在本教程中,了解如何构建安全、可扩展、高性能的应用程序,以释放实时数据的全部潜力。
在本教程中,我们将探索 Hazelcast 和 Redpanda 的强大组合,以构建对实时数据做出反应的高性能、可扩展和容错的应用程序。
Redpanda 是一个流数据平台,旨在处理高吞吐量、实时数据流。Redpanda 与 Kafka API 兼容,为 Apache Kafka 提供了高性能且可扩展的替代方案。Redpanda 独特的架构使其能够每秒处理数百万条消息,同时确保低延迟、容错和无缝可扩展性。
Hazelcast 是一个统一的实时流数据平台,通过独特地将流处理和快速数据存储相结合,实现对事件流和传统数据源的低延迟查询、聚合和状态计算,从而对动态数据进行即时操作。它允许您快速构建资源高效的实时应用程序。您可以以任何规模部署它,从小型边缘设备到大型云实例集群。
在这篇文章中,我们将指导您设置和集成这两种技术,以实现实时数据摄取、处理和分析,从而实现强大的流分析。最后,您将深入了解如何利用 Hazelcast 和 Redpanda 的组合功能来释放应用程序的流分析和即时操作的潜力。
那么,让我们开始吧!
Pizza in Motion:披萨外卖服务的解决方案架构
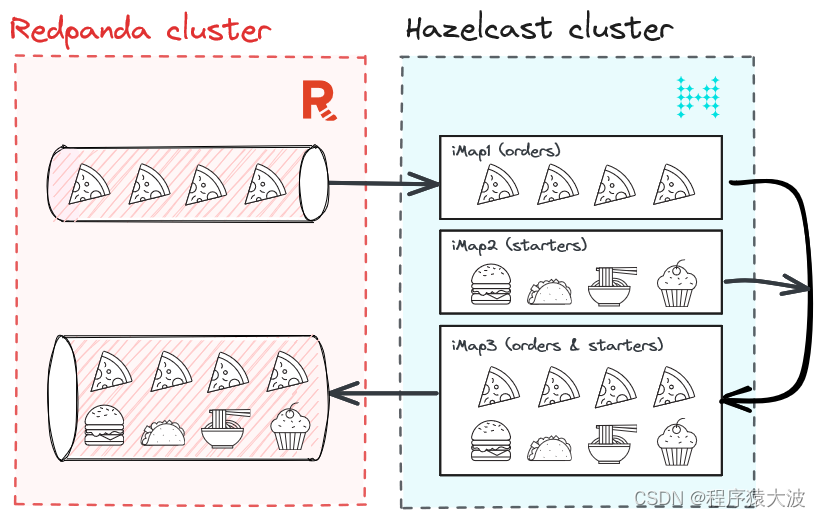
首先,让我们了解我们要构建什么。我们大多数人都喜欢披萨,所以让我们以披萨送货服务为例。我们的披萨外卖服务实时接收来自多个用户的订单。这些订单包含时间戳、user_id、pizza_type 和数量。我们将使用 Python 生成订单,将它们引入 Redpanda,然后使用 Hazelcast 处理它们。
但是,如果您想通过上下文数据丰富披萨订单怎么办?例如,为特定类型的披萨推荐特定的开胃菜。如何实时做到这一点?
实际上有多种选择,但在这篇博文中,我们将向您展示如何使用 Hazelcast 通过存储在 Hazelcast 的 iMap 中的开胃菜丰富来自 Redpanda 的披萨订单。
下面是该解决方案的简要示意图。
教程:使用 Redpanda 和 Hazelcast 进行实时流处理
设置 Redpanda
在本教程的范围内,我们将使用 Docker Compose 设置 Redpanda 集群。因此,请确保本地安装了 Docker Compose。
docker-compose.yml在您选择的位置创建文件并向其中添加以下内容。
version: "3.7"
name: redpanda-quickstart
networks:
redpanda_network:
driver: bridge
volumes:
redpanda-0: null
services:
redpanda-0:
command:
- redpanda
- start
- --kafka-addr internal://0.0.0.0:9092,external://0.0.0.0:19092
# Address the broker advertises to clients that connect to the Kafka API.
# Use the internal addresses to connect to the Redpanda brokers'
# from inside the same Docker network.
# Use the external addresses to connect to the Redpanda brokers'
# from outside the Docker network.
- --advertise-kafka-addr internal://redpanda-0:9092,external://localhost:19092
- --pandaproxy-addr internal://0.0.0.0:8082,external://0.0.0.0:18082
# Address the broker advertises to clients that connect to the HTTP Proxy.
- --advertise-pandaproxy-addr internal://redpanda-0:8082,external://localhost:18082
- --schema-registry-addr internal://0.0.0.0:8081,external://0.0.0.0:18081
# Redpanda brokers use the RPC API to communicate with eachother internally.
- --rpc-addr redpanda-0:33145
- --advertise-rpc-addr redpanda-0:33145
# Tells Seastar (the framework Redpanda uses under the hood) to use 1 core on the system.
- --smp 1
# The amount of memory to make available to Redpanda.
- --memory 1G
# Mode dev-container uses well-known configuration properties for development in containers.
- --mode dev-container
# enable logs for debugging.
- --default-log-level=debug
image: docker.redpanda.com/redpandadata/redpanda:v23.1.11
container_name: redpanda-0
volumes:
- redpanda-0:/var/lib/redpanda/data
networks:
- redpanda_network
ports:
- 18081:18081
- 18082:18082
- 19092:19092
- 19644:9644
console:
container_name: redpanda-console
image: docker.redpanda.com/redpandadata/console:v2.2.4
networks:
- redpanda_network
entrypoint: /bin/sh
command: -c 'echo "$$CONSOLE_CONFIG_FILE" > /tmp/config.yml; /app/console'
environment:
CONFIG_FILEPATH: /tmp/config.yml
CONSOLE_CONFIG_FILE: |
kafka:
brokers: ["redpanda-0:9092"]
schemaRegistry:
enabled: true
urls: ["http://redpanda-0:8081"]
redpanda:
adminApi:
enabled: true
urls: ["http://redpanda-0:9644"]
ports:
- 8080:8080
depends_on:- redpanda-0上面的文件包含使用单个代理启动 Redpanda 集群所需的配置。如果需要,您可以使用三代理集群。但是,对于我们的用例来说,单个经纪人就足够了。
请注意,仅建议在 Docker 上使用 Redpanda 进行开发和测试。对于其他部署选项,请考虑Linux或Kubernetes。
为了生成数据,我们使用 Python 脚本:
import asyncio
import json
import os
import random
from datetime import datetimefrom kafka import KafkaProducer
from kafka.admin import KafkaAdminClient, NewTopicBOOTSTRAP_SERVERS = ("localhost:19092"if os.getenv("RUNTIME_ENVIRONMENT") == "DOCKER"else "localhost:19092"
)PIZZASTREAM_TOPIC = "pizzastream"
PIZZASTREAM_TYPES = ["Margherita","Hawaiian","Veggie","Meat","Pepperoni", "Buffalo","Supreme","Chicken",
]async def generate_pizza(user_id):producer = KafkaProducer(bootstrap_servers=BOOTSTRAP_SERVERS)while True:data = {"timestamp_": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),"pizza": random.choice(PIZZASTREAM_TYPES),"user_id": user_id,"quantity": random.randint(1, 10),}producer.send(PIZZASTREAM_TOPIC,key=user_id.encode("utf-8"),value=json.dumps(data).encode("utf-8"),)print(f"Sent a pizza stream event data to Redpanda: {data}")await asyncio.sleep(random.randint(1, 5))async def main():tasks = [generate_pizza(user_id)for user_id in [f"user_{i}" for i in range(10)]]await asyncio.gather(*tasks)if __name__ == "__main__":# Create kafka topics if running in Docker.if os.getenv("RUNTIME_ENVIRONMENT") == "DOCKER":admin_client = KafkaAdminClient(bootstrap_servers=BOOTSTRAP_SERVERS, client_id="pizzastream-producer")# Check if topics already exist firstexisting_topics = admin_client.list_topics()for topic in [PIZZASTREAM_TOPIC]:if topic not in existing_topics:admin_client.create_topics([NewTopic(topic, num_partitions=1, replication_factor=1)])asyncio.run(main())设置 Hazelcast
启动 Hazelcast 本地集群。这将以客户端/服务器模式运行 Hazelcast 集群以及在本地网络上运行的管理中心实例。
brew tap hazelcast/hz
brew install hazelcast@5.3.1
hz -V现在我们了解了要构建的内容并设置了先决条件,让我们直接进入解决方案。
步骤1:启动Redpanda集群
让我们通过在终端中运行以下命令来启动Redpanda 集群。确保您位于保存文件的同一位置docker-compose.yml。
docker compose up -d类似于以下内容的输出确认 Redpanda 集群已启动并正在运行。
[+] Running 4/4
⠿ Network redpanda_network Created 0.0s
⠿ Volume "redpanda-quickstart_redpanda-0" Created 0.0s
⠿ Container redpanda-0 Started 0.3s
⠿ Container redpanda-console Started 0.6s第 2 步:运行 Hazelcast
您可以运行以下命令来启动具有一个节点的 Hazelcast 集群。
hz start要将更多成员添加到集群,请打开另一个终端窗口并重新运行启动命令。
第 3 步:在 Hazelcast 上运行 SQL
我们将使用 SQL shell——在集群上运行 SQL 查询的最简单方法。您可以使用SQL查询地图和Kafka主题中的数据。结果可以直接发送到客户端或插入到地图或 Kafka 主题中。您还可以使用 Kafka Connector,它允许您在 Hazelcast 集群和 Kafka 之间流式传输、过滤和转换事件。您可以通过运行以下命令来执行此操作:
bin/hz-cli sql第 4 步:摄取 Hazelcast iMap (pizzastream)
使用 SQL 命令,我们创建pizzastreamMap:
CREATE OR REPLACE MAPPING pizzastream(
timestamp_ TIMESTAMP,
pizza VARCHAR,
user_id VARCHAR,
quantity DOUBLE
)
TYPE Kafka
OPTIONS (
'keyFormat' = 'varchar',
'valueFormat' = 'json-flat',
'auto.offset.reset' = 'earliest',
'bootstrap.servers' = 'localhost:19092');步骤 5:用推荐数据丰富流(推荐器)
对于这一步,我们创建另一个地图:
CREATE or REPLACE MAPPING recommender (
__key BIGINT,
user_id VARCHAR,
extra1 VARCHAR,
extra2 VARCHAR,
extra3 VARCHAR )
TYPE IMap
OPTIONS (
'keyFormat'='bigint',
'valueFormat'='json-flat');我们在 Map 中添加一些值:
INSERT INTO recommender VALUES
(1, 'user_1', 'Soup','Onion_rings','Coleslaw'),
(2, 'user_2', 'Salad', 'Coleslaw', 'Soup'),
(3, 'user_3', 'Zucchini_fries','Salad', 'Coleslaw'),
(4, 'user_4', 'Onion_rings','Soup', 'Jalapeno_poppers'),
(5, 'user_5', 'Zucchini_fries', 'Salad', 'Coleslaw'),
(6, 'user_6', 'Soup', 'Zucchini_fries', 'Coleslaw'),
(7, 'user_7', 'Onion_rings', 'Soup', 'Jalapeno_poppers'),
(8, 'user_8', 'Jalapeno_poppers', 'Coleslaw', 'Zucchini_fries'),
(9, 'user_9', 'Onion_rings','Jalapeno_poppers','Soup');第 6 步:使用 SQL 合并两个映射
基于上面两个Map,我们发送以下SQL查询:
SELECTpizzastream.user_id AS user_id,recommender.extra1 as extra1,recommender.extra2 as extra2,recommender.extra3 as extra3,pizzastream.pizza AS pizza
FROM pizzastream
JOIN recommender
ON recommender.user_id = recommender.user_id
AND recommender.extra2 = 'Soup';第7步:将组合数据流发送到Redpanda
为了将结果发送回 Redpanda,我们在 Hazelcast 中创建一个 Jet 作业,将 SQL 查询结果存储到一个新的 Map 中,然后存储到 Redpanda 中:
CREATE OR REPLACE MAPPING recommender_pizzastream(
timestamp_ TIMESTAMP,
user_id VARCHAR,
extra1 VARCHAR,
extra2 VARCHAR,
extra3 VARCHAR,
pizza VARCHAR
)
TYPE Kafka
OPTIONS (
'keyFormat' = 'int',
'valueFormat' = 'json-flat',
'auto.offset.rest' = 'earliest',
'bootstrap.servers' = 'localhost:19092'
);CREATE JOB recommender_job AS SINK INTO recommender_pizzastream SELECTpizzastream.timestamp_ as timestamp_,pizzastream.user_id AS user_id,recommender.extra1 as extra1,recommender.extra2 as extra2,recommender.extra3 as extra3,pizzastream.pizza AS pizza
FROM pizzastream
JOIN recommender
ON recommender.user_id = recommender.user_id
AND recommender.extra2 = 'Soup';结论
在这篇文章中,我们解释了如何使用 Redpanda 和 Hazelcast 构建披萨外卖服务。
Redpanda 通过将披萨订单作为高吞吐量流摄取、可靠地存储它们并允许 Hazelcast 以可扩展的方式使用它们来增加价值。一旦食用,Hazelcast 就会利用上下文数据丰富披萨订单(立即向用户推荐开胃菜),并将丰富的数据发送回 Redpanda。
Hazelcast 允许您快速构建资源高效的实时应用程序。您可以以任何规模部署它,从小型边缘设备到大型云实例集群。Hazelcast 节点集群共享数据存储和计算负载,可以动态扩展和缩减。