文章目录
- 一【题目类别】
- 二【题目难度】
- 三【题目编号】
- 四【题目描述】
- 五【题目示例】
- 六【题目提示】
- 七【解题思路】
- 八【时间频度】
- 九【代码实现】
- 十【提交结果】
一【题目类别】
- 哈希表
二【题目难度】
- 简单
三【题目编号】
- 219.存在重复元素II
四【题目描述】
- 给你一个整数数组 nums 和一个整数 k ,判断数组中是否存在两个 不同的索引 i 和 j ,满足 nums[i] == nums[j] 且 abs(i - j) <= k 。如果存在,返回 true ;否则,返回 false。
五【题目示例】
-
示例 1:
- 输入:nums = [1,2,3,1], k = 3
- 输出:true
-
示例 2:
- 输入:nums = [1,0,1,1], k = 1
- 输出:true
-
示例 3:
- 输入:nums = [1,2,3,1,2,3], k = 2
- 输出:false
六【题目提示】
- 1 < = n u m s . l e n g t h < = 1 0 5 1 <= nums.length <= 10^5 1<=nums.length<=105
- − 1 0 9 < = n u m s [ i ] < = 1 0 9 -10^9 <= nums[i] <= 10^9 −109<=nums[i]<=109
- 0 < = k < = 1 0 5 0 <= k <= 10^5 0<=k<=105
七【解题思路】
- 本题首先想到的思路就是暴力解法,但是这种解法会超时,所以我们想到了哈希表
- 将元素入哈希表,当前元素值为哈希表的key,索引下标为val,如果再次遇到了相同的元素,我们就取出之前存入的val,求其差值,如果差值小于等于k,那么就返回true
- 如果遍历整个数组都没有想要的结果,那么就返回false
- 其实本题本质上是维护一个最近的索引下标
八【时间频度】
- 时间复杂度: O ( n ) O(n) O(n), n n n为传入的数组的长度
- 空间复杂度: O ( n ) O(n) O(n), n n n为传入的数组的长度
九【代码实现】
- Java语言版
class Solution {public boolean containsNearbyDuplicate(int[] nums, int k) {HashMap<Integer, Integer> map = new HashMap<>();for(int i = 0;i < nums.length;i++){if(map.containsKey(nums[i])){if(Math.abs(map.get(nums[i]) - i) <= k){return true;}}map.put(nums[i], i);}return false;}
}
- C语言版
struct HashEntry
{int key;int val;UT_hash_handle hh;
};void hashAddItem(struct HashEntry **obj, int key, int val)
{struct HashEntry* pEntry = (struct HashEntry*)malloc(sizeof(struct HashEntry));pEntry->key = key;pEntry->val = val;HASH_ADD_INT(*obj, key, pEntry);
}struct HashEntry* hashFindItem(const struct HashEntry** obj, int key)
{struct HashEntry* pEntry = NULL;HASH_FIND_INT(*obj, &key, pEntry);return pEntry;
}void hashFreeAll(struct HashEntry** obj)
{struct HashEntry *curr, *next;HASH_ITER(hh, *obj, curr, next){HASH_DEL(*obj, curr);free(curr);}
}bool containsNearbyDuplicate(int* nums, int numsSize, int k)
{struct HashEntry* map = NULL;for(int i = 0;i < numsSize;i++){if(hashFindItem(&map, nums[i]) != NULL){if(i - hashFindItem(&map, nums[i])->val <= k){hashFreeAll(&map);return true;}}hashAddItem(&map, nums[i], i);}hashFreeAll(&map);return false;
}
- Python语言版
class Solution:def containsNearbyDuplicate(self, nums: List[int], k: int) -> bool:map = {}for i, num in enumerate(nums):if num in map:if i - map[num] <= k:return Truemap[num] = ireturn False
- C++语言版
class Solution {
public:bool containsNearbyDuplicate(vector<int>& nums, int k) {unordered_map<int, int> map;for(int i = 0;i < nums.size();i++){if(map.count(nums[i]) != 0){if(i - map[nums[i]] <= k){return true;}}map[nums[i]] = i;}return false;}
};
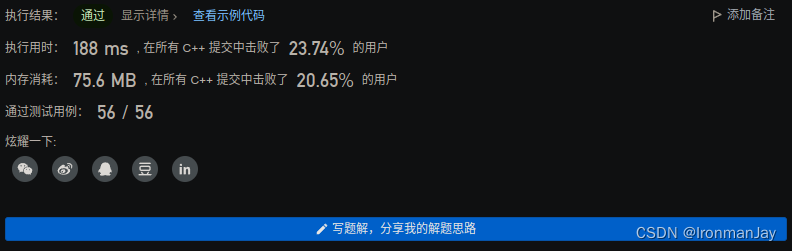
十【提交结果】
-
Java语言版
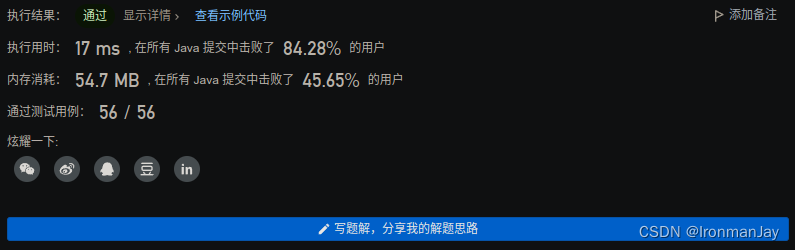
-
C语言版
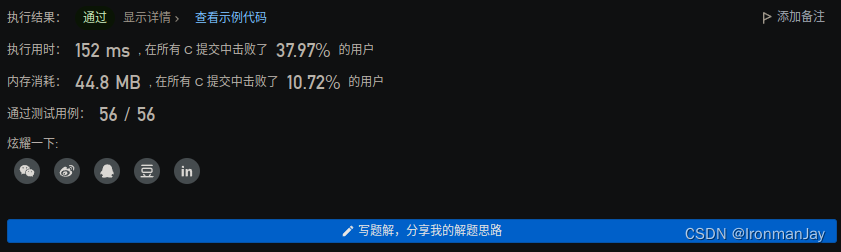
-
Python语言版
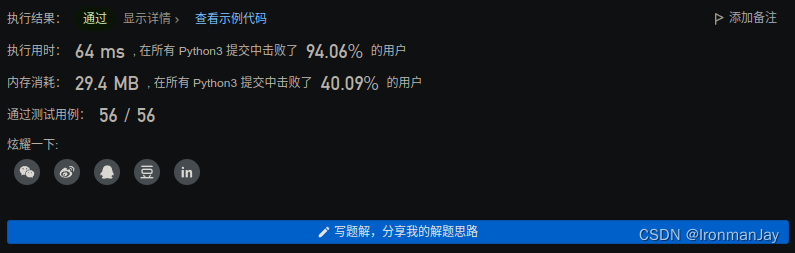
-
C++语言版