数据智能产业创新服务媒体
——聚焦数智 · 改变商业
据华尔街日报报道,美国正在考虑进一步收紧对中国AI芯片的出口管制,最早可能在7月初采取行动。
在没有获得许可证的情况下,美国商务部将禁止英伟达等制造商向中国客户运送AI芯片。英伟达专供中国的A800芯片,在无许可证的情况下也将被禁售。
A800是英伟达在2022年三季度推出的特供中国版的显卡芯片。去年9月,美国禁止英伟达等公司向中国出口高端GPU芯片,主要限制显卡算力及带宽,算力上限是4800 TFLOPS,带宽上限是600 GB/s。此禁令一出,导致A100、H100无缘中国市场。
事实上,依据英伟达2022年财报,中国区销售收入占其总收入额高达20%以上,对其至关重要。为了满足禁令要求且兼顾中国市场,英伟达又推出了特供中国版的显卡A800和H800。
根据 MyDrivers 的说法,A800 的运行速度是 A100 GPU 的70%。此外,后推出的H800相比H100互联速率减半,符合美国出口标准的同时特供中国市场。
2022年底至今,在ChatGPT带动下,无论是互联网平台企业还是AI公司纷纷布局大模型。据不完全统计,目前中国10亿参数规模以上的大模型已发布79个。每一个大模型正常运转的背后,都需要算力加持,跟算力划等号的高端GPU都卖爆了,受此影响英伟达市值直接飙涨破万亿美元。
为了获得更高算力,推进大模型训练速度,抢占发展先机,一场关于GPU的军备竞赛正在国内外上演。
在庞大的需求下,即便是性能“阉割版”的A800和H800也一芯难求。据此前界面消息,在大模型火爆发布之前,A800两周即可到货,但现在可能需要4-8周。报道中还提到,现下英伟达也学起了爱马仕,在购买抢手的 GPU 时,也需购买其它产品作为取得优先供应权的“配货”。如果出口禁令进一步升级,A800、H800或将断供中国市场。
大模型需要算力,而GPU恰是AI训练算力之源。对中国而言,AI产业在大模型加持下已进入新赛点,失去高算力芯片对我国AI产业发展而言极为不利,实现GPU国产替代势在必行。
从英伟达崛起之路看国产GPU
一开始,GPU作为加速图形绘制的处理器,由英伟达在1999年发布GeForce 256图形处理芯片时率先提出,当时GPU主要面向的是游戏和PC市场。
由于GPU在处理绘图任务时,能够高效并行处理海量数据,英伟达又进一步将计算机程序模拟为渲染过程,将GPU用于通用并行计算,并在2007年推出了基于CUDA的GPGPU beta版。
相比于图形渲染类GPU,GPGPU能够同时执行多个计算任务,从而大幅提高计算速度和效率。
在AI领域,许多AI算法需要处理大量的数据,计算量庞大。比如,机器学习下的深度学习算法需要处理大量的矩阵运算,如果在传统CPU上训练一个深度学习模型可能需要数周甚至数月的时间,而在GPU仅需要数小时或者数天内完成,从而大幅提高训练速度和降低成本。
自英伟达推出GPGPU后,GPU不再局限于图形计算的游戏和PC市场,进而在AI领域开疆拓土。十几年来,英伟达GPU产品在算力和存储带宽两个方向上,对比CPU都以超10倍、甚至100倍的优势领先,人工智能与GPU的发展可谓相辅相成。
我们知道,GPU的发展符合摩尔定律,即机体电路上可容纳的晶体数目,每隔18个月便会增加一倍,从而性能提升一倍。英伟达GPU硬件性能便以每两年更新一次的节奏保持更新,使英伟达GPU效能提升数十倍,占领了独立显卡技术的制高点。
截至目前,英伟达GPU在图形渲染领域与AMD并驾齐驱;但在通用GPU领域英伟达一骑绝尘,市场占有率超80%。如今随着大模型研究热潮的兴起,无论是大模型的训练还是推理都离不开GPGPU芯片来提供算力支持,全球大模型训练基本依赖英伟达的GPU。
回到国内,如果出口禁令升级,国产GPU能独当一面么?
现下AI需求最大的英伟达GPU A100采用7nm工艺,拥有540亿晶体管,支持FP16、FP32和FP64浮点运算。2022年3月推出的H100集成800亿晶体管,采用4nm工艺,相比A100,H100在浮点运算上快三倍。
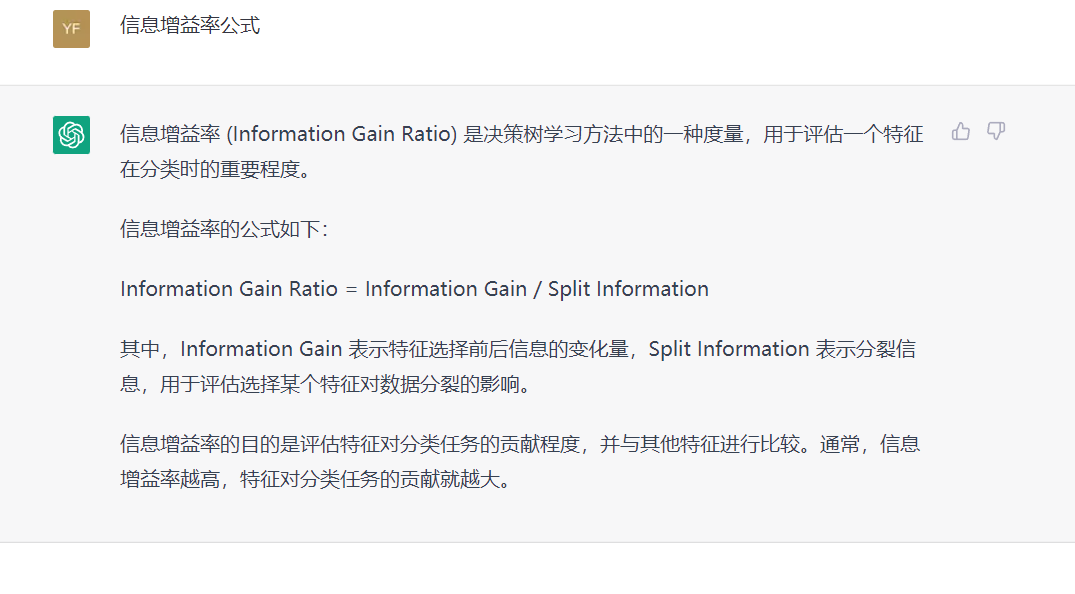
从硬件来看,在GPU芯片设计端,国内GPU厂商中壁仞、天数智芯、沐曦等均已推出采用7nm工艺的GPU,芯瞳半导体、芯动科技、摩尔线程等公司也相继推出GPU产品。
此外,原CPU厂商龙芯、海光等也在加注GPGPU,不过龙芯GPGPU主要是集成在自家SOC中,预计2024年龙芯将流片。海光信息推出DCU属于GPGPU一种。
来源:数据猿,根据公开信息制表
在国内GPU厂商中,景嘉微已成功研发以 JM5系列、JM7系列、JM9系列为代表的、具有自主知识产权的图形处理芯片,并实现了规模化商用,在国内GPU领域处于领先地位,是国内唯一一家GPU营收突破10亿元的公司,2022年净利润近3亿元。
英伟达2024财年一季度营业收入为71.92亿美元(折合人民币约507.82亿元),净利20.43亿美元(折合人民币约144.25亿元。相比之下,景嘉微的整年营收仅是英伟达一个季度营收的1%,更不要说其他GPU初创企业的差距。
“中国GPU厂商的设计能力并不差,但整体产业链的能力还落后5-10年。”华院计算技术总监杨小东在采访中表示。“可以看到,近几年一些GPU初创公司,成立仅2-3年就可以设计出一款性能还不错的GPU,但设计之后能不能顺利流片,能不能量产,是否可用,这中间涉及了众多环节。一次流片未必成功,即便流片成功,到规模化量产,成本控制这一块还有很长的一段路要走。”
以芯片代工为例,台积电是全球代工龙头,先进制程方面已经实现3nm量产,2nm试产。国内中芯国际目前可以实现14nm量产、7nm在研,跟台积电至少有三代技术差。
现阶段国产GPU厂商设计的7nm芯片,国内代工厂由于技术问题尚且无法提供流片服务,那么GPU厂商大概率还是选择先进工艺成熟的台积电流片。据业内人士陈飞透露,初创企业找台积电流片,不仅要高额代工费(2-3亿人民币),流片需要的材料还需要自己找,然后带着材料找台积电流片……
一颗芯片从设计到量产,流片属于非常关键的环节。当芯片完全设计出来以后需要按照图纸在晶圆上进行蚀刻,采用什么样的制程工艺,多大尺寸的晶圆,芯片的复杂程度都会影响这颗芯片的流片成功率和成本,而且许多芯片都不是一次就能流片成功的,往往需要进行多次流片才能获得较为理想的效果。流片是一件非常烧钱的事,多几次流片失败,可能就会把公司搞垮。
对初创GPU厂商来说,从产品设计到落地漫漫长路,又因摩尔定律2年性能翻倍,不得不加速快跑。但当他们攻克硬件难题后,会发现“软件生态”才是国产GPU无法撼动英伟达的根本原因。
CUDA是英伟达最深的护城河
软件、算法与生态是GPU厂商比拼的软实力,也是一款芯片从“能用”到“好用”的关键。
一般而言,GPU生态基本由软件构成,需要在算法平台上完成。基于平台算法去适配各种API接口、下游应用以及其所需要的各种各样的函数。虽然国内GPU在硬件性能上的差距正逐步缩小,但软件生态上的差距巨大。在访谈中,多家GPU厂商谈到,CUDA是英伟达最深的护城河。
CUDA究竟是什么呢?
CUDA(计算统一设备架构)是一种用于高性能计算的编程模型和应用程序接口。它提供了一种简单、高效的方式来访问GPU的计算能力,使得开发者可以方便地编写跨平台GPU程序。
简单讲,CUDA就是英伟达独家的并行计算平台,通过CUDA提供的API接口来做应用开发,调用英伟达GPU的运算能力,使开发者能够为GPU的并行处理能力构建软件。
“对芯片下游的应用厂商来说,GPU具体配备了多大内存、采用了怎样的硬件架构,他们可能并不关心。他们关心的是,在GPU硬件上能跑出怎样的性能,这其实是软件层面所决定的。”陈飞说。
遵循摩尔定律的GPU,两年不到就要推出新产品,不然就会在竞争中掉队。所以,在硬件上英伟达很难摆脱对手。
但在CUDA平台发布后,一切就发生了变化。英伟达所有芯片设计都与CUDA兼容,且用CUDA平台构建软件能发挥英伟达GPU100% 的性能,所以但凡是英伟达GPU的用户都需要用CUDA,从而培养了用户使用习惯。
近两三年GPU国产替代热度高涨,各家GPU硬件有各自的优势,某些数据精度也能跟英伟达PK,但唯独软件生态是短板。对于此,陈飞谈到“软件开发是需要时间的,需要不断增加用户来推动软件迭代,依据用户实际需求来完善软件开发。而且需要软硬件协同开发,这是我们国内GPU初创企业在研发第一代产品时候最容易忽略的。”
从2006年英伟达推出CUDA到现在,英伟达花费近二十几年的时间打造了CUDA软件平台。“首先它是不开源的,所有IP都掌握在英伟达手里。其次它汇集了400万的开发者,这些用户每天都在给反馈,从而形成一种‘滚雪球’似的良性循环:好的性能带来好的生态,好的生态又有助于更好的性能,进而形成生态壁垒。”陈飞表示。
目前,几乎所有跟AI相关的应用开发的厂商,都在基于CUDA平台来写代码,所有 AI 芯片,各种 xPU 们,在落地之前,做的第一件事就是匹配 CUDA。
对于国产GPU生态建设,华院计算技术总监杨小东认为:“只卖GPU硬件是不行的,为了用好GPU还需要完善一系列生态配套,比如驱动、软件等等,如果软件框架支持不了,那么大家想用也用不上。目前,国产GPU尚未达到完全市场化的程度,处于市场开拓的早期,软硬件的原因都有。”
必须承认的是,英伟达CUDA生态建设上的成功并不是一蹴而就的,十几年的漫长积累才形成了“聚沙成塔,聚水成涓”的局面,庞大的用户群需要慢慢养成。对此,天数智芯产品线总裁邹翾认为,与国际主流产品相比,国内的GPU在旗舰级上是有差距的;而国内的客户可能对于国内的GPU产品还不够了解,也需要时间去培养客户。
国产通用GPU从0到1,实现商业化可用
但值得肯定的是,国产通用GPU已打开局面。
如今,全球GPU市场已经形成垄断局面,相比于图形渲染GPU,通用GPU似乎发展前景更为广阔。
“最关键一点,AI是一个在不断增长的蓝海市场。”杨小东在谈及国产通用型GPU比渲染型GPU发展更为迅速的现象时表示。“AI市场潜力足够大,英伟达不可能全部吃下。随着英伟达从国内市场退出,国产厂商可以尝试吃掉英伟达的一部分蛋糕。从趋势上说,国产GPGPU发展更快、更热闹。”
2018年启动芯片设计的天数智芯,在开发首款产品之初,即瞄准通用GPU产品的通用性及AI领域广泛的应用场景。数智芯产品线总裁邹翾告诉数据猿:“从国内GPU整体现状来看,与国外巨头仍然存在一定的差距,但经过前几年AI市场的淬炼之后,已然实现了国产GPGPU‘从0到1’的突破,达到可用的程度。未来,我们将一直坚持通用GPU战略,挖掘通用GPU市场并推出针对市场及用户需求的优质产品,利用先发优势,进一步根据用户反馈普及市场应用情况,加速产品迭代升级。”
目前天数智芯已经有两款通用GPU产品天垓、智铠落地,可以支持当下用户的一些需求,下游应用场景广泛。可应用于训练、推理、通用计算、新算法研究等场景,服务于互联网、安防、运营商、医疗、教育、金融及自动驾驶等各相关行业。
除天数智芯外,国产GPU厂商中2019年成立的壁仞,第一代GPGPU产品壁砺系列在2022年底已经量产,并获得了一些订单。登临科技的通用GPU系列产品—Goldwasser™也已量产,此前已加入由飞桨发起的“硬件生态共创计划”,通过各自在软硬件产品的优势,实现强强联合,共推AI产业化落地。
炼AI大模型必交“GPU税”
2023年,ChatGPT迅速崛起,一股AI热浪正席卷全球。
考量模型的重要标准之一是大参数。当模型规模达到一定程度时,任务性能会出现明显的突变。大语言模型的基础具有很强的可扩展性,可以实现反复自我迭代,参数对大模型性能起到明显作用。而参数量越多,意味着消耗的算力资源越多。
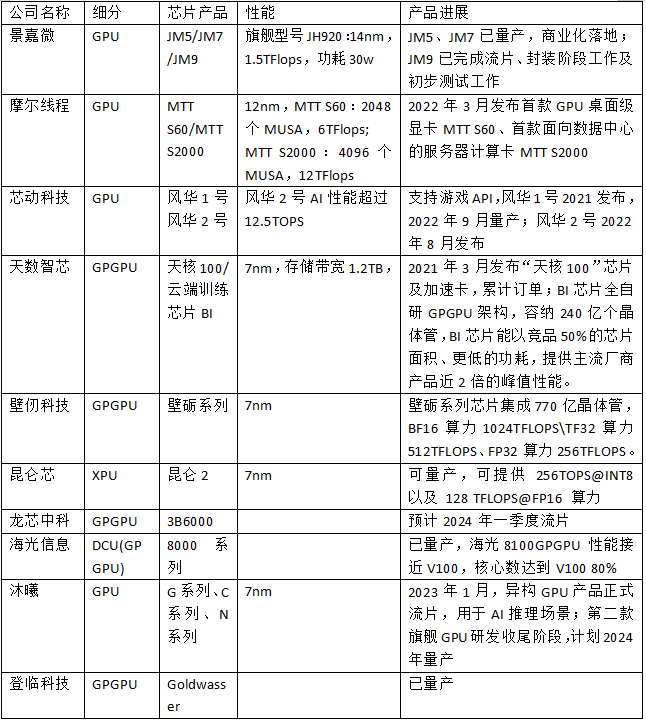
由此,大模型的出现带来了算力的增量需求。根据Verified Market Research数据,2020年,全球GPU市场规模为254.1亿美元(约合人民币1717.2亿元)。随着需求的不断增长,预计到2028年,这一数字将达到2465.1亿美元(约合人民币1.67万亿元),年复合增长率(CAGR)为32.82%。
在英伟达联合发布的论文中,给出了ChatGPT训练时间的经验公式。在这一论文中,训练175B GPT-3需要34天,使用了1024块A100 GPU。
囤A100就相当于囤算力。目前,A100官方售价是1万美金,换算成人民币大概是7.2万,现在已经炒到15万-20万/片。可以想象,通用GPU市场需求之旺盛,市场之广阔。
近几年,在政策与需求的双轮驱动中,“为国分忧”国产GPU初创企业纷纷涌现。
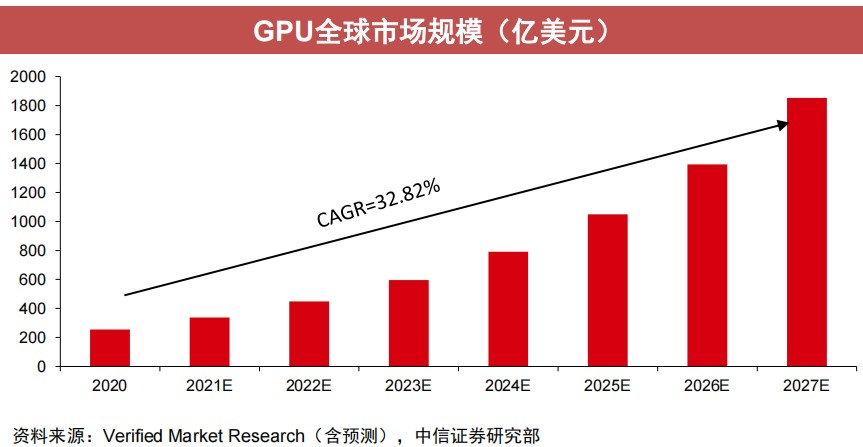
据不完全数据统计,国产GPU融资在2021年迎来高峰,总融资额突破100亿,达到126.35亿元。即便2022年融资总额“腰斩”,但在近8个完整年度的融资表现中,依然位列第二。2020年-2022年均是GPU投融资大年。
制图:数据猿,公开数据统计
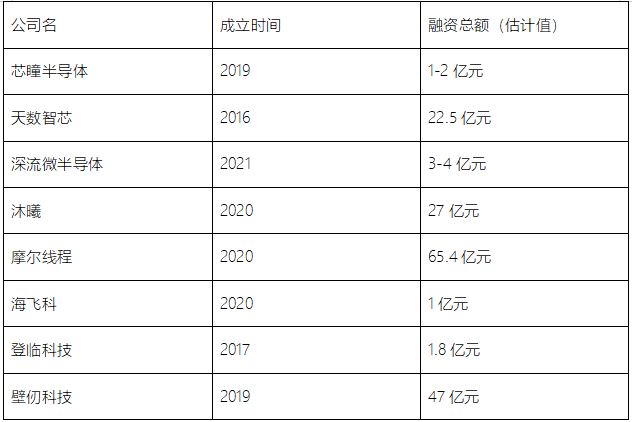
制表:数据猿,公开数据统计
众多成立2-3年的初创企业获得了多轮次巨额融资,但如果对照GPU芯片研发本身来说,似乎并不多。陈飞透露,一款GPU从设计到正式落地,整体花费大致要20几亿人民币,做GPU是非常“烧钱”的一件事。
除了“烧钱”,GPU产品从开发到流片到反片调优,然后正式发布这个完整周期,大概需要一年半到两年甚至更长的时间。
对初创企业来说,硬件层面需要跨越产业链、成本难题;软件层面需要培养客户,软硬协同……国产GPU之路注定艰难,但艰难的路,才是上坡路。
谈及国产GPU未来,邹翾认为,随着时间的推移,国产GPU性能不断攀升、应用将全面开花,有望在5~10年实现追赶。应用落地是提升国产GPU实力的最佳“试验田”。一方面GPU从可用到好用还需要技术和时间积累,需要积累口碑、扩大品牌效应。另一方面,国产GPU可着力应用落地,加大与客户合作力度,在打开局面之后再逐渐扩大领地。
(注:文中陈飞为化名)
文:木阳 / 数据猿