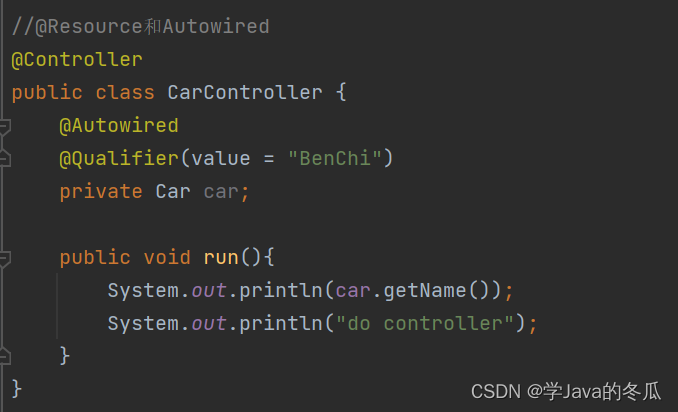
写过Spark批处理的应该都知道,有一个广播变量broadcast这样的一个算子,可以优化我们计算的过程,有效的提高效率;同样在Flink中也有broadcast,简单来说和Spark中的类似,但是有所区别,首先Spark中的broadcast是静态的数据,而Flink中的broadcast是动态的,也就是源源不断的数据流.在Flink中会将广播的数据存到state中.
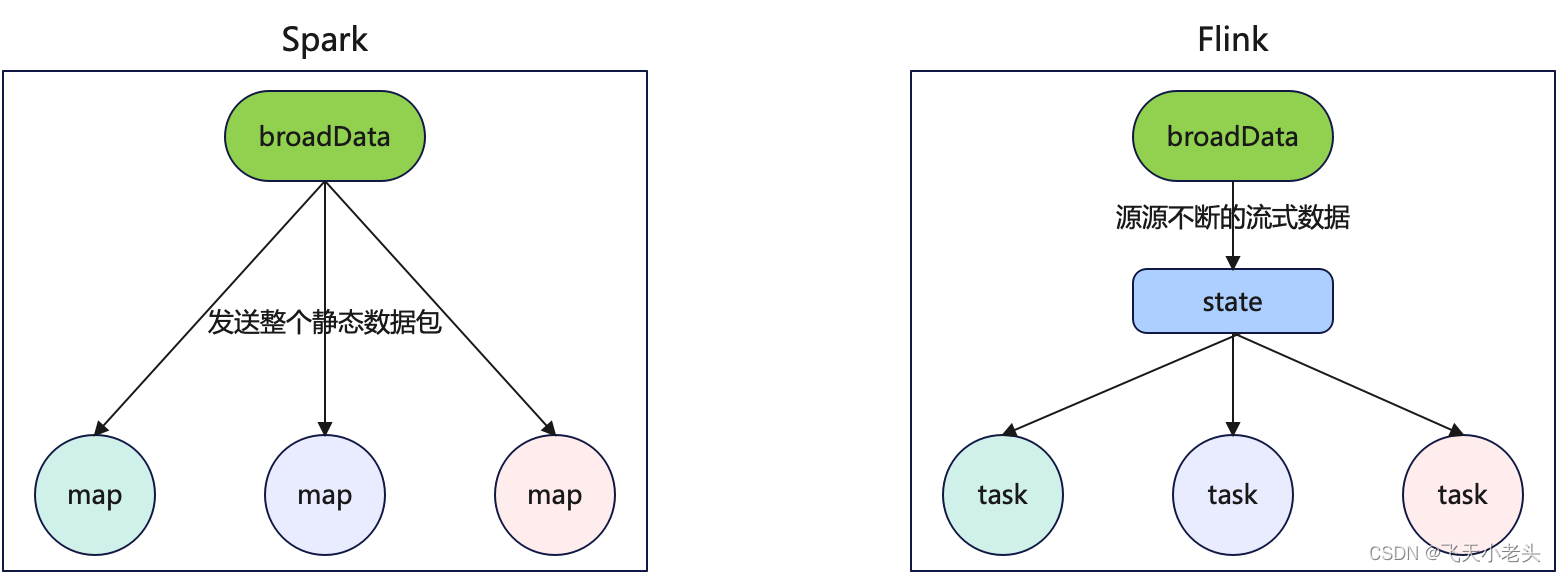
在Flink中主流数据可以获取state中的所有状态数据,使用过window的应该都清楚,当两个streamData中的数据到达窗口的时间刚好错过时就会发生关联不上的情况,如window是2S,sreamData1到达窗口的时间刚好卡在这个2S窗口的尾端,而streamData到达窗口时,这个窗口已经结束了,这种情况就算这两条数据有相同id也无法进行关联了.
但是broadcast会将到达的数据都存储在state中,这样主流到达的每一条数据都可以和state中的广播流数据进行关联比较.
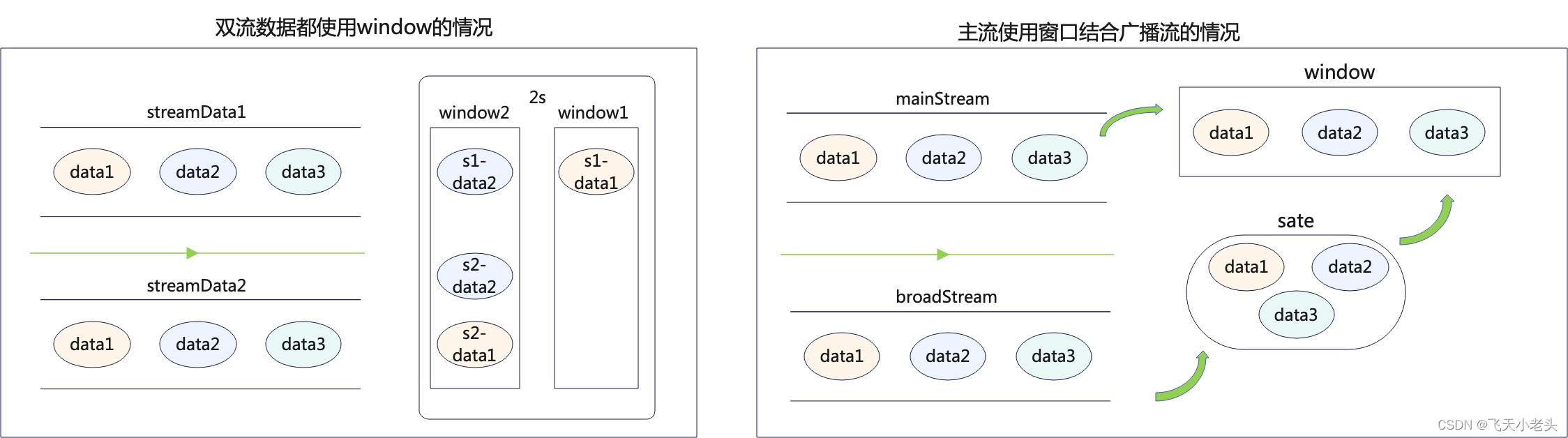
流程图内容可能不够准确,只是为了看起来方便理解.
- 数据源
# 主流数据 ➜ ~ nc -lk 1234 101,浏览商品,2023-08-02 102,浏览商品,2023-08-02 103,查看商品价格,2023-08-04 101,商品加入购物车,2023-08-03 101,从购物车删除商品,2023-08-03 102,下单,2023-08-02 102,申请延期发货,2023-08-03 103,点击商品详情页,2023-08-04 104,点击收藏,2023-08-05 104,下单,2023-08-05 104,付款,2023-08-06 105,浏览商品,2023-08-07 106,浏览商品,2023-08-07 106,加入购物车,2023-08-08 107,浏览商品,2023-08-10# 广播流数据 ➜ ~ nc -lk 5678 101,小明 102,张丽 103,公孙飞天 104,王二虎 106,李四 108,赵屋面 - 代码
import org.apache.flink.api.common.state.BroadcastState; import org.apache.flink.api.common.state.MapStateDescriptor; import org.apache.flink.api.common.state.ReadOnlyBroadcastState; import org.apache.flink.api.common.typeinfo.TypeHint; import org.apache.flink.api.common.typeinfo.TypeInformation; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.api.java.tuple.Tuple3; import org.apache.flink.streaming.api.datastream.*; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction; import org.apache.flink.util.Collector;/*** @Author: J* @Version: 1.0* @CreateTime: 2023/8/11* @Description: 多流操作-广播流**/ public class FlinkBroadcast {public static void main(String[] args) throws Exception {// 构建流环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 设置并行度env.setParallelism(3);// 数据集源1作为主流数据(用户行为日志[id,behavior,date])DataStreamSource<String> sourceStream1 = env.socketTextStream("localhost", 1234);// 将字符串切割处理SingleOutputStreamOperator<Tuple3<String, String, String>> mainSourceStream = sourceStream1.map(str -> Tuple3.of(str.split(",")[0], str.split(",")[1], str.split(",")[2])).returns(new TypeHint<Tuple3<String, String, String>>() {});// 数据源2作为广播流数据(用户信息(id,name))DataStreamSource<String> sourceStream2 = env.socketTextStream("localhost", 5678);// 将字符串切割处理SingleOutputStreamOperator<Tuple2<String, String>> mapStream2 = sourceStream2.map(str -> Tuple2.of(str.split(",")[0], str.split(",")[1])).returns(new TypeHint<Tuple2<String, String>>() {});// 将广播流数据源进行广播/***参数说明* 这里需要我们传入一个MapStateDescriptor,其实就是一个Map结构的数据<k,v>* <String, Tuple2<String, String>>,第一个String类型就是广播流和主流连接的字段,在这个代码中就是id,由实际业务决定* <String, Tuple2<String, String>>,第二个Tuple2<String, String>就是实际广播数据流的数据,由实际业务决定* "userInfo"就是给一个名字,这个自定义无强制要求**/// 先构建一个状态,后面也会使用MapStateDescriptor<String, Tuple2<String, String>> userInfoState = new MapStateDescriptor<>("userInfo", TypeInformation.of(String.class), TypeInformation.of(new TypeHint<Tuple2<String, String>>() {}));BroadcastStream<Tuple2<String, String>> userInfoBroadStream = mapStream2.broadcast(userInfoState);// 将主流数据和广播流数据使用connect连接/*** 我们将数据转变成广播流之后,在Flink中也不知哪个数据流需要使用这个广播流(userInfoBroadStream),* 这个时候就需要我们自己将主流数据和该广播流数据进行连接**/BroadcastConnectedStream<Tuple3<String, String, String>, Tuple2<String, String>> connectedStream = mainSourceStream.connect(userInfoBroadStream);/*** 在process()中有两类函数供我们选择,KeyedBroadcastProcessFunction和BroadcastProcessFunction,* 这里要注意当"connectedStream"是KeyedStream时选择KeyedBroadcastProcessFunction* 当"connectedStream"不是KeyedStream时选择BroadcastProcessFunction就可以.* 使用keyBy算子返回的就是KeyedStream**/SingleOutputStreamOperator<String> resultStream = connectedStream.process(new BroadcastProcessFunction<Tuple3<String, String, String>, Tuple2<String, String>, String>() {// 这个方法写主流数据处理逻辑@Overridepublic void processElement(Tuple3<String, String, String> value, BroadcastProcessFunction<Tuple3<String, String, String>, Tuple2<String, String>, String>.ReadOnlyContext ctx, Collector<String> out) throws Exception {/*** 要注意,这里我们最好从ReadOnlyContext来获取广播状态数据,因为获取只读的状态数据可以保证数据的安全性,* 如果是通过成员变量的方式获取可修改的状态数据,就会存在数据不安全的问题,如在代码逻辑中出现了对状态数据* 修改的代码,那么共享此状态的并行算子可能看到的状态数据不一致,就会导致数据错误或者代码报错.* 而使用ReadOnlyContext就可以保证processElement这个方法中我们只对状态数据进行读取.**/ReadOnlyBroadcastState<String, Tuple2<String, String>> broadcastState = ctx.getBroadcastState(userInfoState);if (broadcastState != null) {// 通过主流中的ID作为key获取广播变量中的用户信息Tuple2<String, String> userInfo = broadcastState.get(value.f0);// 输出数据的形式(id,behavior,date,name)if (userInfo == null) {out.collect(value.f0 + "," + value.f1 + "," + value.f2 + "," + "NULL");} else {out.collect(value.f0 + "," + value.f1 + "," + value.f2 + "," + userInfo.f1);}} else {out.collect(value.f0 + "," + value.f1 + "," + value.f2 + "," + "NULL");}}// 这个方法写广播流数据处理逻辑@Overridepublic void processBroadcastElement(Tuple2<String, String> value, BroadcastProcessFunction<Tuple3<String, String, String>, Tuple2<String, String>, String>.Context ctx, Collector<String> out) throws Exception {// 使用Context获取状态BroadcastState<String, Tuple2<String, String>> broadcastState = ctx.getBroadcastState(userInfoState);// 将数据存入到状态中broadcastState.put(value.f0, value);}});// 打印结果resultStream.print();env.execute("Flink broadcast");} } - 结果
代码内容就不进行详细解释了,注释基本都写清楚了,如有疑问可评论提问,共同探讨.3> 101,浏览商品,2023-08-02,小明 3> 101,商品加入购物车,2023-08-03,小明 3> 102,申请延期发货,2023-08-03,张丽 3> 104,下单,2023-08-05,王二虎 3> 106,浏览商品,2023-08-07,李四 1> 102,浏览商品,2023-08-02,张丽 1> 101,从购物车删除商品,2023-08-03,小明 1> 103,点击商品详情页,2023-08-04,公孙飞天 1> 104,付款,2023-08-06,王二虎 1> 106,加入购物车,2023-08-08,李四 2> 103,查看商品价格,2023-08-04,公孙飞天 2> 102,下单,2023-08-02,张丽 2> 104,点击收藏,2023-08-05,王二虎 2> 105,浏览商品,2023-08-07,NULL 2> 107,浏览商品,2023-08-10,NULL