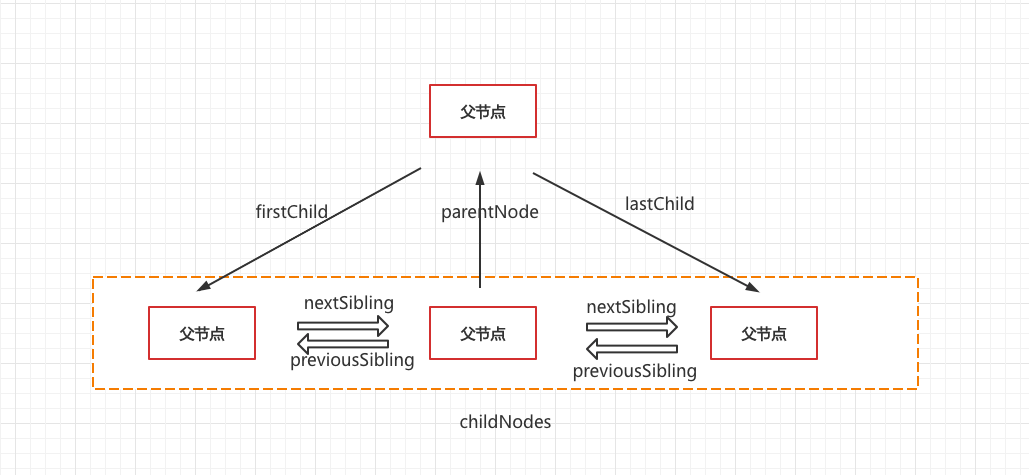
回顾使用requests如何实现自动登录一文中,提到好多网站在我们登录过后,在之后的某段时间内访问该网页时,不会给出请登录的提示,时间到期后就会提示请登录!这样在使用爬虫访问网页时还要登录,打乱我们的节奏,并详细介绍了使用requests爬取网页时为实现自动登录获取键Cookie对应的值的过程。
那么selenium如何实现自动登录呢?又如何获取键Cookie对应的值呢?
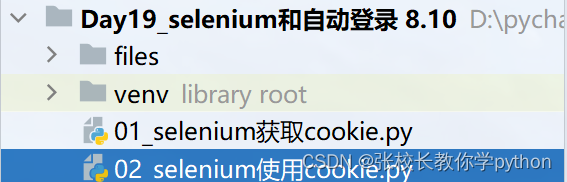
开始之前我们先把项目创建好,如下:文件夹Day19下创建一个files文件夹用于存储爬取到的Cookie对应的值
一、selenium获取键Cookie对应的值
01_selenium获取cookie
from selenium.webdriver import Chrome# 1. 创建浏览器打开需要自动登录的网页
b = Chrome()
url = 'https://www.zhihu.com'
b.get(url)# 2. 留足够长的时间给人工完成登录
#(完成登录的时候必须保证浏览器对象指向的窗口能够看到登录成功的效果)# 进入网页后会有登录提示,手动扫码登录成功后,回到pycharm的输出区输入任意
# 字符给input,方便我们知道执行到什么地方了
input('已经完成登录:')# 3. 获取浏览器cookie保存到本地文件
cookies = b.get_cookies()
with open('files/zhihu.txt', 'w', encoding='utf-8') as f:f.write(str(cookies))
完成登录的时候必须保证浏览器对象指向的窗口能够看到登录成功的效果是针对如下情况:
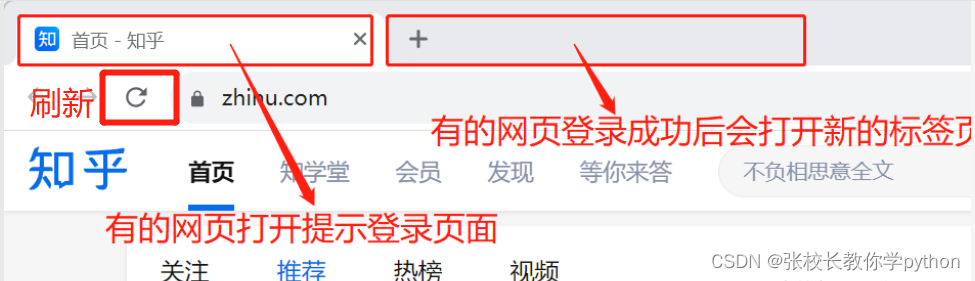
因为第一步创建浏览器是打开网页指向的是第一个标签页,要保证的是如果出现上述情况,我们希望是指向第二个页面,爬虫才能检测到我们已经登录成功了。可以在登录成功页面(第二个页面)刷新一下即可
将获取到的值存储进csv文件中后,我们可以点击files文件查看
二、selenium实现自动登录
02_selenium使用cookie
# 1. 从本地的cookie文件中获取cookie
with open('files/zhihu.txt', encoding='utf-8') as f:cookies = eval(f.read())# 2. 添加cookie
for x in cookies:b.add_cookie(x)# 3.重新打开网页
b.get('https://www.zhihu.com')# 为了不让程序停止,给一个input指令
input()