自定义注解:
自定义注解中有三个元注解@Target,@Retention,@Document
/*** 系统日志注解** @author Mark sunlightcs@gmail.com*/
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface SysLog {String value() default "";
}
@Target(ElementType.METHOD) 表示只能在方法上声明
@Retention 元注解 注解标记其他的注解用于指明标记的注解保留策略
首先要明确生命周期长度 SOURCE < CLASS < RUNTIME ,所以前者能作用的地方后者一定也能作用。
一般如果需要在运行时去动态获取注解信息,那只能用 RUNTIME 注解,比如@RestController使用RUNTIME注解
如果要在编译时进行一些预处理操作,比如生成一些辅助代码(如 ButterKnife),就用 CLASS注解;
如果只是做一些检查性的操作,比如 @Override 和 @SuppressWarnings,使用SOURCE 注解。
注解@Deprecated,用来表示某个类或属性或方法已经过时,不想别人再用时,在属性和方法上用@Deprecated修饰
@Documented注解标记的元素,Javadoc工具会将此注解标记元素的注解信息包含在javadoc中。默认,注解信息不会包含在Javadoc中。
instanceof
- instanceof 是 Java 的保留关键字。
- 作用是:测试它左边的对象是否是它右边的类的实例,返回 boolean 的数据类型。
- instanceof是Java中的二元运算符,左边是对象,右边是类;当对象是右边类或子类所创建对象时,返回true;否则,返回false。
@XmlRootElement
便于对象与xml文件之间的转换
@XmlRootElement( name="doc" )
public class Document {@XmlElementprotected Foo foo;// ...
}<?xml version="1.0" encoding="UTF-8"?>
<doc><foo>...</foo>
</doc>Java Document 工具类
Java 对本地HTML文件的读取和写入的工具类,可以用来修改静态HTML的内容
@Deprecated 说明
- 若类、方法、属性加上该注解之后,表示不再建议使用,调用时会出现删除线,但并不代表不能用,只是不推荐使用,因为有更好的替代
二级缓存
Redis+Guava
Guava Cache 是其中的一个专门用于处理本地缓存的轻量级框架,是全内存方式的本地缓存,而且是线程安全的
和 ConcurrentMap 相比,Guava Cache 可以限制内存的占用,并可设置缓存的过期时间,可以自动回收数据,而 ConcurrentMap 只能通过静态方式来控制缓存,移除数据元素需要显示的方式来移除。
先去查看缓存,若缓存中没有数据则去访问数据库,同时将数据更新至缓存
优点:
- 保证最小的缓存量满足精确查询业务,避免冷数据占用宝贵的内存空间
- 对增删改查业务入侵小、删除即同步
- 可插拔,对于老系统升级,历史数据无需在启动时初始化缓存
缺点:
- 数据量需可控,在无限增长业务场景不适用
- 在微服务场景不利于全局缓存应用
微服务场景下,多个微服务使用一个大缓存,流数据业务下,高频读取缓存对 Redis 压力很大,最终导致缓存雪崩,进而引发我们的服务雪崩。我们使用本地缓存结合 Redis 缓存使用,降低 Redis 压力,同时本地缓存没有连接开销,性能更优
把热点数据(热key)放到我们JVM的本地缓存中,本地缓存可以使用caffeine,ehcache,guava。本文介绍Guava进行实现。
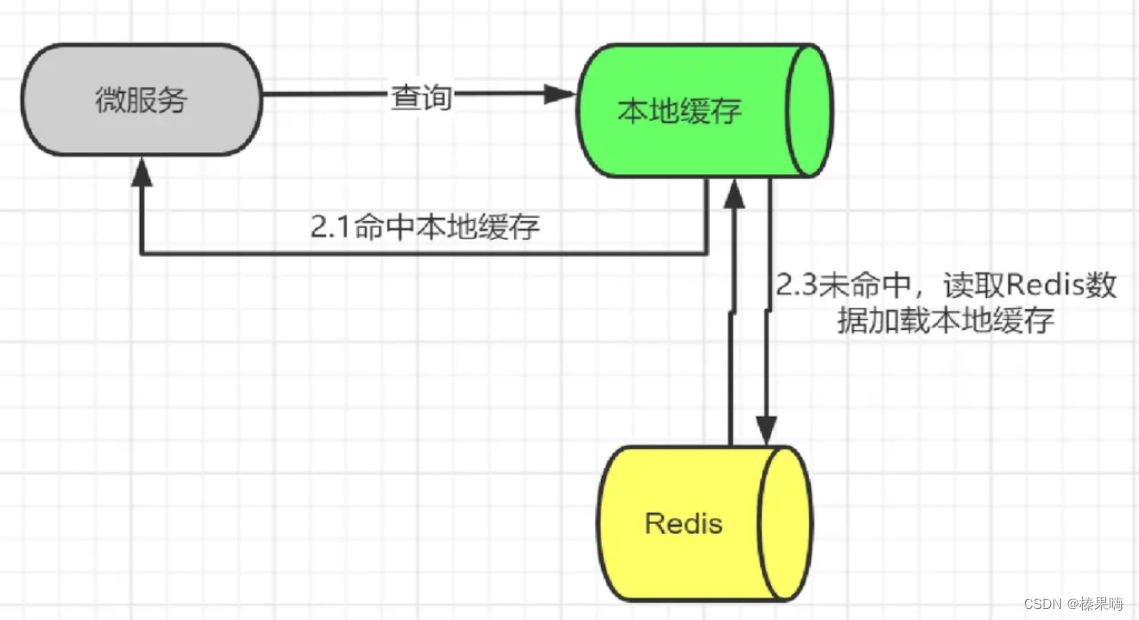
如果是通过redis集群来实现的,我们可以通过一致性hash算法构建一个hash环,主要是防止某一个或者某些个redis结点宕机或者下线而导致数据丢失的问题以及我们后面动态进行扩容的问题
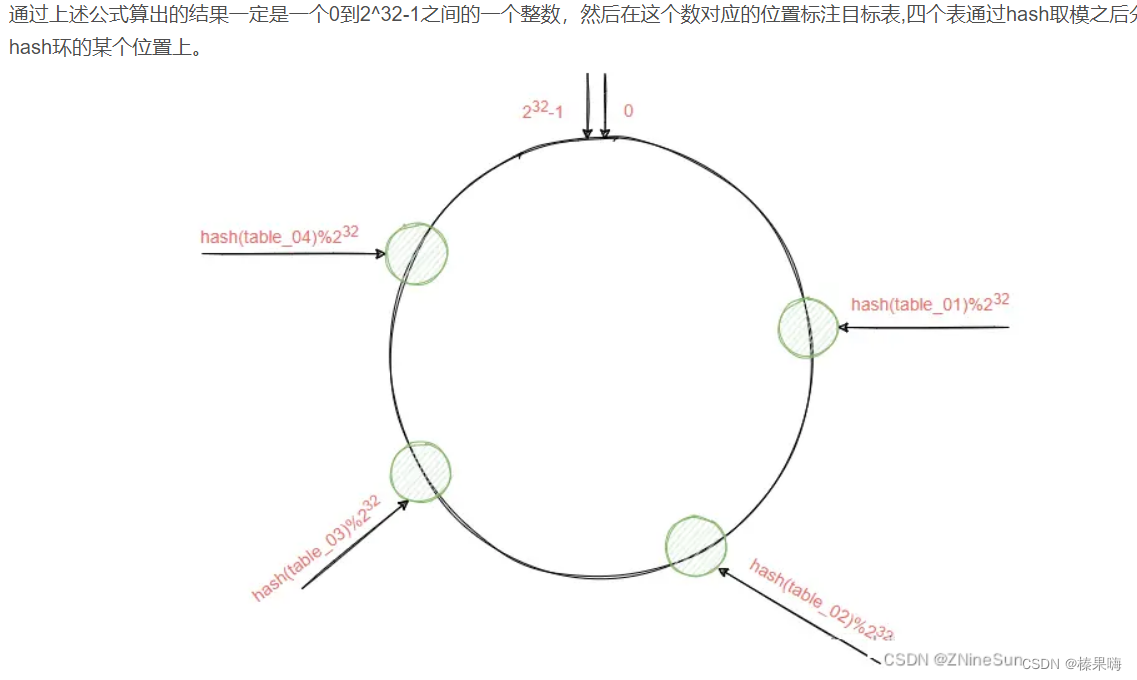
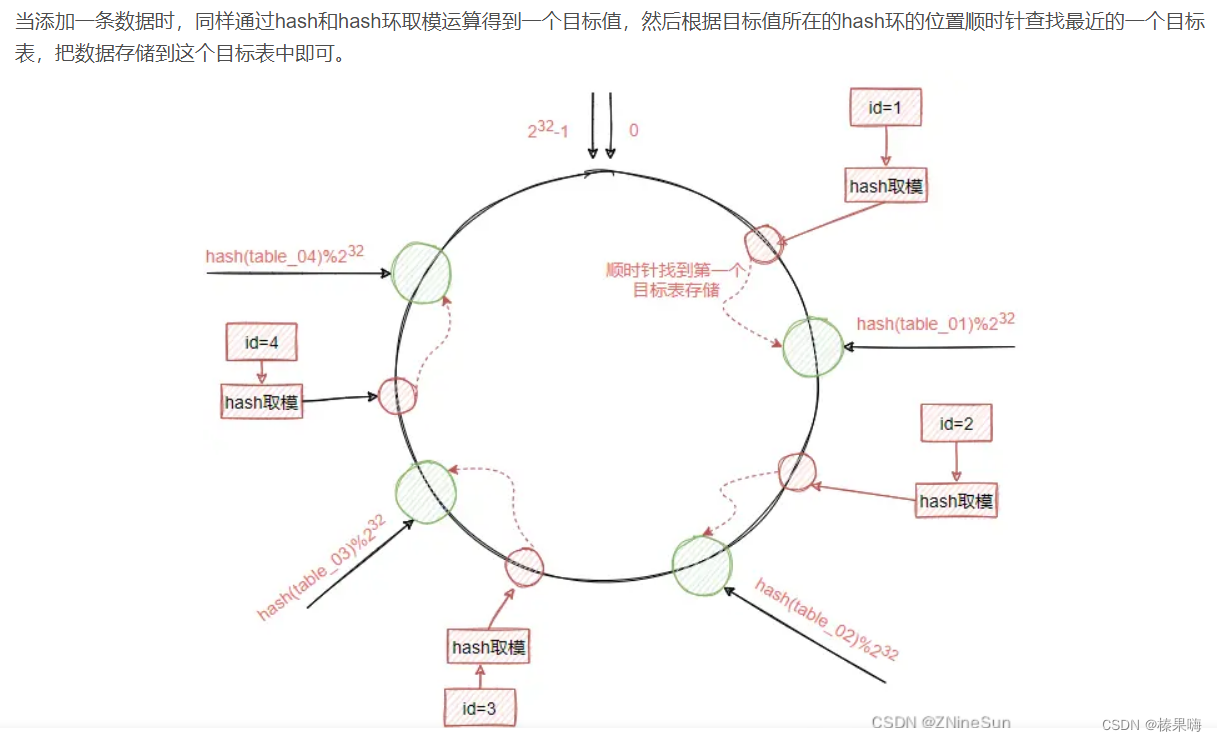
hash取模算法,实际上对目标表或者目标数据库进行hash取模,一旦目标表或者数据库发生数量上的变化,就会导致所有数据都需要进行迁移,为了减少这种大规模的数据影响,才引入了一致性hash算法。
一致性哈希将整个哈希值空间组织成一个虚拟的圆环,取模运算不是直接对这四个表来完成,而是对2^32来实现,
guava的数据回收策略
对于guava的数据删除分为被动移除和主动移除两种
被动移除
基于大小的移除
看字面意思就知道就是按照缓存的大小来移除,如果即将到达指定的大小,那就会把不常用的键值对从cache中移除。
guava提供了两个基于时间移除的方法:
- expireAfterAccess(long, TimeUnit) 这个方法是根据某个键值对最后一次访问之后多少时间后移除
- expireAfterWrite(long, TimeUnit) 缓存项在给定时间内没有被写访问(创建或覆盖),则回收。如果认为缓存数据总是在固定时候后变得陈旧不可用,这种回收方式是可取的
基于引用的移除
- 这种移除方式主要是基于java的垃圾回收机制,根据键或者值的引用关系决定移除。
主动移除数据
主动移除有三种方法:
- 单独移除 Cache.invalidate(key)
- 批量移除 Cache.invalidateAll(keys)
- 移除所有 Cache.invalidateAll()
参考:千万级并发架构下,如何进行关系型数据库的分库分表_ZNineSun的博客-CSDN博客
Redis+Guava实现高性能的二级缓存_guavacache和redis结合使用_ZNineSun的博客-CSDN博客