原文档:使用单层全连接SNN识别MNIST — spikingjelly alpha 文档
代码地址:完整的代码位于
activation_based.examples.lif_fc_mnist.pyGitHub - fangwei123456/spikingjelly: SpikingJelly is an open-source deep learning framework for Spiking Neural Network (SNN) based on PyTorch.
ZhengyuanGao/spikingjelly: 开源脉冲神经网络深度学习框架 - spikingjelly - OpenI - 启智AI开源社区提供普惠算力! (pcl.ac.cn)a
本文补充一些细节代码以解决运行报错问题,并提供可视化代码,解释核心代码作用以辅助SNN初学者快速入门!
目录
1.网络定义
2.主函数
2.1参数设置
2.2主循环
3.可视化
3.1准确率
3.2测试图片与发放脉冲
3.3脉冲发放与电压
4.完整代码
lif_fc_mnist.py(为减少运行耗时,迭代次数设置为1)
lif_fc_mnist_test.py
1.网络定义
class SNN(nn.Module):def __init__(self, tau):super().__init__()self.layer = nn.Sequential(layer.Flatten(),layer.Linear(28 * 28, 10, bias=False),neuron.LIFNode(tau=tau, surrogate_function=surrogate.ATan()),)def forward(self, x: torch.Tensor):return self.layer(x)(1)super:继承父类torch.nn.Module的初始化方法
(2)Sequential:顺序方式连接网络结构,首先将输入展平为一维,定义全连接层,输入格式28*28,输出10个神经元。Neuron.LIFNode为脉冲神经元层,用于对全连接层的激活,指定膜时间常数与替代函数(解决不可导问题)
(3)forward:重写前向传播函数,返回网络输出结果
2.主函数
2.1参数设置
(1)使用命令行设置LIF神经网络的超参数
parser = argparse.ArgumentParser(description='LIF MNIST Training')parser.add_argument('-T', default=100, type=int, help='simulating time-steps')parser.add_argument('-device', default='cuda:0', help='device')parser.add_argument('-b', default=64, type=int, help='batch size')parser.add_argument('-epochs', default=100, type=int, metavar='N',help='number of total epochs to run')parser.add_argument('-j', default=4, type=int, metavar='N',help='number of data loading workers (default: 4)')
# 添加 default='./MNIST' 以解决无下载所需文件夹问题----------------------------------------parser.add_argument('-data-dir', type=str, default='./MNIST', help='root dir of MNIST dataset')
# -----------------------------------------------------------------------------------------parser.add_argument('-out-dir', type=str, default='./logs', help='root dir for saving logs and checkpoint')parser.add_argument('-resume', type =str, help='resume from the checkpoint path')parser.add_argument('-amp', action='store_true', help='automatic mixed precision training')parser.add_argument('-opt', type=str, choices=['sgd', 'adam'], default='adam', help='use which optimizer. SGD or Adam')parser.add_argument('-momentum', default=0.9, type=float, help='momentum for SGD')parser.add_argument('-lr', default=1e-3, type=float, help='learning rate')parser.add_argument('-tau', default=2.0, type=float, help='parameter tau of LIF neuron')
注:在代码上述标记位置添加 default='./MNIST' 以解决无下载所需文件夹问题
超参数含义如下图所示:

(2) 参数代入:是否自动混合精度训练(PyTorch的自动混合精度(AMP) - 知乎 (zhihu.com))
scaler = Noneif args.amp:scaler = amp.GradScaler()
(3)参数代入:优化器类型
optimizer = Noneif args.opt == 'sgd':optimizer = torch.optim.SGD(net.parameters(), lr=args.lr, momentum=args.momentum)elif args.opt == 'adam':optimizer = torch.optim.Adam(net.parameters(), lr=args.lr)else:raise NotImplementedError(args.opt)(4)是否恢复断点训练(if args.resume:从断点处开始继续训练模型)
if args.resume:checkpoint = torch.load(args.resume, map_location='cpu')net.load_state_dict(checkpoint['net'])optimizer.load_state_dict(checkpoint['optimizer'])start_epoch = checkpoint['epoch'] + 1max_test_acc = checkpoint['max_test_acc'](5)泊松编码
encoder = encoding.PoissonEncoder()2.2主循环
(1)在主循环之前补充创建两个空数组,用于保存训练过程中的准确率,以便后续绘制曲线

(2)加载训练数据(测试数据代码大同小异,不另外分析)
for img, label in train_data_loader:optimizer.zero_grad()img = img.to(args.device)label = label.to(args.device)label_onehot = F.one_hot(label, 10).float()- 循环读取训练数据,在每次循环前,清空优化器梯度
- 将img、label放置到GPU上训练
- 对标签进行独热编码,10个类别(独热编码(One-Hot Encoding) - 知乎 (zhihu.com))
(3)判断是否使用混合精度训练
if scaler is not None:with amp.autocast():out_fr = 0.for t in range(args.T):encoded_img = encoder(img)out_fr += net(encoded_img)out_fr = out_fr / args.Tloss = F.mse_loss(out_fr, label_onehot)scaler.scale(loss).backward()scaler.step(optimizer)scaler.update()else:out_fr = 0.for t in range(args.T):encoded_img = encoder(img)out_fr += net(encoded_img)out_fr = out_fr / args.Tloss = F.mse_loss(out_fr, label_onehot)loss.backward()optimizer.step()如果使用:
- 用amp.autocast()包裹前向计算,使其在浮点16位计算
- 用scaler缩放损失scale(loss)
- 损失回传
- 通过scaler更新优化器
如果不使用混合精度:
- 正常进行前向计算
- 损失函数计算
- 反向传播
- 优化器更新
(4)重置网络
functional.reset_net(net)SNN中的脉冲神经元在前向传播时会积累状态,比如膜电位、释放的脉冲等。重置可以清空这些状态,使网络回到初始状态。
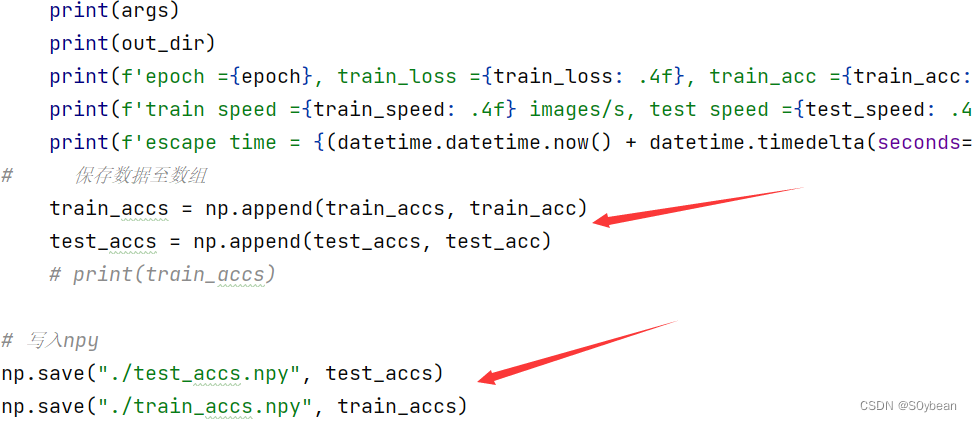
(5)在下图位置添加对应代码保存.npy文件
3.可视化
3.1准确率
在examples文件夹下创建一个.py文件,用于对结果的可视化
代码如下:
import numpy as np
import matplotlib.pyplot as plttest_accs = np.load("./train_accs.npy")
x = []
y = []
maxy = -1
maxx = -1
for t in range(len(test_accs)):if test_accs[t] > maxy:maxy = test_accs[t]maxx = tx.append(t)y.append(test_accs[t])
plt.plot(x, y)
# plt.plot(test_accs)
plt.xlabel('Iteration')
plt.ylabel('Acc')
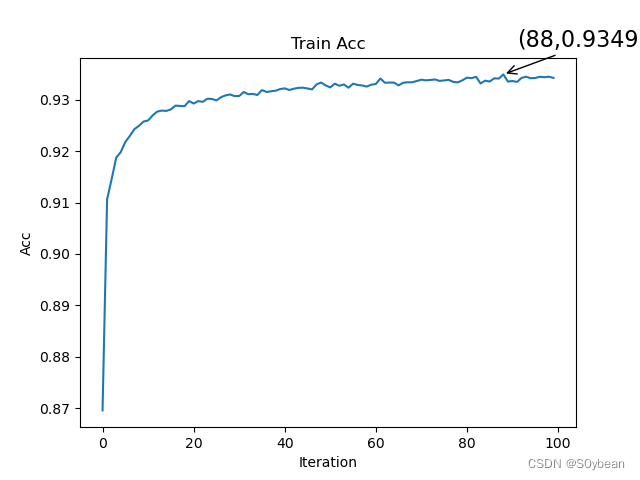
plt.title('Train Acc')
plt.annotate(r'(%d,%f)' % (maxx, maxy), xy=(maxx, maxy), xycoords='data', xytext=(+10, +20), fontsize=16,arrowprops=dict(arrowstyle='->'), textcoords='offset points')
plt.show()
test_accs = np.load("./test_accs.npy")
x = []
y = []
maxy = -1
maxx = -1
for t in range(len(test_accs)):if test_accs[t] > maxy:maxy = test_accs[t]maxx = tx.append(t)y.append(test_accs[t])
# plt.plot(x, y)
plt.plot(test_accs)
plt.xlabel('Epoch')
plt.ylabel('Acc')
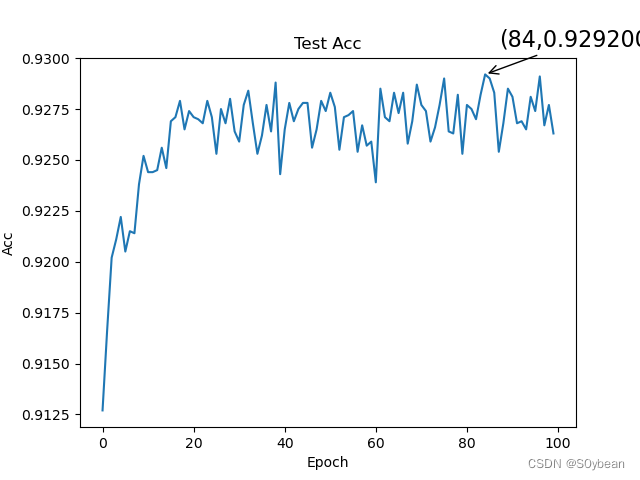
plt.title('Test Acc')
plt.annotate(r'(%d,%f)' % (maxx, maxy), xy=(maxx, maxy), xycoords='data', xytext=(+10, +20), fontsize=16,arrowprops=dict(arrowstyle='->'), textcoords='offset points')
plt.show()
效果:
3.2测试图片与发放脉冲
添加如下代码至main()函数的末尾:
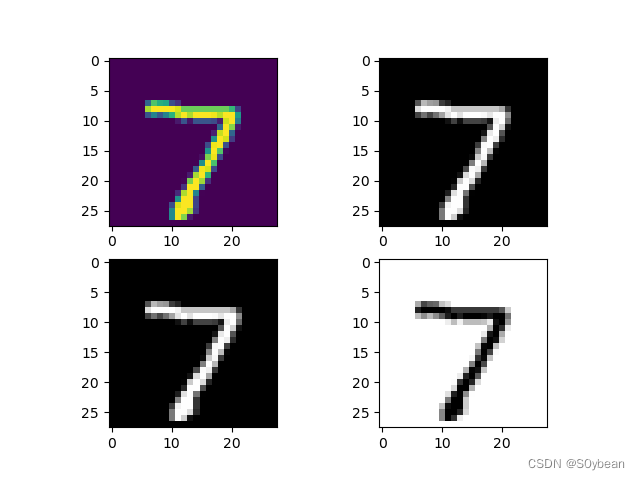
img = img.cpu().numpy().reshape(28, 28)plt.subplot(221)plt.imshow(img)plt.subplot(222)plt.imshow(img, cmap='gray')plt.subplot(223)plt.imshow(img, cmap=plt.cm.gray)plt.subplot(224)plt.imshow(img, cmap=plt.cm.gray_r)plt.show()效果:
![]()
3.3脉冲发放与电压
新建文件夹,运行如下代码:
test_spike = np.load("./s_t_array.npy")test_mem = np.load('./v_t_array.npy')visualizing.plot_2d_heatmap(array=np.asarray(test_mem), title='Membrane Potentials', xlabel='Simulating Step',ylabel='Neuron Index', int_x_ticks=True, x_max=100, dpi=200)visualizing.plot_1d_spikes(spikes=np.asarray(test_spike), title='Membrane Potentials', xlabel='Simulating Step',ylabel='Neuron Index', dpi=200)plt.show()
效果: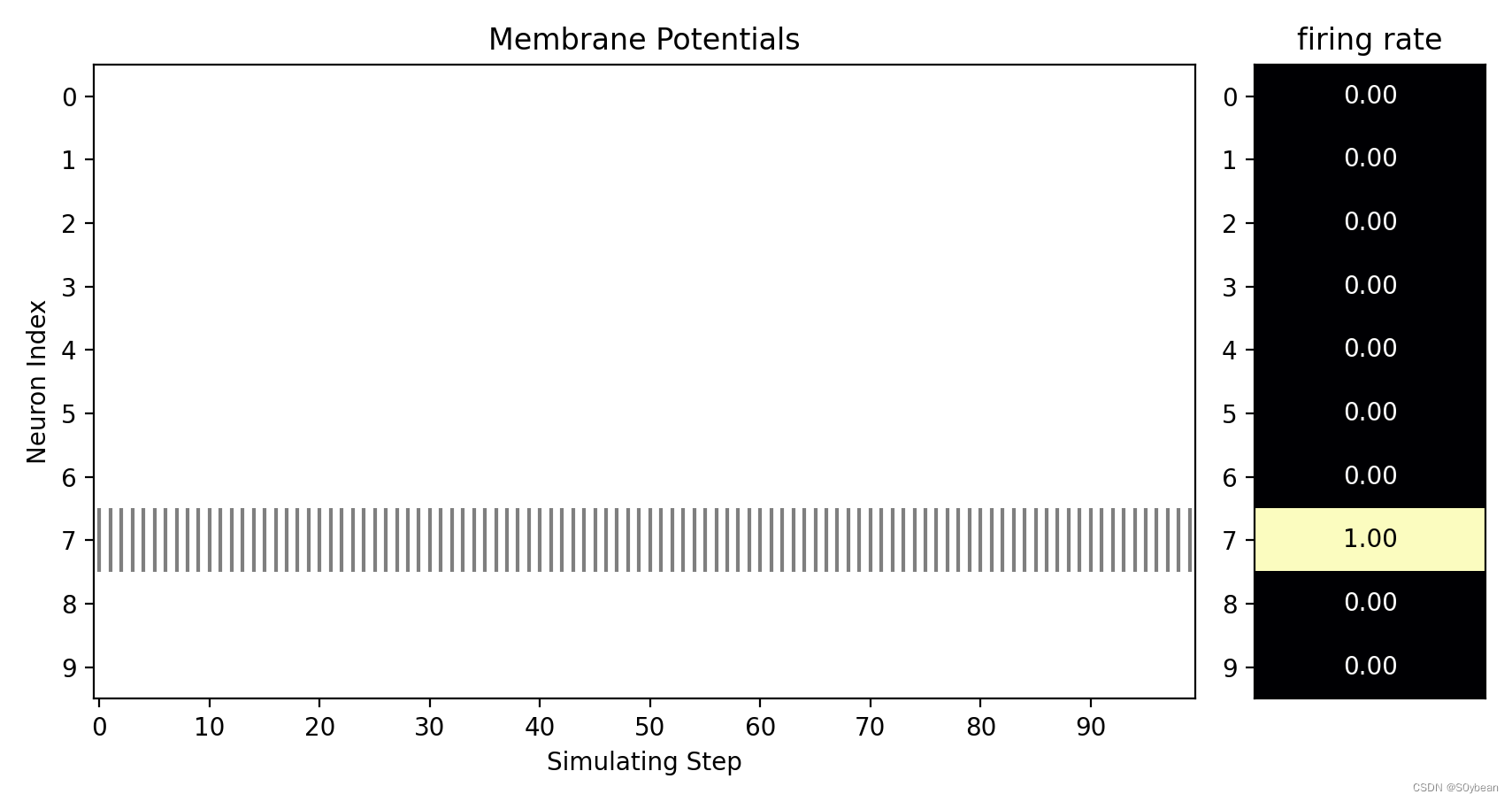
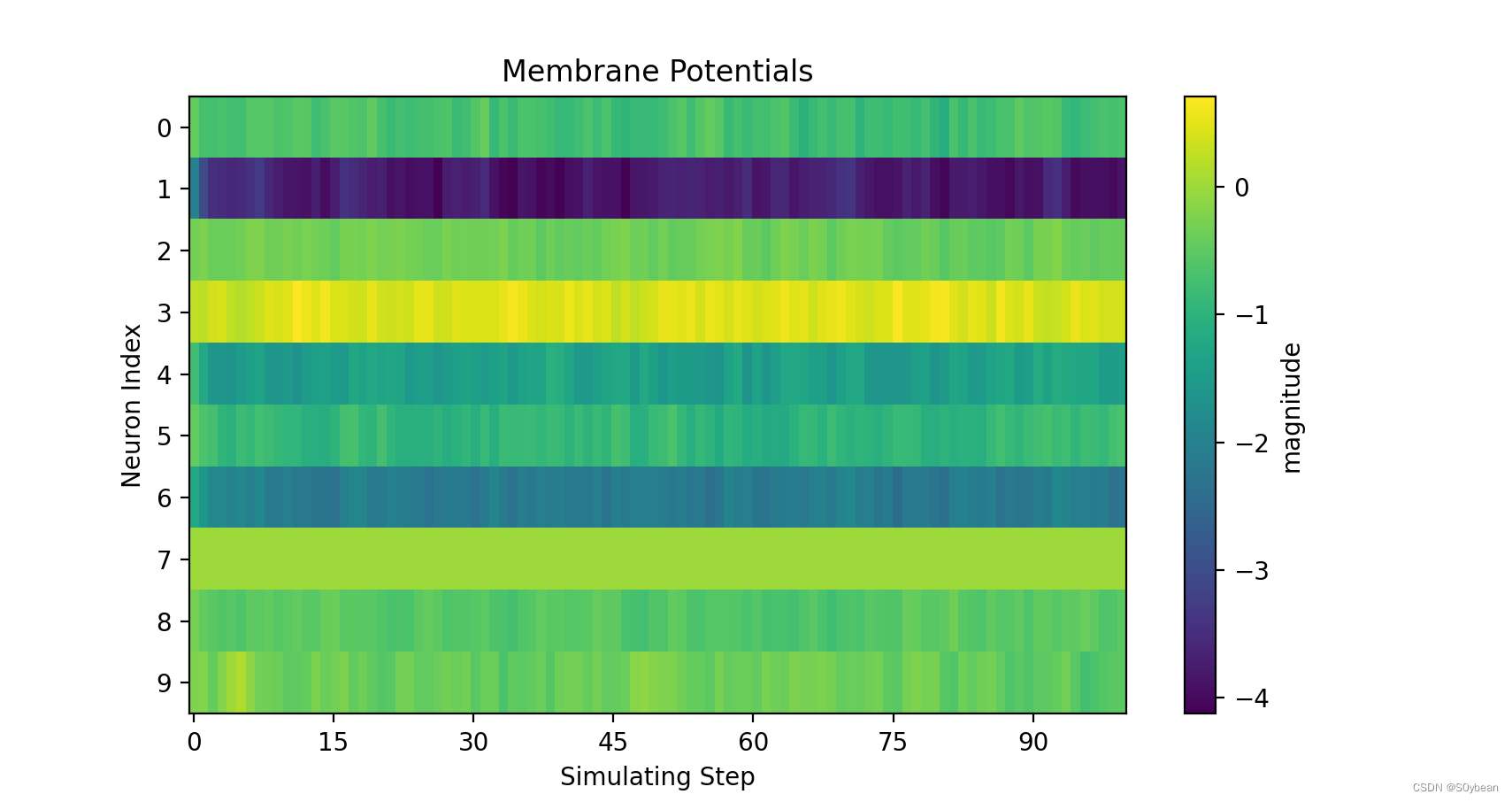
4.完整代码
lif_fc_mnist.py(为减少运行耗时,迭代次数设置为1)
import os
import time
import argparse
import sys
import datetimeimport torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data as data
from torch.cuda import amp
from torch.utils.tensorboard import SummaryWriter
import torchvision
import numpy as np
import matplotlib.pyplot as pltfrom spikingjelly.activation_based import neuron, encoding, functional, surrogate, layerclass SNN(nn.Module):def __init__(self, tau):super().__init__()self.layer = nn.Sequential(layer.Flatten(),layer.Linear(28 * 28, 10, bias=False),neuron.LIFNode(tau=tau, surrogate_function=surrogate.ATan()),)def forward(self, x: torch.Tensor):return self.layer(x)def main():''':return: None* :ref:`API in English <lif_fc_mnist.main-en>`.. _lif_fc_mnist.main-cn:使用全连接-LIF的网络结构,进行MNIST识别。\n这个函数会初始化网络进行训练,并显示训练过程中在测试集的正确率。* :ref:`中文API <lif_fc_mnist.main-cn>`.. _lif_fc_mnist.main-en:The network with FC-LIF structure for classifying MNIST.\nThis function initials the network, starts trainingand shows accuracy on test dataset.'''parser = argparse.ArgumentParser(description='LIF MNIST Training')parser.add_argument('-T', default=100, type=int, help='simulating time-steps')parser.add_argument('-device', default='cuda:0', help='device')parser.add_argument('-b', default=64, type=int, help='batch size')# 100parser.add_argument('-epochs', default=1, type=int, metavar='N',help='number of total epochs to run')parser.add_argument('-j', default=4, type=int, metavar='N',help='number of data loading workers (default: 4)')parser.add_argument('-data-dir', type=str, default='./MNIST', help='root dir of MNIST dataset')parser.add_argument('-out-dir', type=str, default='./logs', help='root dir for saving logs and checkpoint')parser.add_argument('-resume', type =str, help='resume from the checkpoint path')parser.add_argument('-amp', action='store_true', help='automatic mixed precision training')parser.add_argument('-opt', type=str, choices=['sgd', 'adam'], default='adam', help='use which optimizer. SGD or Adam')parser.add_argument('-momentum', default=0.9, type=float, help='momentum for SGD')parser.add_argument('-lr', default=1e-3, type=float, help='learning rate')parser.add_argument('-tau', default=2.0, type=float, help='parameter tau of LIF neuron')args = parser.parse_args()print(args)net = SNN(tau=args.tau)print(net)net.to(args.device)# 初始化数据加载器train_dataset = torchvision.datasets.MNIST(root=args.data_dir,train=True,transform=torchvision.transforms.ToTensor(),download=True)test_dataset = torchvision.datasets.MNIST(root=args.data_dir,train=False,transform=torchvision.transforms.ToTensor(),download=True)train_data_loader = data.DataLoader(dataset=train_dataset,batch_size=args.b,shuffle=True,drop_last=True,num_workers=args.j,pin_memory=True)test_data_loader = data.DataLoader(dataset=test_dataset,batch_size=args.b,shuffle=False,drop_last=False,num_workers=args.j,pin_memory=True)scaler = Noneif args.amp:scaler = amp.GradScaler()start_epoch = 0max_test_acc = -1optimizer = Noneif args.opt == 'sgd':optimizer = torch.optim.SGD(net.parameters(), lr=args.lr, momentum=args.momentum)elif args.opt == 'adam':optimizer = torch.optim.Adam(net.parameters(), lr=args.lr)else:raise NotImplementedError(args.opt)if args.resume:checkpoint = torch.load(args.resume, map_location='cpu')net.load_state_dict(checkpoint['net'])optimizer.load_state_dict(checkpoint['optimizer'])start_epoch = checkpoint['epoch'] + 1max_test_acc = checkpoint['max_test_acc']out_dir = os.path.join(args.out_dir, f'T{args.T}_b{args.b}_{args.opt}_lr{args.lr}')if args.amp:out_dir += '_amp'if not os.path.exists(out_dir):os.makedirs(out_dir)print(f'Mkdir {out_dir}.')with open(os.path.join(out_dir, 'args.txt'), 'w', encoding='utf-8') as args_txt:args_txt.write(str(args))writer = SummaryWriter(out_dir, purge_step=start_epoch)with open(os.path.join(out_dir, 'args.txt'), 'w', encoding='utf-8') as args_txt:args_txt.write(str(args))args_txt.write('\n')args_txt.write(' '.join(sys.argv))encoder = encoding.PoissonEncoder()# 创建保存数组train_accs = []test_accs = []for epoch in range(start_epoch, args.epochs):start_time = time.time()net.train()train_loss = 0train_acc = 0train_samples = 0for img, label in train_data_loader:optimizer.zero_grad()img = img.to(args.device)label = label.to(args.device)label_onehot = F.one_hot(label, 10).float()if scaler is not None:with amp.autocast():out_fr = 0.for t in range(args.T):encoded_img = encoder(img)out_fr += net(encoded_img)out_fr = out_fr / args.Tloss = F.mse_loss(out_fr, label_onehot)scaler.scale(loss).backward()scaler.step(optimizer)scaler.update()else:out_fr = 0.for t in range(args.T):encoded_img = encoder(img)out_fr += net(encoded_img)out_fr = out_fr / args.Tloss = F.mse_loss(out_fr, label_onehot)loss.backward()optimizer.step()train_samples += label.numel()train_loss += loss.item() * label.numel()train_acc += (out_fr.argmax(1) == label).float().sum().item()functional.reset_net(net)train_time = time.time()train_speed = train_samples / (train_time - start_time)train_loss /= train_samplestrain_acc /= train_sampleswriter.add_scalar('train_loss', train_loss, epoch)writer.add_scalar('train_acc', train_acc, epoch)net.eval()test_loss = 0test_acc = 0test_samples = 0with torch.no_grad():for img, label in test_data_loader:img = img.to(args.device)label = label.to(args.device)label_onehot = F.one_hot(label, 10).float()out_fr = 0.for t in range(args.T):encoded_img = encoder(img)out_fr += net(encoded_img)out_fr = out_fr / args.Tloss = F.mse_loss(out_fr, label_onehot)test_samples += label.numel()test_loss += loss.item() * label.numel()test_acc += (out_fr.argmax(1) == label).float().sum().item()functional.reset_net(net)test_time = time.time()test_speed = test_samples / (test_time - train_time)test_loss /= test_samplestest_acc /= test_sampleswriter.add_scalar('test_loss', test_loss, epoch)writer.add_scalar('test_acc', test_acc, epoch)save_max = Falseif test_acc > max_test_acc:max_test_acc = test_accsave_max = Truecheckpoint = {'net': net.state_dict(),'optimizer': optimizer.state_dict(),'epoch': epoch,'max_test_acc': max_test_acc}if save_max:torch.save(checkpoint, os.path.join(out_dir, 'checkpoint_max.pth'))torch.save(checkpoint, os.path.join(out_dir, 'checkpoint_latest.pth'))print(args)print(out_dir)print(f'epoch ={epoch}, train_loss ={train_loss: .4f}, train_acc ={train_acc: .4f}, test_loss ={test_loss: .4f}, test_acc ={test_acc: .4f}, max_test_acc ={max_test_acc: .4f}')print(f'train speed ={train_speed: .4f} images/s, test speed ={test_speed: .4f} images/s')print(f'escape time = {(datetime.datetime.now() + datetime.timedelta(seconds=(time.time() - start_time) * (args.epochs - epoch))).strftime("%Y-%m-%d %H:%M:%S")}\n')# 保存数据至数组train_accs = np.append(train_accs, train_acc)test_accs = np.append(test_accs, test_acc)# print(train_accs)# 写入npynp.save("./test_accs.npy", test_accs)np.save("./train_accs.npy", train_accs)# 保存绘图用数据net.eval()# 注册钩子output_layer = net.layer[-1] # 输出层output_layer.v_seq = []output_layer.s_seq = []def save_hook(m, x, y):m.v_seq.append(m.v.unsqueeze(0))m.s_seq.append(y.unsqueeze(0))output_layer.register_forward_hook(save_hook)with torch.no_grad():img, label = test_dataset[0]img = img.to(args.device)out_fr = 0.for t in range(args.T):encoded_img = encoder(img)out_fr += net(encoded_img)out_spikes_counter_frequency = (out_fr / args.T).cpu().numpy()print(f'Firing rate: {out_spikes_counter_frequency}')output_layer.v_seq = torch.cat(output_layer.v_seq)output_layer.s_seq = torch.cat(output_layer.s_seq)v_t_array = output_layer.v_seq.cpu().numpy().squeeze() # v_t_array[i][j]表示神经元i在j时刻的电压值np.save("v_t_array.npy",v_t_array)s_t_array = output_layer.s_seq.cpu().numpy().squeeze() # s_t_array[i][j]表示神经元i在j时刻释放的脉冲,为0或1np.save("s_t_array.npy",s_t_array)img = img.cpu().numpy().reshape(28, 28)plt.subplot(221)plt.imshow(img)plt.subplot(222)plt.imshow(img, cmap='gray')plt.subplot(223)plt.imshow(img, cmap=plt.cm.gray)plt.subplot(224)plt.imshow(img, cmap=plt.cm.gray_r)plt.show()if __name__ == '__main__':main()
lif_fc_mnist_test.py
import numpy as np
import matplotlib.pyplot as plttest_accs = np.load("./train_accs.npy")
x = []
y = []
maxy = -1
maxx = -1
for t in range(len(test_accs)):if test_accs[t] > maxy:maxy = test_accs[t]maxx = tx.append(t)y.append(test_accs[t])
plt.plot(x, y)
# plt.plot(test_accs)
plt.xlabel('Iteration')
plt.ylabel('Acc')
plt.title('Train Acc')
plt.annotate(r'(%d,%f)' % (maxx, maxy), xy=(maxx, maxy), xycoords='data', xytext=(+10, +20), fontsize=16,arrowprops=dict(arrowstyle='->'), textcoords='offset points')
plt.show()
test_accs = np.load("./test_accs.npy")
x = []
y = []
maxy = -1
maxx = -1
for t in range(len(test_accs)):if test_accs[t] > maxy:maxy = test_accs[t]maxx = tx.append(t)y.append(test_accs[t])
# plt.plot(x, y)
plt.plot(test_accs)
plt.xlabel('Epoch')
plt.ylabel('Acc')
plt.title('Test Acc')
plt.annotate(r'(%d,%f)' % (maxx, maxy), xy=(maxx, maxy), xycoords='data', xytext=(+10, +20), fontsize=16,arrowprops=dict(arrowstyle='->'), textcoords='offset points')
plt.show()