源码地址:https://github.com/kingglory/langchain-chinese-learning/tree/main
基础功能
LLM 调用
- 支持多种模型接口,比如 OpenAI、Hugging Face、AzureOpenAI …
- Fake LLM,用于测试
- 缓存的支持,比如 in-mem(内存)、SQLite、Redis、SQL
- 用量记录
- 支持流模式(就是一个字一个字的返回,类似打字效果)
Prompt管理,支持各种自定义模板
拥有大量的文档加载器,比如 Email、Markdown、PDF、Youtube …
对索引的支持
- 文档分割器
- 向量化
- 对接向量存储与搜索,比如 Chroma、Pinecone、Qdrand
Chains
- LLMChain
- 各种工具Chain
- LangChainHub
必知概念
Loader 加载器
顾名思义,这个就是从指定源进行加载数据的。比如:文件夹 DirectoryLoader、Azure 存储 AzureBlobStorageContainerLoader、CSV文件 CSVLoader、印象笔记 EverNoteLoader、Google网盘 GoogleDriveLoader、任意的网页 UnstructuredHTMLLoader、PDF PyPDFLoader、S3 S3DirectoryLoader/S3FileLoader、
Youtube YoutubeLoader 等等,上面只是简单的进行列举了几个,官方提供了超级的多的加载器供你使用。
- https://python.langchain.com/en/latest/modules/indexes/document_loaders.html
Document 文档
当使用loader加载器读取到数据源后,数据源需要转换成 Document 对象后,后续才能进行使用。
Text Spltters 文本分割
顾名思义,文本分割就是用来分割文本的。为什么需要分割文本?因为我们每次不管是做把文本当作 prompt 发给 openai api ,还是还是使用 openai api embedding 功能都是有字符限制的。
比如我们将一份300页的 pdf 发给 openai api,让他进行总结,他肯定会报超过最大 Token 错。所以这里就需要使用文本分割器去分割我们 loader 进来的 Document。
Vectorstores 向量数据库
因为数据相关性搜索其实是向量运算。所以,不管我们是使用 openai api embedding 功能还是直接通过向量数据库直接查询,都需要将我们的加载进来的数据 Document 进行向量化,才能进行向量运算搜索。转换成向量也很简单,只需要我们把数据存储到对应的向量数据库中即可完成向量的转换。
官方也提供了很多的向量数据库供我们使用。
- https://python.langchain.com/en/latest/modules/indexes/vectorstores.html
Chain 链
我们可以把 Chain 理解为任务。一个 Chain 就是一个任务,当然也可以像链条一样,一个一个的执行多个链。
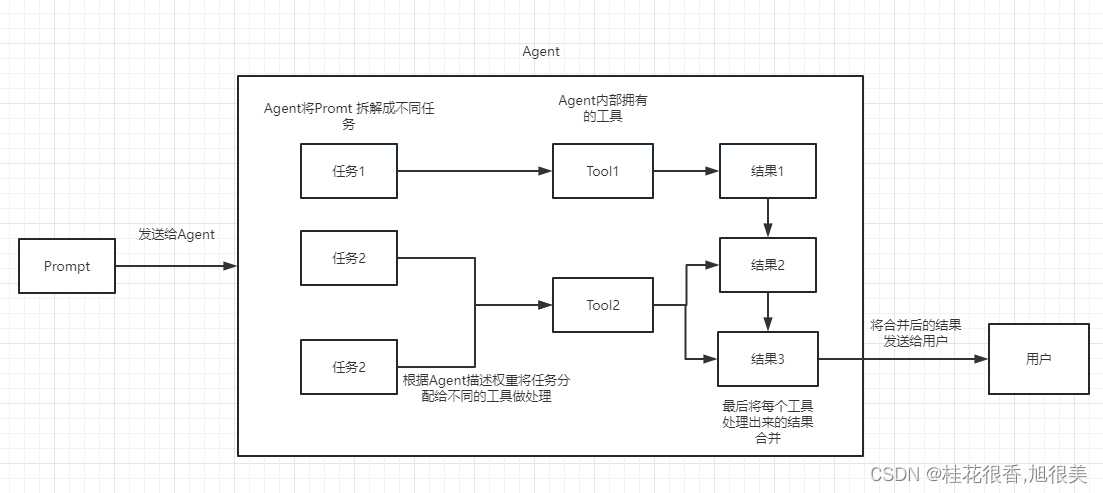
Agent 代理
我们可以简单的理解为他可以动态的帮我们选择和调用chain或者已有的工具。
执行过程可以参考下面这张图:
Embedding
用于衡量文本的相关性。这个也是 OpenAI API 能实现构建自己知识库的关键所在。
他相比 fine-tuning 最大的优势就是,不用进行训练,并且可以实时添加新的内容,而不用加一次新的内容就训练一次,并且各方面成本要比 fine-tuning 低很多。
- 具体比较和选择可以参考这个视频:https://www.youtube.com/watch?v=9qq6HTr7Ocw
install packages
!pip install langchain
!pip install tiktoken
!pip install openai
!pip install transformers
!pip install google-search-results
!pip install CallbackManager
!pip install unstructured
!pip install chromadb
!pip install pinecone-client
!pip install youtube-transcript-api
!pip install pytube
完成一次问答
import os
os.environ["OPENAI_API_KEY"] = 'your api keys'
from langchain.llms import OpenAIllm = OpenAI(model_name="text-davinci-003",max_tokens=1024)
llm("怎么评价langchain和LlamaIndex")
'?\n\nLangchain和LlamaIndex是两种开源的区块链技术,它们都可以用来构建公共区块链网络。Langchain是一种智能合约的区块链技术,它可以在区块链上执行复杂的业务逻辑,能够支持多种货币和资产类型的交易;LlamaIndex是一个面向数据和分析的区块链技术,它可以支持更多有效的数据管理方式,支持更快的数据分析和报表生成。总的来说,Langchain和LlamaIndex都是一种有用的区块链技术,可以用来构建公共区块链网络,它们可以帮助企业实现更有效的数据管理和更快的分析报表生成。'
通过 Google 搜索并返回答案
接下来,我们就来搞点有意思的。我们来让我们的 OpenAI api 联网搜索,并返回答案给我们。
这里我们需要借助 Serpapi 来进行实现,Serpapi 提供了 google 搜索的 api 接口。
首先需要我们到 Serpapi 官网上注册一个用户,https://serpapi.com/ 并复制他给我们生成 api key。
然后我们需要像上面的 openai api key 一样设置到环境变量里面去。
os.environ["SERPAPI_API_KEY"] = 'your api key'
import langchain
print(dir(langchain.llms))
['AI21', 'AlephAlpha', 'Anthropic', 'Anyscale', 'AzureOpenAI', 'Banana', 'BaseLLM', 'Beam', 'Bedrock', 'CTransformers', 'CerebriumAI', 'Cohere', 'Databricks', 'DeepInfra', 'Dict', 'FakeListLLM', 'ForefrontAI', 'GPT4All', 'GooglePalm', 'GooseAI', 'HuggingFaceEndpoint', 'HuggingFaceHub', 'HuggingFacePipeline', 'HuggingFaceTextGenInference', 'HumanInputLLM', 'LlamaCpp', 'Modal', 'MosaicML', 'NLPCloud', 'OpenAI', 'OpenAIChat', 'OpenLM', 'Petals', 'PipelineAI', 'PredictionGuard', 'PromptLayerOpenAI', 'PromptLayerOpenAIChat', 'RWKV', 'Replicate', 'SagemakerEndpoint', 'SelfHostedHuggingFaceLLM', 'SelfHostedPipeline', 'StochasticAI', 'Type', 'VertexAI', 'Writer', '__all__', '__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__', 'ai21', 'aleph_alpha', 'anthropic', 'anyscale', 'bananadev', 'base', 'beam', 'bedrock', 'cerebriumai', 'cohere', 'ctransformers', 'databricks', 'deepinfra', 'fake', 'forefrontai', 'google_palm', 'gooseai', 'gpt4all', 'huggingface_endpoint', 'huggingface_hub', 'huggingface_pipeline', 'huggingface_text_gen_inference', 'human', 'llamacpp', 'loading', 'modal', 'mosaicml', 'nlpcloud', 'openai', 'openlm', 'petals', 'pipelineai', 'predictionguard', 'promptlayer_openai', 'replicate', 'rwkv', 'sagemaker_endpoint', 'self_hosted', 'self_hosted_hugging_face', 'stochasticai', 'type_to_cls_dict', 'utils', 'vertexai', 'writer']
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.llms import OpenAI
from langchain.agents import AgentType# 加载 OpenAI 模型
llm = OpenAI(temperature=0,max_tokens=2048) # 加载 serpapi 工具
tools = load_tools(["serpapi"])# 如果搜索完想再计算一下可以这么写
# tools = load_tools(['serpapi', 'llm-math'], llm=llm)# 如果搜索完想再让他再用python的print做点简单的计算,可以这样写
# tools=load_tools(["serpapi","python_repl"])# 工具加载后都需要初始化,verbose 参数为 True,会打印全部的执行详情
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)# 运行 agent
agent.run("What's the date today? What great events have taken place today in history?")
[1m> Entering new AgentExecutor chain...[0m
[32;1m[1;3m I should look up the current date and then search for historical events that have taken place on that day.
Action: Search
Action Input: Current date[0m
Observation: [36;1m[1;3mToday's current date and time with time zone and date picker: Select locale. en-US. Friday, June 2, 2023. 5:00:05 PM. PST8PDT (GMT-7).[0m
Thought:[32;1m[1;3m I should now search for historical events that have taken place on this day.
Action: Search
Action Input: Historical events June 2[0m
Observation: [36;1m[1;3mOn this day - June 2[0m
Thought:[32;1m[1;3m I now know the historical events that have taken place on this day.
Final Answer: Today is June 2, 2023. On this day in history, the Battle of Midway began in 1942, the first successful transatlantic flight took place in 1919, and the first successful powered flight took place in 1903.[0m[1m> Finished chain.[0m'Today is June 2, 2023. On this day in history, the Battle of Midway began in 1942, the first successful transatlantic flight took place in 1919, and the first successful powered flight took place in 1903.'
我们可以看到,他正确的返回了日期(有时差),并且返回了历史上的今天。
在 chain 和 agent 对象上都会有 verbose 这个参数,这个是个非常有用的参数,开启他后我们可以看到完整的 chain 执行过程。
可以在上面返回的结果看到,他将我们的问题拆分成了几个步骤,然后一步一步得到最终的答案。
关于agent type 几个选项的含义(理解不了也不会影响下面的学习,用多了自然理解了):
-
zero-shot-react-description: 根据工具的描述和请求内容的来决定使用哪个工具(最常用)
-
react-docstore: 使用 ReAct 框架和 docstore 交互, 使用Search 和Lookup 工具, 前者用来搜, 后者寻找term, 举例: Wipipedia 工具
-
self-ask-with-search 此代理只使用一个工具: Intermediate Answer, 它会为问题寻找事实答案(指的非 gpt 生成的答案, 而是在网络中,文本中已存在的), 如 Google search API 工具
-
conversational-react-description: 为会话设置而设计的代理, 它的prompt会被设计的具有会话性, 且还是会使用 ReAct 框架来决定使用来个工具, 并且将过往的会话交互存入内存
- reAct 介绍可以看这个:https://arxiv.org/pdf/2210.03629.pdf
- LLM 的 ReAct 模式的 Python 实现: https://til.simonwillison.net/llms/python-react-pattern
- agent type 官方解释:
https://python.langchain.com/en/latest/modules/agents/agents/agent_types.html?highlight=zero-shot-react-description
有一点要说明的是,这个 serpapi 貌似对中文不是很友好,所以提问的 prompt 建议使用英文。
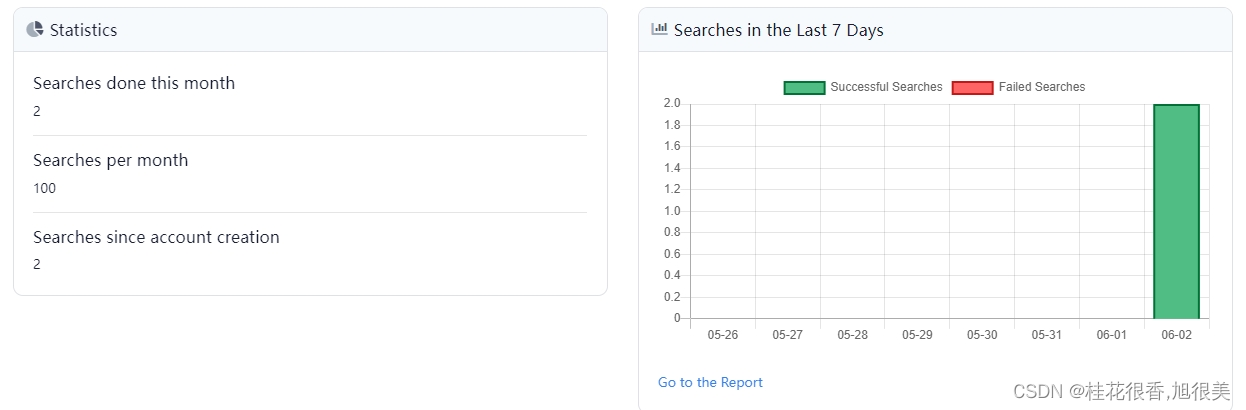
上面那个任务一共搜索了两次( serpapi 一个月免费搜索100次)
对超长文本进行总结
假如我们想要用 openai api 对一个段文本进行总结,我们通常的做法就是直接发给 api 让他总结。但是如果文本超过了 api 最大的 token 限制就会报错。
这时,我们一般会进行对文章进行分段,比如通过 tiktoken 计算并分割,然后将各段发送给 api 进行总结,最后将各段的总结再进行一个全部的总结。
如果,你用是 LangChain,他很好的帮我们处理了这个过程,使得我们编写代码变的非常简单。
from langchain.document_loaders import UnstructuredFileLoader
from langchain.chains.summarize import load_summarize_chain
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain import OpenAI# 导入文本
loader = UnstructuredFileLoader("/content/langchain_data/lg_test.txt")
# 将文本转成 Document 对象
document = loader.load()
print(f'documents:{len(document)}')# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500,chunk_overlap = 0
)# 切分文本
split_documents = text_splitter.split_documents(document)
print(f'documents:{len(split_documents)}')# 加载 llm 模型
llm = OpenAI(model_name="text-davinci-003", max_tokens=1500)# 创建总结链
chain = load_summarize_chain(llm, chain_type="refine", verbose=True)# 执行总结链,(为了快速演示,只总结前5段)
chain.run(split_documents[:5])
documents:1
documents:331[1m> Entering new RefineDocumentsChain chain...[0m[1m> Entering new LLMChain chain...[0m
Prompt after formatting:
[32;1m[1;3mWrite a concise summary of the following:"声明:本书为爱奇电子书(www.i7wu.cn)的用户上传至其在本站的存储空间,本站只提供TXT全集电子书存储服务以及免费下载服务,以下作品内容之版权与本站无任何关系。用户上传之内容开始《地藏心经》作者:铸剑师无名正文第一第十五章 天下势,渡江(一)“渝州陆家?!”虽然原本的那个秦逸,每日只知道苦读诗书,从未与商贾们打过交道,但是渝州陆家的名声,他还是知道。陆家三代为官,官至两江总督,五代经商,百年经营,家私何止千万,直至今朝,俨然已是江南一等士族大户。渝州陆氏以皮货起家,乃是西北之地数得上号的商户,西北之地所产的皮货,有三成经他们之手卖往江南。若只是如此,陆氏也不过是一头肥硕的羔羊,只待他人宰杀。"CONCISE SUMMARY:[0m[1m> Finished chain.[0m[1m> Entering new LLMChain chain...[0m
Prompt after formatting:
[32;1m[1;3mYour job is to produce a final summary
We have provided an existing summary up to a certain point:
爱奇电子书(www.i7wu.cn)提供TXT全集电子书存储服务和免费下载服务,用户上传的《地藏心经》由铸剑师无名所作,故事讲述了渝州陆家家族的来历和发展史,以及他们以皮货起家,成为西北地区的商户。
We have the opportunity to refine the existing summary(only if needed) with some more context below.
------------
陆氏三代家主都极具雄韬伟略,以千金买官,以万金开路,更是在蛮夷南侵之时,倾尽家资招兵买马,拒十万蛮夷铁骑于侯关外,短短三年间,便一手扶持起了都护大将军——苏和,抗夷大将军——邓昌。以姻亲握住兵权后,陆氏子弟一路仕途平坦,百年来,人才辈出,更有陆云,陆羽等良将贤才。而今,已是雄踞渝、豫两地的世家阀门,这江南数万水军,便是掌握在这一代的陆家族长手中。朝廷无权,皇帝无兵,短短十年,南朝便形同虚设,各地封疆大使,世家阀门手握重兵,除了京都三省还在南朝皇族手中,其他俨然已经分地而治。西北,邓、李、苏、何、公孙五家世家阀门割据一方,联手共抗蛮夷合并后的金国。南方,陆、熊、刘、郑四家百年士族据守江南,与中山国相持已然数十载。东方,京都三省雄兵三十万,黑甲铁骑八千,时刻防范着秦国有所异动。(备注:黑甲铁骑配备长枪,马刀,黑铁重甲,所乘骑的乃是西域宛马,是南朝立国时便赫赫有名的百战铁骑。曾以八千黑甲铁骑破中山国十万雄兵而名动天下。)这些,便是张狂融合完原本那个‘秦逸’的记忆,而整理出的天下大势。
------------
Given the new context, refine the original summary
If the context isn't useful, return the original summary.[0m[1m> Finished chain.[0m[1m> Entering new LLMChain chain...[0m
Prompt after formatting:
[32;1m[1;3mYour job is to produce a final summary
We have provided an existing summary up to a certain point: 爱奇电子书(www.i7wu.cn)提供TXT全集电子书存储服务和免费下载服务,用户上传的《地藏心经》由铸剑师无名所作,故事讲述了渝州陆家家族的来历和发展史,以及他们以皮货起家,成为西北地区的商户,百年来贤才辈出,陆氏子弟一路仕途平坦,最终在西北、豫两地占据世家阀门,掌握江南数万水军,而后又破除南朝,联合五家世家阀门抗击金国,与中山国持久战斗,最后以京都三省的三十万雄兵和八千黑甲铁骑防范着秦国的异动,成就了今天的天下大势。
We have the opportunity to refine the existing summary(only if needed) with some more context below.
------------
“少爷。这船都被陆家车行的人包下了。”不过一会儿,秦汉便略显沮丧地走了回来。渝州陆家势大,而今就连附属下面的陆家车行,身份也是水涨船高。自从秦逸父亲病逝后,秦家家道中落,与陆家比不得,况且此地也并非西北所属,秦家纵然还有些人脉,却也用不上。所以,为了避免麻烦,他也没敢去与陆家争船。“嗯。”秦逸默然,脸色平静,对着秦汉点点头,也未多说些什么。虽然他心中也想早点赶往渝州,在年关前,布置些家业,好早些安定下来。“我知道了。”“敢问公子贵姓?”这时,秦逸身旁的中年商人,突然出口问道。原来他见秦逸,ww W.l6K .cN面容俊逸,又是一身锦衣华服,虽然风尘仆仆,但是谈吐举止中,无一不带着士族风范,不由得起了巴结之心。南朝商人地位虽然要略高于前朝列代,但是依旧排在最后。“士农工商”,商人自古就有着“不劳而获”之名。
------------
Given the new context, refine the original summary
If the context isn't useful, return the original summary.[0m[1m> Finished chain.[0m[1m> Entering new LLMChain chain...[0m
Prompt after formatting:
[32;1m[1;3mYour job is to produce a final summary
We have provided an existing summary up to a certain point: 爱奇电子书(www.i7wu.cn)提供TXT全集电子书存储服务和免费下载服务,用户上传的《地藏心经》由铸剑师无名所作,故事讲述了渝州陆家家族的来历和发展史,以及他们以皮货起家,成为西北地区的商户,百年来贤才辈出,陆氏子弟一路仕途平坦,最终在西北、豫两地占据世家阀门,掌握江南数万水军,而后又破除南朝,联合五家世家阀门抗击金国,与中山国持久战斗,最后以京都三省的三十万雄兵和八千黑甲铁骑防范着秦国的异动,成就了今天的天下大势。爱奇电子书的用户上传的《地藏心经》讲述了渝州陆家家族的传奇故事,从皮货起家,到成为西北地区的商户,再到掌握江南数万水军,最终与中山国持久战斗,布置三省三十万雄兵和八千黑甲铁骑,守护天下大势,完成了他们伟大的壮举。
We have the opportunity to refine the existing summary(only if needed) with some more context below.
------------
“姓秦。”秦逸面色淡然,转头看了中年商人一眼,出声道。他来于后世,对商人并无轻视之意,所以也没有摆什么士族的架子。中年商人闻言微微一愣,随即动容,隐隐带着喜悦,他躬腰低头,对着秦逸恭恭敬敬地行了一个大礼,而后出声询问道:“敢问可是晋中秦家?!”“正是!”说话的确是秦汉,秦家在西北之地声名远播,善名百里,虽然手中无兵无权,但是在西北士族中还是举足轻重,俨然已成精神领袖。“敢问,可是秦逸公子?!”中年商人对着秦逸又是一个大礼,声音颇为颤抖地说道。此番回程,他便听说了秦家少爷要前往渝州,却想不到自己居然正好遇上!“五代行善,何其不易!夫天下之人,独晋中秦家也!”……秦家善名,至今已然百年有余。“嗯。”秦逸点头,并未多说。一路行来,他已经陆续感受到了秦家在这个世界上的声望。一世行善容易,但是五代行善,中原数千年来,独此一家。就连数十年前,蛮夷赫连氏族入侵中原,都刻意避开了晋中秦家。在草原蛮族的教义中,屠戮真正的善人,会被狼神抛弃,灵魂永世不得安息。
------------
Given the new context, refine the original summary
If the context isn't useful, return the original summary.[0m[1m> Finished chain.[0m[1m> Entering new LLMChain chain...[0m
Prompt after formatting:
[32;1m[1;3mYour job is to produce a final summary
We have provided an existing summary up to a certain point: 爱奇电子书(www.i7wu.cn)提供TXT全集电子书存储服务和免费下载服务,用户上传的《地藏心经》由铸剑师无名所作,故事讲述了渝州陆家家族的来历和发展史,以及他们以皮货起家,成为西北地区的商户,百年来贤才辈出,陆氏子弟一路仕途平坦,最终在西北、豫两地占据世家阀门,掌握江南数万水军,而后又破除南朝,联合五家世家阀门抗击金国,与中山国持久战斗,最后以京都三省的三十万雄兵和八千黑甲铁骑防范着秦国的异动,成就了今天的天下大势。爱奇电子书的用户上传的《地藏心经》讲述了渝州陆家家族的传奇故事,从皮货起家,到成为西北地区的商户,再到掌握江南数万水军,最终与中山国持久战斗,布置三省三十万雄兵和八千黑甲铁骑,守护天下大势,完成了他们伟大的壮举,他们的善名在中原数千年来一直传唱,令草原蛮族敬畏其功勋。经过百年的努力,渝州陆家家族完成了他们的伟大壮举,守护着天下大势,践行五代行善,在中原数千年中,成为了独一无二的传奇家族。
We have the opportunity to refine the existing summary(only if needed) with some more context below.
------------
就在秦逸准备寻一处清净地,安安静静的等待陆家车行的人先走时,远处,一团人簇拥着一个青衫老者往这边走来。而为首的,正是昨日在路上遇到的那个满脸扎须的壮年汉子。“那便是陆家车行的管事。”一旁的中年商人适时的报出了那位青衫老者的身份。“陆氏车行?管事?”秦逸眉头一挑,不由得心头一动。若是等到陆家车行货物运完,这一来一去,天怕是已经摸黑了,想来渡江只能等到明晚。既然面前,就是陆家车行的管事,何不找他试试,看看能不能一并登船渡江。想到这,秦逸略微整了整衣衫,脸上挂着一副淡定的笑容,迎了上去。“长者有礼了!”秦逸走到人群前,对着为首的青衫老者微微一拱手,行礼道。
------------
Given the new context, refine the original summary
If the context isn't useful, return the original summary.[0m[1m> Finished chain.[0m[1m> Finished chain.[0m'\n\n爱奇电子书(www.i7wu.cn)提供TXT全集电子书存储服务和免费下载服务,用户上传的《地藏心经》由铸剑师无名所作,故事讲述了渝州陆家家族的来历和发展史,他们以皮货起家,成为西北地区的商户,百年来贤才辈出,陆氏子弟一路仕途平坦,最终在西北、豫两地占据世家阀门,掌握江南数万水军,而后又破除南朝,联合五家世家阀门抗击金国,与中山国持久战斗,最后以京都三省的三十万雄兵和八千黑甲铁骑防范着秦国的异动,完成了他们伟大的壮举,令草原蛮族敬畏其功勋,成就了今天的天下大势。经过百年的努力,渝州陆家家族完成了他们的伟大壮举,守护着天下大势,践行五代行善,在中原数千年中,成为了独一无二的传奇家族。'
首先我们对切割前和切割后的 document 个数进行了打印,我们可以看到,切割前就是只有整篇的一个 document,切割完成后,会把上面一个 document 切成 331 个 document。
最终输出了对前 5 个 document 的总结:
这本书的内容是《地藏心经》,作者是铸剑师无名。第一第十五章讲述了渝州陆家的家族史,他们是以皮货起家的西北商户,出售江南的皮货占了三成,但也只是一头肥硕的羔羊,只待他人宰杀。陆氏三代家主都极具雄韬伟略,以千金买官,以万金开路,更是在蛮夷南侵之时,倾尽家资招兵买马,拒十万蛮夷铁骑于侯关外。经过百年来的积累,陆家族已形成了雄踞渝、豫两地的世家阀门,掌握着江南数万水军,朝廷无权,皇帝无兵,南朝形同虚设,而西北、南方、东方各地也都有世家阀门割据一方,抗击蛮夷合并后的金国,但是秦家也并未被淹没,他们依旧带着士族风范,举止优雅,虽未能抗衡陆家,却也不会被压迫,最终在年关前,秦家依然布置了一些家业,安定下来。本书讲述了陆家的家族史,他们以皮货起家,凭借着雄韬伟略的家主们,百年来积累而形成的雄踞渝、豫两地的世家阀门,掌握着江南数万水军,朝廷无权,皇帝无兵,南朝形同虚设,而西北、南方、东方各地也都有世家阀门割据一方,抗击蛮夷合并后的金国。尽管秦家无法抗衡陆家,他们仍然不会被压迫,在年关前,他们也布置了一些家业,安定下来。
几个参数需要注意:
文本分割器的 chunk_overlap 参数
这个是指切割后的每个 document 里包含几个上一个 document 结尾的内容,主要作用是为了增加每个 document 的上下文关联。比如,chunk_overlap=0时, 第一个 document 为 aaaaaa,第二个为 bbbbbb;当 chunk_overlap=2 时,第一个 document 为 aaaaaa,第二个为 aabbbbbb。
不过,这个也不是绝对的,要看所使用的那个文本分割模型内部的具体算法。
- 文本分割器可以参考这个文档:https://python.langchain.com/en/latest/modules/indexes/text_splitters.html
chain 的 chain_type 参数
这个参数主要控制了将 document 传递给 llm 模型的方式,一共有 4 种方式:
- stuff: 这种最简单粗暴,会把所有的 document 一次全部传给 llm 模型进行总结。如果document很多的话,势必会报超出最大 token 限制的错,所以总结文本的时候一般不会选中这个。
- map_reduce: 这个方式会先将每个 document 进行总结,最后将所有 document 总结出的结果再进行一次总结。
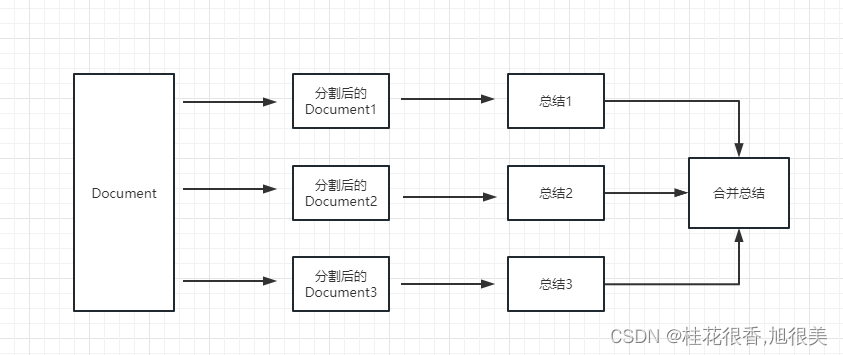
-
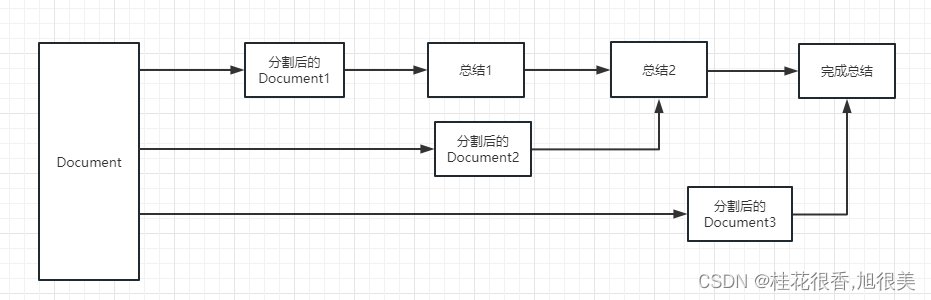
refine: 这种方式会先总结第一个 document,然后在将第一个 document 总结出的内容和第二个 document 一起发给 llm 模型在进行总结,以此类推。这种方式的好处就是在总结后一个 document 的时候,会带着前一个的 document 进行总结,给需要总结的 document 添加了上下文,增加了总结内容的连贯性。
-
map_rerank: 这种一般不会用在总结的 chain 上,而是会用在问答的 chain 上,他其实是一种搜索答案的匹配方式。首先你要给出一个问题,他会根据问题给每个 document 计算一个这个 document 能回答这个问题的概率分数,然后找到分数最高的那个 document ,在通过把这个 document 转化为问题的 prompt 的一部分(问题+document)发送给 llm 模型,最后 llm 模型返回具体答案。
构建本地知识库问答机器人
在这个例子会介绍如何从本地读取多个文档构建知识库,并且使用 Openai API 在知识库中进行搜索并给出答案。
这个是个很有用的教程,比如可以很方便的做一个可以介绍公司业务的机器人,或是介绍一个产品的机器人。
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain import OpenAI,VectorDBQA
from langchain.document_loaders import DirectoryLoader
from langchain.chains import RetrievalQA# 加载文件夹中的所有txt类型的文件
loader = DirectoryLoader('/content/langchain_data/xunfei/', glob='**/*.txt')
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader.load()# 初始化加载器
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0)
# 切割加载的 document
split_docs = text_splitter.split_documents(documents)# 初始化 openai 的 embeddings 对象
embeddings = OpenAIEmbeddings()
# 将 document 通过 openai 的 embeddings 对象计算 embedding 向量信息并临时存入 Chroma 向量数据库,用于后续匹配查询
docsearch = Chroma.from_documents(split_docs, embeddings)# 创建问答对象
qa = VectorDBQA.from_chain_type(llm=OpenAI(), chain_type="stuff", vectorstore=docsearch,return_source_documents=True)
# 进行问答
result = qa({"query": "科大讯飞今年第一季度收入是多少?"})
print(result)
WARNING:langchain.text_splitter:Created a chunk of size 493, which is longer than the specified 100
WARNING:langchain.text_splitter:Created a chunk of size 102, which is longer than the specified 100
WARNING:langchain.text_splitter:Created a chunk of size 109, which is longer than the specified 100
WARNING:langchain.text_splitter:Created a chunk of size 154, which is longer than the specified 100
/usr/local/lib/python3.10/dist-packages/langchain/chains/retrieval_qa/base.py:201: UserWarning: `VectorDBQA` is deprecated - please use `from langchain.chains import RetrievalQA`warnings.warn({'query': '科大讯飞今年第一季度收入是多少?', 'result': ' 28.88亿元', 'source_documents': [Document(page_content='科大讯飞股份有限公司\n\n董事会二〇二三年四月二十一日', metadata={'source': '/content/langchain_data/xunfei/xunfei.txt'}), Document(page_content='编制单位:科大讯飞股份有限公司\n\n2023年03月31日\n\n单位:元\n\n项目\t期末余额\t年初余额\n\n流动资产:\n\n货币资金\t3,219,369,124.97\t4,346,384,857.27', metadata={'source': '/content/langchain_data/xunfei/xunfei.txt'}), Document(page_content=':公司2023 年第一季度营业收入28.88亿元,较去年同期下降17.64%;归属于上市公司股东的净利\n\n润与扣除非经常性损益的净利润分别为\n\n0.58亿元和\n\n3.38亿元。主要原因为:', metadata={'source': '/content/langchain_data/xunfei/xunfei.txt'}), Document(page_content='1) 由于去年12月份和今年1月份特殊的社会经济客观环境,当期无法推进项目进程和合同签署等工作,随后又面临春节假期,较多大项目在一季度的签单、实施、交付、验收等工作进程出现了延迟,影响了收入的实现进度。一季度的特殊社会经济环境对公司的影响属于短期冲击,不影响公司长期经营基本面。2) 公司2019年被列入美国实体清单,2022年10月7日被再次极限施压,从供应链到相关的合同签署需要调整的过程,经过去年四季度和今年一季度的努力,主要调整已基本完成。3) 面对认知智能技术阶跃带来的重大机遇,公司依托认知智能全国重点实验室的长期积累,于2022年12月15日启动了“1+N认知智能大模型专项攻关”,将于2023年5月6日正式发布讯飞星火大模型。上述攻关项目的新增投入一定程度上影响了当期利润,但是会带来公司已有产品竞争力的显著提升,同时还提供了公司深度参与互联网产业格局重塑的新机遇,为讯飞实现“用人工智能建设美好世界”的产业梦想提供更广阔的空间。公司虽然在一季度业绩下滑,但基于在国产替代和业务开拓上的进展,预计从二季度开始将会实现收入和毛利正向增长,并有信心实现全年高质量增长的目标。', metadata={'source': '/content/langchain_data/xunfei/xunfei.txt'})]}
查询结果,科大讯飞2023 年第一季度收入28.88亿元,与文档里的内容一致!
- 关于 Openai embeddings 详细资料可以参看这个连接: https://platform.openai.com/docs/guides/embeddings
构建向量索引数据库
上个案例里面有一步是将 document 信息转换成向量信息和embeddings的信息并临时存入 Chroma 向量数据库。
因为是临时存入,所以当我们上面的代码执行完成后,上面的向量化后的数据将会丢失。如果想下次使用,那么就还需要再计算一次embeddings,这肯定不是我们想要的。
下面通过 Chroma 和 Pinecone 这两个数据库来讲一下如何做向量数据持久化。
- 因为 LangChain 支持的数据库有很多,所以这里就介绍两个用的比较多的,更多的可以参看文档:https://python.langchain.com/en/latest/modules/indexes/vectorstores/getting_started.html
Chroma
chroma 是个本地的向量数据库,他提供的一个 persist_directory 来设置持久化目录进行持久化。读取时,只需要调取 from_document 方法加载即可。
from langchain.vectorstores import Chroma# 持久化数据
docsearch = Chroma.from_documents(documents, embeddings, persist_directory="D:/vector_store")
docsearch.persist()# 加载数据
docsearch = Chroma(persist_directory="D:/vector_store", embedding_function=embeddings)
Pinecone
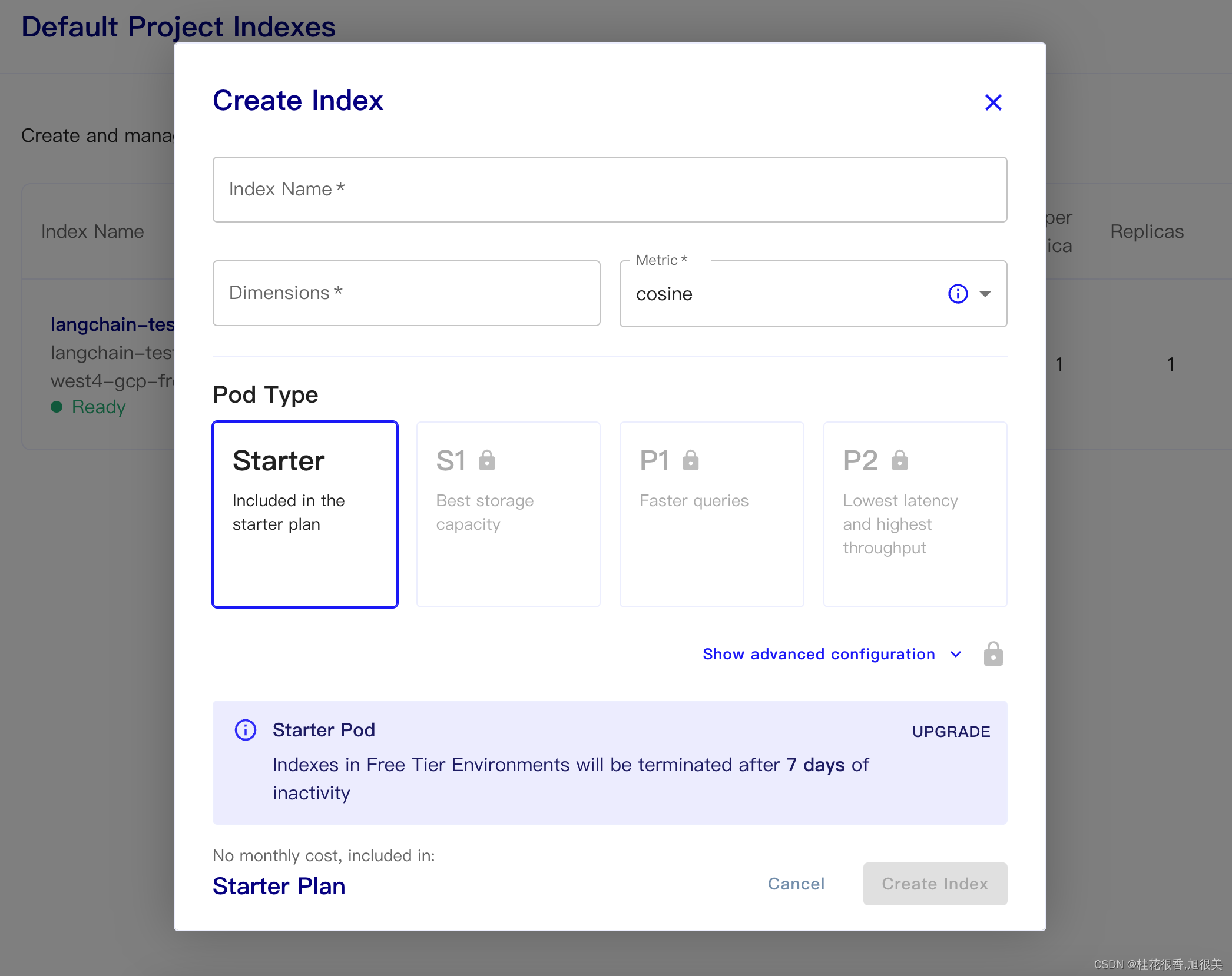
Pinecone 是一个在线的向量数据库。第一步依旧是注册,然后拿到对应的 api key。https://app.pinecone.io/ (免费版如果索引14天不使用会被自动清除。)
然后创建我们的数据库:
Index Name:这个随意
Dimensions:OpenAI 的 text-embedding-ada-002 模型为 OUTPUT DIMENSIONS 为 1536,所以我们这里填 1536
Metric:可以默认为 cosine
选择starter plan
持久化数据和加载数据代码如下
# 持久化数据
docsearch = Pinecone.from_texts([t.page_content for t in split_docs], embeddings, index_name=index_name)# 加载数据
docsearch = Pinecone.from_existing_index(index_name, embeddings)
一个简单从数据库获取 embeddings,并回答的代码如下
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import DirectoryLoader
from langchain.vectorstores import Chroma, Pinecone
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.chains.question_answering import load_qa_chain#import pinecone# 初始化 pinecone
# pinecone.init(
# api_key="你的api key",
# environment="你的Environment"
# )loader = DirectoryLoader('/content/langchain_data/xunfei/', glob='**/*.txt')
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader.load()# 初始化加载器
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=0)
# 切割加载的 document
split_docs = text_splitter.split_documents(documents)index_name="wws-test"# 持久化数据
# docsearch = Pinecone.from_texts([t.page_content for t in split_docs], embeddings, index_name=index_name)# 加载数据
#docsearch = Pinecone.from_existing_index(index_name,embeddings)# 持久化数据
#docsearch = Chroma.from_documents(documents, embeddings, persist_directory="/content/langchain_data/xunfei_verctor/")
#docsearch.persist()# 加载数据
docsearch = Chroma(persist_directory="/content/langchain_data/xunfei_verctor/", embedding_function=embeddings)query = "科大讯飞今年第一季度收入是多少?"
docs = docsearch.similarity_search(query, include_metadata=True)llm = OpenAI(temperature=0)
chain = load_qa_chain(llm, chain_type="refine", verbose=True)
chain.run(input_documents=docs, question=query)
WARNING:chromadb.db.index.hnswlib:Number of requested results 4 is greater than number of elements in index 1, updating n_results = 1[1m> Entering new RefineDocumentsChain chain...[0m[1m> Entering new LLMChain chain...[0m
Prompt after formatting:
[32;1m[1;3mContext information is below.
---------------------
科大讯飞股份有限公司)注:公司2023 年第一季度营业收入28.88亿元,较去年同期下降17.64%;归属于上市公司股东的净利润与扣除非经常性损益的净利润分别为0.58亿元和3.38亿元。主要原因为:
---------------------
Given the context information and not prior knowledge, answer the question: 科大讯飞今年第一季度收入是多少?
[0m[1m> Finished chain.[0m[1m> Finished chain.[0m"\nThe company's revenue for the first quarter of this year was 28.88 billion yuan."
使用GPT3.5模型构建油管频道问答机器人
在 chatgpt api(也就是 GPT-3.5-Turbo)模型出来后,因钱少活好深受大家喜爱,所以 LangChain 也加入了专属的链和模型.
import osfrom langchain.document_loaders import YoutubeLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import ChatVectorDBChain, ConversationalRetrievalChainfrom langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (ChatPromptTemplate,SystemMessagePromptTemplate,HumanMessagePromptTemplate
)# 加载 youtube 频道
loader = YoutubeLoader.from_youtube_url('https://www.youtube.com/watch?v=Dj60HHy-Kqk')
# 将数据转成 document
documents = loader.load()# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000,chunk_overlap=20
)# 分割 youtube documents
documents = text_splitter.split_documents(documents)# 初始化 openai embeddings
embeddings = OpenAIEmbeddings()# 将数据存入向量存储
vector_store = Chroma.from_documents(documents, embeddings)
# 通过向量存储初始化检索器
retriever = vector_store.as_retriever()system_template = """
Use the following context to answer the user's question.
If you don't know the answer, say you don't, don't try to make it up.
And answer in Chinese.
-----------
{context}
-----------
{chat_history}
"""# 构建初始 messages 列表,这里可以理解为是 openai 传入的 messages 参数
messages = [SystemMessagePromptTemplate.from_template(system_template),HumanMessagePromptTemplate.from_template('{question}')
]# 初始化 prompt 对象
prompt = ChatPromptTemplate.from_messages(messages)# 初始化问答链
qa = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0.1,max_tokens=2048),retriever,condense_question_prompt=prompt)chat_history = []
while True:question = input('问题:')# 开始发送问题 chat_history 为必须参数,用于存储对话历史result = qa({'question': question, 'chat_history': chat_history})chat_history.append((question, result['answer']))print(result['answer'])
问题:这个视频的主题是什么?
这个视频的主题是展示Unreal Engine 5.2的新实验性功能,包括用于复杂材质和程序化内容生成的工具。视频中展示了一个使用Unreal Engine制作的环境,包括一个Rivian R1T车辆模型和使用程序化工具生成的场景元素。---------------------------------------------------------------------------KeyboardInterrupt Traceback (most recent call last)<ipython-input-37-1d8dd71e2e4d> in <cell line: 63>()62 chat_history = []63 while True:
---> 64 question = input('问题:')65 # 开始发送问题 chat_history 为必须参数,用于存储对话历史66 result = qa({'question': question, 'chat_history': chat_history})/usr/local/lib/python3.10/dist-packages/ipykernel/kernelbase.py in raw_input(self, prompt)849 "raw_input was called, but this frontend does not support input requests."850 )
--> 851 return self._input_request(str(prompt),852 self._parent_ident,853 self._parent_header,/usr/local/lib/python3.10/dist-packages/ipykernel/kernelbase.py in _input_request(self, prompt, ident, parent, password)893 except KeyboardInterrupt:894 # re-raise KeyboardInterrupt, to truncate traceback
--> 895 raise KeyboardInterrupt("Interrupted by user") from None896 except Exception as e:897 self.log.warning("Invalid Message:", exc_info=True)KeyboardInterrupt: Interrupted by user
使用流式回答也很方便
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandlerchat = ChatOpenAI(streaming=True, callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]), verbose=True, temperature=0)
resp = chat(chat_prompt_with_values.to_messages())
用 OpenAI 连接万种工具
主要是结合使用 zapier 来实现将万种工具连接起来。
所以我们第一步依旧是需要申请账号和他的自然语言 api key。https://zapier.com/l/natural-language-actions
他的 api key 虽然需要填写信息申请。但是基本填入信息后,基本可以秒在邮箱里看到审核通过的邮件。
然后,我们通过右键里面的连接打开我们的api 配置页面。我们点击右侧的 Manage Actions 来配置我们要使用哪些应用。
我在这里配置了 Gmail 读取和发邮件的 action,并且所有字段都选的是通过 AI 猜。
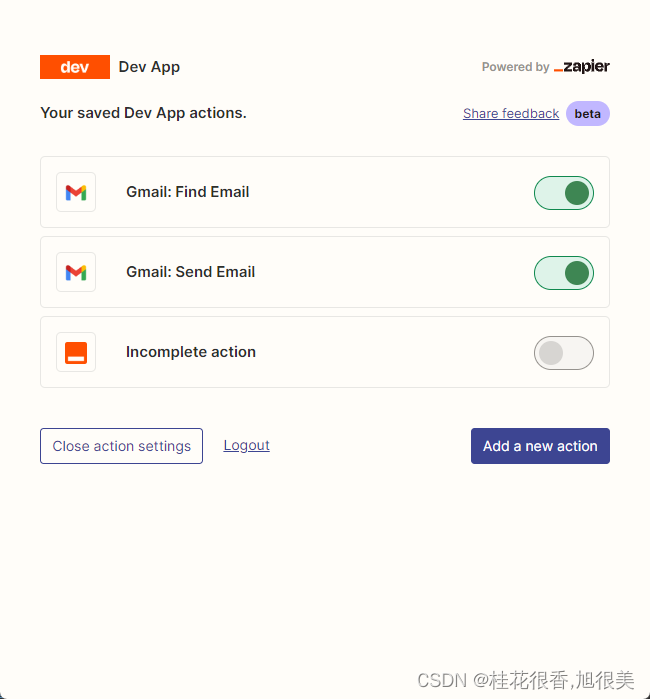
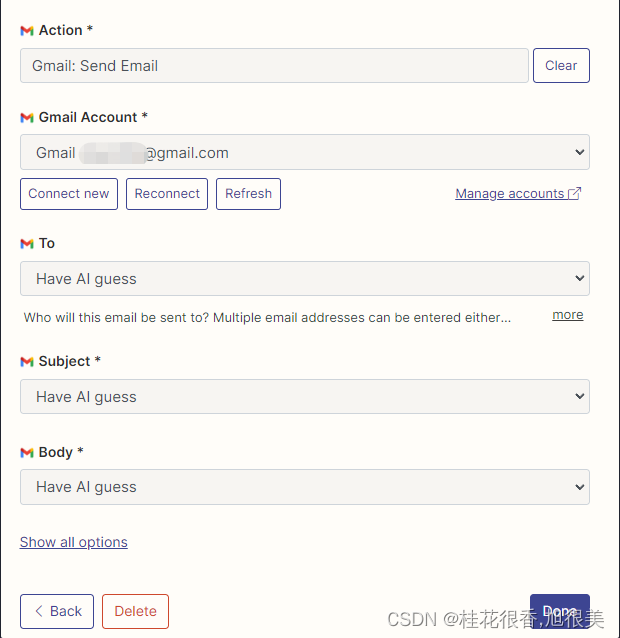
配置好后,我们开始写代码
import os
os.environ["ZAPIER_NLA_API_KEY"] = ''
from langchain.llms import OpenAI
from langchain.agents import initialize_agent
from langchain.agents.agent_toolkits import ZapierToolkit
from langchain.utilities.zapier import ZapierNLAWrapperllm = OpenAI(temperature=.3)
zapier = ZapierNLAWrapper()
toolkit = ZapierToolkit.from_zapier_nla_wrapper(zapier)
agent = initialize_agent(toolkit.get_tools(), llm, agent="zero-shot-react-description", verbose=True)# 我们可以通过打印的方式看到我们都在 Zapier 里面配置了哪些可以用的工具
for tool in toolkit.get_tools():print (tool.name)print (tool.description)print ("\n\n")agent.run('请用中文总结最后一封"******@qq.com"发给我的邮件。并将总结发送给"******@qq.com"')

我们可以看到他成功读取了******@qq.com给他发送的最后一封邮件,并将总结的内容又发送给了******@qq.com
这是我发送给 Gmail 的邮件。
其他小例子
执行多个chain
因为他是链式的,所以他也可以按顺序依次去执行多个 chain
from langchain.llms import OpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.chains import SimpleSequentialChain# location 链
llm = OpenAI(temperature=1)
template = """Your job is to come up with a classic dish from the area that the users suggests.
% USER LOCATION
{user_location}YOUR RESPONSE:
"""
prompt_template = PromptTemplate(input_variables=["user_location"], template=template)
location_chain = LLMChain(llm=llm, prompt=prompt_template)# meal 链
template = """Given a meal, give a short and simple recipe on how to make that dish at home.
% MEAL
{user_meal}YOUR RESPONSE:
"""
prompt_template = PromptTemplate(input_variables=["user_meal"], template=template)
meal_chain = LLMChain(llm=llm, prompt=prompt_template)# 通过 SimpleSequentialChain 串联起来,第一个答案会被替换第二个中的user_meal,然后再进行询问
overall_chain = SimpleSequentialChain(chains=[location_chain, meal_chain], verbose=True)
review = overall_chain.run("china")
[1m> Entering new SimpleSequentialChain chain...[0m
[36;1m[1;3m
Classic Chinese dish: Kung Pao Chicken.[0m
[33;1m[1;3m
Ingredients:
- 2 boneless chicken breasts, cut into cubes
- 2 tablespoons vegetable oil
- 4 cloves garlic, minced
- 2 teaspoons ginger, grated
- 1/2 teaspoon red chili pepper flakes
- 1/2 cup peanuts
- 1/4 cup soy sauce
- 2 tablespoons dry sherry
- 1/4 cup chicken broth
- 2 tablespoons rice vinegar
- 2 teaspoons sesame oil
- 1/4 teaspoon white sugarInstructions:1. Heat the vegetable oil in a wok or large skillet over high heat.
2. Add the chicken and stir-fry for 3-4 minutes, until lightly browned.
3. Add the garlic, ginger, and red chili pepper flakes and cook for 1 minute.
4. Add the peanuts, soy sauce, sherry, chicken broth, rice vinegar, sesame oil, and sugar and stir to combine.
5. Reduce heat to low, simmer for 10 minutes, stirring occasionally.
6. Serve over white rice, garnish with scallions and extra peanuts if desired.[0m[1m> Finished chain.[0m
结构化输出
有时候我们希望输出的内容不是文本,而是像 json 那样结构化的数据。
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAIllm = OpenAI(model_name="text-davinci-003")# 告诉他我们生成的内容需要哪些字段,每个字段类型式啥
response_schemas = [ResponseSchema(name="bad_string", description="This a poorly formatted user input string"),ResponseSchema(name="good_string", description="This is your response, a reformatted response")
]# 初始化解析器
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)# 生成的格式提示符
# {
# "bad_string": string // This a poorly formatted user input string
# "good_string": string // This is your response, a reformatted response
#}
format_instructions = output_parser.get_format_instructions()template = """
You will be given a poorly formatted string from a user.
Reformat it and make sure all the words are spelled correctly{format_instructions}% USER INPUT:
{user_input}YOUR RESPONSE:
"""# 将我们的格式描述嵌入到 prompt 中去,告诉 llm 我们需要他输出什么样格式的内容
prompt = PromptTemplate(input_variables=["user_input"],partial_variables={"format_instructions": format_instructions},template=template
)promptValue = prompt.format(user_input="welcom to shanghai !")
llm_output = llm(promptValue)# 使用解析器进行解析生成的内容
output_parser.parse(llm_output)
{'bad_string': 'welcom to shanghai !', 'good_string': 'Welcome to Shanghai!'}
爬取网页并输出JSON数据
有些时候我们需要爬取一些 结构性比较强 的网页,并且需要将网页中的信息以JSON的方式返回回来。
我们就可以使用 LLMRequestsChain 类去实现,具体可以参考下面代码
- 为了方便理解,在例子中直接使用了Prompt的方法去格式化输出结果,而没用使用上个案例中用到的 StructuredOutputParser去格式化,也算是提供了另外一种格式化的思路
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
from langchain.chains import LLMRequestsChain, LLMChainllm = OpenAI(model_name="gpt-3.5-turbo", temperature=0)template = """在 >>> 和 <<< 之间是网页的返回的HTML内容。
网页是新浪财经A股上市公司的公司简介。
请抽取参数请求的信息。>>> {requests_result} <<<
请使用如下的JSON格式返回数据
{{"company_name":"a","company_english_name":"b","issue_price":"c","date_of_establishment":"d","registered_capital":"e","office_address":"f","Company_profile":"g"}}
Extracted:"""prompt = PromptTemplate(input_variables=["requests_result"],template=template
)chain = LLMRequestsChain(llm_chain=LLMChain(llm=llm, prompt=prompt))
inputs = {"url": "https://vip.stock.finance.sina.com.cn/corp/go.php/vCI_CorpInfo/stockid/600519.phtml"
}response = chain(inputs)
print(response['output'])
/usr/local/lib/python3.10/dist-packages/langchain/llms/openai.py:171: UserWarning: You are trying to use a chat model. This way of initializing it is no longer supported. Instead, please use: `from langchain.chat_models import ChatOpenAI`warnings.warn(
/usr/local/lib/python3.10/dist-packages/langchain/llms/openai.py:716: UserWarning: You are trying to use a chat model. This way of initializing it is no longer supported. Instead, please use: `from langchain.chat_models import ChatOpenAI`warnings.warn({"company_name":"贵州茅台酒股份有限公司","company_english_name":"Kweichow Moutai Co.,Ltd.","issue_price":"31.39","date_of_establishment":"1999-11-20","registered_capital":"125620万元(CNY)","office_address":"贵州省仁怀市茅台镇","Company_profile":"公司是根据贵州省人民政府黔府函〔1999〕291号文,由中国贵州茅台酒厂有限责任公司作为主发起人,联合贵州茅台酒厂技术开发公司、贵州省轻纺集体工业联社、深圳清华大学研究院、中国食品发酵工业研究院、北京市糖业烟酒公司、江苏省糖烟酒总公司、上海捷强烟草糖酒(集团)有限公司于1999年11月20日共同发起设立的股份有限公司。经中国证监会证监发行字[2001]41号文核准并按照财政部企[2001]56号文件的批复,公司于2001年7月31日在上海证券交易所公开发行7,150万(其中,国有股存量发行650万股)A股股票。主营业务:贵州茅台酒系列产品的生产与销售,饮料、食品、包装材料的生产与销售,防伪技术开发;信息产业相关产品的研制和开发等。"
}
自定义agent中所使用的工具
from langchain.agents import initialize_agent, Tool
from langchain.agents import AgentType
from langchain.tools import BaseTool
from langchain.llms import OpenAI
from langchain import LLMMathChain, SerpAPIWrapperllm = OpenAI(temperature=0)# 初始化搜索链和计算链
search = SerpAPIWrapper()
llm_math_chain = LLMMathChain(llm=llm, verbose=True)# 创建一个功能列表,指明这个 agent 里面都有哪些可用工具,agent 执行过程可以看必知概念里的 Agent 那张图
tools = [Tool(name = "Search",func=search.run,description="useful for when you need to answer questions about current events"),Tool(name="Calculator",func=llm_math_chain.run,description="useful for when you need to answer questions about math")
]# 初始化 agent
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)# 执行 agent
agent.run("Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.233 power?")
/usr/local/lib/python3.10/dist-packages/langchain/chains/llm_math/base.py:50: UserWarning: Directly instantiating an LLMMathChain with an llm is deprecated. Please instantiate with llm_chain argument or using the from_llm class method.warnings.warn([1m> Entering new AgentExecutor chain...[0m
[32;1m[1;3m I need to find out who Leo DiCaprio's girlfriend is and then calculate her age raised to the 0.233 power.
Action: Search
Action Input: "Leo DiCaprio girlfriend"[0m
Observation: [36;1m[1;3mLeonardo DiCaprio has split from girlfriend Camila Morrone. Getty. Taking a look at his dating history, Leo has always had a preference for ...[0m
Thought:[32;1m[1;3m I need to find out Camila Morrone's age
Action: Search
Action Input: "Camila Morrone age"[0m
Observation: [36;1m[1;3m25 years[0m
Thought:[32;1m[1;3m I need to calculate 25 raised to the 0.233 power
Action: Calculator
Action Input: 25^0.233[0m[1m> Entering new LLMMathChain chain...[0m
25^0.233[32;1m[1;3m```text
25**0.233
```
...numexpr.evaluate("25**0.233")...
[0m
Answer: [33;1m[1;3m2.1169959248669104[0m
[1m> Finished chain.[0mObservation: [33;1m[1;3mAnswer: 2.1169959248669104[0m
Thought:[32;1m[1;3m I now know the final answer
Final Answer: Camila Morrone is Leo DiCaprio's girlfriend and her current age raised to the 0.233 power is 2.1169959248669104.[0m[1m> Finished chain.[0m"Camila Morrone is Leo DiCaprio's girlfriend and her current age raised to the 0.233 power is 2.1169959248669104."
自定义工具里面有个比较有意思的地方,使用哪个工具的权重是靠 工具中描述内容 来实现的,和我们之前编程靠数值来控制权重完全不同。
比如 Calculator 在描述里面写到,如果你问关于数学的问题就用他这个工具。我们就可以在上面的执行过程中看到,他在我们请求的 prompt 中数学的部分,就选用了Calculator 这个工具进行计算。
使用Memory实现一个带记忆的对话机器人
上一个例子使用的是通过自定义一个列表来存储对话的方式来保存历史的。
当然,你也可以使用自带的 memory 对象来实现这一点。
from langchain.memory import ChatMessageHistory
from langchain.chat_models import ChatOpenAIchat = ChatOpenAI(temperature=0)# 初始化 MessageHistory 对象
history = ChatMessageHistory()# 给 MessageHistory 对象添加对话内容
history.add_ai_message("你好!")
history.add_user_message("上海周末哪里比较好玩?")# 执行对话
ai_response = chat(history.messages)
print(ai_response)
content='您好!上海周末有很多好玩的地方,以下是一些推荐:\n\n1. 上海迪士尼乐园:适合全家人一起去玩,有各种刺激的游乐设施和演出。\n\n2. 外滩:可以欣赏到上海的夜景,还可以看到黄浦江两岸的历史建筑。\n\n3. 上海科技馆:适合带孩子去,有很多有趣的科技展览和互动体验。\n\n4. 上海博物馆:可以了解上海的历史和文化,还有一些世界级的展览。\n\n5. 田子坊:是一个有着悠久历史的文化艺术区,有很多小店和餐厅,适合逛街和品尝美食。\n\n希望以上推荐能够帮到您!' additional_kwargs={} example=False
使用 Hugging Face 模型
使用 Hugging Face 模型之前,需要先设置环境变量
import os
os.environ['HUGGINGFACEHUB_API_TOKEN'] = ''
使用在线的 Hugging Face 模型
from langchain import PromptTemplate, HuggingFaceHub, LLMChaintemplate = """Question: {question}
Answer: Let's think step by step."""prompt = PromptTemplate(template=template, input_variables=["question"])
llm = HuggingFaceHub(repo_id="google/flan-t5-xl", model_kwargs={"temperature":0, "max_length":64})
llm_chain = LLMChain(prompt=prompt, llm=llm)question = "What NFL team won the Super Bowl in the year Justin Beiber was born?"
print(llm_chain.run(question))
将 Hugging Face 模型直接拉到本地使用
from langchain import PromptTemplate, LLMChain
from langchain.llms import HuggingFacePipeline
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline, AutoModelForSeq2SeqLMmodel_id = 'google/flan-t5-large'
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(model_id)pipe = pipeline("text2text-generation",model=model,tokenizer=tokenizer,max_length=100
)local_llm = HuggingFacePipeline(pipeline=pipe)
print(local_llm('What is the capital of France? '))template = """Question: {question} Answer: Let's think step by step."""
prompt = PromptTemplate(template=template, input_variables=["question"])llm_chain = LLMChain(prompt=prompt, llm=local_llm)
question = "What is the capital of England?"
print(llm_chain.run(question))
Downloading (…)okenizer_config.json: 0%| | 0.00/2.54k [00:00<?, ?B/s]Downloading spiece.model: 0%| | 0.00/792k [00:00<?, ?B/s]Downloading (…)/main/tokenizer.json: 0%| | 0.00/2.42M [00:00<?, ?B/s]Downloading (…)cial_tokens_map.json: 0%| | 0.00/2.20k [00:00<?, ?B/s]Downloading (…)lve/main/config.json: 0%| | 0.00/662 [00:00<?, ?B/s]Downloading pytorch_model.bin: 0%| | 0.00/3.13G [00:00<?, ?B/s]Downloading (…)neration_config.json: 0%| | 0.00/147 [00:00<?, ?B/s]paris
The capital of England is London. London is the capital of England. So the answer is London.
将模型拉到本地使用的好处:
- 训练模型
- 可以使用本地的 GPU
- 有些模型无法在 Hugging Face 运行
通过自然语言执行SQL命令
通过 SQLDatabaseToolkit 或者 SQLDatabaseChain 都可以实现执行SQL命令的操作
from langchain.agents import create_sql_agent
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
from langchain.sql_database import SQLDatabase
from langchain.llms.openai import OpenAIdb = SQLDatabase.from_uri("sqlite:///../notebooks/Chinook.db")
toolkit = SQLDatabaseToolkit(db=db)agent_executor = create_sql_agent(llm=OpenAI(temperature=0),toolkit=toolkit,verbose=True
)agent_executor.run("Describe the playlisttrack table")
from langchain import OpenAI, SQLDatabase, SQLDatabaseChaindb = SQLDatabase.from_uri("mysql+pymysql://root:root@127.0.0.1/chinook")
llm = OpenAI(temperature=0)db_chain = SQLDatabaseChain(llm=llm, database=db, verbose=True)
db_chain.run("How many employees are there?")
这里可以参考这两篇文档:
- https://python.langchain.com/en/latest/modules/agents/toolkits/examples/sql_database.html
- https://python.langchain.com/en/latest/modules/chains/examples/sqlite.html