文章目录
- 一 基础地图使用
- 二 国内疫情可视化图表
- 2.1 实现步骤
- 2.2 完整代码
- 2.3 运行结果
一 基础地图使用
- 使用 Pyecharts 构建地图可视化也是很简单的。Pyecharts 支持多种地图类型,包括普通地图、热力图、散点地图等。以下是一个构建简单地图的示例,以中国地图为例:
-
首先,确保已安装了Pyecharts 库。可以使用以下命令来安装:
pip install pyecharts -
然后,创建一个 Python 脚本,例如
map_example.py,并输入以下代码:
from pyecharts.charts import Map
from pyecharts.options import VisualMapOpts# 准备地图对象
map = Map()
# 准备数据
data = [("北京市", 99),("上海市", 199),("湖南省", 299),("台湾省", 399),("广东省", 499)
]
# 添加数据
map.add("销售额", data, "china")# 设置全局选项
map.set_global_opts(visualmap_opts=VisualMapOpts(is_show=True,is_piecewise=True,pieces=[{"min": 1, "max": 9, "label": "1-9", "color": "#CCFFFF"},{"min": 10, "max": 99, "label": "10-99", "color": "#FF6666"},{"min": 100, "max": 500, "label": "100-500", "color": "#990033"}])
)# 绘图
map.render("销售额.html")-
使用Pyecharts 的
Map类来创建地图可视化。通过add方法,添加销售额数据,并指定了地图类型为 “china”。然后,通过set_global_opts方法设置了图表的标题和视觉映射选项,以控制颜色映射。 -
运行脚本后,将会生成一个名为
销售额.html的 HTML 文件,其中包含了一个简单的中国地图。
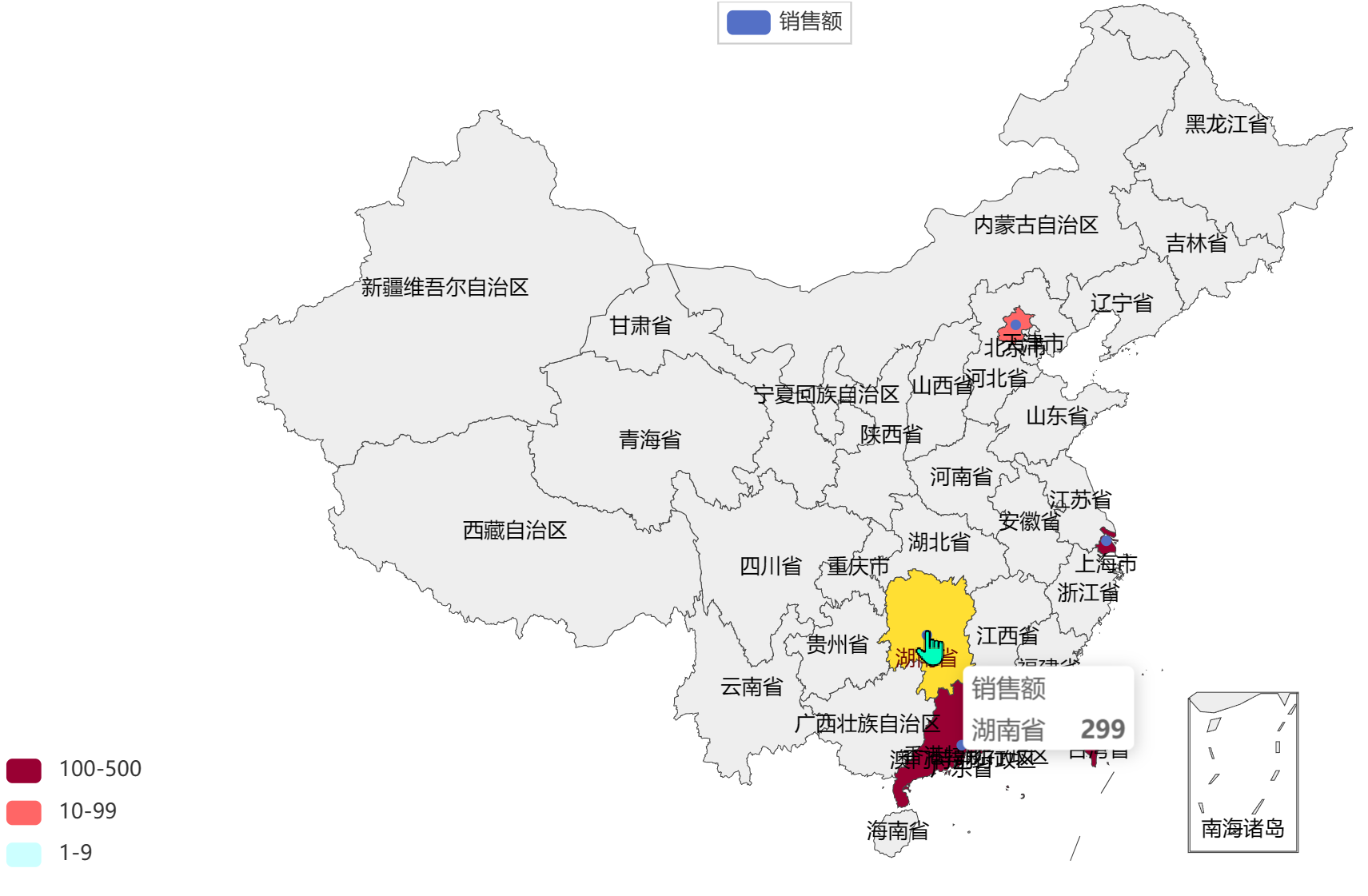
二 国内疫情可视化图表
2.1 实现步骤
- 查看数据文件分析json结构,可使用在线json工具进行分析
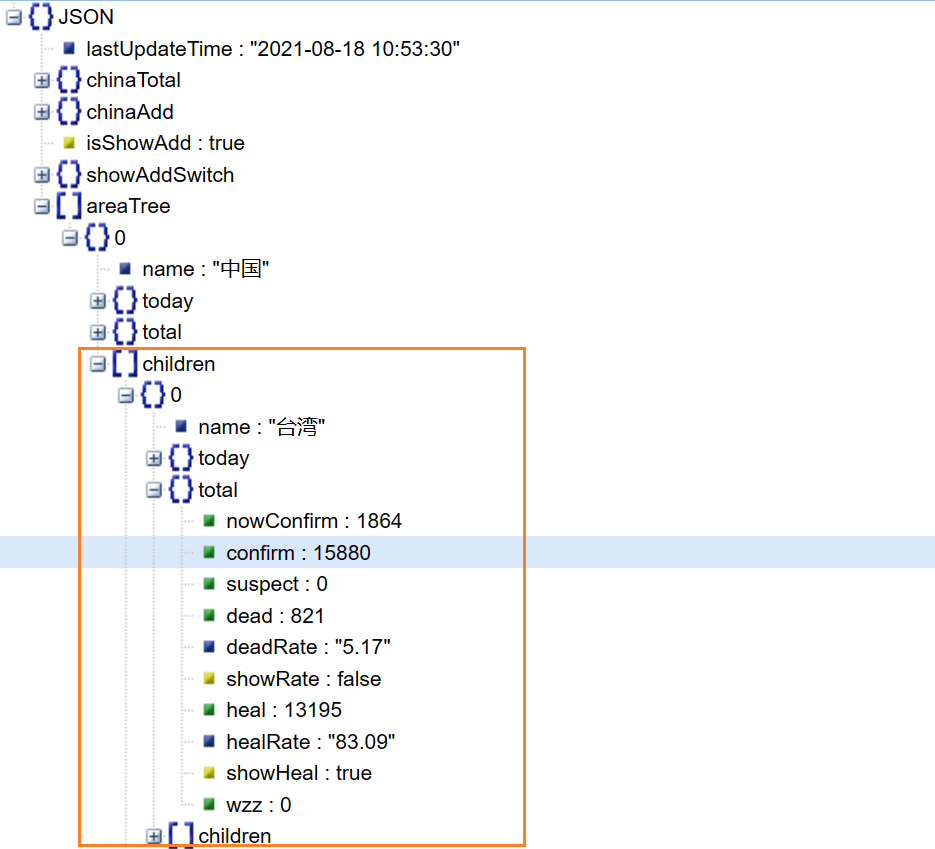
- 根据json文件结构获取省份(name)和确诊人数(confirm)数据,并组成列表
import json# 读取数据文件
f = open("D:/疫情.txt", "r", encoding="UTF-8")
data = f.read() # 全部数据
# 关闭文件
f.close()
# 取到各省数据
# 将字符串json转换为python的字典
data_dict = json.loads(data) # 基础数据字典
# 从字典中取出省份的数据
province_data_list = data_dict["areaTree"][0]["children"]
# 组装每个省份和确诊人数为元组,并各个省的数据都封装入列表内
data_list = [] # 绘图需要用的数据列表
for province_data in province_data_list:province_name = province_data["name"] # 省份名称province_confirm = province_data["total"]["confirm"] # 确诊人数data_list.append((province_name, province_confirm))
- 省份的缩写映射到全称处理
# 字典映射省份缩写到全称
province_mapping = {'台湾': '台湾省','江苏': '江苏省','云南': '云南省','河南': '河南省','上海': '上海市','湖南': '湖南省','湖北': '湖北省','广东': '广东省','香港': '香港特别行政区','福建': '福建省','浙江': '浙江省','山东': '山东省','四川': '四川省','天津': '天津市','北京': '北京市','陕西': '陕西省','广西': '广西壮族自治区','辽宁': '辽宁省','重庆': '重庆市','澳门': '澳门特别行政区','甘肃': '甘肃省','山西': '山西省','海南': '海南省','内蒙古': '内蒙古自治区','吉林': '吉林省','黑龙江': '黑龙江省','宁夏': '宁夏回族自治区','青海': '青海省','江西': '江西省','贵州': '贵州省','西藏': '西藏自治区','安徽': '安徽省','河北': '河北省','新疆': '新疆维吾尔自治区',
}# 处理地区名,替换为全称
processed_data=[(province_mapping.get(area, area), value) for area, value in data_list]
print(processed_data)
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181), ('湖北省', 68286),
('广东省', 2978), ('香港特别行政区', 12039), ('福建省', 773), ('浙江省', 1417), ('山东省', 923), ('四川省', 1179), ('天津市', 445),('北京市', 1107), ('陕西省', 668), ('广西壮族自治区', 289), ('辽宁省', 441), ('重庆市', 603), ('澳门特别行政区', 63), ('甘肃省', 199), ('山西省', 255), ('海南省', 190), ('内蒙古自治区', 410), ('吉林省', 574), ('黑龙江省', 1613), ('宁夏回族自治区', 77),('青海省', 18), ('江西省', 937), ('贵州省', 147), ('西藏自治区', 1), ('安徽省', 1008), ('河北省', 1317), ('新疆维吾尔自治区', 980)]- 创建地图,设置颜色分段映射
from pyecharts.charts import Map
from pyecharts.options import *# 创建地图对象
map = Map()
# 添加数据
map.add("各省份确诊人数", processed_data, "china")
# 设置全局配置,定制分段的视觉映射
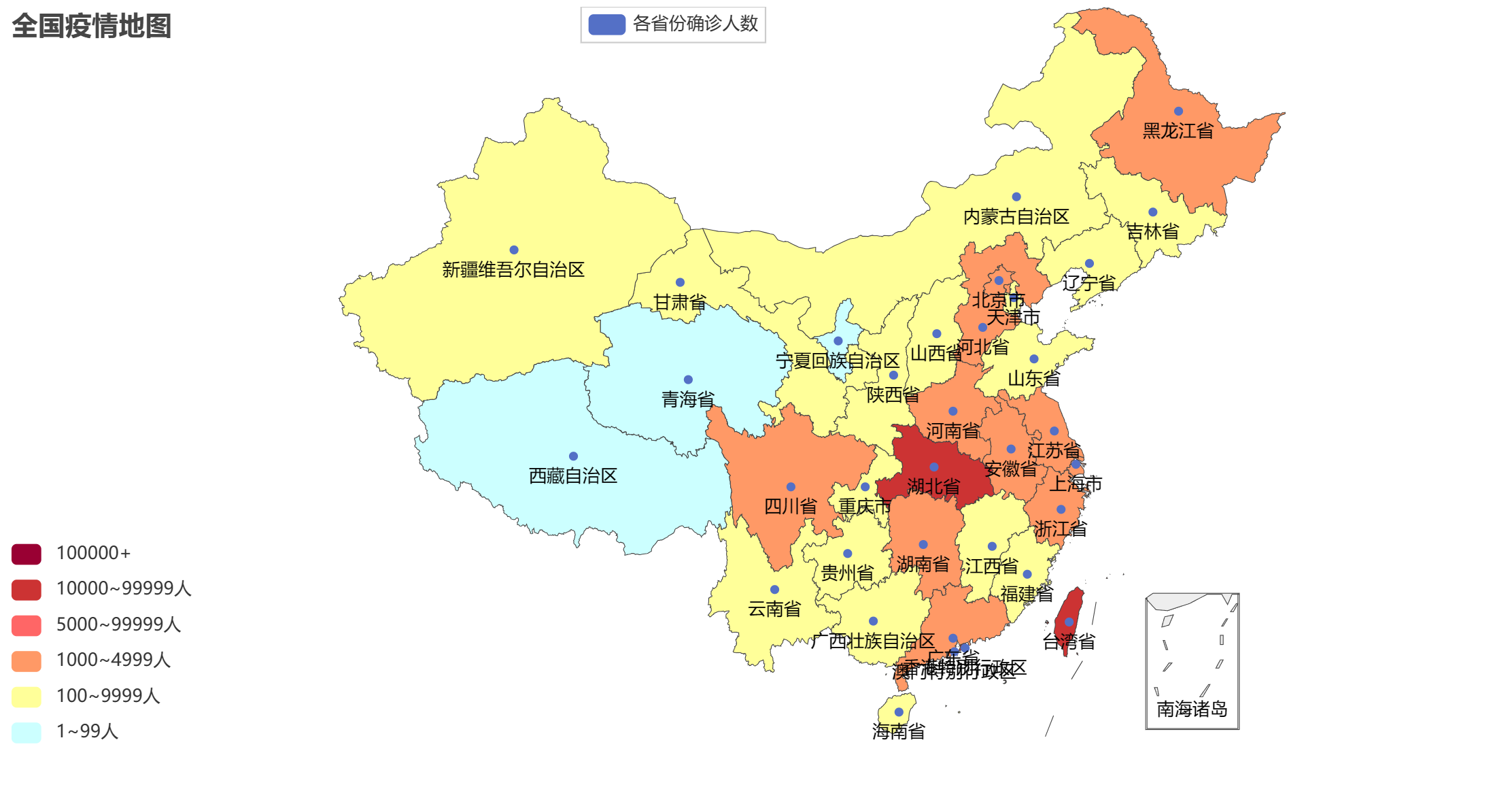
map.set_global_opts(title_opts=TitleOpts(title="全国疫情地图"),visualmap_opts=VisualMapOpts(is_show=True, # 是否显示is_piecewise=True, # 是否分段pieces=[{"min": 1, "max": 99, "label": "1~99人", "color": "#CCFFFF"},{"min": 100, "max": 999, "label": "100~9999人", "color": "#FFFF99"},{"min": 1000, "max": 4999, "label": "1000~4999人", "color": "#FF9966"},{"min": 5000, "max": 9999, "label": "5000~99999人", "color": "#FF6666"},{"min": 10000, "max": 99999, "label": "10000~99999人", "color": "#CC3333"},{"min": 100000, "label": "100000+", "color": "#990033"},])
)
# 绘图
map.render("全国疫情地图.html")
2.2 完整代码
import json
from pyecharts.charts import Map
from pyecharts.options import *# 字典映射省份缩写到全称
province_mapping = {'台湾': '台湾省','江苏': '江苏省','云南': '云南省','河南': '河南省','上海': '上海市','湖南': '湖南省','湖北': '湖北省','广东': '广东省','香港': '香港特别行政区','福建': '福建省','浙江': '浙江省','山东': '山东省','四川': '四川省','天津': '天津市','北京': '北京市','陕西': '陕西省','广西': '广西壮族自治区','辽宁': '辽宁省','重庆': '重庆市','澳门': '澳门特别行政区','甘肃': '甘肃省','山西': '山西省','海南': '海南省','内蒙古': '内蒙古自治区','吉林': '吉林省','黑龙江': '黑龙江省','宁夏': '宁夏回族自治区','青海': '青海省','江西': '江西省','贵州': '贵州省','西藏': '西藏自治区','安徽': '安徽省','河北': '河北省','新疆': '新疆维吾尔自治区',
}# 读取数据文件
f = open("C:/疫情.txt", "r", encoding="UTF-8")
data = f.read() # 全部数据
# 关闭文件
f.close()
# 取到各省数据
# 将字符串json转换为python的字典
data_dict = json.loads(data) # 基础数据字典
# 从字典中取出省份的数据
province_data_list = data_dict["areaTree"][0]["children"]
# 组装每个省份和确诊人数为元组,并各个省的数据都封装入列表内
data_list = [] # 绘图需要用的数据列表
for province_data in province_data_list:province_name = province_data["name"] # 省份名称province_confirm = province_data["total"]["confirm"] # 确诊人数data_list.append((province_name, province_confirm))# 处理地区名,替换为全称
processed_data=[(province_mapping.get(area, area), value) for area, value in data_list]
print(processed_data)# 创建地图对象
map = Map()
# 添加数据
map.add("各省份确诊人数", processed_data, "china")
# 设置全局配置,定制分段的视觉映射
map.set_global_opts(title_opts=TitleOpts(title="全国疫情地图"),visualmap_opts=VisualMapOpts(is_show=True, # 是否显示is_piecewise=True, # 是否分段pieces=[{"min": 1, "max": 99, "label": "1~99人", "color": "#CCFFFF"},{"min": 100, "max": 999, "label": "100~9999人", "color": "#FFFF99"},{"min": 1000, "max": 4999, "label": "1000~4999人", "color": "#FF9966"},{"min": 5000, "max": 9999, "label": "5000~99999人", "color": "#FF6666"},{"min": 10000, "max": 99999, "label": "10000~99999人", "color": "#CC3333"},{"min": 100000, "label": "100000+", "color": "#990033"},])
)
# 绘图
map.render("全国疫情地图.html")2.3 运行结果