最近设计了一个网络服务器程序,对于4C8G的机器配置,TPS可以达到5W。业务处理逻辑是简单的字符串处理。服务器接收请求后对下游进行类似广播的发送。在此分享一下设计方式,如果有改进思路欢迎大家交流分享。
程序运行在CentOS7.9操作系统上,GCC使用4.8.5版本,网络是千兆网。
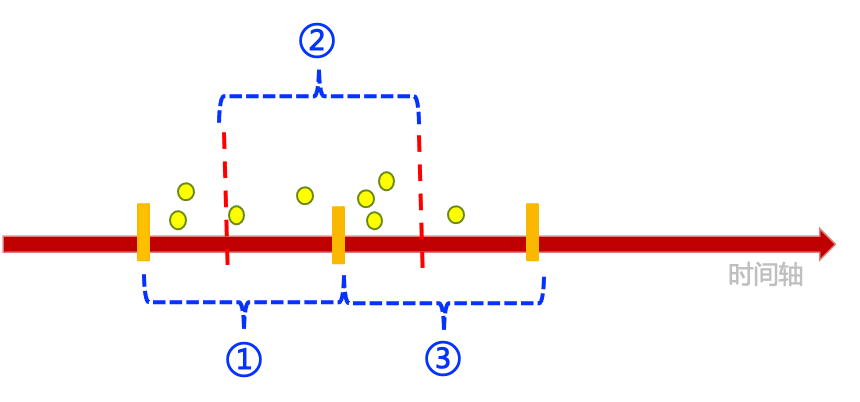
会话状态机
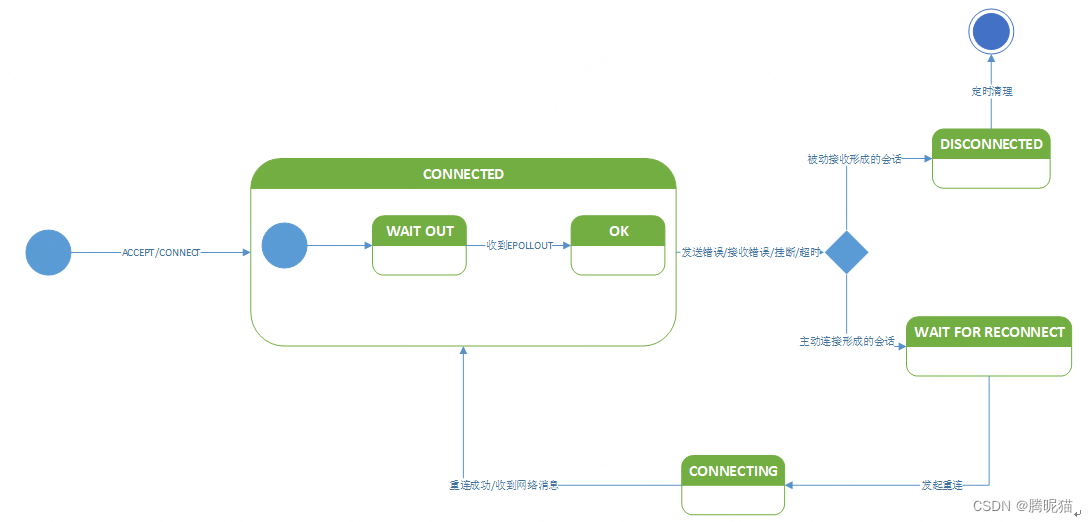
会话存在已连接/正连接/断开/等待重连,这4种状态。如果监听端口有连接请求,创建新会话,状态为连接状态,但是目前会话还不具备发送能力,需要等到套接字上有EPOLLOUT信号时才表示会话已经可以发送了,否则如果没准备好发送的时候发送出现报错,程序会认为会话已经出现了异常情况,然后直接将会话关闭。
服务器主动连接其他服务的时候也会创建一个会话,这个会话具备重连功能。创建的新会话开始也是连接状态。
会话发送接收错误,挂断等很多情况会导致会话进入断开或者等待重连状态。有一个专门的线程会定时检查有没有需要重连的会话,如果有的话会执行重连,在对端没有应答的情况下进入正连接的状态,直到有数据接收到。重连对端直接回应则表示重连成功,进入已连接状态。
网络事务处理线程
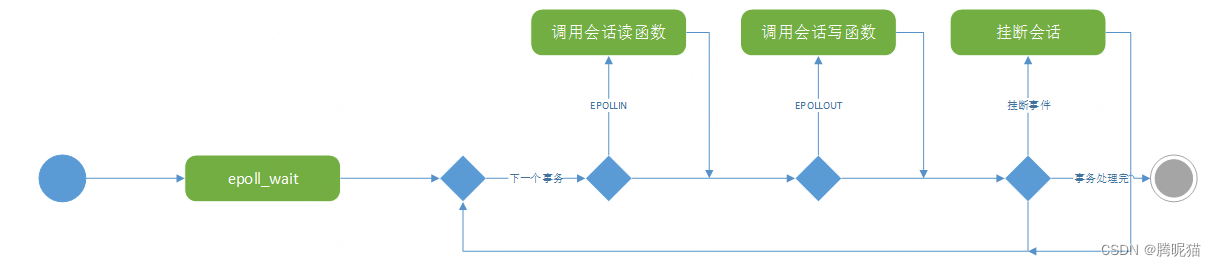
这个线程的作用很简单,有数据来就用event中的会话指针调用读;有写的调用写;有挂断的置挂断标志然后清理会话组。(这里在调用会话读、写的时候会对会话组加读锁;调用清理会话组时会加写锁)
接收流程
展示如下:
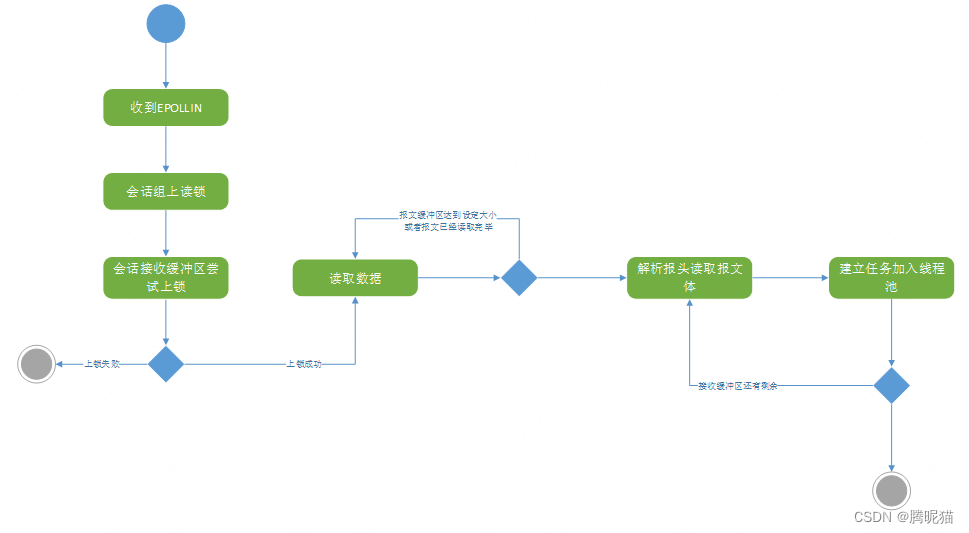
epollin进来之后会进行会话组的读锁锁定,这样会话不可能在上锁期间析构掉,保证了会话指针(包括其内部的接收缓存)的安全。在会话处理内部对消息缓冲区进行了尝试上锁。如果上锁失败则返回(这样保证了如果一个会话的数据特别多,其他网络接收线程也可以及时处理其他会话进来的数据)。
发送流程
如下:

发送线程有两种模式:直接发送、缓冲发送。直接发送模式就是直接将需要发送的数据发送处理,缓冲发送是将数据写到会话的缓冲区,然后进行发送。直接发送的好处就是可以不用复制数据,这样可以减少CPU和内存的占用,但是坏处就是由于没有对于每个会话进行单独的缓冲,因此需要遍历每个会话,对数据进行依次发送。此时,如果有一个会话的接收速度特别慢,就会导致整体的发送效率降低。缓冲发送模式则不存在这个问题,一个会话的接收速度慢,但是它有自己的缓冲区,所以可以直接把数据复制到它的缓冲区中,然后继续下一个会话的发送。
缓冲模式使用双缓冲区,写入和发送缓冲区两者操作不冲突。
系统使用优先直接发送,如果遇到EAGAIN时候直接转到缓冲区发送的方式。这样就可以保证尽量不复制缓冲区,同时在发送遇到阻塞时候也能不影响其他会话。
自检流程
会话组自检

在主线程启动会话组自检工作。会话组自检时对于需要重连的会话进行重连,然后执行各个会话的自检,再执行发送心跳包和删除已关闭会话的工作。
会话自检
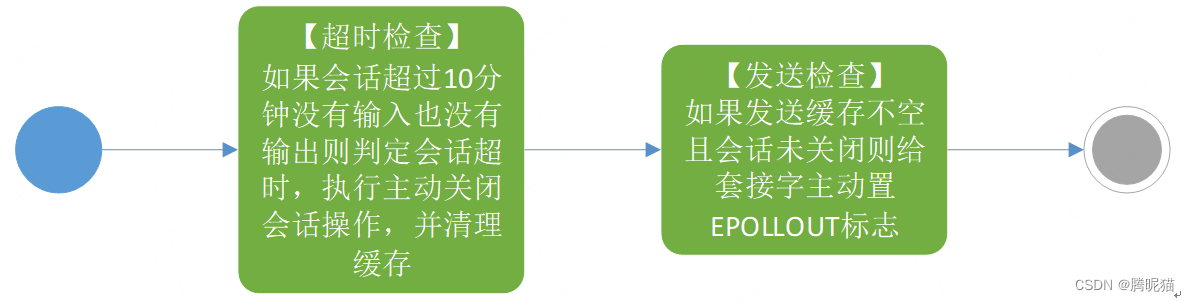
会话自检主要是预防一个会话已经断开了,但是网络事务处理线程没有能够处理这个挂断的事务从而导致死掉的会话还一直存在的问题。
其他设计
封装内存管理类,用于管理内存。内存管理类每次分配固定数值倍数的内存,在析构时自动对管理的内存进行析构。封装读、写操作,封装读整理操作(从内存头部读取一定大小的内存以后将后面的内存拷贝到前面来,这样就不用析构这部分内存,可以下次有数据写入继续使用)。
效果测试
在5W的TPS下可以接收8个下游系统,上下游网络流量已经几乎达到带宽极值,CPU占用率67%,内存在运行48小时后会达到78M。
但是还是存在问题。1)单独使用缓存发送模式的时候有一个问题,就是CPU占用率特别高,每多一个会话则CPU的占用率升值需要升高10%-20%(这里似乎没有CAS导致的CPU占用,同时,使用的锁也全都是普通锁,并没有自旋锁);2)下游接收速度很慢的时候CPU占用率会提高到70%以上。