GPU上没程序在跑但是显存被占用

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/9079.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

JAVA实战开源项目:蜗牛兼职平台(Vue+SpringBoot) 附源码
本文项目编号 T 034 ,文末自助获取源码 \color{red}{T034,文末自助获取源码} T034,文末自助获取源码 目录 一、系统介绍1.1 平台架构1.2 管理后台1.3 用户网页端1.4 技术特点 二、演示录屏三、启动教程四、功能截图五、文案资料5.1 选题背景…

DeepSeek LLM解读
背景:
量化巨头幻方探索AGI(通用人工智能)新组织“深度求索”在成立半年后,发布的第一代大模型DeepSeek试用地址:DeepSeek ,免费商用,完全开源。作为一家隐形的AI巨头,幻方拥有1万枚…

用WinForm如何制作简易计算器
首先我们要自己搭好页面 using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Windows.Forms;namespace _7_简易计算…

Luzmo 专为SaaS公司设计的嵌入式数据分析平台
Luzmo 是一款嵌入式数据分析平台,专为 SaaS 公司设计,旨在通过直观的可视化和快速开发流程简化数据驱动决策。以下是关于 Luzmo 的详细介绍:
1. 背景与定位
Luzmo 前身为 Cumul.io ,专注于为 SaaS 公司提供嵌入式分析解决方案。…

Openfga 授权模型搭建
1.根据项目去启动 配置一个 openfga 服务器
先创建一个 config.yaml文件
cd /opt/openFGA/conf
touch ./config.yaml
怎么配置?
根据官网来看
openfga/.config-schema.json at main openfga/openfga GitHub
这里讲述详细的每一个配置每一个类型 这些配置有…

【物联网】ARM核常用指令(详解):数据传送、计算、位运算、比较、跳转、内存访问、CPSR/SPSR、流水线及伪指令
文章目录 指令格式(重点)1. 立即数2. 寄存器位移 一、数据传送指令1. MOV指令2. MVN指令3. LDR指令 二、数据计算指令1. ADD指令1. SUB指令1. MUL指令 三、位运算指令1. AND指令2. ORR指令3. EOR指令4. BIC指令 四、比较指令五、跳转指令1. B/BL指令2. l…

星火大模型接入及文本生成HTTP流式、非流式接口(JAVA)
文章目录 一、接入星火大模型二、基于JAVA实现HTTP非流式接口1.配置2.接口实现(1)分析接口请求(2)代码实现 3.功能测试(1)测试对话功能(2)测试记住上下文功能 三、基于JAVA实现HTTP流…

lightweight-charts-python 包 更新 lightweight-charts.js 的方法
lightweight-charts-python 是 lightweight-charts.js 的 python 包装,非常好用 lightweight-charts 更新比较频繁,导致 lightweight-charts-python 内置的 lightweight-charts 经常不是最新的。 新的 lightweight-charts 通常可以获得性能改进和bug修复…

记录 | Docker的windows版安装
目录 前言一、1.1 打开“启用或关闭Windows功能”1.2 安装“WSL”方式1:命令行下载方式2:离线包下载 二、Docker Desktop更新时间 前言 参考文章:Windows Subsystem for Linux——解决WSL更新速度慢的方案 参考视频:一个视频解决D…

2025年01月27日Github流行趋势
项目名称:onlook项目地址url:https://github.com/onlook-dev/onlook项目语言:TypeScript历史star数:5340今日star数:211项目维护者:Kitenite, drfarrell, iNerdStack, abhiroopc84, apps/dependabot项目简介…

【Linux探索学习】第二十七弹——信号(一):Linux 信号基础详解
Linux学习笔记:
https://blog.csdn.net/2301_80220607/category_12805278.html?spm1001.2014.3001.5482
前言: 前面我们已经将进程通信部分讲完了,现在我们来讲一个进程部分也非常重要的知识点——信号,信号也是进程间通信的一…

海外问卷调查渠道查如何设置:最佳实践+示例
随着经济全球化和一体化进程的加速,企业间的竞争日益加剧,为了获得更大的市场份额,对企业和品牌而言,了解受众群体的的需求、偏好和痛点才是走向成功的关键。而海外问卷调查才是获得受众群体痛点的关键,制作海外问卷调…

《STL基础之vector、list、deque》
【vector、list、deque导读】vector、list、deque这三种序列式的容器,算是比较的基础容器,也是大家在日常开发中常用到的容器,因为底层用到的数据结构比较简单,笔者就将他们三者放到一起做下对比分析,介绍下基本用法&a…

一组开源、免费、Metro风格的 WPF UI 控件库
前言
今天大姚给大家分享一个开源、免费、Metro风格的 WPF UI 控件库:MahApps.Metro。 项目介绍
MahApps.Metro 是一个开源、免费、Metro风格的 WPF UI 控件库,提供了现代化、平滑和美观的控件和样式,帮助开发人员轻松创建具有现代感的 Win…

网易云音乐歌名可视化:词云生成与GitHub-Pages部署实践
引言 本文将基于前一篇爬取的网易云音乐数据, 利用Python的wordcloud、matplotlib等库, 对歌名数据进行深入的词云可视化分析. 我们将探索不同random_state对词云布局的影响, 并详细介绍如何将生成的词云图部署到GitHub Pages, 实现数据可视化的在线展示. 介绍了如何从原始数据…
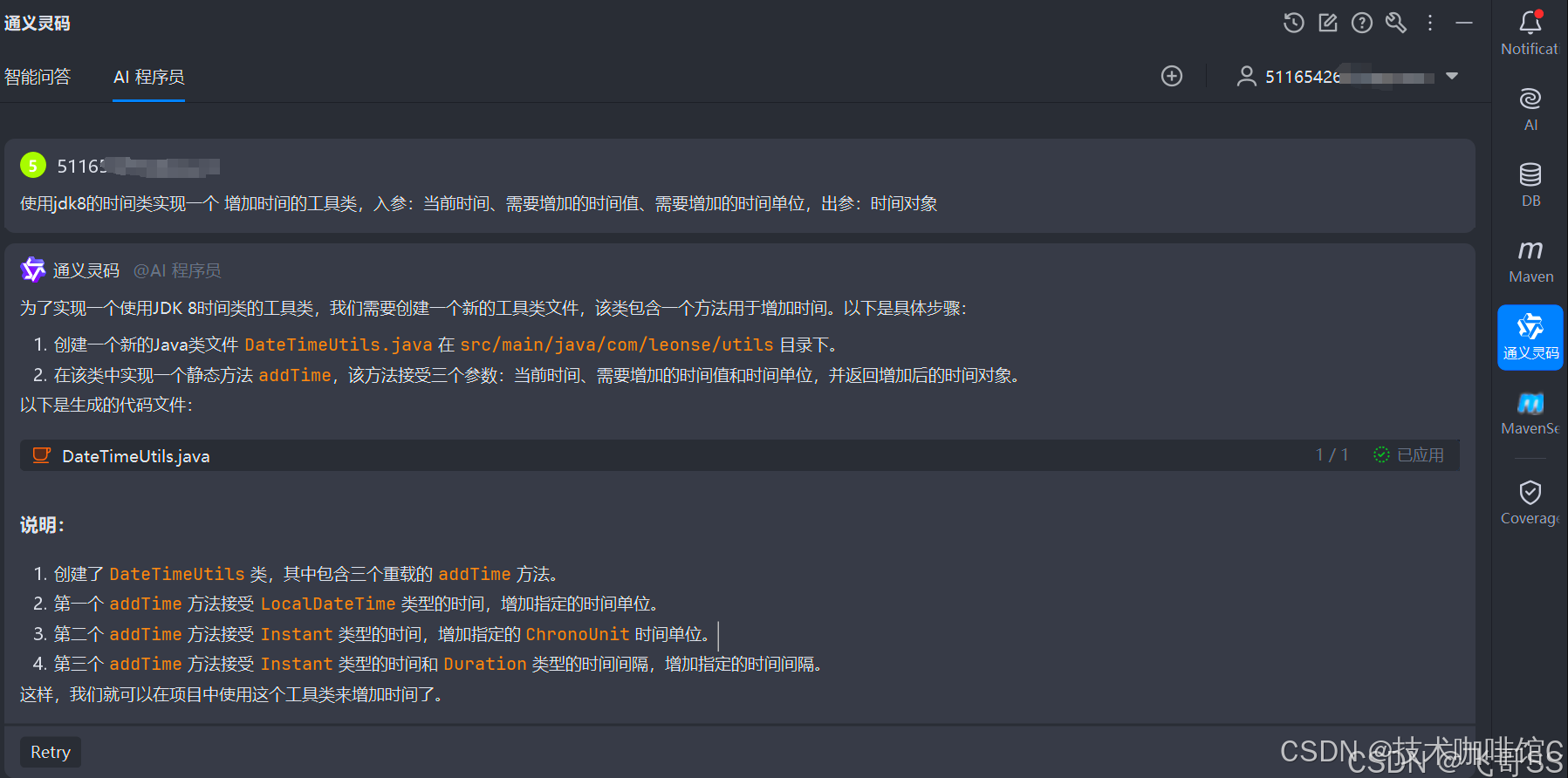
通义灵码插件保姆级教学-IDEA(安装及使用)
一、JetBrains IDEA 中安装指南
官方下载指南:通义灵码安装教程-阿里云
步骤 1:准备工作 操作系统:Windows 7 及以上、macOS、Linux; 下载并安装兼容的 JetBrains IDEs 2020.3 及以上版本,通义灵码与以下 IDE 兼容&…

工业级 RAG 实现 - QAnything
文章目录 1. QAnything简介2. QAnything 安装教程2. 1 安装软件包2.2 运行QAnything框架2.3 访问前端页面 3. QAnything 简单使用3.1 创建知识库3.2 创建聊天机器人3.3 关联知识库3.4 测试 4. QAnything 的分析:4. 1 QAnything 架构4. 2 两阶段检索4. 2.1 一阶段检索…

Cross-Resolution知识蒸馏论文学习
TPAMI 2024:Pixel Distillation: Cost-Flexible Distillation Across Image Sizes and Heterogeneous Networks 教师模型使用高分辨率输入进行学习,学生模型使用低分辨率输入进行学习
学生蒸馏损失:Lpkd和Lisrd
Lpkd:任务损失lo…

Versal - 基础3(AXI NoC 专题+仿真+QoS)
目录
1. 简介
2. 示例
2.1 示例说明
2.2 创建项目
2.2.1 平台信息
2.2.2 AXI NoC Automation
2.2.3 创建时钟和复位
2.3 配置 NoC
2.4 配置 AXI Traffic
2.5 配置 Memory Size
2.6 Validate BD
2.7 添加观察信号
2.8 运行仿真
2.9 查看结果
2.9.1 整体波形
2.9…

【PostgreSQL内核学习 —— (WindowAgg(一))】
WindowAgg 窗口函数介绍WindowAgg理论层面源码层面WindowObjectData 结构体WindowStatePerFuncData 结构体WindowStatePerAggData 结构体eval_windowaggregates 函数update_frameheadpos 函数 声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊…
推荐文章
- Quantum supremacy using a programmable superconducting processor 全文翻译,配公式和图
- # 基于OpenCV的图像拼接与文档检测:从特征提取到透视变换
- (二)趣学设计模式 之 工厂方法模式!
- .NET Core跨域
- [LeetCode]day17 349.两个数组的交集
- [SQL] 事务的四大特性(ACID)
- [动手学习深度学习]28. 批量归一化
- 《Linux运维实战:Ubuntu 22.04使用pam_faillock实现登录失败处理策略》
- 《OpenCV》——dlib(人脸应用实例)
- 《Operating System Concepts》阅读笔记:p460-p4470
- 《十七》浏览器基础
- 《周易》中的思想和方法在IT中的应用可能性探讨