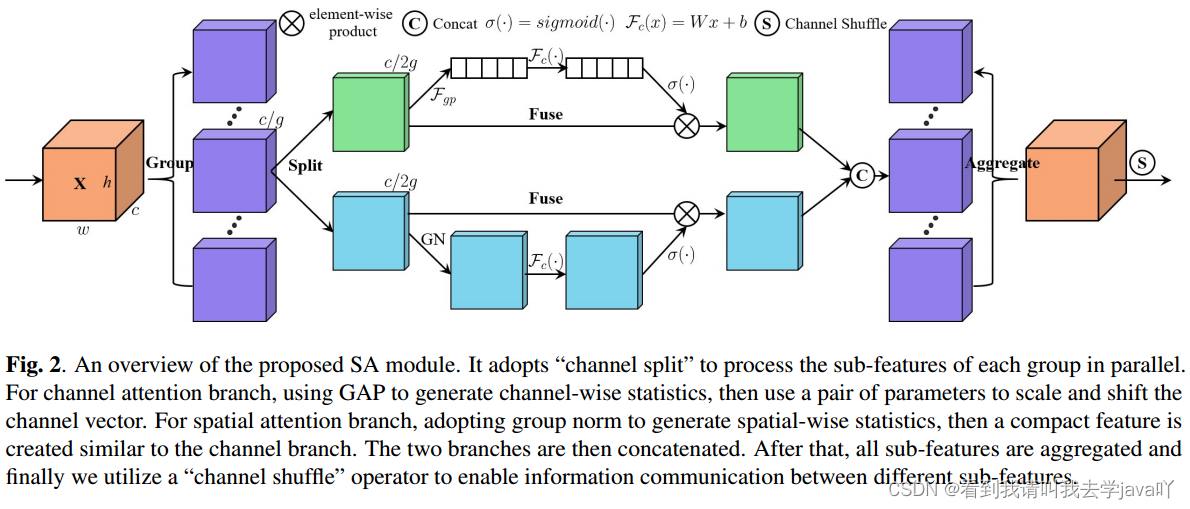
广泛应用的注意力机制主要有空间注意力机制和通道注意力机制,其目的分别是捕捉像素级的成对关系和通道依赖关系。虽然将两种机制融合在一起可以获得比单独更好的性能,但计算开销不可避免。因而,本文提出Shuffle Attetion,即SA,以解决这个问题。SA采用Shuffle Units有效地结合两种注意力机制。具体来说,SA首先将通道维度分组为多个子特征,然后并行处理。对于每个子特征,SA利用Shuffle Units描述空间和通道维度上的特征依赖关系,然后对所有子特征进行聚合,采用channel shuffle算子实现不同子特征间的信息通信。
1.1 背景
注意力机制分为两种,通道注意和空间注意,都是通过不同的聚集策略、转换和强化函数,从所有位置聚集相同的特征来增强原始特征。
GCNet和CBAM将通道注意和空间注意整合到一个模块中,在取得显著结果的同时,也存在存在收敛困难或计算负担过重的问题。
ECA-Net通过使用一维卷积简化了SE模块中信道权重的计算过程;SGE将通道的维度划分为多个子特征表示不同的语义,使用注意掩码在所有位置缩放特征向量,对每个特征组应用空间机制。然而这些网络没有充分利用空间注意和通道注意之间的相关性,致使其效率较低。
本文提出Shuffle Attention 模块,即SA。该模块按通道维度分组为子特征。对于每个子特征,SA采用Shuffle Unit同时构建通道注意和空间注意。对于每个注意模块,本文设计了一个覆盖所有位置的注意掩模,以抑制可能的噪声并突出正确的语义特征区域。
2.1 多分支架构
多分支架构背后的原理是“分裂-转换-合并”,即split-transform-merge,这降低了训练数百层网络的难度。
InceptionNet系列是成功的多分支架构,其中每个分支都精心配置了自定义的内核过滤器,以便聚合更多信息和多种功能;ResNets也可以看作是两个分支网络,其中一个分支是身份映射;SKNets和ShuffleNet系列都遵循了InceptionNets的思想,为多个分支提供了各种过滤器,但SKNets利用自适应选择机制来实现神经元的自适应感受野大小,ShuffleNets进一步将channel split和channel shuffle操作合并为单元素操作,以在速度和准确性之间进行权衡。
2.2 特征分组
特征分组学习可追溯至AlexNet,其动机是将模型分配至更多的GPU上。
MobileNets和ShuffleNets将每个通道视为一个组;CapsuleNets将每个分组神经元建模为一个capsule,其中活动capsule中的神经元代表图像中特定实体的各种属性;SGE优化了CapsuleNets,按通道维度划分多个子特征来学习不同的语义。
2.3 注意力机制
注意力机制突出信心量大的特征,而抑制不太有用的特征;自注意力机制会计算一个位置的上下文,作为图像中所有位置的加权和。
SE使用2个FC层对通道关系进行建模;ECA-Net采用一维卷积生成通道权值,降低了SE的复杂度;NL(non-local)通过计算特征图中空间点的关系矩阵生成注意力图;CBAM、GCNet和SGE将空间注意和通道注意顺序结合;DANet通过将来自不同分支的两个注意力模块相加,自适应地将局部特征与其全局依赖结合起来。
下面附上修改代码
有不明白的可以评论区留言
首先在common中添加一下模块
class ShuffleAttention(nn.Module):def __init__(self, channel=512,reduction=16,G=8):super().__init__()self.G=Gself.channel=channelself.avg_pool = nn.AdaptiveAvgPool2d(1)self.gn = nn.GroupNorm(channel // (2 * G), channel // (2 * G))self.cweight = Parameter(torch.zeros(1, channel // (2 * G), 1, 1))self.cbias = Parameter(torch.ones(1, channel // (2 * G), 1, 1))self.sweight = Parameter(torch.zeros(1, channel // (2 * G), 1, 1))self.sbias = Parameter(torch.ones(1, channel // (2 * G), 1, 1))self.sigmoid=nn.Sigmoid()def init_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):init.kaiming_normal_(m.weight, mode='fan_out')if m.bias is not None:init.constant_(m.bias, 0)elif isinstance(m, nn.BatchNorm2d):init.constant_(m.weight, 1)init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):init.normal_(m.weight, std=0.001)if m.bias is not None:init.constant_(m.bias, 0)@staticmethoddef channel_shuffle(x, groups):b, c, h, w = x.shapex = x.reshape(b, groups, -1, h, w)x = x.permute(0, 2, 1, 3, 4)# flattenx = x.reshape(b, -1, h, w)return xdef forward(self, x):b, c, h, w = x.size()#group into subfeaturesx=x.view(b*self.G,-1,h,w) #bs*G,c//G,h,w#channel_splitx_0,x_1=x.chunk(2,dim=1) #bs*G,c//(2*G),h,w#channel attentionx_channel=self.avg_pool(x_0) #bs*G,c//(2*G),1,1x_channel=self.cweight*x_channel+self.cbias #bs*G,c//(2*G),1,1x_channel=x_0*self.sigmoid(x_channel)#spatial attentionx_spatial=self.gn(x_1) #bs*G,c//(2*G),h,wx_spatial=self.sweight*x_spatial+self.sbias #bs*G,c//(2*G),h,wx_spatial=x_1*self.sigmoid(x_spatial) #bs*G,c//(2*G),h,w# concatenate along channel axisout=torch.cat([x_channel,x_spatial],dim=1) #bs*G,c//G,h,wout=out.contiguous().view(b,-1,h,w)# channel shuffleout = self.channel_shuffle(out, 2)return outyolo.py中注册
elif m in [S2Attention, SimSPPF, ACmix, CrissCrossAttention, SOCA, ShuffleAttention, SEAttention, SimAM, SKAttention]:修改yaml文件 以yolov5s为列
# YOLOv5 🚀 by YOLOAir, GPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[-1, 1, ShuffleAttention, [1024]],[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]以上就是完整的改法