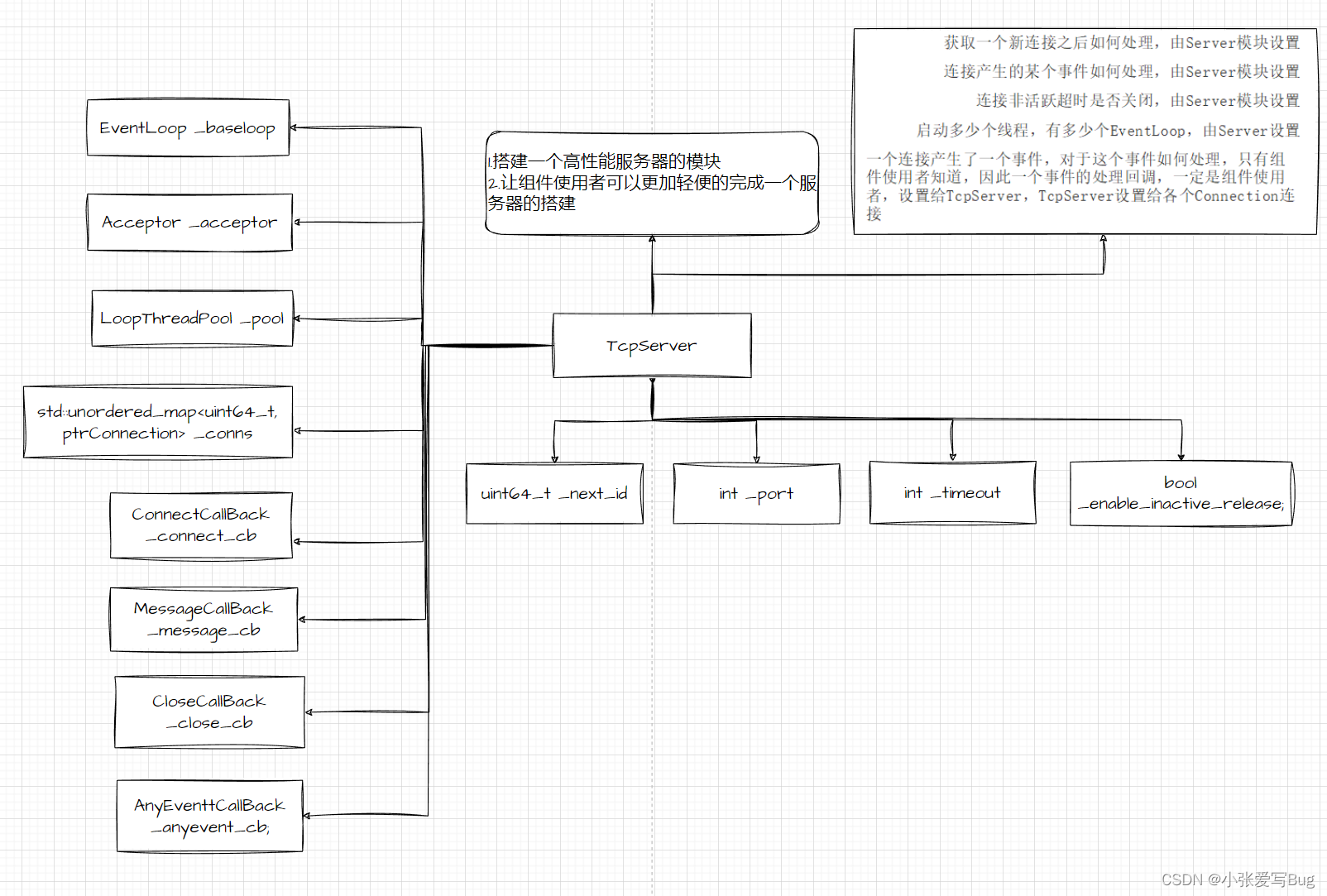
数据预处理
- 💫数据预处理的重要性
- 💫处理缺失值
- ⭐️识别表格中的数据
- ⭐️计算每列缺失值的数量
- ⭐️删除含有缺失值的样本或特征
- ⭐️填充缺失值
- 💫处理异常值
- ⭐️异常值的鉴别
- ⭐️异常值的处理
- 💫将数据集划分为训练数据集和测试数据集
💫数据预处理的重要性
数据预处理在数据分析和机器学习中起着非常重要的作用。它是数据分析和机器学习流程中的第一步,决定了后续分析和建模的质量和可靠性。
数据预处理包括数据清洗、数据转换等步骤。
在数据清洗中,我们需要对数据的缺失值情况进行检验并用剔除法或插值法等方法进行替换,同时,我们需要检验数据的异常值情况,并对异常值进行替换或者删除处理。有时候还需要对重复值进行处理等等,通过数据清洗,可以使得我们的数据更加干净和可靠。
在实际应用中,我们拿到的数据不一定都是数值型数据让我们可以直接上手分析,很多情况下,我们拿到的数据往往会以不同的形式和单位进行表示,这时候就需要我们将数据转化为利于我们分析和建模的形式,比如利用独热编码解决标称特征列。例如,可以进行数值化、标准化、归一化、离散化等操作,使得数据更加易于处理和比较。
综上所述,数据的预处理在数据分析和机器学习中起着非常重要的作用,它可以帮助我们提高数据分析和机器学习的效果。因此,在进行数据分析和机器学习之前,进行数据的预处理是非常必要和重要的。
💫处理缺失值
在我们拿到的表格数据中,表格中的空白或者占位符很常见。如果我们将表格数据的前几行打印,若有空缺值,输出端会显示出
NaN(代表“非数字”),计算机一般无法处理这些缺失值。如果简单的忽略这些缺失值,会产生不可预知的后果。因此,在进一步分析之前,必须要想处理这些缺失值。
⭐️识别表格中的数据
在这篇文章中,我使用的数据是经典的葡萄酒数据进行预处理及分析。
首先我们导入数据。
import pandas as pd
file_path="D:\A_data\Data_wine数据\wine.xlsx"
df=pd.read_excel(file_path)
df
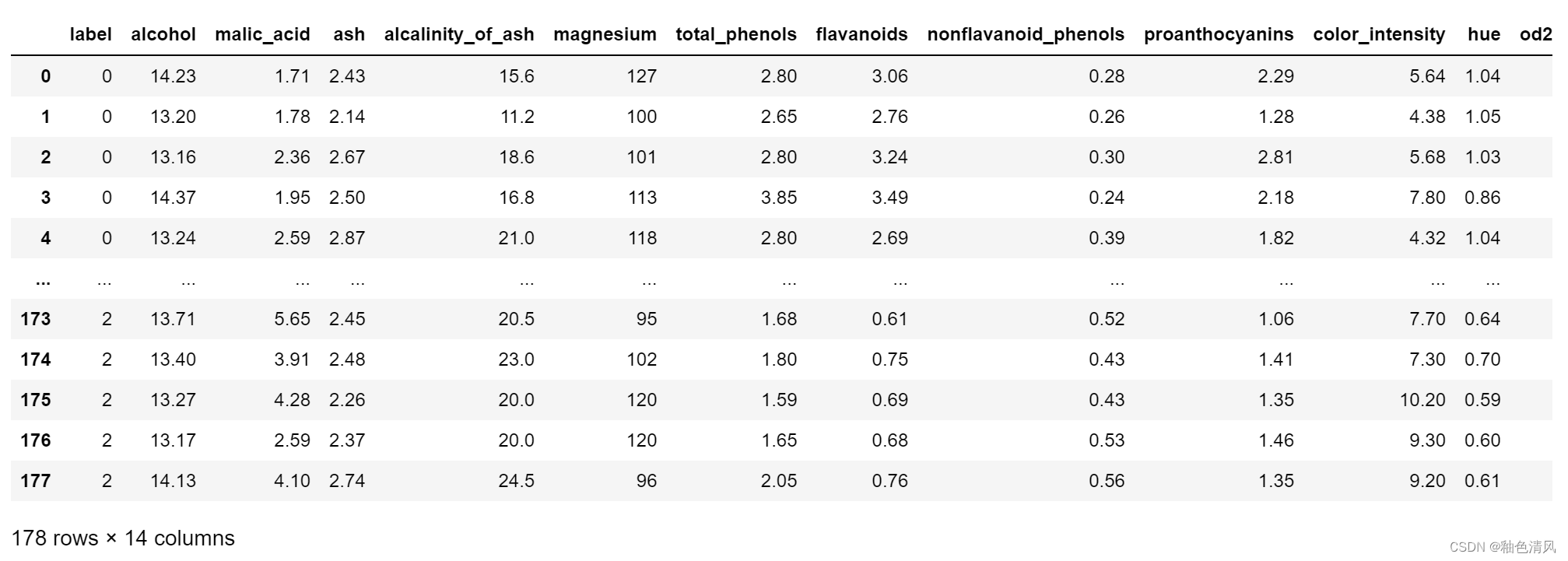
首先,我们可以看出该葡萄酒数据一共有178行,14列。在这14列中,第一列是类别(即葡萄酒有三种不同的类别,用数字0、1、2进行表示),2-14列都是葡萄酒的特征。
⭐️计算每列缺失值的数量
使用isnull方法查找缺失值,其返回值为一个存有布尔值的DataFrame。使用sum方法可以计算出每一列包含缺失值的数量。
df.isnull().sum()
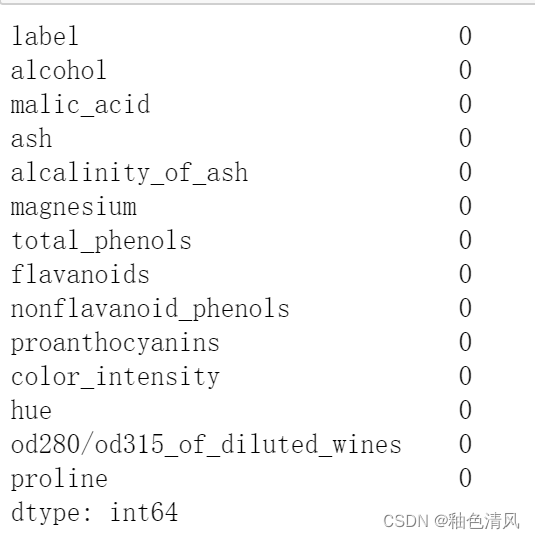
可以看出在这个葡萄酒数据集中没有缺失值。
⭐️删除含有缺失值的样本或特征
处理缺失值最简单的方法之一就是从数据集中完全删除缺失值对应的样本(行)或者特征(列)。
例如:
使用dropna方法删除所有包含缺失值的行:
df.dropna(axis=0)
将参数axis设置为1,可以删除包含缺失值的列:
df.dropna(axis-1)
虽然删除缺失值的方法简单,但是有时候删除太多行使得样本数据
大大减少,从而使得数据分析的结果变得不可靠。删除太多特征列将会丢失用于分类任务的辨别性信息。
⭐️填充缺失值
通常,我们最常用的方法就是
插值法。即根据数据集中其他样本估计缺失数据的值。 常用的一种插值方法是均值插补,均值插补是使用整个特征列的均值替换缺失值。
可以调用Scikit-Learn中的SimpleImputer类实现均值插补,代码如下所示:
from sklearn.impute import SimpleImputer
import numpy as np
imr=SimpleImputer(missing values=np.nan,strategy='mean')
imr=imr.fit(df.values)
imputed_data=imr.transform(df.values)
strategy参数还可以设置为median(中位数)或者most_frequent(众数)。
还有一种实现缺失值插补的方法。可以使用pandas的fillna方法实现缺失值插补。使用fillna方法时需要提供插补方法作为参数。
例如,使用pandas时可以命令在DataFrame对象中实现均值插补。
df.fillna(df.mean())
💫处理异常值
异常值,指的是样本中的一些数值明显偏离其余数值的样本点,所以也称为离群点。异常值分析就是要将这些离群点找出来,然后进行分析。
⭐️异常值的鉴别
箱型图很适合鉴别异常值,具体的判断标准是计算出数据中的最小估计值和最大估计值。如果数据数据超过这一范围,说明该值可能为异常值。箱型图会自动标出此范围,异常值则用圆圈表示。
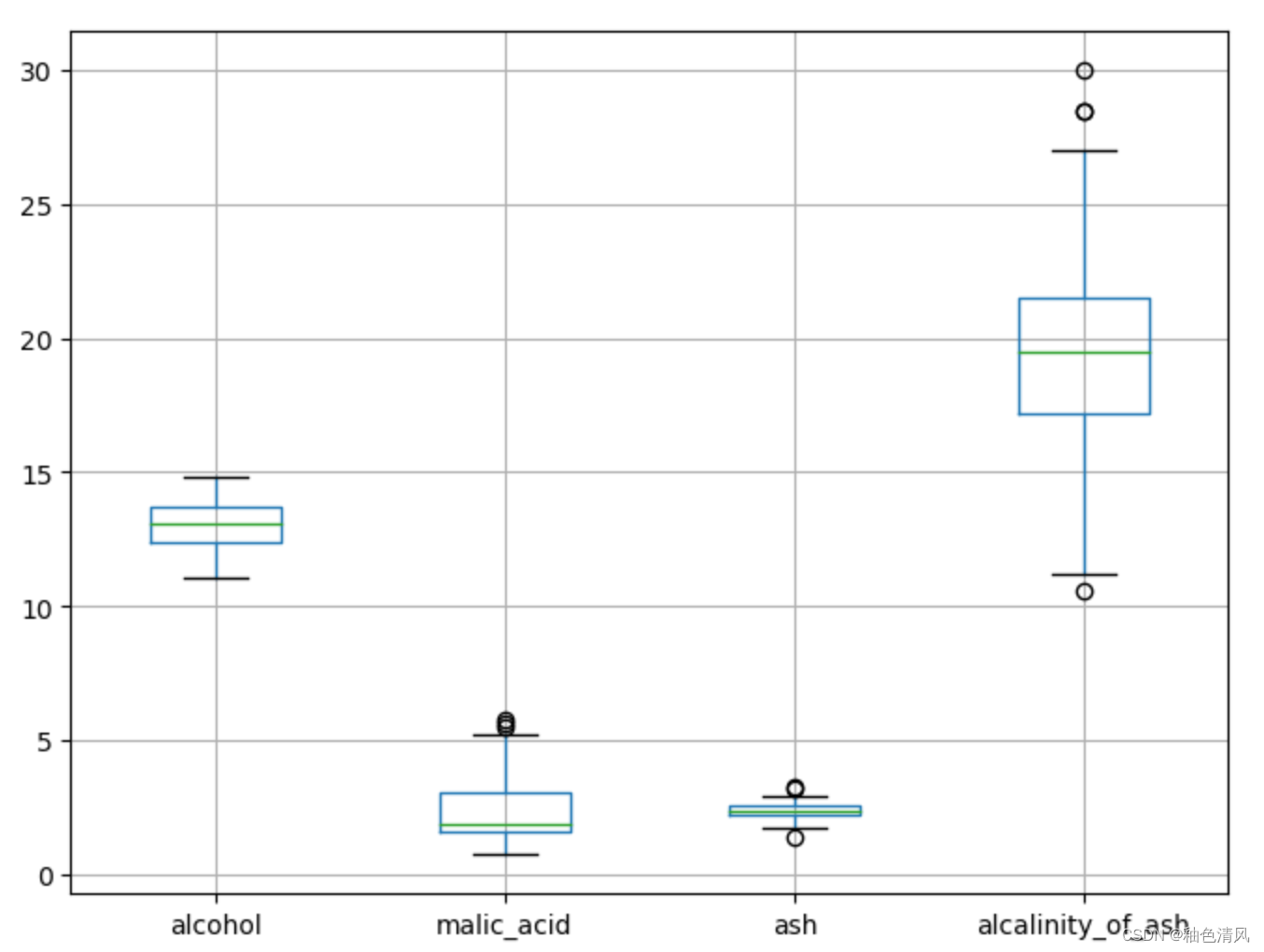
下面我们以葡萄酒数据为例,绘制出13个特征列的箱型图,观察有无异常值。
import matplotlib.pyplot as plt
fig = plt.figure(figsize = (8, 6))# 绘制
scores = ['alcohol', 'malic_acid', 'ash','alcalinity_of_ash']
_df = df[scores]
_df.boxplot()
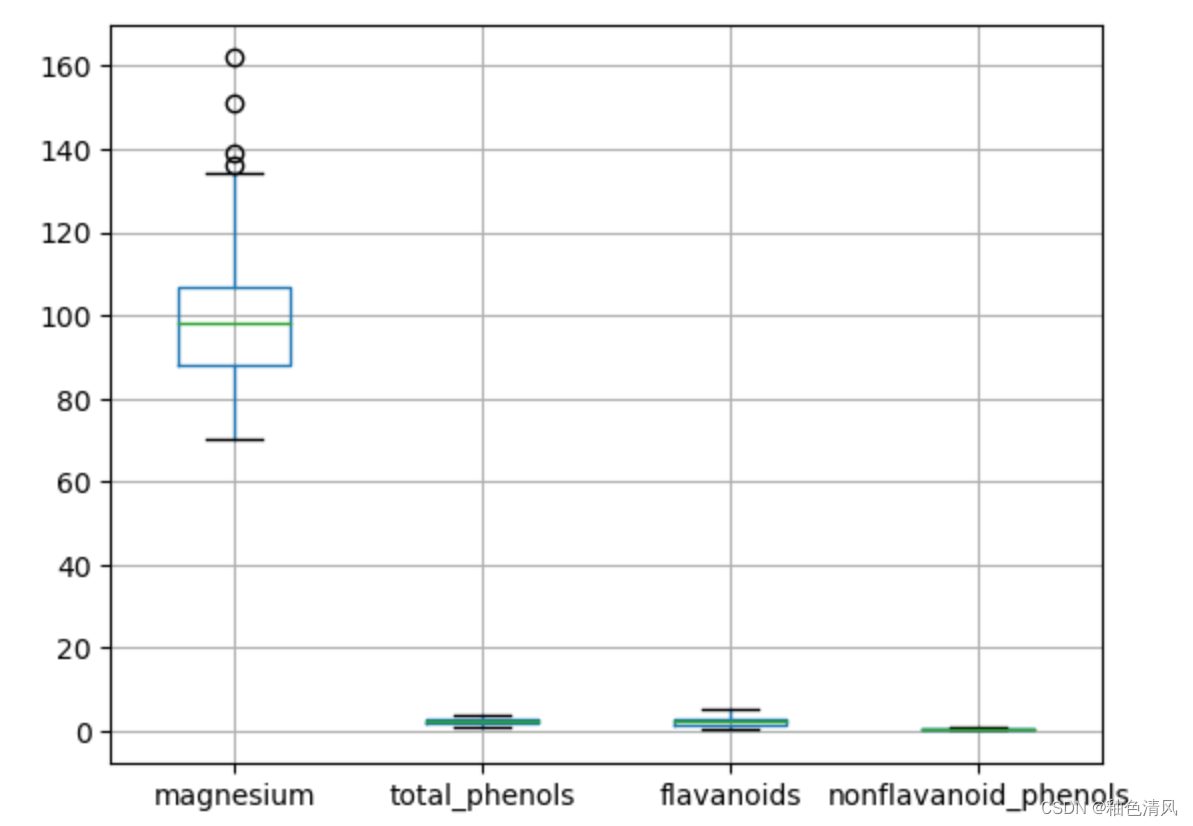
scores = ['magnesium', 'total_phenols', 'flavanoids','nonflavanoid_phenols']
_df = df[scores]
_df.boxplot()
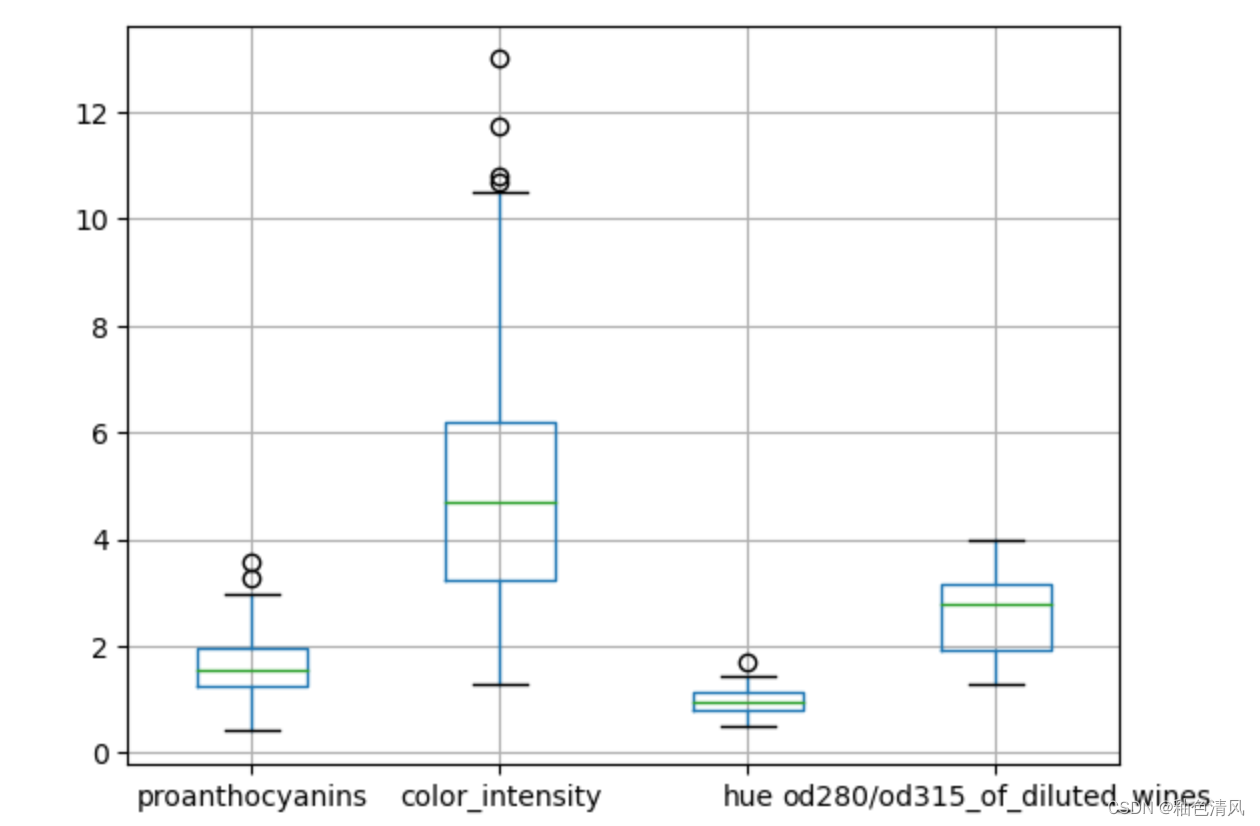
scores = ['proanthocyanins','color_intensity','hue','od280/od315_of_diluted_wines']
_df = df[scores]
_df.boxplot()
scores=['proline']
_df = df[scores]
_df.boxplot()
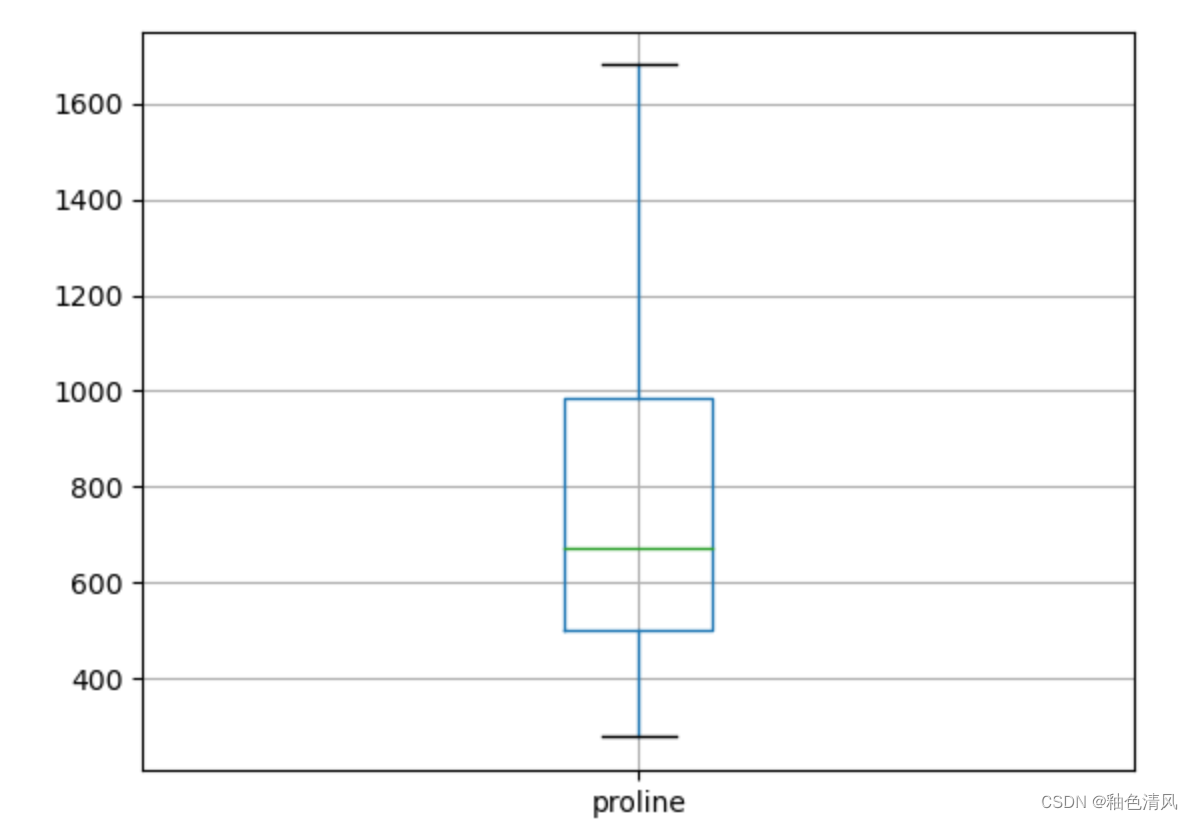
通过上面的箱型图,我们可以看出malic_acid,ash,alcalinity_of_ash,magnesium,proanthocyanins,color_intensity,hue这些特征列含有异常值。
⭐️异常值的处理
如果有异常值的特征列比
较少,且样本数量比较大时,我们可以考虑删除异常值。 如果异常值非常多时,则可能需要进行填补设置,同处理缺失值一样,我们可以用平均值,中位数,众数等来填补。
可以将处理方法包装成一个函数,方便对含有异常值的列进行处理。
def box_outliers(data, fea, scale):Q1 = data[fea].quantile(0.25)Q3 = data[fea].quantile(0.75)IQR = Q3 - Q1lower_bound=Q1-1.5*IQRupper_bound=Q1+1.5*IQRcond=(data[fea]<lower_bound)|(data[fea]>upper_bound)data[fea][cond]=data[fea].mean()return data
调用函数
box_outliers(df,'alcohol',1.5)
💫将数据集划分为训练数据集和测试数据集
使用Scikit-Learn的model_selection子包中的tran_test_split函数将数据集随机划分为独立的训练数据集和测试数据集:
from sklearn.model_selection import train_test_split
X,y=df.iloc[:,1:].values,df.iloc[:,0].values
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=0,stratify=y)
把分类标签y作为stratify的参数可以保证训练数据集和测试数据集具有相同的类别标签比例。