如何使用Spark/Flink等分布式计算引擎做网络入侵检测
- 引言
- 16 Distributed Abnormal Behavior Detection Approach Based on Deep Belief Network and Ensemble SVM Using Spark
- 17 Spark configurations to optimize decision tree classification on UNSW-NB15
- 18 A dynamic spark-based classification framework for imbalanced big data
- 19 A review of big data in network intrusion detection system: Challenges, approaches, datasets, and tools
- 20 A feature selection method for intrusion detection based on parallel sparrow search algorithm
- 21 Features dimensionality reduction approaches for machine learning based network intrusion detection
- 22 A comparison of two hybrid ensemble techniques for network anomaly detection in TEspark distributed environment
- 23 Real-time network intrusion detection system based on deep learning
- 24 Online Internet Traffic Monitoring and DDoS Attack Detection Using Big Data Frameworks
- 25 Machine Learning Solutions for Investigating Streams Data using Distributed Frameworks: Literature Review
- 26 A comprehensive survey of anomaly detection techniques for high dimensional big data
- 27 Multi-job Merging Framework and Scheduling Optimization for Apache Flink
- 28 Machine learning based network intrusion detection for data streaming IoT applications
- 29 Multiple submodels parallel support vector machine on spark
- 30 Apache Flink 概要
- 31 Research on Parallel SVM Algorithm Based on Cascade SVM
⚠申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址。 全文共计3077字,阅读大概需要3分钟
🌈更多学习内容, 欢迎👏关注👀【文末】我的个人微信公众号:不懂开发的程序猿
个人网站:https://jerry-jy.co/
引言
本篇博客是我在做基于Spark/Flink大数据环境下网络入侵检测的小论文过程中,阅读的一些参考文献,并把我认为对我有用的地方记录下来,希望也能打开你的研究思路
16 Distributed Abnormal Behavior Detection Approach Based on Deep Belief Network and Ensemble SVM Using Spark
N. Marir, H. Wang, G. Feng, B. Li and M. Jia, “Distributed Abnormal Behavior Detection Approach Based on Deep Belief Network and Ensemble SVM Using Spark,” in IEEE Access, vol. 6, pp. 59657-59671, 2018, doi: 10.1109/ACCESS.2018.2875045.
选择支持向量机作为多层集成学习的基分类器。与其他机器学习算法相比,它具有良好的泛化性能。特别是,SVM可以解决网络入侵检测系统中的二元分类问题。然而,SVM 对于高维网络流量数据来说是一种高成本且耗时的模型,并且对于不平衡数据中的少数类别表现不佳。
17 Spark configurations to optimize decision tree classification on UNSW-NB15
Bagui, Sikha, et al. “Spark configurations to optimize decision tree classification on UNSW-NB15.” Big data and cognitive computing 6.2 (2022): 38.
本文研究了使用大型数据集(UNSW-NB15 数据集)更改 Spark 配置参数对机器学习算法的影响。研究了优化分类过程的环境条件。要构建智能入侵检测系统,需要深入了解环境参数。具体来说,重点关注以下环境参数:执行器内存、执行器数量、每个执行器的核心数量、执行时间以及对统计指标的影响。因此,目标是使用 Spark 优化资源使用并最大限度地减少决策树分类的处理时间。这表明额外的资源是否会提高性能、缩短处理时间并优化计算资源。UNSW-NB15 数据集是一个大型数据集,提供足够的数据和复杂度来查看Spark中计算资源配置的变化。主成分分析用于预处理数据集。结果表明,缺乏执行器和核心会导致资源浪费和处理时间过长。过多的资源分配并没有改善处理时间。环境调整有显着的影响
图 3展示了本工作中使用的总体方法的流程图。虽然每次都做PCA乍一看有些多余,但由于使用了SparkUI,所以每次都必须完全离开Spark环境。因此,每次都必须重新进行PCA
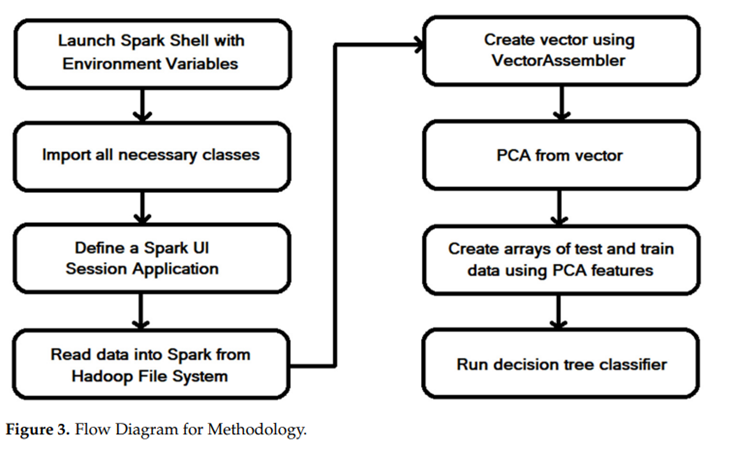
总体结论是,随着声明的执行程序内存增加,执行时间减少,但核心数量保持不变。最后,Spark并行环境上的决策树算法在分类时间、准确率和误报率方面表现更好。
本文提出了一种基于机器学习算法、基于特征重要性的特征选择方法和Spark框架相结合的分布式攻击检测系统,该系统选择了最优的特征子集,保证了更高的准确率。提议的方法将在新南威尔士大学-NB 15数据集上进行测试和评价。
我们的工作的主要贡献可归纳如下:
- 将网络数据集的维数降到最小,同时保证了较好的入侵检测精度。
- 克服了现有解决方案的不足,如不支持海量数据,限制了Apache SPark的可选性(很少选择),同时也保证了现有大多数ID由于不分布式而缺乏的高可用性。
- 与现有工程相比,我们提出的方法更有效、更合适。
为此目的,本文组织如下。在第二节中,我们介绍了有关ML、FS和ApacheSPark在IDS中的应用的相关工作。在第三节中,在描述了所选择的数据集(UNSW-NB 15)后,我们介绍了所提出的方法,并对该方法的每一步进行了描述。最后,我们总结了我们的工作,并在第五节中描述了今后的工作。
18 A dynamic spark-based classification framework for imbalanced big data
Abdel-Hamid, Nahla B., et al. “A dynamic spark-based classification framework for imbalanced big data.” Journal of Grid Computing 16 (2018): 607-626.
Synthetic Minority Over-Sampling TEchnique (SMOTE)
在过去的十年中,不平衡大数据的分类引起了许多研究人员的广泛考虑。标准分类方法对少数类样本的诊断效果不佳。人们提出了几种方法来解决大数据中的类不平衡问题,以增强分类的泛化能力。然而,这些方法大多忽略了边界样本对分类性能的影响;高影响边界样本可能会出现错误分类。本文提出了一种基于 Spark 的挖掘框架(SBMF)来解决数据不平衡问题。为此目的设计了两个主要模块。第一个是边界处理模块 (BHM),它对低影响的多数边界实例进行欠采样,并对少数类实例进行过采样。第二个模块是选择性边界实例采样(SBI)模块,它增强了 BHM 模块的输出。对 SBMF 框架的性能进行了评估,并与其他最新系统进行了比较。使用具有不同不平衡比的中等和大数据集进行了许多实验。与最近的工作相比,从 SBMF 框架获得的结果显示了不同数据集和分类器的更好性能。
为了缓解班级不平衡的问题,人们做了很多尝试。合成抽样技术SMOTE [4]是为解决不平衡数据集的分类问题而发展起来的一种过采样方法,它通过创建合成的少数类样本来处理。Smote通过综合少数民族类的新的样本,[5]提出了改进SMOTET性能的边界-平滑算法,比较了多数类的实例数和边界实例的相邻少数类的数目,然后对少数民族类的边界样本进行了过采样处理,即在适当的区域内进行插值,证明了边界平滑比平滑更好。随着大型数据的出现,对类不平衡提出了不同的挑战。本文提出了一种基于火花的挖掘框架(SBMF)来解决不平衡的大数据问题。SMACK[6]是一个对大数据进行分布式操作的快速集群计算平台,它加快了数据分析的过程。
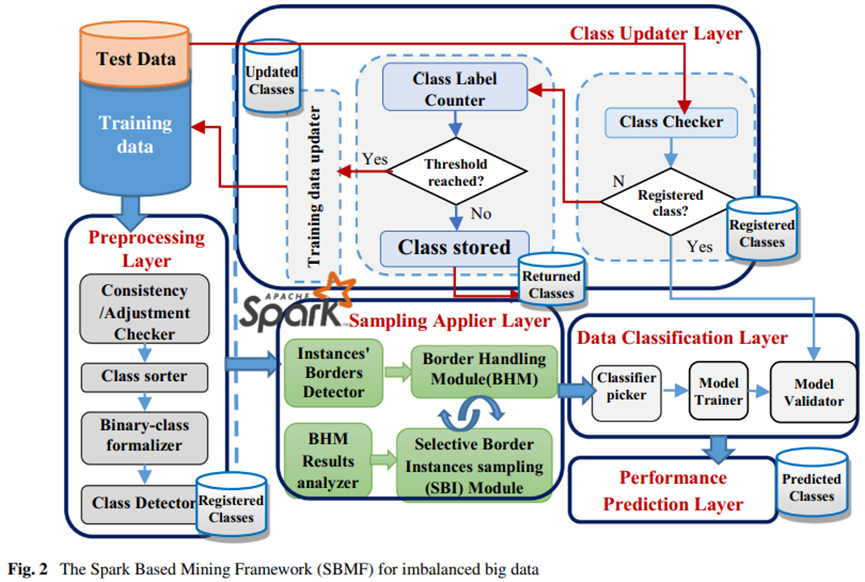
在本节中,我们提出了一种基于Spark的MiningFramework SBMF,它充分利用了大数据集的全部特性,而无需牺牲常规顺序处理方法中使用的部分数据,从而释放了SPark的计算能力。SPark提供的分布式计算优势允许充分利用所有数据集中隐藏的信息,从而有助于提高分类性能。如图2所示,所提议的SBMF框架由以下五个主要层组成:
预处理层处理原始数据集中可能出现的噪声或缺失数据,通过一致性检查模块检查数据一致性,检测和统计每个类中的实例数。另外,将多类数据集转换为二进制类,确定数据集的不平衡比率,并将类存储在寄存器类存储库中。
采样应用程序层检测边界上的实例并识别它们的类,这一层将在下一节中详细讨论。
数据分类层:设置期望分类器,对模型进行训练和建模,SBMF可以对大、小、不平衡的数据集进行采样和分类。SBMF利用辅助选择器模块从支持向量机(SVM)、朴素贝叶斯(NB)、判别分析(DA)和随机森林(RF)四种不同的分类器中进行选择。在选择分类器后,在这一层对模型进行训练和验证。
性能预测层:进行数据分类并对预测结果进行评价。在这一层中,通过创建一个混淆矩阵来评估分类器的性能,该矩阵的行显示实际类的实例数,而olumns则显示预测类的实例数。在此基础上,计算了接收机工作特性曲线(AUC)、G-均值和f-测度下的面积,并对其进行了评价.预测的类也被存储。

19 A review of big data in network intrusion detection system: Challenges, approaches, datasets, and tools
Alshamy, Reem, and Mossa Ghurab. “A review of big data in network intrusion detection system: Challenges, approaches, datasets, and tools.” Journal of Computer Sciences and Engineering 8.7 (2020): 62-74.
⼊侵检测是指披露试图损害资源的机密性、完整性或可⽤性的⾏为[4]。⼊侵检测系统(IDS)是⽹络安全最基本的考虑因素,可以在攻击之前和/或之后检测⼊侵。第⼀个使⽤ IDS 术语的是 20 世纪 70 年代末和 80 年代初的 James Anderson[5]。 IDS可以定义为⼀种⼊侵检测过程,旨在发现计算机⽹络中违反安全策略的事件,它通常位于⽹络内部以监视所有内部流量[6]。
20 A feature selection method for intrusion detection based on parallel sparrow search algorithm
Chen, Hongwei, Xin Ma, and Song Huang. “A feature selection method for intrusion detection based on parallel sparrow search algorithm.” 2021 16th International Conference on Computer Science & Education (ICCSE). IEEE, 2021.
21 Features dimensionality reduction approaches for machine learning based network intrusion detection
Abdulhammed, Razan, et al. “Features dimensionality reduction approaches for machine learning based network intrusion detection.” Electronics 8.3 (2019): 322.


22 A comparison of two hybrid ensemble techniques for network anomaly detection in TEspark distributed environment
Kaur, Gagandeep. “A comparison of two hybrid ensemble techniques for network anomaly detection in TEspark distributed environment.” Journal of Information Security and Applications 55 (2020): 102601.
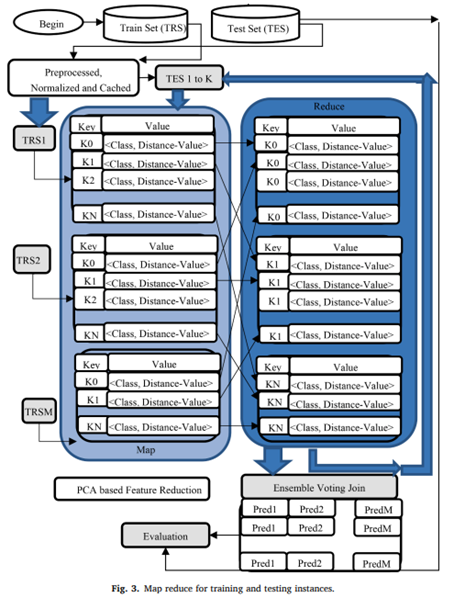
23 Real-time network intrusion detection system based on deep learning
Dong, Yuansheng, Rong Wang, and Juan He. “Real-time network intrusion detection system based on deep learning.” 2019 IEEE 10th International Conference on Software Engineering and Service Science (ICSESS). IEEE, 2019.
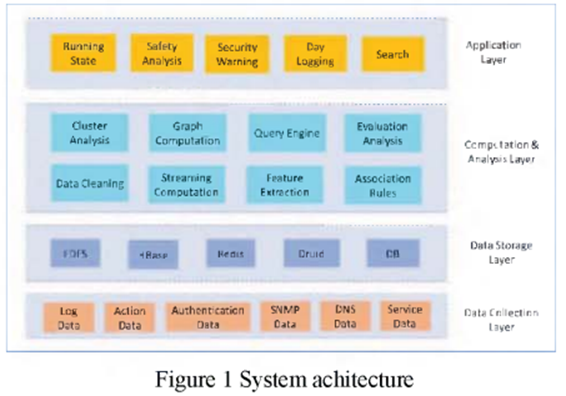
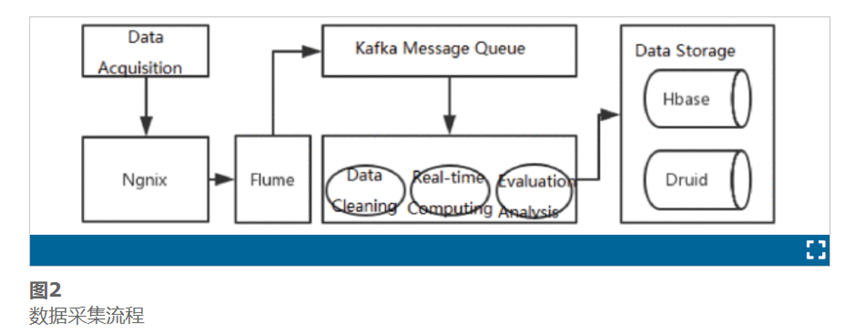
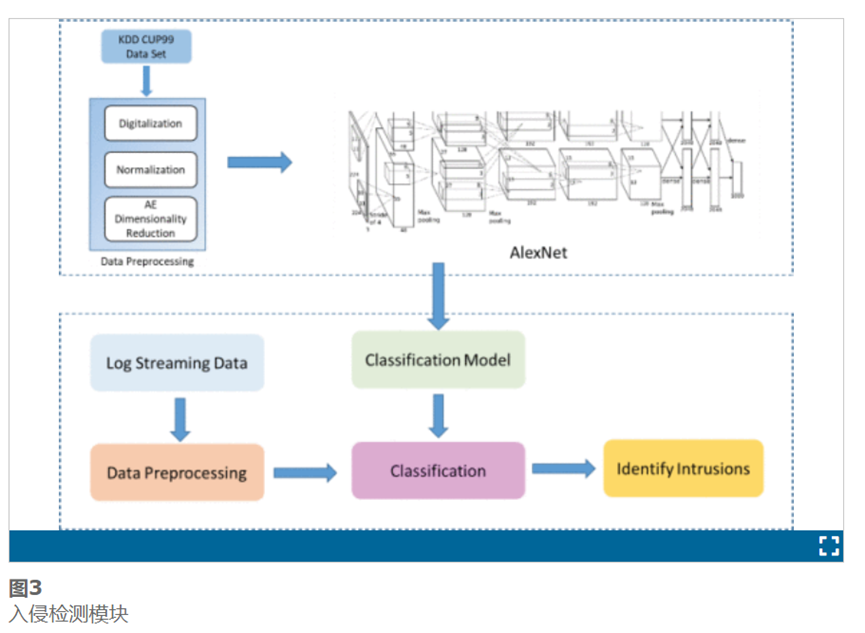
24 Online Internet Traffic Monitoring and DDoS Attack Detection Using Big Data Frameworks
B. Zhou, J. Li, Y. Ji and M. Guizani, “Online Internet Traffic Monitoring and DDoS Attack Detection Using Big Data Frameworks,” 2018 14th International Wireless Communications & Mobile Computing Conference (IWCMC), Limassol, Cyprus, 2018, pp. 1507-1512, doi: 10.1109/IWCMC.2018.8450335.
随着互联网流量的增长,传统的单机网络分析方法已经不再适用。现有方法利用大数据框架来提高处理效率。然而,这些方法主要集中于离线数据分析。在本文中,我们提出了一种利用 Spark Streaming 和 Flink 的在线互联网流量监控框架。具体来说,我们基于我们的系统实现了两个典型的用例,即TCP性能监控和DDoS攻击检测。我们证明了互联网测量和监控可以被视为流分析问题,并且可以通过流处理平台进行处理。
大量的实验结果表明,当输入流速率较低时,Flink 的处理速度比 Spark Streaming 更快,但吞吐量也较低。我们可以通过增加批量大小来增加 Spark Streaming 的最大吞吐量。
本文提出了流处理入侵检测解决方案概念的一种新方法,该解决方案允许集成各种组件。它是我们先前工作[15]的扩展。解决方案能够在Kafka主题中创建流,并实现许多机器学习算法中的一种,提供适当的警报或视图/可视化,然后将结果传输到数据库中。使用基于NetFlow的特性具有许多优点,例如减少执行网络入侵检测所需的处理负载。NetFlow还提供了比深度包检查更大的隐私。NetFlow还提供网络数据包的全面覆盖。
25 Machine Learning Solutions for Investigating Streams Data using Distributed Frameworks: Literature Review
Kumar, Kunal, Neeraj Anand Sharma, and ABM Shawkat Ali. “Machine Learning Solutions for Investigating Streams Data using Distributed Frameworks: Literature Review.” 2021 IEEE Asia-Pacific Conference on Computer Science and Data Engineering (CSDE). IEEE, 2021.
流数据是一个术语,指的是视频、文本、图像等各种来源的实时数据源。近年来,由于对主动预测和缓解医疗状况、网络攻击、交通拥堵、道路事故等基本问题的需求不断增长,流数据获得了很大的吸引力。流数据使用机器学习和统计方法提供实时数据分析,以识别和缓解时间敏感且关键的问题。流数据使系统能够分析传入的数据并立即做出关键预测。流数据通常是实时摄取的,但会小批量处理,足以训练机器学习模型。
Apache Spark 是处理大数据最流行的分布式框架之一。它由加州大学伯克利分校的 AMPLab 于 2009 年创建,并作为开源 Apache 项目部署。Apache Spark,通常称为 Spark。这是 Hadoop MapReduce 框架的巨大发展,处理速度大幅提高。在内存中执行时,Spark 处理数据的速度比 MapReduce 快一百倍,在磁盘上执行时则快十倍。Spark 的主要优点是能够执行内存计算,从而大大减少数据查找时间。它还将数据转换为弹性分布式数据集(RDD)它抽象了要并行处理的数据集。Spark 还采用有向无环图来确保高效的数据处理。Spark 最初构建在 Yarn 之上,作为更快地执行 MapReduce 作业的工具。然而,Spark 并不限于 Hadoop 和 Yarn,因为它可以作为独立应用程序部署,并可以与其他资源管理器(例如 Mesos)结合使用。Spark 拥有一个包含 Spark 引擎、Spark Streaming、机器学习库和用于可视化的 GraphX 的生态系统。
26 A comprehensive survey of anomaly detection techniques for high dimensional big data
Thudumu, Srikanth, et al. “A comprehensive survey of anomaly detection techniques for high dimensional big data.” Journal of Big Data 7 (2020): 1-30.
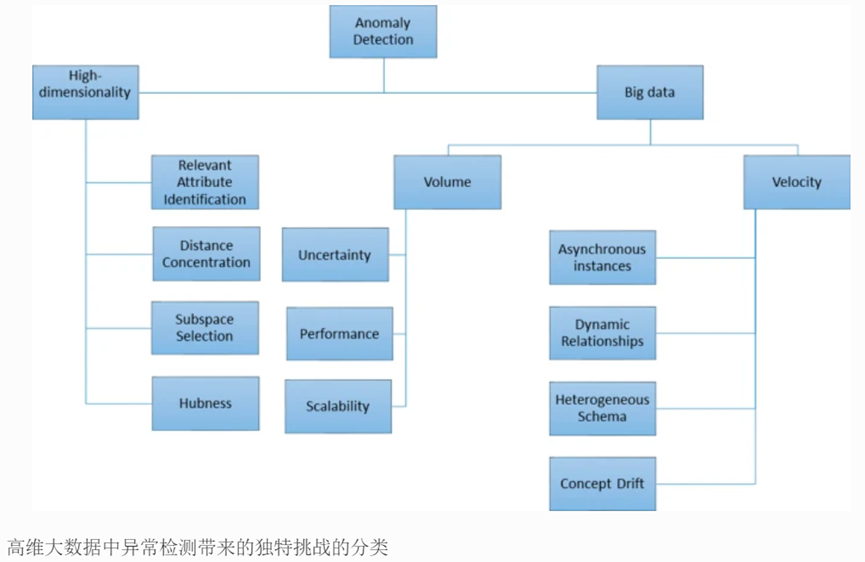
检测高维空间中的异常的传统技术很复杂,因为异常很少见,并且通常出现在维度子集或子空间的分数视图中[27 ]。Aggarwal 也建议了这一点 [ 28] 几乎所有基于邻近概念的异常检测算法在高维空间中都会出现质量下降;因此,重新定义算法是必要的。此外,随着维度的增加,传统方法变得越来越没有意义,因为它们使用的策略对数据相对较低的维度做出某些假设[ 29 ]。此外,对于高维数据集来说,可能只有一小部分数据点提供信息[ 28 ]。
解决高维问题的异常检测可以应用于在线或离线模式。在离线模式下,在历史数据集中检测异常,称为“批处理”。这与大数据的“体量”特征有关。相比之下,在在线模式下,在检测异常情况时不断引入新的数据点(称为“数据流”)。这与大数据的“速度”特性有关。许多现有的调查和评论强调了机器学习和数据挖掘等各个领域的高维问题。
高维是指可用于分析的数据中具有大量自变量、组件、特征或属性的数据集[ 41 ]。数据分析的复杂性随着维度数量的增加而增加,需要更复杂的方法来处理数据。数据集的样本大小n不断增长,但维度m不断增长。同时,在大数据时代,m通常被误解为高维,因为数千维是很常见的。如果一个数据集有n个样本和m个维度(或特征),那么该数据可以称为m-维度。一般来说,当维数为m导致“维数灾难”效应时,数据集可以称为高维数据集
“维数灾难”一词首先由贝尔曼[ 58 ]引入,用于描述因维数或输入变量数量增加而引起的问题。当数据维数增加时,数据规模也成比例增加,导致数据稀疏,稀疏数据难以分析。维度的诅咒会影响异常检测技术,因为相对于维度增加的异常性质的水平可能会被不必要的属性所掩盖甚至隐藏[ 27 ]。由于异常值被定义为稀疏区域中的数据实例,因此在高维空间的几乎同样稀疏的位置中观察到了不充分的判别区域[ 28 ]。
维度的增加使得数据点分散和孤立,并且难以找到数据集的全局最优值。添加到数据集中的维度越多,它就会变得越复杂,因为每个添加的维度都会带来大量的误报[ 42 ]。图 3说明了一维、二维和三维投影时数据的稀疏性。维数灾难是指在高维空间中分析和组织数据时出现的许多情况。这些现象的本质是,每当维度增加时,空间体积就会成比例增加,从而导致所有其他数据点变得稀疏。这种稀疏性对于任何需要统计值的技术来说都是一个挑战。此外,它还会产生与其他噪声水平相关的许多复杂情况,这些噪声水平可能是不相关的特征或不必要的属性,这可能会使数据实例复杂化甚至隐藏[ 29]]。这是许多算法难以处理高维数据的主要原因。随着维数的增加,诸如距离测量之类的统计方法变得不太有用,因为由于维数灾难,点彼此之间几乎等距。
高维数据需要大量的计算内存并带来巨大的计算负担。对于高维数据,识别有用的见解或模式变得复杂且具有挑战性。处理高维问题的最简单方法是最小化特征,并且可以通过研究数据集的内在维数或嵌入维数来更好地理解特征。理解内在维度和嵌入维度之间的细微差别至关重要。内在维度是覆盖数据完整表示的最小特征种类;嵌入维数是整个数据空间的特征或列的数量的表示。
随着世界变得越来越数据驱动,并且没有通用的大数据异常检测方法,高维问题在许多应用领域是不可避免的。此外,随着数据量的增加,准确性的损失更大,计算也更复杂。识别具有高维问题的大型数据集中的异常数据点是一项研究挑战。本次调查全面概述了与数据量和速度等大数据特征相关的异常检测技术,并具有:研究了解决高维问题的策略。显然,需要进一步研究和评估解决高维问题的大数据异常检测策略。为了解决这个研究问题,我们提出了构建一个新颖的框架的未来研究方向,该框架能够在具有高维问题的大量数据中识别异常数据点。主要贡献将是改善高维问题大数据异常检测的性能和准确性之间的平衡。
27 Multi-job Merging Framework and Scheduling Optimization for Apache Flink
Ji, Hangxu, et al. “Multi-job Merging Framework and Scheduling Optimization for Apache Flink.” Database Systems for Advanced Applications: 26th International Conference, DASFAA 2021, Taipei, Taiwan, April 11–14, 2021, Proceedings, Part I 26. Springer International Publishing, 2021.
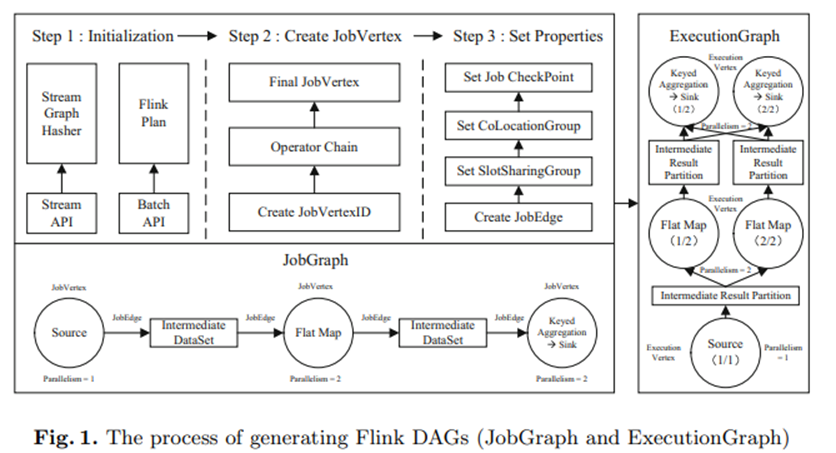
随着大数据技术的普及,分布式计算系统不断发展和成熟,为海量数据的查询和分析做出了实质性的贡献。然而,系统资源利用率不足是分布式计算引擎固有的问题。特别是,当更多作业导致执行阻塞时,即使集群中还有许多剩余资源,系统也会按照先来先执行(FCFE)的原则调度多个作业。因此,资源利用的优化是提高多作业执行效率的关键。我们研究了多作业执行优化领域,设计了多作业合并框架和调度优化算法,并在最新一代分布式计算系统 Apache Flink 中实现。综上所述,我们工作的优点突出如下:(1)该框架使Flink能够支持多作业收集、合并和执行顺序的动态调整,并且这些功能的选择是可定制的。(2)通过多作业合并和优化,总运行时间比传统顺序执行可减少31%。(3)多作业调度优化算法可带来28%的性能提升,平均情况下可减少集群闲置资源61%。与传统顺序执行相比,总运行时间可减少31%。(3)多作业调度优化算法可带来28%的性能提升,平均情况下可减少集群闲置资源61%。与传统顺序执行相比,总运行时间可减少31%。(3)多作业调度优化算法可带来28%的性能提升,平均情况下可减少集群闲置资源61%。
Apache Flink [ 2 ]是最新一代的分布式计算系统,在处理海量数据时表现出高吞吐量和低延迟。它可以缓存中间数据并使用自己的优化器支持增量迭代。由于Flink的众多优势,许多基于Flink的实验研究、优化技术和应用平台不断涌现。例如,在Flink诞生初期,大部分研究都集中在Flink和Spark的比较[10,11,15 ] ,并指出Flink更适合未来的数据计算。随着Flink的流行,最近的研究包括基于Flink的测试工具[ 9 ]、多查询优化技术[16 ]、推荐系统[ 5 ]等。
然而,大多数分布式计算系统都存在硬件资源利用率不足的问题。虽然 Flink 通过引入 TaskSlot 隔离内存来最大化资源利用率,但由于传统顺序执行时部分 Operator 并行度较低,因此也存在空闲资源。此外,当用户提交多个作业时,Flink 仅以先到先执行(FCFE)的方式运行它们,这无法使作业共享 Slots。更糟糕的情况是,如果作业A正在执行,之后的作业B因剩余资源不足而不满足执行条件,那么即使作业B之后的作业C满足执行条件,作业C也无法提前执行,造成严重的后果。资源浪费。这些运行多个作业的 FCFE 策略只能确保作业级别的公平性,但不是用户想要的。在大多数情况下,用户只需要所有作业的最小总执行时间。通过同时执行多个作业,动态调整作业执行顺序,使满足执行条件的作业提前执行,可以解决上述问题。
在本次研究中,我们回顾了由于Flink不支持多个作业同时执行以及执行顺序优化而导致的系统资源利用不足的问题,然后重点研究了增加Slot占用所带来的多作业效率提升速度。其基本思想是通过多作业合并实现同时执行,并通过多作业调度动态调整执行顺序,本文的贡献总结如下。
(1)
我们提出了一个突破性的框架,可以支持 Flink 中的多作业合并和调度。它可以收集并解析多个待执行的作业,并通过多作业合并和调度两种优化方法生成新的作业执行计划,并提交给 Flink 执行。
(2)
为了同时执行多个作业,我们提出了基于子图同构和启发式策略的多作业合并算法,以使多个作业能够共享槽。两种算法在实验过程中都能提高效率并适应不同的工作场景。
(3)
为了动态调整作业执行顺序,我们提出了基于最大并行度的多作业调度算法,使满足剩余资源的作业提前执行。实验结果表明,该算法能够提高效率并减少空闲资源。
28 Machine learning based network intrusion detection for data streaming IoT applications
Yahyaoui, Aymen, et al. “Machine learning based network intrusion detection for data streaming IoT applications.” 2021 21st ACIS International Winter Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD-Winter). IEEE, 2021.
在本文中,我们为物联网流应用程序设计了一种入侵检测系统架构。该系统基于我们使用机器学习技术开发的检测组件。我们将我们的系统的部署与大数据领域两个领先的流处理框架(Apache Flink 和 Apache Spark Streaming)进行测试和比较。前者带来了相当大的吞吐量(每秒处理超过 196,000 个数据包)。此外,我们获得了很高的检测精度(超过99.9%)。我们这项工作主要关注异常网络入侵。然而,我们的解决方案可以处理其他类型的异常。我们使用两个不同的数据集比较不同机器学习算法的性能。此外,我们还将我们的结果与最近的研究工作进行比较。结果证明了我们系统的效率。
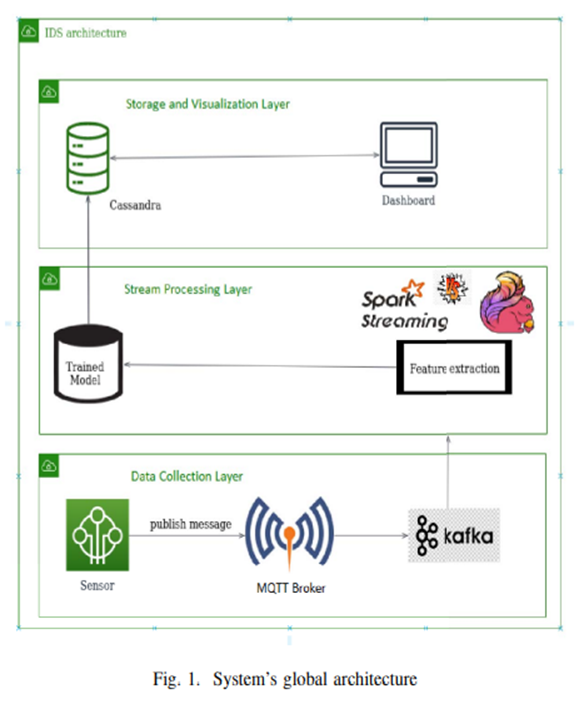
该系统的主要目的是实时分析来自物联网节点的传入流量,并在大数据环境中高精度检测异常情况(在我们的例子中为入侵)。考虑到这一目标,我们设计了如图1所示的三层架构IDS,由数据采集层、流处理层以及存储和可视化层组成。
首先,数据包被发布到 MQTT 代理。MQTT 协议并不是为高可扩展性而设计的,这就是为什么我们使用其插件 Kafka connect 将其与 Kafka 消息传递框架配对的原因。其次,捕获的流量被发送到流处理框架,该框架将提取特征并使用已经训练的 ML 模型对接收到的流量的性质进行预测。然后,流处理引擎将结果发送到数据库,网络活动的统计数据可以在仪表板上可视化。
流处理层以数据流的形式接收来自Kafka集群的数据并进行实时分析。大多数繁重的处理都是在这一层完成的:特征提取、数据训练、模型生成以及更新和预测。因此,一旦数据分析速度更快,该层就负责最大限度地减少延迟。有不同的流处理框架。最著名的是 Apache Flink、Apache Spark Streaming、Apache Storm、Apache Heron、Akka 和 Samza [15]。在这项工作中,我们考虑比较两个领先的框架:Apache Flink 和 Apache Spark Streaming。
对于Flink流处理,我们使用Java编程和Weka 3.6.10来实现机器学习算法。我们在单节点设置环境中使用 Apache Flink 1.10.0,使用 flink-kafka 连接器和 Apache Kafka 2.4.1。对于 Spark Streaming,我们使用 python 编程语言(pyspark)和 MLlib 库来实现机器学习算法。我们在单节点设置环境中使用spark-2.4.4,使用spark-streaming-kafka-0-8- assembly 2.11-2.1.0连接器和Apache Kafka 2.4.1。对于这两种解决方案,均使用 Cassandra 3.11.6.1 和 Grafana 6.7.3 来构建存储和可视化层
在这项工作中,我们设计了一个架构,开发并部署了一个基于机器学习算法的物联网流应用程序的入侵检测系统(IDS)。我们根据不同的特征数量、机器学习算法、机器性能进行了多次测试,并报告了两个指标:准确性和吞吐量。与 Apache Spark Streaming 相比,Apache Flink 流引擎提供了高吞吐量。与两个相关工作系统相比,IDS 被证明是高效的。作为未来的工作,我们的目标是使用其他指标来评估其他流处理引擎。此外,我们还将推广这项工作以检测其他类型的异常,这些异常可能是有趣的事件以及网络攻击。
29 Multiple submodels parallel support vector machine on spark
Liu, Chang, et al. “Multiple submodels parallel support vector machine on spark.” 2016 IEEE International Conference on Big Data (Big Data). IEEE, 2016.
支持向量机(SVM)是一种经典的分类算法,有着广泛的应用。通过核函数,SVM可以处理在原始特征空间中不可线性分离的数据集,使其在实际使用中比线性模型更加灵活。然而,其训练的复杂性是大规模数据集处理的障碍。本文提出了 Spark 上的多子模型并行 SVM(MSM-SvM),以利用计算机集群加速非线性 SVM 的训练。利用SVM的模型理论,引入基于聚类的数据分割方法,以实现并行训练过程并用多个局部子模型逼近全局解。我们还通过“一对一”策略涵盖多分类。实验表明,MSM-SVM不仅在二分类上表现良好,而且在多类分类上也表现良好。在预测二进制情况的准确性方面,它优于 Spark MLlib 中的 SVM With MiniBatch SGD 工具。对于我们几乎所有的实验数据集,MSM-SVM 提供了与 LIBSVM 相似的预测性能,同时花费的时间少得多。
30 Apache Flink 概要
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
1、处理无界和有界数据
Apache Flink 擅长处理无界和有界数据集 精确的时间控制和状态化使得 Flink 的运行时(runtime)能够运行任何处理无界流的应用。有界流则由一些专为固定大小数据集特殊设计的算法和数据结构进行内部处理,产生了出色的性能。数据集是有界流,网络实时处理是无界流,未来展望中
2、部署应用到任意地方
Apache Flink 是一个分布式系统,它需要计算资源来执行应用程序。Flink 集成了所有常见的集群资源管理器,例如 Hadoop YARN、 Apache Mesos 和 Kubernetes,但同时也可以作为独立集群运行。
3、运行任意规模应用
Flink 旨在任意规模上运行有状态流式应用。因此,应用程序被并行化为可能数千个任务,这些任务分布在集群中并发执行。所以应用程序能够充分利用无尽的 CPU、内存、磁盘和网络 IO。而且 Flink 很容易维护非常大的应用程序状态。其异步和增量的检查点算法对处理延迟产生最小的影响,同时保证精确一次状态的一致性。
4、利用内存性能
有状态的 Flink 程序针对本地状态访问进行了优化。任务的状态始终保留在内存中,如果状态大小超过可用内存,则会保存在能高效访问的磁盘数据结构中。任务通过访问本地(通常在内存中)状态来进行所有的计算,从而产生非常低的处理延迟。Flink 通过定期和异步地对本地状态进行持久化存储来保证故障场景下精确一次的状态一致性。
在Flink中,由于处理时间比较简单,早期版本默认的时间语义是处理时间(系统时间);而考虑到事件时间在实际应用中更为广泛,从Flink1.12版本开始,Flink已经将事件时间作为默认的时间语义了。如果按照处理时间,数据到达时可能不是按序到达的,网络传输存在乱序的情况,因此,后面的Flink版本改为按事件时间处理数据
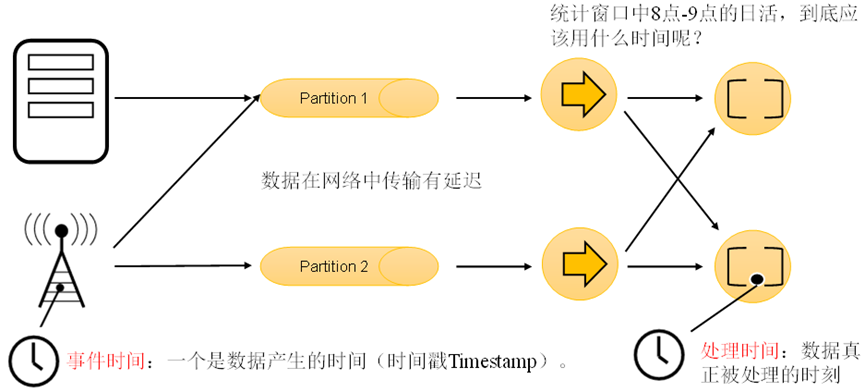
一般的实时流处理场景中,事件时间基本与处理时间同步,只是略微延迟
由于不同的slot在计算资源上是物理隔离的,所以Flink能管理的状态在并行任务间是无法共享的,每个状态只能针对当前子任务的实例有效
Flink需要用户进行初始资源配置,该配置在作业开始后不再改变,除非重启任务
31 Research on Parallel SVM Algorithm Based on Cascade SVM
Cheng, Yi. “Research on Parallel SVM Algorithm Based on Cascade SVM.” arXiv preprint arXiv:2203.05768 (2022).
级联SVM(CSVM)可以并行对数据集进行分组并训练子集,从而大大减少了训练时间和内存消耗。但使用该方法得到的模型精度与直接训练相比存在一定误差。为了减少误差,我们分析分组训练中出现误差的原因,总结出理想条件下无误差的分组。提出一种平衡级联支持向量机(BCSVM)算法,平衡分组后子集中的样本比例,保证子集中的样本比例与原始数据集相同。同时证明BCSVM算法得到的模型精度高于CSVM。最后使用两个常见的数据集进行实验验证,
–end–