一,数据库约束
1.1 约束对象
- not null - 该列不能为空
- unique - 保证该列的每一行都不一样
- default - 规定没有给列赋值时的默认值(自定义)
- primary key - not null 和 unique 的结合,会给该列添加一个索引,提高查询速度
- foreign key - 保证一个表中的数据匹配另一个表的数据
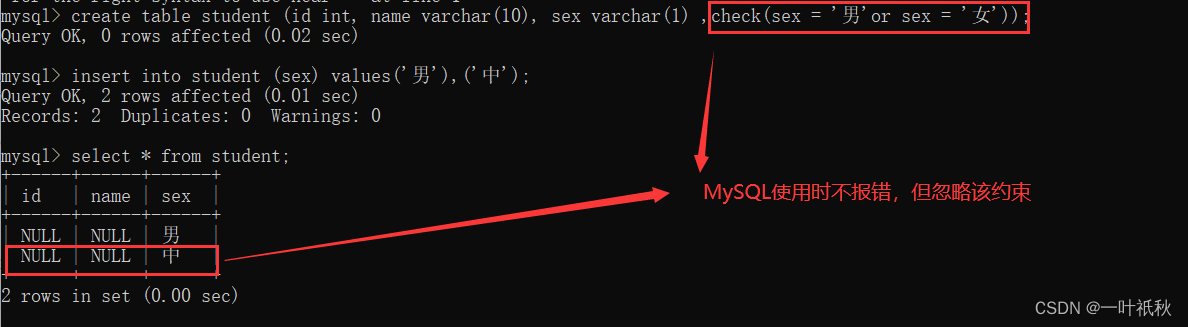
- check - 保证列中的值符合指定的条件,对于MySQL数据库,堆check字句进行分析,但忽略check子句
1.2 null 约束
创建表时,指定某列不为空。

1.3 unique
保证该列的每一个值都是唯一的,即该列没有重复值。

1.4 default
如果该列没有被赋值,那么就会赋值为 default 后面的值:

1.5 primary key - 主键约束
主键同时具有 not null 与 unique 的特点,还可以搭配 自增长auto_increment 来使用(插入字段不赋值时,使用最大值+1,有点类似于JAVA中的枚举)。

注:auto_increment 只能作用于整数类型!!!!
1.6 foreign key - 外键约束
外键用于关联其他表的主键或唯一键,语法:
foreign key (字段名) references 主表(列名)

表示 class_id 与 id 联系起来,添加的class_id必须存在于id中,否则添加失败,即 子表必须依赖父表 。并且不能单独删除 class 表,想删除class表必须先删除student表,因为要是先删除class表,那么student表中 class_id列就没有参考了。
1.7 check 约束
MySQL使用时不报错,但忽略该约束
二,表的设计
- 一对一 :类似于人与身份证号,一个人只能有一个身份证号
- 一对多 :类似于班级与学生,一个班级可以有很多的学生
- 多对多 :类似于学科与学生与老师

三,新增
insert into 表名 【列名....】 select ....

四,查询
4.1 聚合查询
4.1.1 聚合函数
| 函数 | 说明 |
| count (【distinct】列名) | 返回查询到的数据的 数量 |
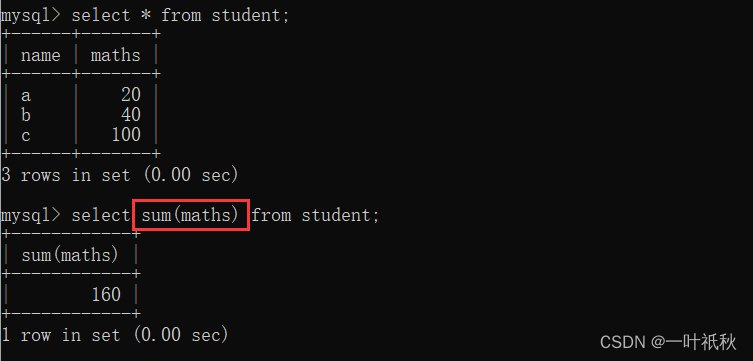
| sum (【distinct】列名) | 返回查询到的数据的 总和 |
| avg (【distinct】列名) | 返回查询到的数据的 平均值 |
| max (【distinct】列名) | 返回查询到的数据的 最大值 |
| min (【distinct】列名) | 返回查询到的数据的 最小值 |
- count

注:count(*) 与 count(0) 效果一样!!!
- sum
- avg
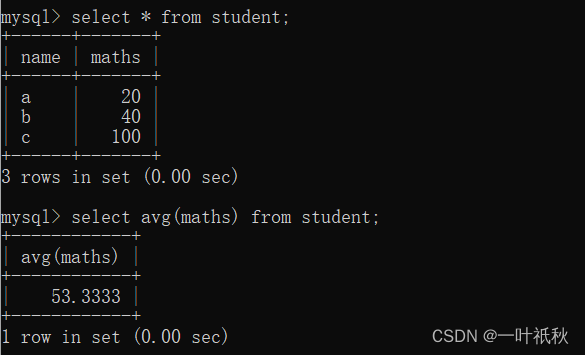
- max

- min

注:当遇到null时,聚合函数不会理会,即不会让null进行运算!!!
4.1.2 group by 字句
分组查询:将表中的数据按照列进行分组,必须和聚合函数一起使用,例如:将一个班的学生分成一组。
select column1,sum(column2),...... from table group by column3...
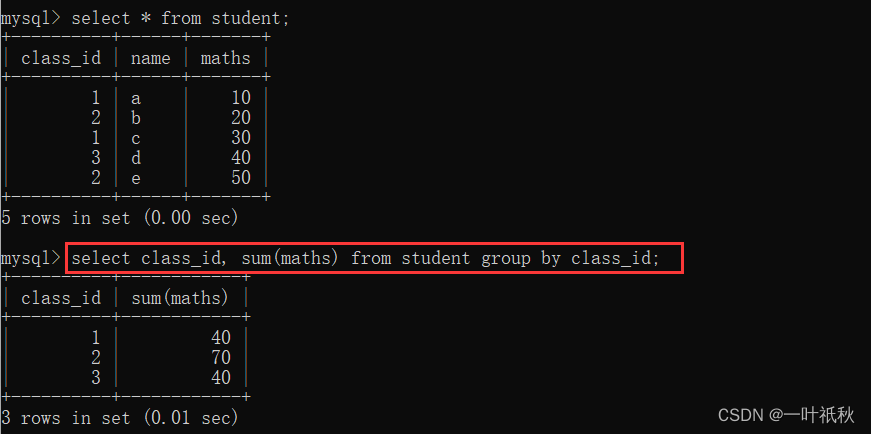
4.1.3 having
group by 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 where 语句,而需要用 having

4.2 联合查询
实际开发中我们所要的数据往往来自不同的表中,所以需要多表联合查询,要了解联合查询,就要先了解笛卡尔积,简单来说就是将多个表排列组合形成一张新的表,然后再根据表之间的联系(比如之前讲的 primary key 与 foreign key 的联系)以及我们的需求筛选出我们要查找到内容。但是需要注意的是,这种操作一般能不用就不用,因为要查找的内容过于庞大,会导致服务器阻塞(当然在自己的库试试没事,毕竟没多少数据)
- 内连接
两种写法:
select column... from 表1 join 表2 on 条件1 and 条件2...;
select column... from 表1 ,表2... where 条件1 and 条件2...;
//可以使用别名
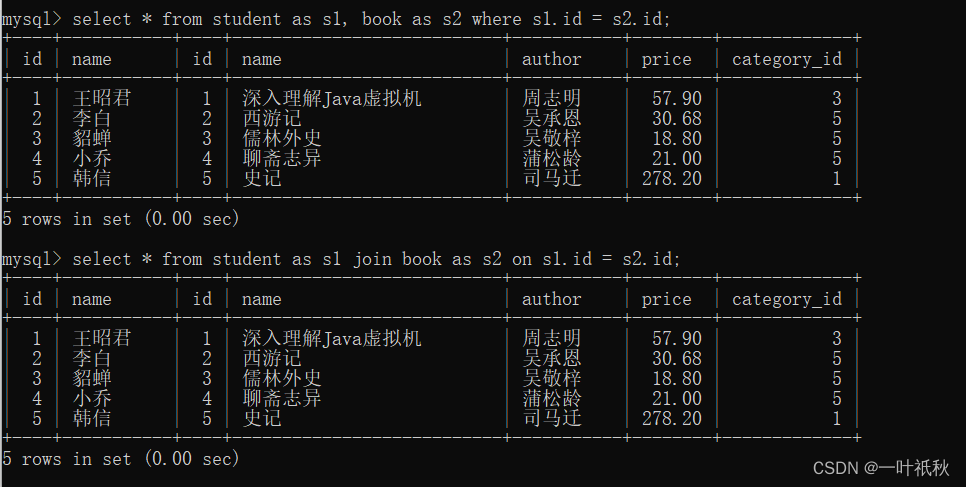
- 外连接
select column... from 表1 left/right join 表2 on 条件1 and 条件2...;

画个图看一看内连接与外连接的区别:

- 自链接
顾名思义就是指同一张表连接自身进行查询
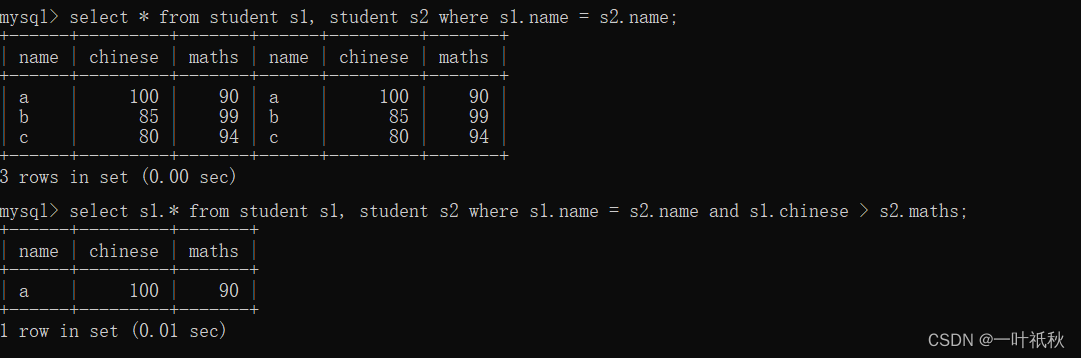
- 子查询
简单来说就是 select 和 select 可以套用
例如:
select * from student where class_id = (select class from student where id in(1,2,3));
- 合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all。使用union 和 union all 时,前后查询的结果集中,字段需要一致.
例如:
select * from stduent where age < 20 union / union all select * from student where id < 10;
union 可以自动去重,union all 不去重。