Flume
由三部分 Source Channel Sink
可以通过配置拦截器和Channel选择器,来实现对数据的分流,
可以通过对channel的2个存储容量的的设置,来实现对流速的控制
Kafka
同样由三大部分组成 生产者 服务器 消费者
生产者负责发送数据给服务器
服务器存储数据
消费者通过从服务器取数据
但是,Kafka比Flume要更精细一点
生产者到服务器存数据(发数据):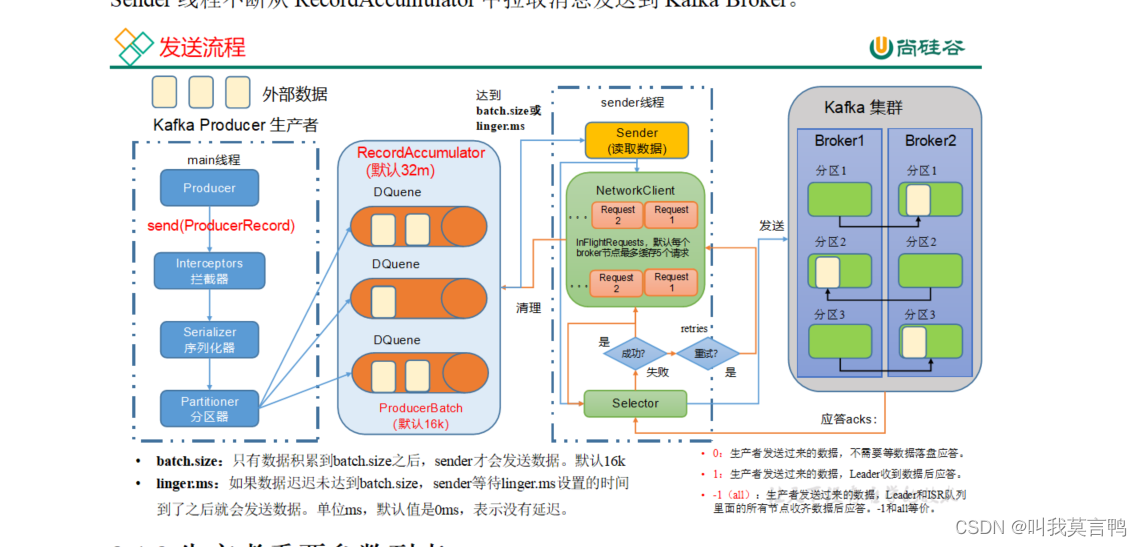
获取配置->修改配置->拦截器->序列化器->分区器->sender 到broker
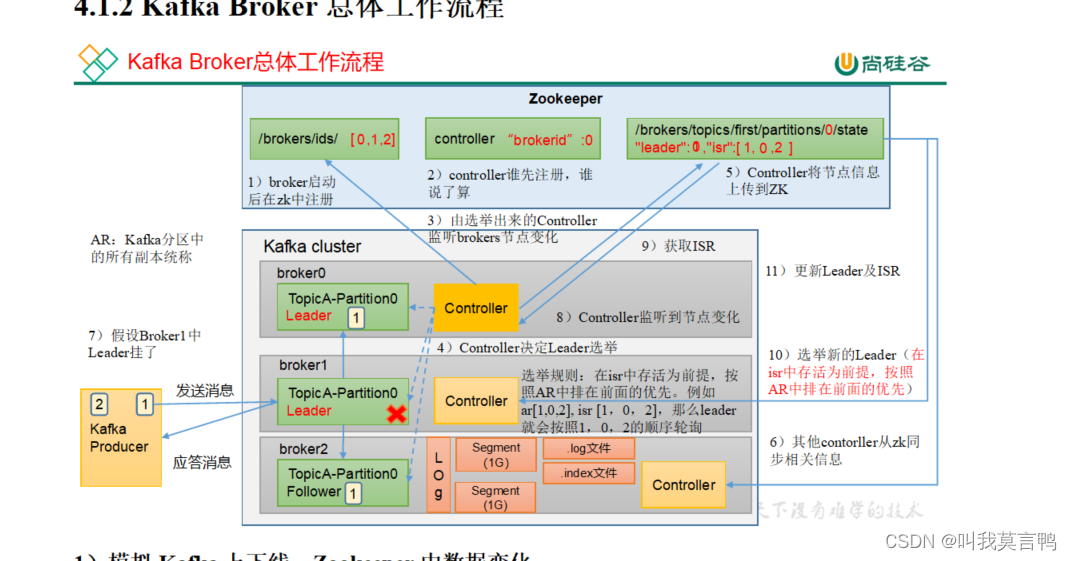
服务器如何存数据?
选举leader和发回消息
1.一个分区多个副本的controller同时去抢注册ZK
2.注册成功的监控broker节点变化
3.然后开始选举,选举出来将结果传给zk
4.其他的controller对从zk上同步节点信息(每个controller都会监控zk)
4.1.Leader挂了的话,重新选举, 然后其他controller重新同步
5.选举出来之后,生产者开始发送数据,数据由Leader同步到follower副
6.发送的数据就是Segment(默认1个G),
那么什么是Segment .log .timeindex .index .snapshot leader .metadata
50个consumer_offset 就是存储消费者读取的偏移量
7.向生产者应答
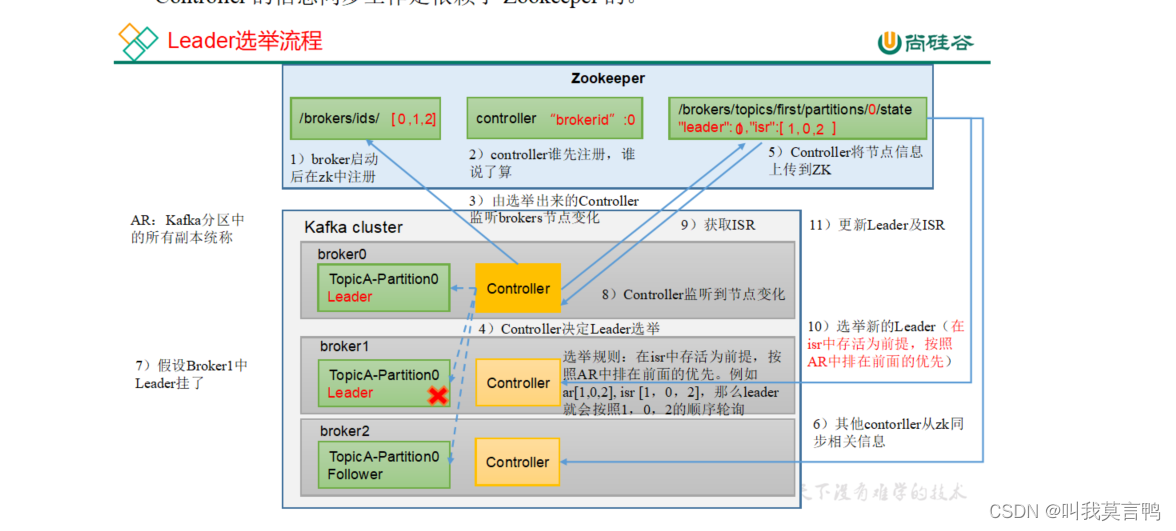
注意一下Leader挂是怎么挂?
1.broker直接挂 2. 数据太多,崩掉
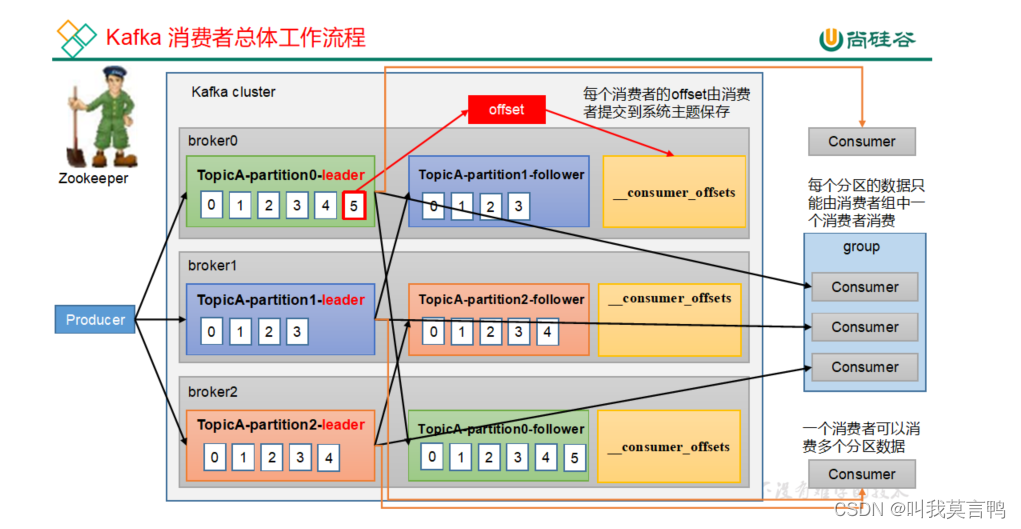
消费者到服务器取数据:
消费者是按topic去读取的,一般都是一个分区对应一个消费者
消费者的offset由消费者自己提交到系统主题保存
按组按照消费策略进行读取
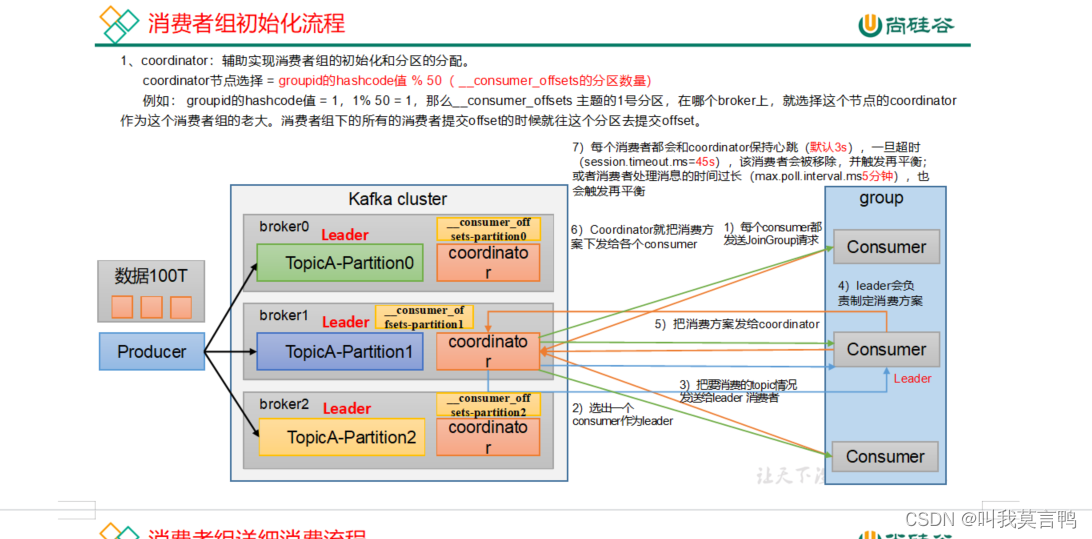
消费者组初始化
1.选出coordinator groupid的哈希值%50 这个组下的所有消费者提交offset都往这个分区提交
2.消费者实例到coordinator注册,然后coordinator选出一个consumer leader
3.Consumer leader制定一个消费方案,发给coordinator 然后coordinator转发
4.每个消费者都和coordinator保持心跳3s,超时(45s)移除该消费者,或者处理时间过长(超过5分钟),触发再平衡,重新制定消费方案

Kafka的高效读写
为什么?
1.Kafka本身分布式集群,分区技术,并行度高
2.读数据采用稀疏索引,可以快速定位要消费的数据
3.顺序写磁盘
他是如何顺序写磁盘的?
因为他的写入方式是追加写入
为什么顺序写磁盘快?
因为不需要寻址时间,而磁盘的寻址时间太长了
页缓存和零拷贝
什么是页缓存?
操作系统在内存中的缓存机制,
存: 存到页缓存 ->存到磁盘 取->先看页缓存有没有->没有就看磁盘
什么是零拷贝?
传输: 一般传输 ->s 内存->内核缓冲区->e网络设备 零拷贝 内存->网络设备

零拷贝: Kafka的数据加工处理操作交由Kafka生产者和Kafka消费者处理。而Broker应用层不关心存储数据,不用走应用层
消费者如何提高吞吐量?
1.如果消费者对分区不是1对1 ,加消费者
2.提高每批次拉数据的数量