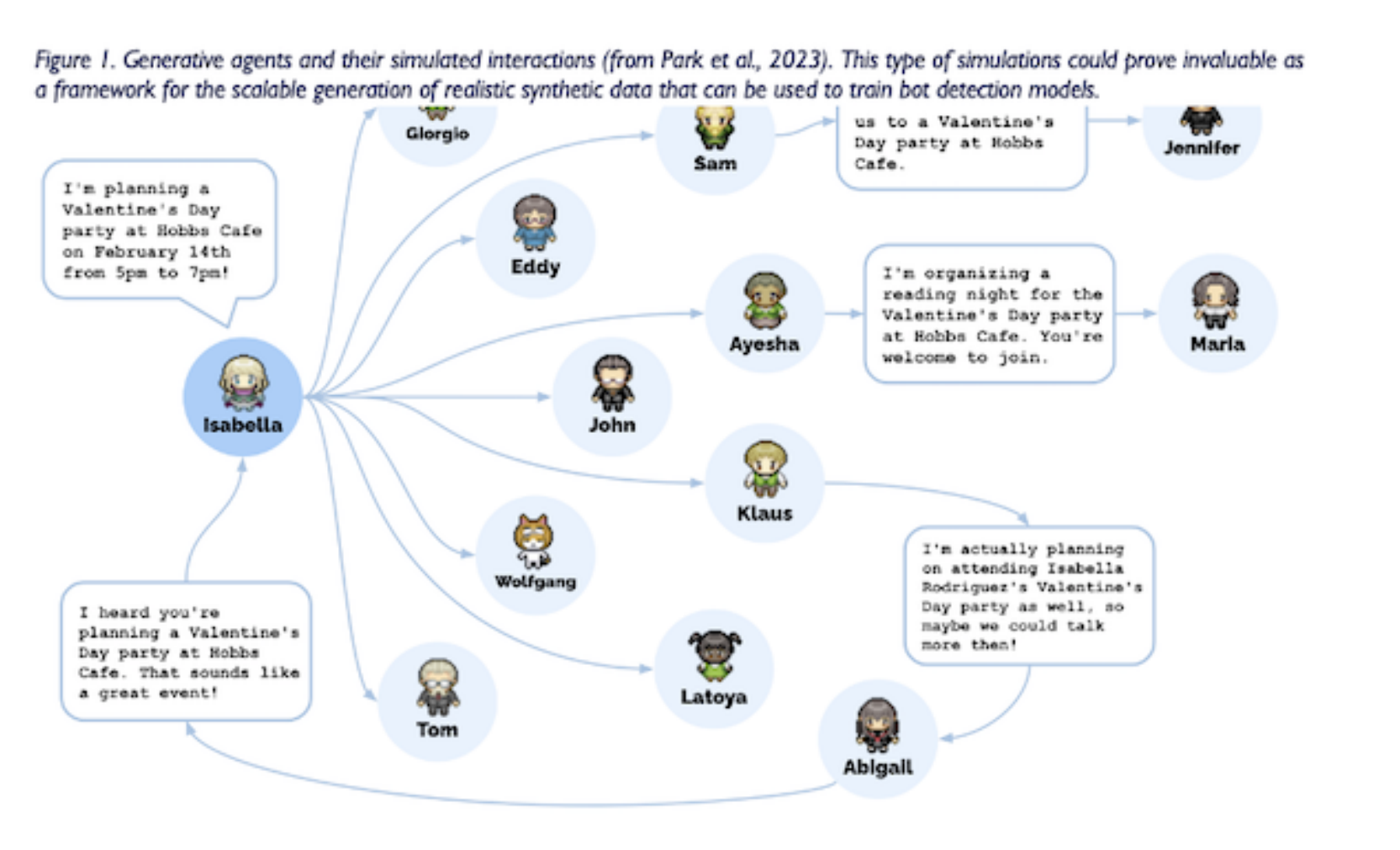
通过将大型语言模型与计算交互式代理融合,研究人员可以生成大量真实且多样化的数据,这些数据可用于训练更强大、更准确的检测模型。生成代理创建的合成数据可用于模拟各种场景和通信模式,使研究人员能够开发可以在不同环境中很好地推广的检测模型。
此外,使用生成代理创建的合成数据可以帮助解决社交机器人检测中面临的一些挑战,例如标记数据的稀缺性以及机器人生成内容的不断发展的性质。由于生成代理可以被控制和操纵,研究人员可以大规模生成标记数据,有效减少对手动注释和数据收集过程的依赖。
此外,生成代理可以随着时间的推移进行更新和微调,以模仿机器人生成内容中观察到的最新趋势和模式,确保合成数据对于训练和评估检测模型保持相关性和有用性。这种适应性对于与日益复杂的社交机器人的持续战斗至关重要。
总之,生成代理和合成数据的使用为增强社交机器人检测技术提供了有希望的机会。通过利用大型语言模型和计算代理来生成真实且多样化的数据,研究人员可以开发更强大、更准确的检测模型,这些模型能够更好地识别和减轻恶意社交机器人的影响。
5. Case studies: Social bot detection in real-world applications
在本节中,我们将介绍一系列案例研究,说明社交机器人检测技术在各个领域的实际应用。这些例子证明了社交机器人检测在解决选举干扰和政治操纵、虚假信息活动和假新闻、金融诈骗和加密货币操纵等关键问题方面的重要性。通过研究这些案例研究,我们的目的是阐明社交机器人检测的实际影响以及该领域持续研究和开发的重要性。
5.1. Election interference and political manipulation
操纵舆论和干扰选举
2016 年美国总统选举
社交机器人被广泛用于操纵舆论和干扰选举,因为它们可以轻松传播政治宣传、虚假信息和两极分化内容。 2016 年美国总统选举是一个众所周知的例子,社交机器人在放大和传播政治偏见内容方面发挥了重要作用,影响了选举的动态(Ferrara,2015;Bessi 和 Ferrara,2016;Badawy 等人, 2018;Chang 等人,2021)。研究人员开发了各种专门针对政治机器人的社交机器人检测技术,旨在最大程度地减少其对公共话语和民主进程的影响(Gorwa 等人,2020 年;Howard 和 Kolanyi,2016 年)。
Bessi 和 Ferrara(2016)对 2016 年美国总统大选进行了深入分析,发现社交机器人负责在社交媒体平台(尤其是 Twitter)上生成和传播很大一部分与选举相关的内容。他们观察到,机器人产生了大约五分之一的围绕选举的整个对话,并且对特定的政治话题和候选人有强烈的偏见。通过使用机器学习算法根据行为模式识别机器人帐户,贝西和费拉拉能够发现机器人的广泛存在及其对选举的潜在影响。这些发现后来与俄罗斯领导的一项干预美国大选的国家资助行动有关(Badawy 等人,2018 年;Addawood 等人,2019 年;Luceri 等人,2019 年)。
英国 2016 年脱欧公投
Howard 和 Kolanyi(2016)的另一项研究调查了社交机器人在英国 2016 年脱欧公投中的作用。他们发现,机器人贡献了与公投相关的 Twitter 流量的很大一部分,支持脱欧的机器人比支持留欧的机器人更活跃。研究人员采用监督机器学习技术,利用推文频率、转发率和内容相似度等特征对机器人帐户进行分类。他们的发现强调了社交机器人在重大政治事件中塑造公众舆论的潜在影响。
2017 年加泰罗尼亚独立公投
斯特拉等人 (2018) 提出了一种在 Twitter 上的政治讨论背景下检测社交机器人的方法,重点关注 2017 年加泰罗尼亚独立公投。他们结合使用了无监督学习技术(例如聚类和降维)来识别相似用户组并根据他们的行为模式检测机器人。通过分析这些机器人产生的内容,Stella 等人。能够发现协调一致的虚假信息活动,并深入了解机器人操作员在选举期间采用的策略。
综上所述,社交机器人在各国操纵舆论、干扰选举方面发挥了重要作用。关于检测和理解政治机器人行为的研究为了解其策略及其对民主进程的潜在影响提供了宝贵的见解。通过开发有效的检测技术和对策,可以减轻社交机器人对公共话语的影响并保护选举过程的完整性。
5.2. Detection of disinformation campaigns by social bots
传播虚假信息和假新闻
通过社交媒体平台传播虚假信息和假新闻已成为一个重大问题,因为它可能导致错误信息、加剧两极分化以及降低对媒体和机构的信任。社交机器人可以通过快速传播虚假信息并制造对特定叙述进行广泛支持的假象来加剧这一问题(Ferrara,2017;Shao 等人,2018)。检测参与虚假信息活动的社交机器人对于减少虚假新闻的传播和维护在线信息的完整性至关重要。
传播政治偏见内容的自动帐户
我们分析了社交机器人在法国总统选举期间塑造公众舆论的作用(Ferrara,2017)。我们对虚假信息传播(尤其是在 Twitter 上)的调查发现,大量存在传播政治偏见内容的自动帐户。该研究强调了社交机器人在宣扬扭曲叙事、操纵公共话语和两极分化在线对话方面的广泛使用。
放大低可信度内容
邵,等人 (2018) 对 2016 年美国总统大选期间和之后社交机器人在 Twitter 上传播低可信度内容中的作用进行了一项研究。他们发现社交机器人在放大低可信度内容方面发挥了重要作用,有些机器人甚至以协调的方式运作。通过采用机器学习技术,Shao 等人。我们能够检测和描述参与传播虚假信息的机器人的行为,为他们的策略和对公共话语的潜在影响提供有价值的见解。
检测假新闻和导致其传播的社交机器人
Ruchansky 等人的一项研究中 (2017),作者提出了一种称为 CSI(捕获、评分和集成)的混合深度学习模型,用于检测假新闻和导致其传播的社交机器人。通过利用内容和社交网络结构的特征,他们的模型在检测假新闻和传播假新闻的机器人方面实现了高精度,展示了基于人工智能的技术在应对虚假信息挑战方面的潜力。
社交机器人的活动虚假信息比真实信息传播得更快、更广泛
Vosoughi 等人在他们的研究中(2018)研究了真实和虚假新闻在网上的传播,发现虚假信息比真实信息传播得更快、更广泛,部分原因是社交机器人的活动。他们使用各种机器学习技术来模拟新闻传播并识别区分真假信息的特征。他们的发现强调了有效的社交机器人检测和对策以限制虚假信息传播的必要性。
开发社交机器人检测技术( 解决虚假信息和虚假新闻)
解决虚假信息和虚假新闻问题需要采取多方面的方法,包括开发社交机器人检测技术,该技术可以识别和减轻参与传播虚假信息的机器人的活动。通过利用先进的机器学习和自然语言处理方法,研究人员可以更好地了解虚假信息活动所采用的战略和策略,并设计干预措施来保护在线信息源的完整性。
5.3. Financial scams and cryptocurrency manipulation
研究社交机器人如何解决这些问题的技术细节
社交媒体平台上社交机器人的激增导致金融诈骗和加密货币操纵增加。在本节中,我们将深入研究社交机器人如何解决这些问题的技术细节,讨论它们的策略和潜在的检测方法。我们还参考了相关已发表的论文,以深入了解这一日益严重的问题。
社交机器人可以被编程来执行各种金融诈骗,例如拉高抛售计划、网络钓鱼以及传播虚假信息以操纵股票价格或加密货币价值。这些机器人经常模仿人类行为,并能以惊人的速度传播错误信息,这使得它们在欺骗毫无戒心的用户方面特别有效。
在加密货币领域,社交机器人被发现通过影响公众情绪来操纵市场。通过生成大量宣传某些加密货币的虚假消息或传播有关市场趋势的虚假信息,这些机器人可以创造人为需求,从而推高目标加密货币的价值。一旦价值达到预定阈值,机器人或其控制者就可以出售其持有的资产,导致加密货币价值迅速下跌,并使其他投资者蒙受损失(Vasek 和 Moore,2015)。
检测涉及金融诈骗和加密货币操纵的社交机器人可能具有挑战性,因为它们能够适应自己的行为并逃避传统的检测方法。然而,一些研究提出了解决这个问题的创新技术。例如,Nizzoli 和合作者 (2020) 开发了一个数据驱动的框架来识别加密货币市场中的拉高和抛售计划。通过收集和分析来自 Twitter、Telegram 和 Discord 等平台的数百万条消息,他们的模型能够揭示两种机制(拉高抛售和庞氏骗局),揭示与涉及加密货币欺诈的可疑机器人账户相关的欺骗活动。
Nghiem 等人的另一项研究 (2018) 提出了一种在 Twitter 上检测与加密货币相关的社交机器人的方法。作者结合使用网络分析、内容分析和机器学习技术来识别正在宣传或传播有关加密货币的虚假信息的机器人帐户。事实证明,这种多方面的方法可以有效地检测参与加密货币操纵的机器人,即使存在复杂的规避策略。
为了减轻社交机器人在金融诈骗和加密货币操纵中的影响,研究人员开发新的检测技术来适应这些机器人所采用的不断发展的策略至关重要。潜在的研究方向包括深度学习和强化学习算法的结合,以及开发可以分析文本、图像和视频等多模态数据源的模型(Ferrara,2022)。
6. Conclusions
随着恶意机器人继续影响在线信息生态系统并在各个领域造成重大问题,社交机器人检测已成为一个日益重要的研究领域。在本结论部分,我们回顾了社交机器人检测中的挑战和机遇,讨论了 ChatGPT 时代检测的未来,并提出了最终的想法和潜在的研究方向。
6.1. Recap of challenges and opportunities in social bot detection
在本文中,我们探讨了社交机器人检测领域的各种挑战和机遇,以及先进的人工智能生成的聊天机器人(例如 ChatGPT)对该领域的影响。在整个讨论过程中,我们参考了大量相关已发表的论文,为该主题提供了全面且技术上详细的观点。
人工智能生成的内容日益复杂(对抗性攻击和规避策略,可扩展和实时解决方案,道德隐私)
社交机器人检测面临着几个挑战。一项重大挑战是人工智能生成的内容日益复杂,这使得区分人类用户和社交机器人变得更加困难。此外,对抗性攻击和规避策略使检测过程进一步复杂化,因为机器人变得更加擅长规避传统检测方法。鉴于社交媒体平台的巨大规模和动态性质,对可扩展和实时检测解决方案的需求是另一个挑战。最后,与社交机器人检测相关的道德考虑和隐私问题带来了独特的挑战,需要解决这些挑战,以维护公众信任并遵守法律和道德框架。
迁移学习和无监督学习,多模式检测方法,协作和联合学习,可解释的人工智能
尽管存在这些挑战,但改进社交机器人检测技术仍然存在许多机会。迁移学习和无监督学习提供了有前途的方法来利用现有知识并发现机器人行为的潜在模式。多模式检测方法可以利用不同数据源和特征的集成,从而实现更稳健和准确的检测。检测的协作和联合学习有助于促进不同组织和平台之间的合作,提高检测方法的整体有效性。最后,将可解释的人工智能和可解释性结合到检测技术中可以帮助建立信任,并为这些模型的底层决策过程提供有价值的见解。
6.2. The future of social bot detection in the age of ChatGPT
随着我们进入 ChatGPT 和其他高级语言模型的时代,社交机器人检测的未来将需要适应人工智能生成内容的日益复杂性。面对人工智能生成的聊天机器人的快速发展,研究人员和从业者必须保持警惕,这些机器人不断模糊了人类和机器生成内容之间的区别(Radford 等人,2019)。本节讨论社交机器人检测的未来,重点关注先进的人工智能生成的聊天机器人的影响以及检测方法相应发展的潜在途径。
为了有效抵消人工智能生成的聊天机器人的改进能力,研究人员必须探索补充现有技术的新方法和途径。一个潜在的方向是开发更复杂的机器学习模型,该模型可以解释 ChatGPT 等高级聊天机器人生成的内容中的微妙之处和细微差别。这些模型不仅应该能够识别语言特征,还应该能够识别与机器人生成的内容相关的上下文和行为方面。
迁移学习和对抗训练(Goodfellow 等,2014)为提高社交机器人检测模型的稳健性和泛化性提供了有希望的途径。迁移学习可以帮助利用预先训练的模型和其他领域的知识来增强机器人检测能力。另一方面,对抗性训练可以在模型训练过程中引入对抗性示例,从而提高模型对机器人使用的规避技术的适应能力。
将上下文和多模态信息纳入检测方法是增强机器人检测技术能力的另一个潜在途径。通过不仅分析文本内容,还分析图像、视频和其他媒体类型,并考虑用户行为和网络结构,研究人员可以开发更全面、更强大的检测模型,以解释更广泛的机器人特征和行为。
随着人工智能生成的聊天机器人不断发展,考虑社交机器人检测的道德影响至关重要。有必要制定解决该问题的道德、法律和社会层面的指导方针和政策,以确保检测方法尊重用户隐私并遵守法律框架。
总之,ChatGPT 和其他高级语言模型时代的社交机器人检测的未来将需要能够适应人工智能生成内容快速变化的格局的创新技术。通过探索新的方法论和方法、促进跨学科合作以及解决 ChatGPT 时代的社交机器人检测:挑战和机遇、检测的伦理影响,研究人员可以为更安全、更值得信赖的在线环境做出贡献。
6.3. Final remarks and potential research directions
在本文中,我们探讨了社交机器人检测中的挑战和机遇,重点关注先进人工智能生成的聊天机器人(例如 ChatGPT)的影响。在最后一节中,我们概述了潜在的研究方向,这些方向可以帮助推进社交机器人检测领域,并有助于开发更有效、更可靠的检测技术。
人机协作:随着人工智能生成的聊天机器人变得越来越复杂,有必要考虑人机协作在社交机器人检测中的潜力。主题专业知识可以帮助指导和完善检测模型,而人工智能可以提供分析大量数据所需的计算能力。研究人类与人工智能协作的新范式,例如主动学习和混合主动系统,可以产生有价值的见解并改进社交机器人检测性能。
跨平台检测:大多数关于社交机器人检测的研究都集中在特定平台上,例如 Twitter 或 Facebook。然而,随着新的社交媒体平台不断出现,开发可以跨平台推广的检测方法至关重要。这将涉及跨平台数据集的创建以及可以考虑平台特定功能和用户行为的模型的开发。
机器人的时间动态:许多现有的检测方法是静态的,侧重于机器人行为的单个快照。然而,机器人可能会随着时间的推移而改变其行为,无论是作为其策略的一部分还是为了响应检测工作(Luceri 等人,2019 年;Luceri 等人,2020 年)。未来的研究应该探索社交机器人的时间动态,结合时间序列分析和其他技术来跟踪和检测不断变化的机器人行为(Pozzana 和 Ferrara,2020)。
反事实推理:随着人工智能生成的聊天机器人的改进,它们可能能够生成密切模仿人类行为的内容。在这种情况下,探索反事实推理作为检测机器人的手段可能会有所帮助。通过考虑机器人在每种情况下与人类用户相比会做什么,研究人员也许能够开发新的、更有效的检测技术。
低资源环境:研究和开发低资源语言的社交机器人检测新技术,利用跨语言迁移学习、无监督学习和数据增强方法来提高检测能力,可以支持代表性不足的社区对抗恶意社交机器人。
多模态检测:探索社交机器人检测框架中文本、图像、音频和视频等多种数据模态的集成,以增强检测算法的鲁棒性和准确性,可以解决单模态方法在识别复杂和复杂的数据方面的局限性。复杂的社交机器人。
隐私保护检测技术:随着对用户隐私和数据保护的日益关注,开发可以在隐私保护框架内运行的检测技术至关重要。可以采用差分隐私和联合学习等技术来确保检测方法不会损害用户隐私,同时仍能有效识别恶意机器人。
总之,社交机器人检测领域为研究人员提供了大量的机会来探索和开发创新技术,以应对人工智能生成的聊天机器人日益复杂的问题。通过解决这些潜在的研究方向并促进研究人员、从业者和政策制定者之间的合作,我们可以努力为所有用户提供更安全、值得信赖的在线环境。