My MLOps tutorials:
- Tutorial 1: A Beginner-Friendly Introduction to MLOps
- 教程 2:使用 MLOps 构建机器学习项目
一、说明
如果你希望将机器学习项目提升到一个新的水平,MLOps 是该过程的重要组成部分。在本文中,我们将以经典手写数字分类问题为例,提供有关如何为 MLOps 构建项目的实用教程。我们将逐步引导您完成创建可用于组织自己的项目的基本项目模板的过程。在本教程结束时,你将对 MLOps 原则以及如何将它们应用于自己的项目有深入的了解。但是,如果你不熟悉 MLOps,我们建议从我的初学者友好教程开始快速上手。因此,让我们深入了解您的 ML 项目,让您的 ML 项目更上一层楼!
二. 简介
2.1 MLOps是啥?
MLOps(机器学习运营)是将 DevOps 实践应用到机器学习生命周期的过程。它涉及机器学习管道各个方面的自动化、监控和优化,从数据采集和准备到模型训练、部署和管理。
MLOps 旨在简化机器学习开发流程,提高机器学习模型的准确性和可靠性,并减少开发和部署机器学习系统所需的时间和成本。它结合了软件工程、数据科学和运营的最佳实践,创建了强大且可扩展的机器学习基础设施。
MLOps 涉及一系列工具、技术和流程,包括版本控制、持续集成和交付、容器化、编排、监控和反馈循环。对于希望在机器学习计划中实现卓越运营并通过数据驱动的洞察和自动化提供业务价值的组织来说,这是至关重要的。
2.2 本教程实验需要
在本教程中,我们将使用手写数字分类作为示例。在之前的教程中,我创建了一个用于 MNIST 分类的 Github 存储库,项目结构如下所示:
MNIST_classification
├── dataset_scripts
│ ├── construct_dataset_csv.py
│ ├── construct_dataset_folders.py
│ ├── describe_dataset_csv.py
│ ├── explore_dataset_idx.py
│ └── README.md
├── main_classification_convnet.py
├── main_classification_onehot.py
├── main_classification_single_output.py
├── .gitignore
└── README.md 项目文件夹包括“dataset_scripts”文件夹,其中包含用于以原始 IDX 格式操作数据集的脚本(您可以查看我之前的教程“如何轻松探索您的 IDX 数据集”以获取更多信息)、用于训练三种不同类型的模型的 Python 脚本、一个 .gitignore 文件和一个自述文件。项目结构很简单,因为它是为教程目的而设计的。在本教程中,我将介绍 MLOps 项目的项目结构。请注意,如果您想了解有关模型和训练的编程详细信息,您可以随时参考我的教程“神经网络简介:分类问题”。
三. MLOps流程
MLOps 工作流概述了机器学习过程中的不同步骤,其中包括业务问题、数据工程、机器学习模型工程和代码工程。在本节中,我们将探讨如何实现每个步骤。但是,由于我们正在解决的问题(手写数字分类)不需要它们,因此不会深入讨论某些步骤。我们将重点介绍以绿色突出显示的步骤(见下图)。其余步骤将在以后的教程中介绍。若要了解有关 MLOps 工作流的详细信息,可以查看我的初学者友好教程。

3.1. 业务问题
本教程中解决的问题是手写数字的分类,这是一个多类分类任务。具体地,给定手写数字的输入图像范围从0到9,模型需要识别该数字并输出其相应的标签。
AI 画布包含以下组件:任务描述、预测(模型输出)、判断、操作、结果、训练、输入、反馈和模型对问题的影响。对于当前的手写数字分类问题,我们的AI画布将按如下方式构建和填充:

3.2. 数据工程

数据工程包括各种任务,例如数据引入、探索和验证、清理、标记和拆分。在此项目中,我们执行了以下数据工程任务:
- 数据摄取:我们从其官方网站下载了原始格式的 MNIST 数据集,并将其转换为 CSV 文件。
- 数据探索和验证:我们可视化了数据集中的一些图像并展示了一些见解。
- 数据清洗:数据集已经干净,不需要任何进一步的清理。
- 数据标注: 数据集已标记,因此无需额外标记。
- 数据拆分:数据集已拆分为训练集和测试集。稍后我们将从训练集中提取验证集。
值得注意的是,该项目涉及一个相对简单的数据工程过程,因为数据集已经准备好并处理了。但是,我们将在以后的文章中探讨更复杂的示例。
3.3. 机器学习模型工程

机器学习模型工程
机器学习模型工程是 MLOps 工作流中的第三步。它涉及各种任务,例如模型训练、评估、测试和打包。在此项目中,我们执行了以下 ML 模型工程任务:
- 模型训练:对于特征工程,我们使用数据缩放(将像素缩放到[0,1]的范围),数据重塑(将图像表示为一维向量或二维矩阵)和数据编码(独热编码)。对于模型工程,我们实现了两种不同类型的模型并应用了超参数调优。
- 模型评估:除了准确性之外,我们还使用了其他评估指标,例如召回率、精度和 F1 分数,以确保模型满足 AI 画布中描述的业务目标(结果)。
- 模型测试:评估模型后,我们在两种不同类型的数据上对其进行了测试:第一种类型是MNIST数据集的测试集,第二种类型是从应用程序生成的一些手写数字图像。
- 模型打包和版本控制将在下一教程中讨论,我们将更详细地介绍机器学习管道。
如果你想要更多编程细节,你可以随时查看我以前的教程。
3.4. 代码工程
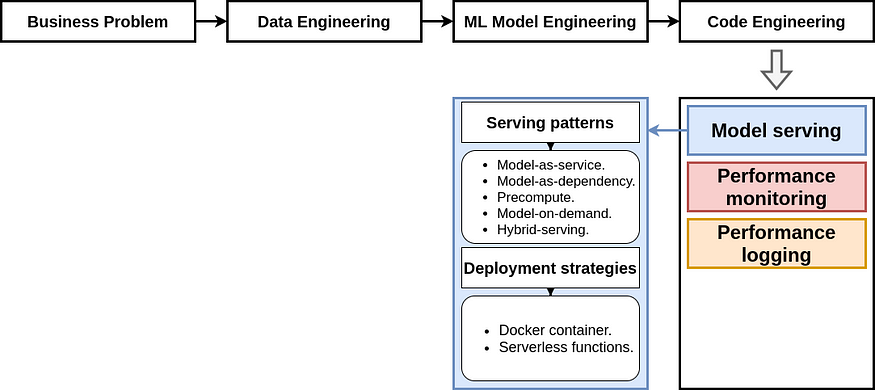
在代码工程步骤中,所选模型将部署到应用程序,并且需要监视和记录其性能。在部署模型之前,需要仔细选择服务模式和部署策略。部署后,需要管理和维护其行为,以确保其正常运行。虽然本教程中没有详细说明这部分,但我计划在不久的将来专门写整篇文章来介绍它。
四、 项目结构
现在,我们已经重点介绍了在手写数字分类中应用的不同 MLOps 步骤,让我们继续构建项目以满足项目需求,同时牢记这些步骤。为此,我将首先介绍一个众所周知的项目结构,然后介绍我的 MLOps 项目结构模板。随着我们添加更多组件,此模板将在稍后更新。
但是,为什么正确构建机器学习项目很重要?嗯,有几个好处:
- 良好的透明度:一个有组织的项目更容易理解,不仅对你,对其他人也是如此。
- 维护简单:结构良好的项目更易于维护和更新,从而节省时间和精力。
- 提高效率:清晰的计划可以减少浪费的时间,并将偏离轨道或丢失重要信息的风险降至最低。
- 良好的重现性和可重复使用性:良好的项目结构可确保项目结果可以轻松复制,并且其组件可以重复使用。
- 轻松协作:当一个项目以清晰和合乎逻辑的方式组织时,其他人就会变得更容易理解和贡献。
总之,正确构建机器学习项目可以提高透明度、效率、可维护性和协作性。
4.1. 千篇一律的数据科学
如本文前面所述,在编写任何代码行之前,我们需要做的第一件事是定义项目结构。这可以通过使用项目结构模板来实现。模板可以是为响应公司/项目需求而建立的公司模板、一组人员或个人创建并发布供其他人使用的公开可用模板,也可以是你自己习惯使用的自定义模板。
该领域最著名的项目结构之一是千篇一律的数据科学,它是:
一个逻辑的、合理的标准化但灵活的项目结构,用于执行和共享数据科学工作。
您可以在下面找到此模板的项目结构,以及每个文件的描述:

4.2 MLOps 项目结构
现在,我们已经介绍了如何执行 MLOps 工作流的不同步骤,接下来让我们定义一个与 MLOps 工作流一致的项目结构模板。Cookiecutter MLOps 模板基于我们之前介绍的 Cookiecutter 数据科学模板。与 Cookiecutter Data Science 一样,我的 Cookiecutter MLOps 模板包括 LICENSE、README、Makefile 和需求文件;以及文档、模型、笔记本、参考、报告、可视化和源文件夹。但是,添加了额外的文件夹(配置),并增强了源和可视化文件夹。
MLOps 项目结构模板具有以下结构:
MLOps_MLflow_mnist_classification
├── configs
│ ├── cnnbased.yaml
│ └── singleoutput.yaml
├── data
│ ├── external
│ │ └── test
│ │ ├── 0_0.png
│ │ ├── 1_0.png
│ │ ├── 1_1.png
│ │ ├── 3_1.png
│ │ ├── 5_1.png
│ │ ├── 7_0.png
│ │ └── 8_0.png
│ ├── interim
│ ├── processed
│ │ ├── test.csv
│ │ └── train.csv
│ └── raw
│ ├── test_images.gz
│ ├── test_labels.gz
│ ├── train_images.gz
│ └── train_labels.gz
├── LICENSE
├── Makefile
├── MLproject
├── mlruns
├── models
├── README.md
├── requirements.txt
└── src├── data│ ├── build_features.py│ ├── dataloader.py│ └── ingestion.py├── models│ ├── cnnbased│ │ ├── hyperparameters_tuning.py│ │ ├── model.py│ │ ├── predict.py│ │ ├── preprocessing.py│ │ └── train.py│ └── singleoutput│ ├── hyperparameters_tuning.py│ ├── model.py│ ├── predict.py│ ├── preprocessing.py│ └── train.py└── visualization├── evaluation.py└── exploration.pyconfigs 文件夹包含所有配置文件,例如模型超参数。
数据文件夹(src 的子文件夹)包括以下文件:
- ingestion.py:用于收集数据。如果需要创建备份、保护私人信息或创建元数据目录,最好在此处执行此操作。
- cleaning.py:用于通过减少异常值/噪声、处理缺失值等来清理数据。
- labeling.py:用于在必要时标记数据。
- splitting.py:用于将数据拆分为测试集和训练集。
- validation.py:用于验证数据(以确保数据已准备好进行训练)。
- build_features.py:此文件已移至此文件夹,因为构建要素意味着将数据集组织到特定结构中。
在模型文件夹(src 的子文件夹)中,每个模型的脚本都组织在模型的文件夹中,包括:
- model.py:用于定义模型体系结构。
- dataloader.py:用于加载要馈送到模型的数据。
- preprocessing.py:用于在将数据馈送到模型之前对其进行预处理。
- train.py:用于训练模型。
- hyperparameters_tuning.py:用于调整模型和/或训练超参数。
- predict.py:用于对随机图像(不是来自数据集)进行预测。
可视化文件夹包括以下内容:
- exploration.py:此文件包括用于在数据工程过程中可视化数据的函数。
- evaluation.py:此文件包括用于可视化训练结果的函数。
这是 MLOps 模板,需要考虑一些重要注意事项:
- 这是一个基本模板,因此可以根据项目要求删除或添加某些文件和文件夹。
- 某些预处理函数可以在所有模型中使用,因此可以创建单个预处理文件并将其移动到数据文件夹以避免重复函数。但是,建议将预处理文件分开,以提高模型的可重用性并防止将来出现潜在问题。
- 在预测脚本中,假定数据来自应用程序而不是数据集,因此可能需要额外的预处理步骤。
4.3 启动新的 MLOps 项目
如果要使用此模板启动机器学习项目,可以使用 GitHub 模板或使用 Cookiecutter 模板,如下所示:
- 要使用 GitHub 模板,首先,您需要在此处访问模板页面。然后,单击绿色按钮“使用此模板”,您将必须选择是“创建新存储库”还是“在代码空间中打开”:

- 要使用 Cookiecutter 模板,您首先需要使用以下命令安装 Cookiecutter:
pip install cookiecutter 或:
conda config --add channels conda-forge
conda install cookiecutter 然后在命令行运行以下命令:
cookiecutter https://github.com/Chim-SO/cookiecutter-mlops 下面是手写数字分类的示例配置,您可以通过填写所需参数来自定义该配置。按 Enter 键将保留您不希望更改的任何参数的默认值:
project_name [project_name]: MLOps_MLflow_mnist_classificationrepo_name [mlops_mlflow_mnist_classification]: author_name [Your name (or your organization/company/team)]: Chim SOdescription [A short description of the project.]: MNIST classificationSelect open_source_license:
1 - MIT
2 - BSD-3-Clause
3 - No license file
Choose from 1, 2, 3 [1]: 1s3_bucket [[OPTIONAL] your-bucket-for-syncing-data (do not include 's3://')]: aws_profile [default]:Select python_interpreter:
1 - python3
2 - python
Choose from 1, 2 [1]:4.4 使用 MLOps 项目模板进行手写数字分类
在第二部分中,我们讨论了手写数字分类任务的 MLOps 工作流中涉及的不同步骤。使用 MLOps 模板实现该管道将生成以下项目结构:
MLOps_MLflow_mnist_classification
├── configs
│ ├── cnnbased.yaml
│ └── singleoutput.yaml
├── data
│ ├── external
│ │ └── test
│ │ ├── 0_0.png
│ │ ├── 1_0.png
│ │ ├── 1_1.png
│ │ ├── 3_1.png
│ │ ├── 5_1.png
│ │ ├── 7_0.png
│ │ └── 8_0.png
│ ├── interim
│ ├── processed
│ │ ├── test.csv
│ │ └── train.csv
│ └── raw
│ ├── test_images.gz
│ ├── test_labels.gz
│ ├── train_images.gz
│ └── train_labels.gz
├── LICENSE
├── Makefile
├── MLproject
├── mlruns
├── models
├── README.md
├── requirements.txt
└── src├── data│ ├── build_features.py│ ├── dataloader.py│ └── ingestion.py├── models│ ├── cnnbased│ │ ├── hyperparameters_tuning.py│ │ ├── model.py│ │ ├── predict.py│ │ ├── preprocessing.py│ │ └── train.py│ └── singleoutput│ ├── hyperparameters_tuning.py│ ├── model.py│ ├── predict.py│ ├── preprocessing.py│ └── train.py└── visualization├── evaluation.py└── exploration.py由于我们已经描述了每个文件和文件夹的内容,因此我现在将重点介绍可能有点模棱两可的最重要步骤。
- 该文件夹包含两个配置文件,每个模型一个。例如,该文件包括模型配置、训练参数、日志记录参数(将在后续教程中讨论)和模型调优参数。
configssingleoutput.yaml
# Data parameters
data:dataset_path : 'data/processed/'# Model parameters
model:name: 'singleoutput'num_units: 224num_layers: 5activation_function : 'sigmoid'# Training parameters
training:batch_size: 128num_epochs: 200loss_function: 'mae'metric: 'mse'# Logging and output parameters
mlflow:mlruns_path: 'file:models/mlruns'experiment_name: 'singleOutput'# Tuning
hyperparameter_tuning:num_layers: [3, 5]num_units: [16, 64, 224]activation_function: ['relu', 'sigmoid']batch_size: [128, 256]loss_function: ['mae']metric: ['mse']num_epochs: [200]- 使用 ,首先将数据下载并存储在 中。然后,它被转换为记录结构,并直接存储到 .
src/data/ingestion.pydata/raw/src/data/build_features.pydata/processed - 在该文件夹中,我添加了一个子文件夹,其中包含一些手写数字的随机图像。脚本将使用这些图像来测试训练模型对新的、看不见的数据的预测。
data/externaltestpredict.py

- 此示例的数据/临时文件夹为空,因为数据处理管道中没有中间步骤。
- 由于数据是经典数据集,因此不会复制每个模型的数据加载器,而是将其从模型文件夹移动到 。
src/data/ - 该脚本概述了用于预测随机图像类的管道。与用于训练模型的预处理管道(涉及调整大小和缩放)不同,预测管道首先修剪图像、反转像素,然后调整大小和缩放图像。
src/models/<model>/predict.py
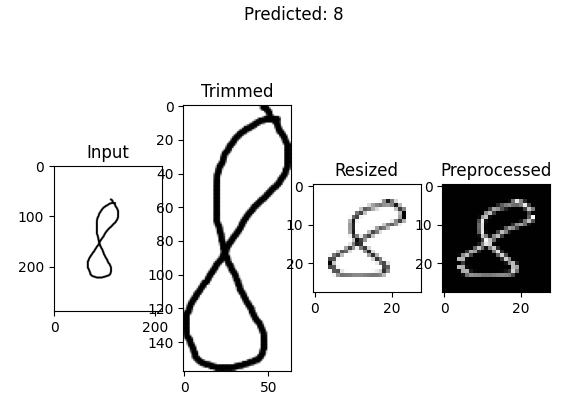
随机图像的数据预处理流水线。
- MLflow 库利用该文件和文件夹,该库是用于管理机器学习管道的平台。下一篇文章将详细介绍这个主题,所以如果你对你来说是新手,请不要担心。
MLprojectmlruns
4.5 如何运行你的项目?
执行 Python 项目有几种方法:交互式运行(逐行执行)、批处理运行(调度 cron 作业或使用作业调度程序)、容器化运行(使用 Docker 或 Kubernetes)、自动化运行(例如使用 MLflow)或分布式运行(使用 Apache Spark 等分布式计算框架)。由于这不是本文的主题,因此让我们使用最简单的方法从项目目录执行以下命令:
python src/data/ingestion.py -r data/raw/ # Download data
python src/data/build_features.py -r data/raw/ -p data/processed/ # Create csv files
python -m src.models.cnnbased.train -c configs/cnnbased.yaml # Train CNN model五、 结论
在本文中,我们提供了一个 MLOps 项目结构模板,并将其应用于手写数字分类问题。我们演示了如何应用 MLOps 工作流来解决此问题,并绘制了一个项目结构模板,您可以将其用作 Cookiecutter 项目或 Github 模板。如果您觉得该模板有帮助,请在 GitHub 上给它加一颗星,以便其他人可以发现它。如果你不熟悉 MLOps,可以阅读我的初学者友好教程。