一、考虑的因素(仅代表个人观点)
1.首先我们看到他的这篇文章所考虑的不同方面从而做出的不同改进,首先考虑到了对于基因组预测的深度学习方法的设计 ,我们设计出来这个方法就是为了基因组预测而使用,这也是主要目的,所以要抓住事物的主要方面。
2.DNNGP相比于其他方法的预测准确性的比较,提出一个新方法当然要比其它方法在某些方面表现的要更好,才证明有可行性,比其他方法有改进才可以。
3.这篇文章的创新之处还有就是输入数据形式的不同,输入数据的形式支持多种格式,在这当然也要比较不同输入形式下的预测准确性。
4.通过使用DNNGP在所有的数据集中捕捉到的非线性关系,能够找到数据集之间更多的关系。
5.样本量的大小对预测方法的影响,通常来说的话也是样本集越大预测方法的准确性便越高,样本集的大小通常来说都是衡量预测方法性能的一个重要评判标准,要注意观察随着样本量的增加是不是准确率越来越高。
6.SNP的数量对预测方法的影响性也是很大的,所以也要考虑不同SNP数量的影响,结合样本量的大小的话是不是可以同时考虑样本量的大小和SNP数量的组合,设置不同的组合来分别进行验证。
7.假如模型准确性的提升带来的是计算时间的提升,也要考虑两个因素的共同影响了,如何才能选择更优化的方案,准确性高的同时不以牺牲其它指标为代价。
当然无论什么样的方法可能在某个特定的数据集或者某个品种的数据集下的表现比较好,但是换了其它数据集的表现效果就会因数据集而异了,评判一个方法的好坏需要在多个数据集上得到验证。
二、不同方法比较
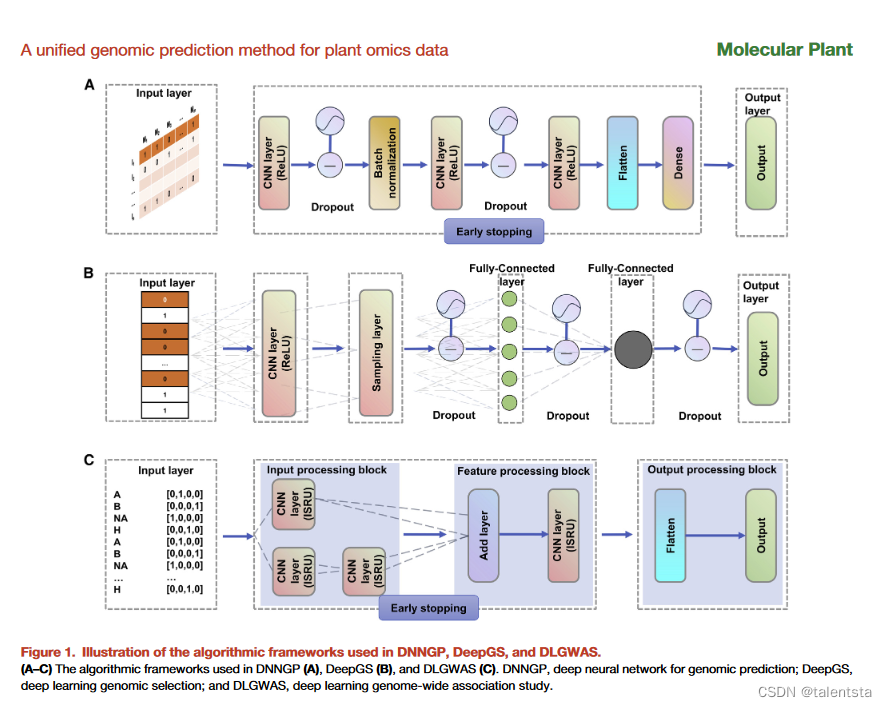
DNNGP相比DeePGS的亮点是在于多加了 early stopping ,相比于 DLGWAS 的亮点是多加了Batch normalization 结构,根据这个模型是不是可以创造出相对更复杂一些的神经网络来提升准确率,降维之后的数据是否还能准确反应之前未降维数据的线性关系,考虑进环境和基因组关系后模型表现又如何呢
三、early stopping 结构详解
early stopping 是一种常用的深度学习regularization技术,可以提前停止神经网络的训练,以避免过拟合。它的工作原理是:
1. 划分出验证集。一般从训练数据中划出一部分作为验证集。
2. 训练时同时在训练集和验证集上测试模型。
3. 记录验证集loss,如果验证集loss在连续一定Steps(如50)未提升,则停止训练。
4. 返回最佳模型参数(validation loss最小时的参数)。Early stopping的主要作用是:- 避免模型在训练集上过拟合,从而提高模型在测试集上的泛化能力。- 提前停止无效的训练,节省计算资源和时间。- 提取最优模型参数,避免模型退化。
使用Early Stopping的主要注意事项:- 需要设置patience参数,即容忍多少个epoch验证集loss不下降就停止。- 验证集大小需要合适,太小难以反映泛化能力,太大影响模型训练。- 需要保存最佳模型参数。训练结束后需要加载最佳参数。- 可结合其他正则化方法如L2正则化使用。
总之,Early stopping是深度学习中比较常用并有效的一种正则化技术。
import tensorflow as tf
# 设置early stopping参数
PATIENCE = 20 # 容忍20个epoch视为loss不下降
STOP_DELTA = 0.001 # loss变化小于0.001视为不下降
model = tf.keras.Sequential()
# 构建模型...
# 定义early stopping的回调函数
early_stopping = tf.keras.callbacks.EarlyStopping(monitor='val_loss', # 监控验证集losspatience=PATIENCE,min_delta=STOP_DELTA,restore_best_weights=True # 是否将模型恢复到best weights
)model.compile(optimizer='adam', loss='sparse_categorical_crossentropy',metrics=['acc'])history = model.fit(train_data, train_labels, validation_data=(val_data, val_labels),epochs=100, callbacks=[early_stopping])# 加载恢复最优模型参数
model.load_weights(early_stopping.best_weights) # 进行评估和预测1. 设置Early Stopping的参数:- PATIENCE = 20:连续20个epoch验证集loss不下降,就停止训练。- STOP_DELTA = 0.001:这个是最小变化程度,如果一个epoch的loss比上个epoch的loss下降了不到0.001,就认为loss没有下降。- restore_best_weights = True:在停止训练的时候,是否将模型的参数值恢复到最佳状态(即验证集loss最小时的参数)。连续训练20次后损失函数的值没有超过下降阈值时便停止训练,损失之在训练迭代的时候它的值不是只会下降,也有可能会上升,True就代表返回的值是验证集 loss 最小时候的值,即代表最佳状态。
2. 定义回调函数EarlyStopping:- monitor='val_loss':指定要监控验证集的loss值。- patience=PATIENCE:设置之前定义的PATIENCE值。- min_delta=STOP_DELTA:设置之前定义的最小变化程度。- restore_best_weights=True:恢复最佳参数状况。
3. 模型训练:- 通过callbacks参数设置回调函数early_stopping。- 当触发early stopping条件时,自动停止训练。
4. 恢复最佳参数:- early_stopping.best_weights储存了最佳参数值。- 通过model.load_weights()恢复这些最佳参数。这样就实现了Early Stopping的整个流程,避免模型过拟合,得到最佳参数。
5.compile函数含义
在TensorFlow/Keras中,compile是模型配置和优化的一个过程,主要包括以下作用:1. 指定损失函数:模型将使用何种损失函数来评估当前参数情况下的预测误差。常见的有mse、binary_crossentropy等。2. 指定优化器:训练模型时使用的优化算法,如sgd、adam、rmsprop等。优化器负责基于损失函数更新模型参数。3. 指定评估指标:用于监控模型训练和测试的指标,如accuracy、AUC等。这些指标不会用于训练,只是进行评估。4. 将损失函数和优化器关联到模型:将定义的损失函数和优化器“编译”到模型上,完成模型的配置。5. 编译计算图:针对特定的后端(TensorFlow、Theano等)编译模型的计算图,为训练和预测优化计算图的结构和执行。一个典型的compile示例如下:
model.compile(optimizer='rmsprop',loss='categorical_crossentropy', metrics=['accuracy']
)这里指定了优化器rmsprop、损失函数categorical_crossentropy、评估指标accuracy。综上,compile对模型进行各种设置,建立模型Optimization的相关计算图,使模型成为一个可训练的状态,这是一个必须的步骤。之后才可以使用model.fit进行训练。
Early Stopping 主要适用于以下几种情况:
1. 模型容易过拟合的情况。对于容易在训练数据上过拟合的模型,使用 Early Stopping 可以避免模型过度复杂化。
2. 需要找到最佳模型的情况。Early Stopping 可以通过保留最佳参数,避免模型在迭代后期发生退化。
3. 计算资源有限的情况。Early Stopping 可以减少不必要的训练迭代,节省计算时间和资源。
4. 需要调节过拟合和欠拟合的情况。通过设定 Early Stopping 的超参数,可以得到适当的过拟合程度。
随着迭代次数增加,模型的训练 loss 和验证 loss 的变化一般有以下几种情况:
1. 欠拟合:训练 loss 和验证 loss 都在下降,但验证 loss 下降缓慢或效果不明显。
2. 过拟合:训练 loss 持续下降,但验证 loss 下降缓慢甚至开始上升。
3. 正常:训练 loss 和验证 loss 均较快下降,然后变缓。验证 loss 达到局部最小值时停止迭代。
4. 发散:训练 loss 和验证 loss 均再次上升,模型出现问题。Early Stopping 主要用于情况2,避免过拟合。设置合适的 Early Stopping 阈值,可以在情况1、2、3中停止训练,取得最佳模型。
四、Batch normalization结构详解
Batch Normalization (批标准化)是深度学习中一个常用的正则化技术。它的主要作用是:
1. 加速训练过程,模型收敛速度更快。
2. 减少对参数初始化的依赖。
3. 减少过拟合,提高泛化能力。它的工作原理是:在网络的中间层(通常是卷积层或全连接层)中,对每个batch的数据进行标准化(均值为0,方差为1)。标准化公式如下:x_norm = (x - μ) / (σ+ε)这里 x 是原始数据,μ和σ分别是该batch数据的均值和方差,ε是一个很小的数(防止分母为0)。通过减去batch的均值,然后除以方差,实现标准化。这样可以减小内部covshift的问题。在测试时,使用整个训练过程中均值和方差的移动平均值进行标准化。
Batch Normalization的使用注意事项:- 一般只适用于中间层,不要应用在网络输出。- 在ReLU之后、激活函数之前使用。- 训练和测试时的表现可能不太一样,需要校正。- 可能影响某些优化器的效果。总之,BN通过减小内部covshift,加速训练过程,对参数初始化和过拟合都有很好的控制效果。是深度学习中非常重要的技术之一。
BN(Batch Normalization)可以减小内部covshift(内部 covariate shift)。covshift指的是在神经网络的训练过程中,每一层输入数据的分布在不断发生变化。由于每一层的参数会影响后面层的输入分布,所以会导致后面层的输入分布随着训练的进行而发生变化。这种变化称为内部covshift。内部covshift会对训练过程产生负面影响:- 后层需要不断适应前层分布的变化,造成训练过程波动和收敛缓慢。- 模型对参数初始化更加敏感。BN的标准化操作可以减小covshift。因为每层输入进行标准化后,其分布变化会被很大程度抑制,使各层输入分布相对稳定。这就加快了模型的收敛速度,降低了对参数初始化的依赖。同时也减少了过拟合风险,起到了正则化的作用。总之,减小内部covshift是BN技术的核心作用和数学基础,这带来了训练加速和正则化的双重收益。
import tensorflow as tf# 创建输入数据,shape为[batch_size, height, width, channels]
x = tf.placeholder(tf.float32, [None, 32, 32, 3])# 创建BN层
beta = tf.Variable(tf.constant(0.0, shape=[3]))
gamma = tf.Variable(tf.constant(1.0, shape=[3]))
batch_mean, batch_var = tf.nn.moments(x, [0,1,2], keepdims=True)
x_normalized = tf.nn.batch_normalization(x, batch_mean, batch_var, beta, gamma, 0.001)# BN层在训练和测试中的moving average
ema = tf.train.ExponentialMovingAverage(decay=0.5)
maintain_averages_op = ema.apply([batch_mean, batch_var])with tf.control_dependencies([maintain_averages_op]):training_op = tf.no_op(name='train')mean, variance = ema.average(batch_mean), ema.average(batch_var)
x_normalized_inference = tf.nn.batch_normalization(x, mean, variance, beta, gamma, 0.001)BN层实现的代码:
1. x 是输入数据,shape为[batch_size, height, width, channels]。TensorFlow的placeholder,用来定义输入数据x的形状和类型。具体来看:1. tf.placeholder: 创建一个占位符tensor,在执行时需要填入实际的tensor。2. tf.float32: 定义placeholder中的数据类型为32位浮点数(float32)。3. [None, 32, 32, 3]: 定义了placeholder的形状shape,是一个4维tensor。4. None: 第一个维度设置为None,表示batch大小不定,可以是任意正整数。5. 32, 32: 第二和第三个维度固定为32,表示输入图像的高度和宽度均为32像素。6. 3: 第四个维度固定为3,表示输入中的通道数,这里为RGB 3通道图像。7. 所以整体的shape表示可以输入batch大小不定的32x32大小的RGB图像。这样定义的placeholder x在运行时需要填入实际的输入tensor,比如一个batch size为128的32x32 RGB图像,则传入的tensor应该是[128, 32, 32, 3]的形状。
这里x表示BN层的输入数据,它的shape为[batch_size, height, width, channels]:- batch_size:表示一个batch中样本的数量。- height:输入图片的高度。- width:输入图片的宽度。- channels:输入图片的通道数,例如RGB图像为3通道。举个例子,如果输入是RGB图像,batch size为128,图像大小是32x32,那么x的shape就是[128, 32, 32, 3]。其中第一个维度128表示这个batch中有128张图像,后三个维度表示每张图像的高、宽和通道数。BN层就是在这种shape的4D输入数据上进行运算的,先计算这个batch的均值和方差,然后进行标准化。不同batch之间进行标准化使用了移动平均的均值和方差。所以明确输入x的shape对理解BN的运算对象非常重要。这也是BN层只能在4D张量上进行运算的原因,需要确定样本、空间和特征维度进行标准化。
2. beta和gamma是可训练的缩放参数,shape为[channels],分别初始化为0和1。在批标准化(Batch Normalization)层中,beta和gamma是两个可训练的参数:- beta: 是一个偏移量,通常初始化为0。shape与特征矩阵的通道维度相同。- gamma:是一个缩放参数,通常初始化为1。shape与特征矩阵的通道维度相同。批标准化的计算公式如下:x_norm = (x - μ) / σ # μ和σ为x的均值和方差
out = gamma * x_norm + beta可以看到,beta和gamma分别用来进行偏移和缩放,以便恢复标准化前的数据分布。因此,beta和gamma增加了BN层的表达能力,模型可以学习到适合当前任务的偏移和缩放参数。在BN层实现时,我们需要创建beta和gamma变量,并在训练过程中更新,以优化模型的效果。
总结一下,beta和gamma是BN层中的可学习参数,起到偏移和缩放的作用,用来校正标准化后的结果,提高模型的适应性。它们和特征维度大小相同,并可以通过反向传播更新。
3. batch_mean和batch_var计算输入x在当前batch上的均值和方差。moments函数计算KEEP_DIMS为True的mean和variance。
4. x_normalized利用batch_mean和batch_var对x进行标准化。加上beta和gamma进行缩放。
5. ema对象维护batch_mean和batch_var的移动平均值,decay控制平均的速度。
ema对象在这里是用于维护batch_mean和batch_var的移动平均的。ema代表指数移动平均(Exponential Moving Average),它的计算公式如下:ema_t = decay * ema_{t-1} + (1 - decay) * value_t这里:- ema_t 是时刻t的移动平均值
- ema_{t-1} 是上一时刻的移动平均值
- value_t 是当前时刻的监测值,这里是batch的mean和variance
- decay 是衰减因子,控制平均的速度decay越大,EMA会更多地依赖历史,变化越缓慢。decay越小,EMA对新的value更敏感。在BN中,训练时直接使用batch的mean/variance;而测试时使用EMA的mean/variance。这是因为batch mean在训练时可计算但测试时不可用。EMA可以更平滑地跟踪训练过程中的mean/variance变化,用来模拟测试时的mean/variance。所以ema对象在这里的作用就是维护训练mean/variance的EMA,decay控制EMA的更新速度。这是让BN层在训练和测试中获得一致性的关键。
6. maintain_averages_op通过ema.apply更新移动平均值。控制依赖关系确保此操作执行。
7. training_op是一个空操作,但控制依赖关系使moving average得以更新。
8. mean和variance取两个移动平均值,用于推理时标准化。