Spring循环依赖
前言
大制作来啦,spring源码篇,很早之前我就想写一系列spring源码篇了,正好最近总是下雨,不想出门,那就让我来带大家走进Spring源码世界吧。
阅读建议
spring源码读起来有点难度,需要多Debug和做笔记,大家千万不要在一个方法里陷进去,不要想着只运行一次就能理解透,一定要先走几遍完整的流程。
一、IOC和依赖注入
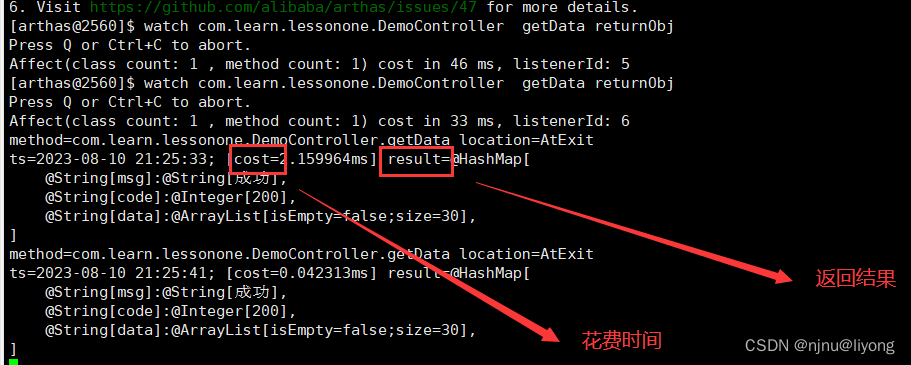
在循环依赖之前,我想先简单的讲一下IOC和依赖注入,因为循环依赖这个问题就是出现在依赖注入。
IOC:控制反转,就是将对象的创建权力交给了容器,不需要自己手动去new对象
1.1 举个例子
传统创建bean
假设D依赖C,C依赖B,B依赖A,如果你需要创建D对象,那么你要从new D到new A,然后把A设置到B,把B设置到C,把C设置到D,这时候你才能拿到完整的D对象,是不是也不复杂?如果A-D还有10几个对象要维护,那是不是就想删库跑路了?
容器创建bean
控制反转就是将创建bean交给容器,你只要和容器说需要D对象,就能直接获取到了,是不是很方便,你可以会问:那容器是怎样创建的bean并将A-D的对象关联起来的呢?这正是我们今天要讲的内容。
二、循环依赖
对象间的依赖可能会出现循环依赖,下面就跟着我来看看spring是怎样将对象关联起来的,又是怎样解决循环以来的。
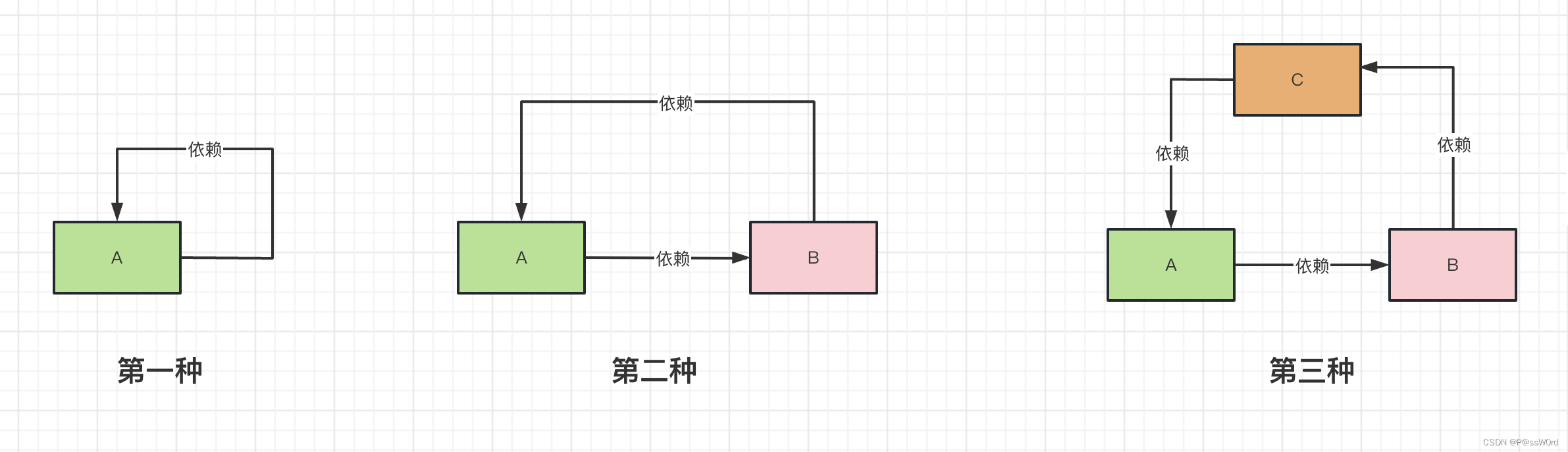
2.1 什么是循环依赖
如图,循环依赖分为三种,总的来说就是依赖形成了一个闭环,而打破这个闭环的就是今天重点要讲的三级缓存。
三、三级缓存
3.1 名词解析
在阅读源码前,先看看是哪三级缓存,分别都有什么作用。
- 一级singletonObjects 保存已经(实例化、注入、初始化)完成的bean
- 二级earlySingletonObjects 保存已经(实例化)完成的bean
- 三级singletonFactories 保存bean创建工厂,便于创建代理对象
3.2 创建bean流程图
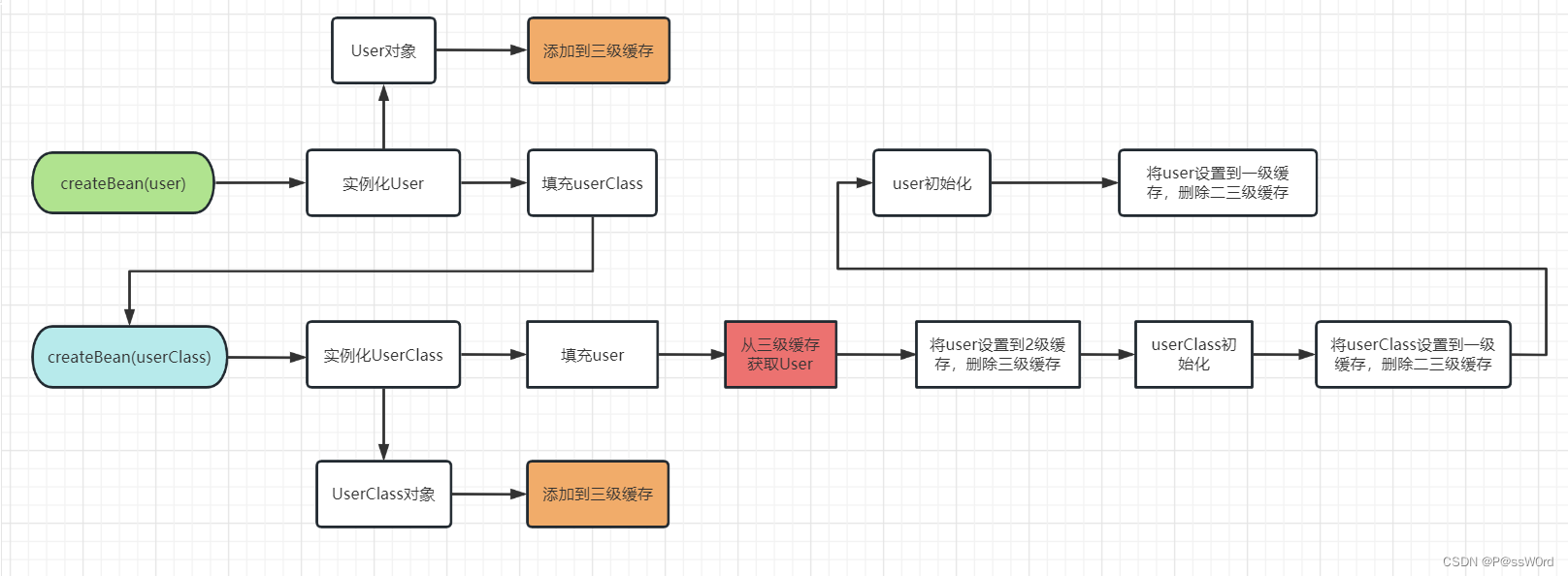
- 实例化User对象,将User放入第三级缓存
- 填充User的属性,发现依赖了UserClass,开始创建UserClass
- 实例化UserClass对象,将UserClass放入第三级缓存
- 填充UserClass的属性,发现依赖了User, 从第三级缓存中拿到User,将User放入第二级缓存
- 初始化UserClass,将UserClass添加到第一级缓存,删除第二第三级缓存
- User开始初始化,将User添加到第一级缓存,删除第二第三级缓存
3.3 能不能删除第二级缓存
看代码和流程图发现打破循环是第三级缓存的功劳,根本没用到二级缓存,那能不能删除第二级缓存呢?
答案肯定是不能的,让我举个例子

如果A需要找B、C,B需要找A,C也需要找A
- B 找到 A 时,直接通过三级缓存的工厂的代理对象,生成对象 A1。
- C 找到 A 时,直接通过三级缓存的工厂的代理对象,生成对象 A2。
通过 A 的工厂的代理对象,生成了两个不同的对象 A1 和 A2 ,所以为了避免这种问题的出现,我们搞个二级缓存,把 A1 存下来,下次再获取时,直接从二级缓存获取,无需再生成新的代理对象。
所以“二级缓存”的目的是为了避免因为 AOP 创建多个对象,其中存储的是半成品的 AOP 的单例 bean。
如果没有 AOP 的话,我们其实只要 1、3 级缓存,就可以满足要求。
四、代码调试
这里我以第二种情况为例,总的流程还是比较简单的。
4.1 第一步:创建实例
通过createBeanInstance(beanName, mbd, args)方法创建实例
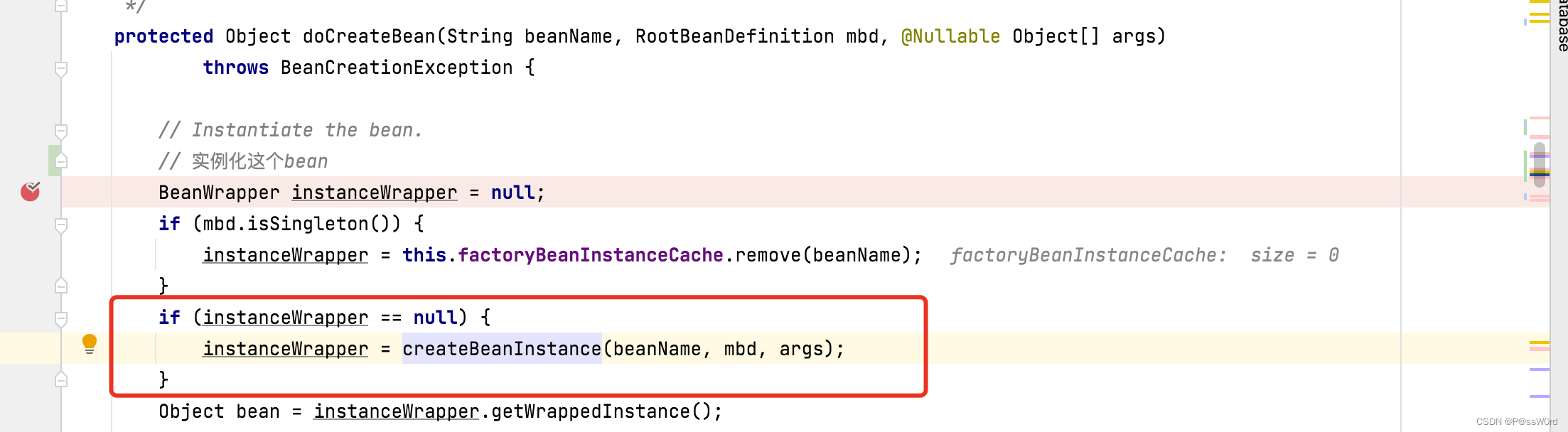
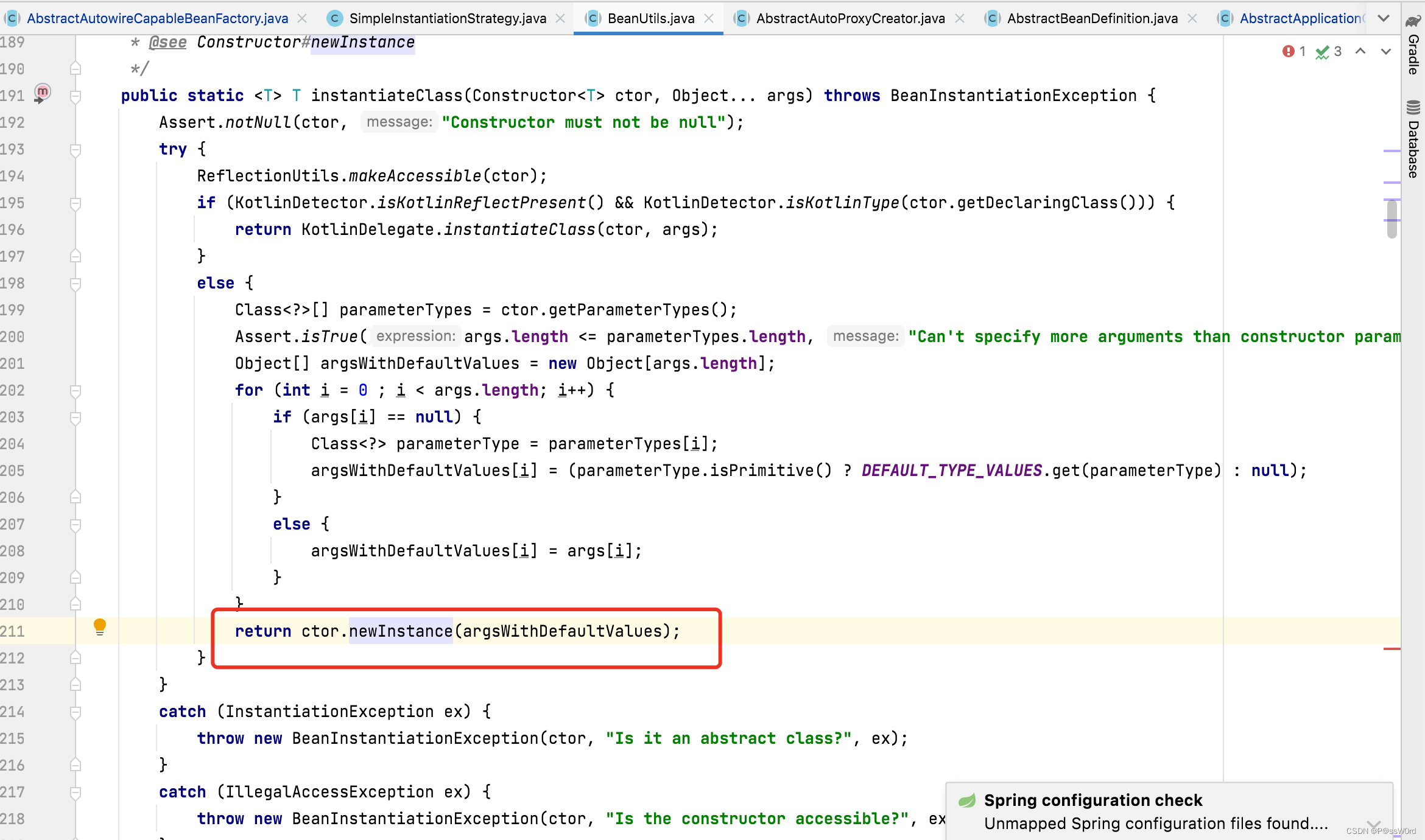
进入createBeanInstance内部,发现BeanUtils通过反射Constructor.newInstance(Object… args)创建的实例。
4.2 第二步: 将实例保存到第三级缓存
添加到第三级缓存的地方是addSingletonFactory
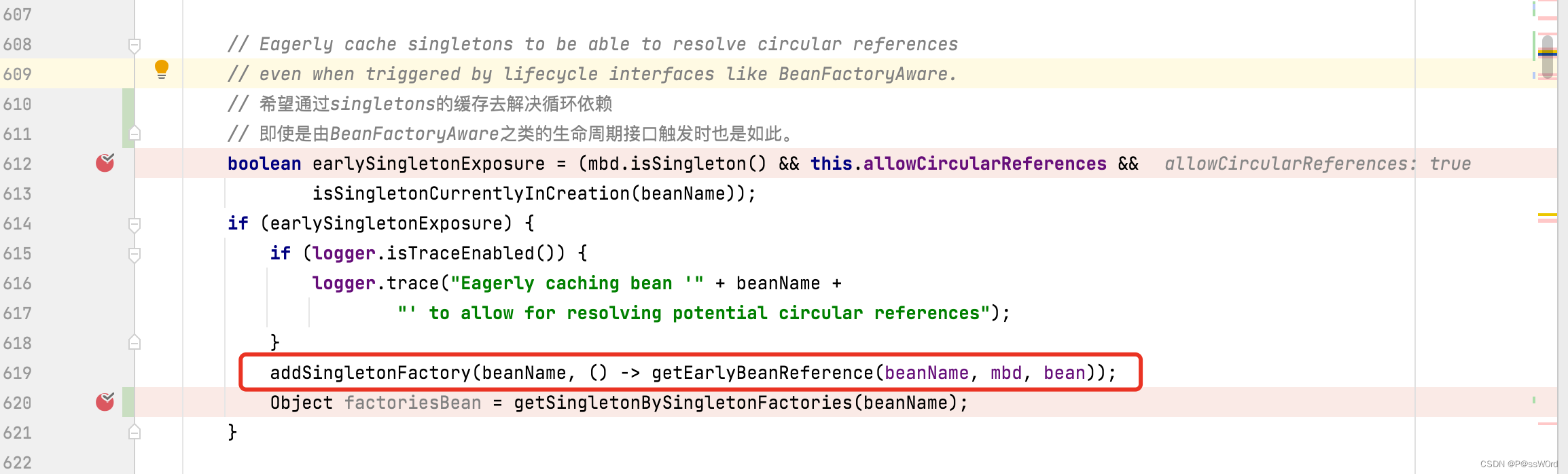
这是个Lambda表达式,我们进入getEarlyBeanReference方法内部,发现如果不符合这段判断就直接返回4.1反射出来的对象,符合判断就进入这段代码,那这段返回的是什么呢?就是代理的对象

我们接着往下看,进入 getEarlyBeanReference(exposedObject, beanName) 方法,发现Spring会创建一个代理对象,并返回。
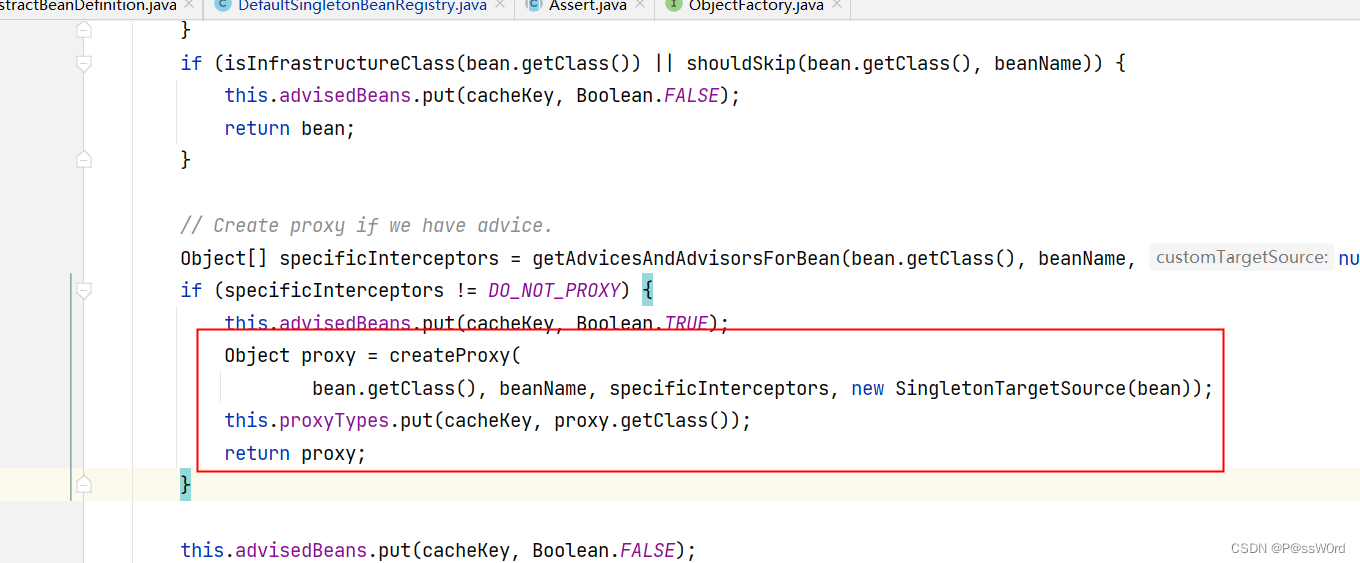
进入addSingletonFactory方法内部可以看到spring把singletonFactory放入了singletonFactories内部
4.3 第三步:填充属性
循环依赖就出在填充属性的过程,如以下情况,A等待B创建,B等待A创建,这样就形成循环依赖了。
进入populateBean(beanName, mbd, instanceWrapper)方法
第一个属性是userClass,就是user依赖的类,这里会调用getBean方法
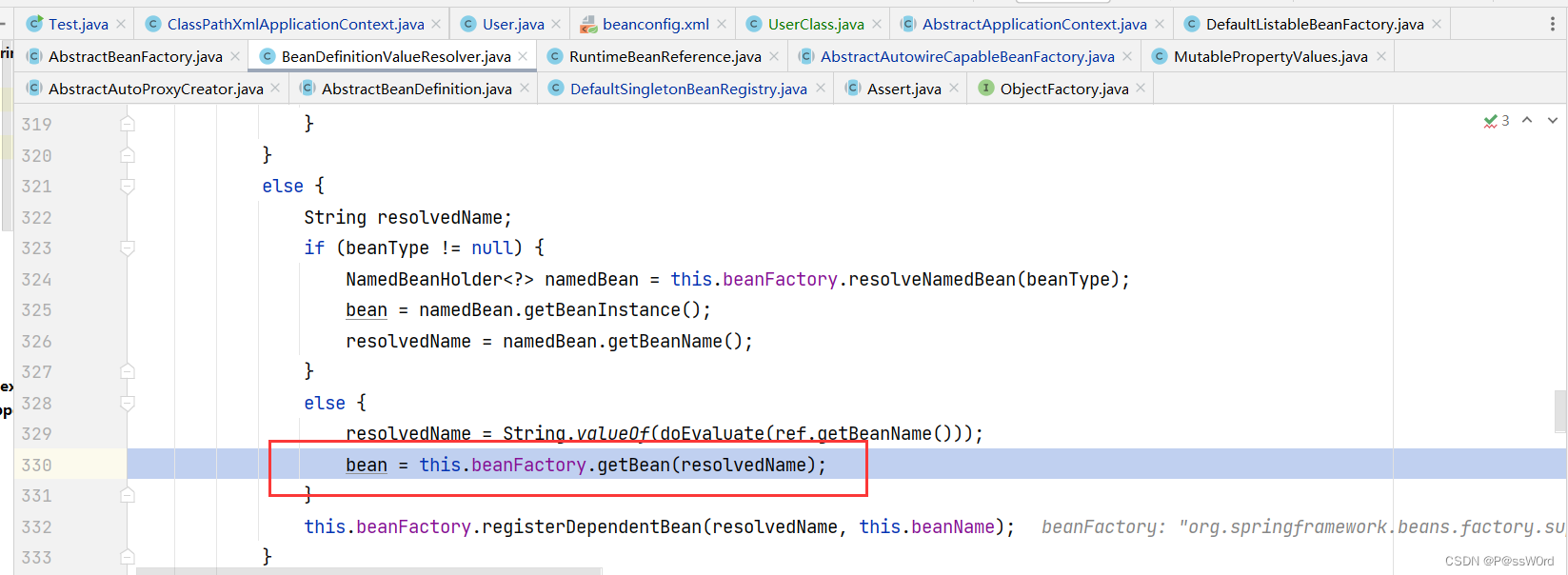
4.3.1 实例化UserClass的Bean,放入第三级缓存
因为UserClass也没创建,所以这里创建过程和4.1、4.2是一样的
4.3.2 填充UserClasss属性
是不是进入循环了?如果没有三级缓存的话,假如UserClass有一个User属性,那么又要去创建User,就形成一个死循环了,三级缓存就是帮我们打破这个循环的。
我们从userClass的populateBean方法深入进来,它会从beanFactory获取user

4.3.3 获取user填充到UserClasss
进入beanFactory.getBean(resolvedName)方法内部,可以获取到创建bean的工厂,从三级工厂获取到bean的时候会将对象设置到二级缓存里,并删除三级缓存。
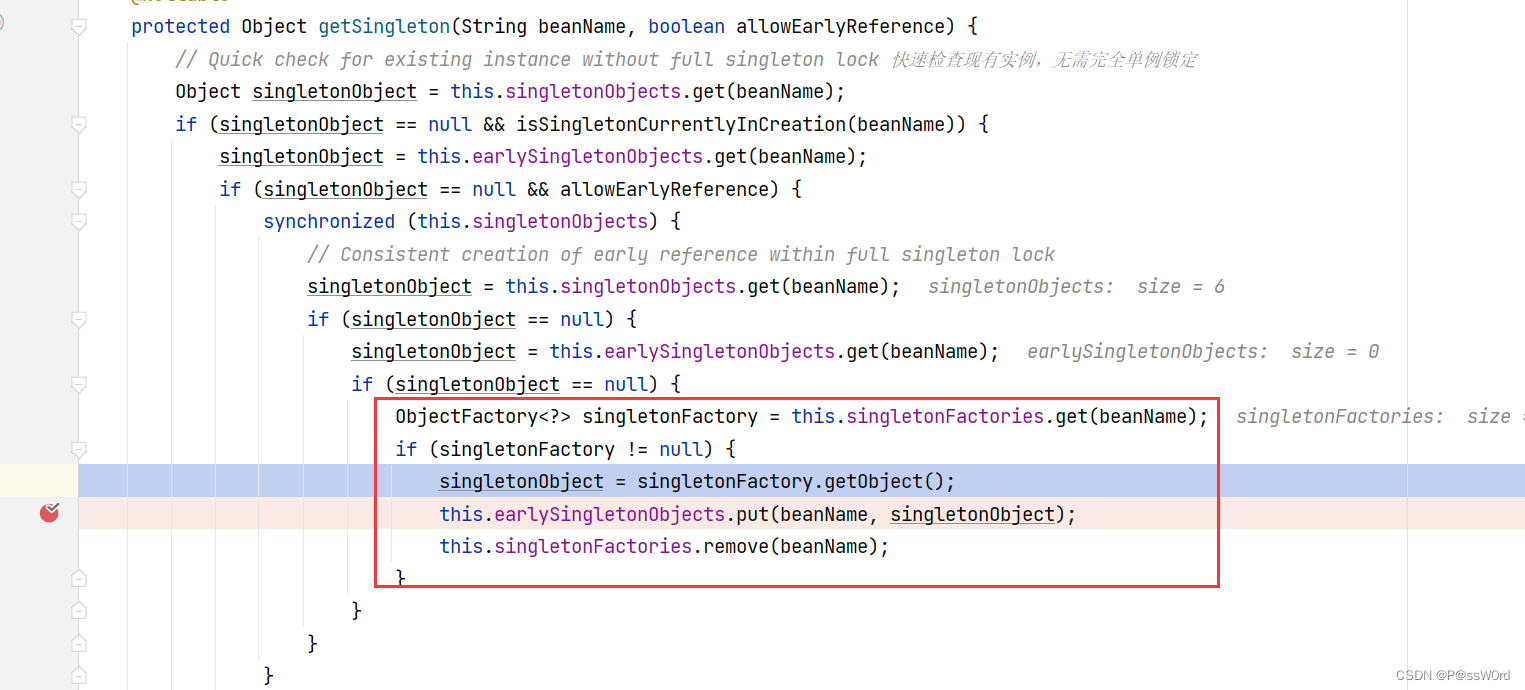
当调用singletonFactory.getObject()方法的时候进入到了getEarlyBeanReference,这就是4.2说的如果需要创建代理对象就返回一个代理对象,否则返回最开始实例化的对象。
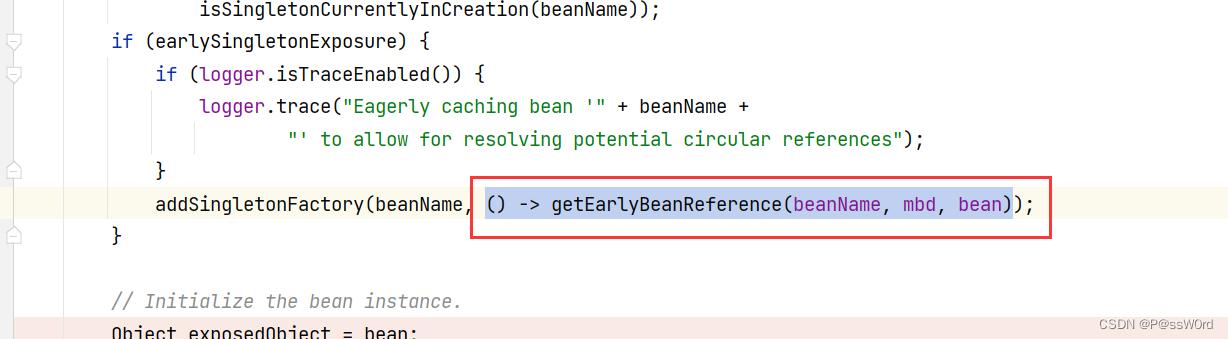
4.4 第四步:初始化Bean
这里引入一个重要的概念:Bean的生命周期,在4.3将属性填充完成后,开始了bean的初始化过程,Bean的生命周期我们放到第五点来讲。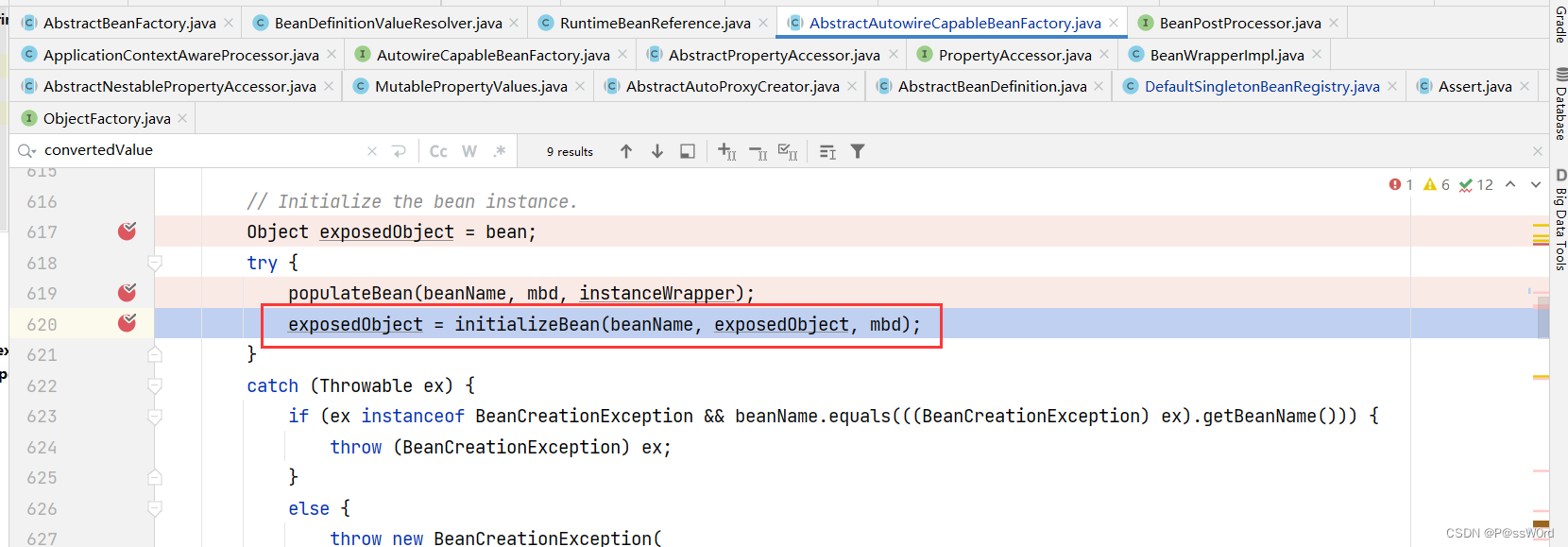
4.5 第五步:将userClass添加到一级缓存
将初始化完成的userClass添加到一级缓存,删除第二级缓存
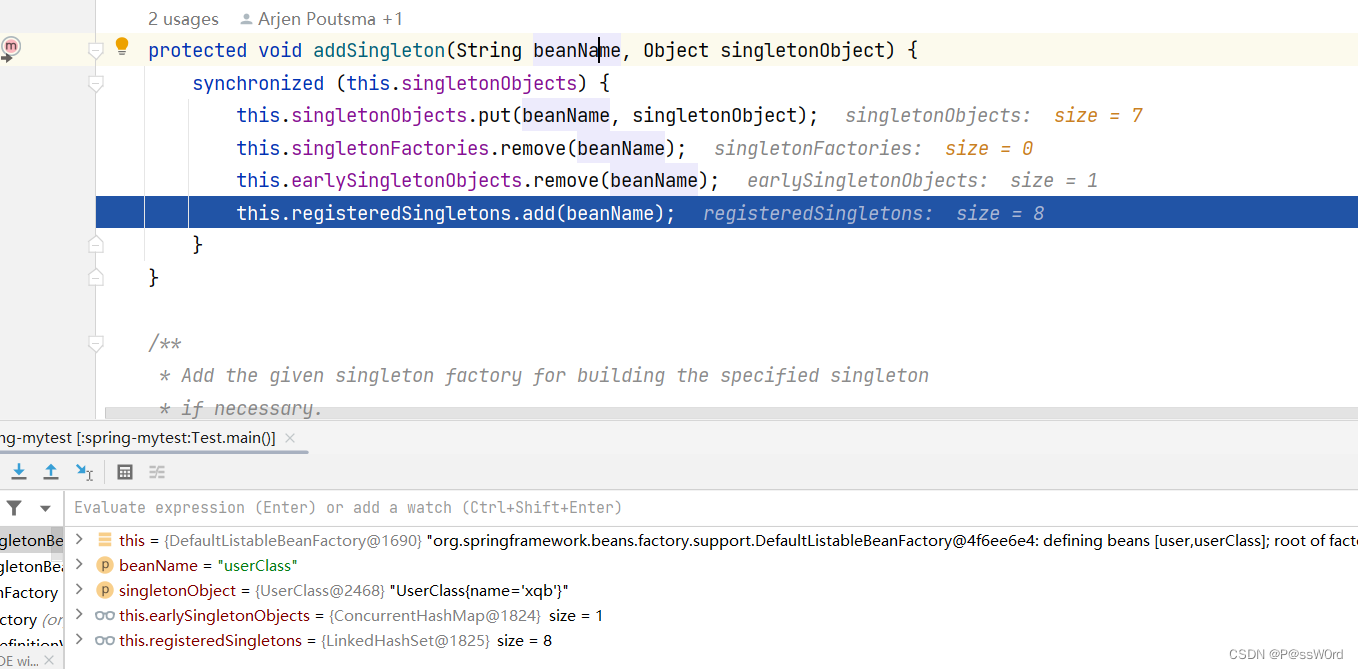
4.6 第六步 将userClass设置到user中
4.7 第七步 开始初始化user
4.8 第八步:将user添加到一级缓存
将初始化完成的user添加到一级缓存,删除第二级缓存
五、Bean生命周期
5.1 流程图
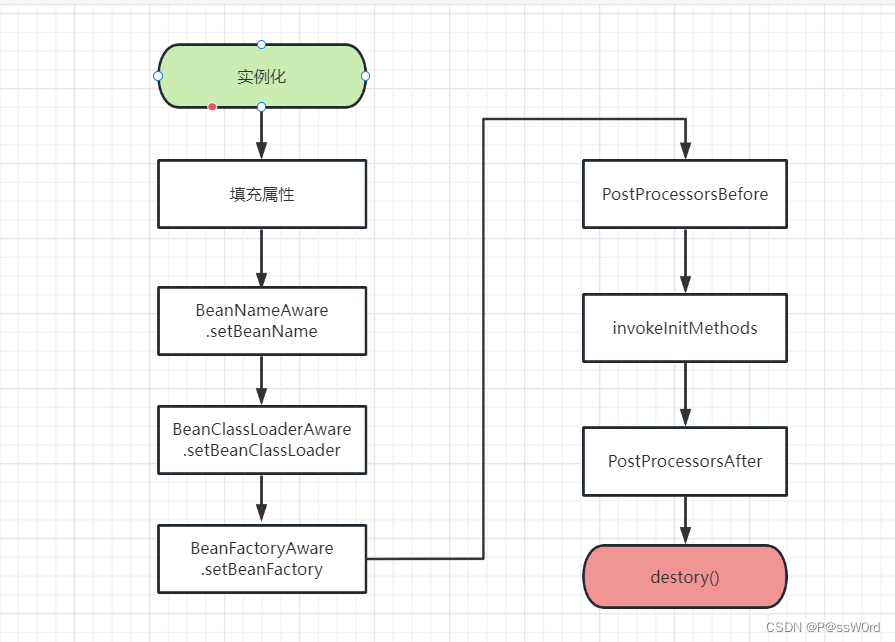
5.2 文字概述
- 调用Bean构造方法或工厂方法实例化Bean,将bean添加到三级缓存singletonFactories里面。
- 利用依赖注入完成Bean中所有属性值的配置注入,如果出现了循环依赖问题,会从三级缓存中解决问题。
- 如果Bean实现了各种Aware 接口,则调用对应的set方法。
- postProcessBefore对 Bean 进行加工操作,此处非常重要,Spring 的 AOP 就是利用它实现的。
- 如果在配置文件中通过 init-method 属性指定了初始化方法,则调用该初始化方法。
- postProcessAfter,此时Bean已经可以被应用系统使用了。
- 如果是"singleton",则归spring管生命周期;如果是"prototype",则将该 Bean 交给调用者,调用者管理该 Bean 的生命周期。
- 如果Bean实现了DisposableBean 接口,则调用 destory() 方法销毁Bean;如果配置destory-method,则调用该方法销毁Bean。
六、总结
再来回顾三级缓存的作用
- 一级缓存:单例池,bean都初始化完成了,拿来就能用了
- 二级缓存:为了防止AOP代理出现多个对象
- 三级缓存:为了打破循环,保存创建bean的工厂方法