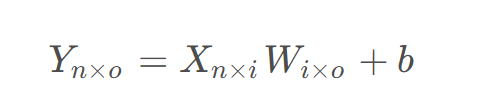大模型基础:GPT 家族与提示学习
从 GPT-1 到 GPT-3.5
GPT(Generative Pre-trained Transformer)是 Google 于2018年提出的一种基于 Transformer 的预训练语言模型。它标志着自然语言处理领域从 RNN 时代进入 Transformer 时代。GPT 的发展历史和技术特点如下:
- GPT-1
2018年6月, Google 在论文 “Improving Language Understanding by Generative Pre-Training” 中首次提出 GPT 模型。GPT-1 使用 12 层 Transformer 解码器堆叠而成,每层包含一个 multi-head self-attention 模块和一个全连接前馈网络。在一个包含网页、书籍等的大规模文本数据集上进行了无监督预训练,根据下游任务进行微调,展示了其在语言理解和生成任务上的强大能力, 是语言模型发展历史上的重要里程碑。GPT-1 的贡献在于证明了 Transformer 结构也可以进行无监督预训练, 并可以捕获语言的长距离依赖特征。GPT-1的提出推动了后续GPT模型系列的发展与革新。

- GPT-2
2019年2月, OpenAI 发布 GPT-2 模型。GPT-2 使用更大规模的数据集,包含40GB文本数据,规模比GPT-1大40倍。GPT-2基于GPT-1进行改进,提出了一种简化的 Transformer 解码器结构。GPT-2 展示了强大的语言生成能力, 可以根据提示文本进行长段落语言生成。GPT-2 继承 GPT-1的设计思路, 通过扩大模型和数据集规模, 优化模型结构, 给出了一个更强大的预训练语言模型, 显示了该方向的发展前景。
- GPT-3
2020年5月,OpenAI 发布GPT-3,引起了广泛关注。GPT-3使用了1750亿参数,是迄今为止最大的语言模型。GPT-3沿用了 Transformer 解码器结构,但进一步扩大了模型宽度和深度, 包含了96层Transformer块, 具有更强的表示能力。训练数据集达到了4000亿字的海量文本数据, 远超之前的GPT模型。这为GPT-3提供了丰富的世界知识。GPT-3在问答、翻译、总结等多项任务上都展现出强大的零样本学习能力,展现出接近人类的语言处理能力。GPT-3的关键创新在于提出了In-Context Learning概念, 可以理解提示并根据上下文进行回答,例如在问答任务中,只需在prompt提供问题及一个QA示例,GPT-3就可以学习回答同类问题,在千亿级参数量级的模型上,In-Context Learning 的能力才初步显现,可以从5-10个示例中获取新任务和概念信息。这种学习方式更贴近人类的学习模式。GPT-3 使语言模型产生了质的飞跃, 具有广泛的应用前景。

| 模型 | 发布时间 | 模型规模 | 层数 | 数据集 | 主要贡献 |
|---|---|---|---|---|---|
| GPT-1 | 2018年6月 | 117M参数 | 12层 | BooksCorpus 数据集(8000本书) | 首个无监督预训练的Transformer语言模型 |
| GPT-2 | 2019年2月 | 1.5B参数 | 48层 | WebText 数据集(450GB文本) | 展示了规模对生成质量的重要性 |
| GPT-3 | 2020年5月 | 175B参数 | 96层 | CommonCrawl 数据集(45TB文本) | 规模再次扩大,上下文学习能力, prompt engineering |
ChatGPT:赢在哪里
ChatGPT 是技术和商业的成功结合。
-
模型训练:虽然GPT-3和ChatGPT都是基于Transformer的语言模型,但在训练数据和目标函数上有所不同。GPT-3主要是用大量的非结构化文本进行训练的,而ChatGPT则在GPT-3的基础上进行了进一步的训练,这包括使用与对话相关的数据集和更适合对话任务的训练目标。
-
对话管理:在对话管理方面进行了优化,以提供更自然、连贯的对话体验。这包括保持对话的上下文、处理多轮对话、以及在一个对话中处理多个话题等。
-
用户输入处理:这包括理解和响应各种类型的查询,如信息查询、任务请求、小说式的输入等。
-
输出生成:生成更贴近人类的输出。这包括使用更复杂的生成策略、生成更长的响应、以及更好地处理模糊或不确定的输入等。
-
安全性和道德规范:还进行了一些改进以提高模型的安全性和符合道德规范。这包括对模型的过滤和调节,以防止生成不适当或有害的内容,以及对模型进行额外的评估和测试,以确保其在各种情况下都能表现良好。
GPT-4:一个新的开始
2022年8月,GPT-4 模型训练完成。2023年3月14日,OpenAI 正式发布 GPT-4。 与GPT-3和GPT-3.5相比,
GPT-4在各方面都有所优化和提升:
-
多模态模型: GPT-4支持图像输入,出色的视觉信息理解能力使得GPT-4能对接更多样化的下游任务,如:描述不寻常图像中的幽默、总结截屏文本以及回答包含图表的试题。在文本理解能力上,GPT-4 在中文和多轮对话中也表现出远超 GPT-3.5 的能力。
-
扩展上下文窗口:gpt-4 and gpt-4-32k 分别提供了最大长度为8192和32768个token的上下文窗口。这使得 GPT-4可以通过更多的上下文来完成更复杂的任务,也为 思维链(CoT)、思维树(ToT)等后续工作提供了可能。
-
GPT+生态 :借助GPT-4强大能力,依托 ChatGPT Plugin 搭建AIGC应用生态商店(类似 App Store)
-
应用+GPT :GPT-4已经被应用在多个领域,包括微软Office、Duolingo、Khan Academy等。

提示学习(Prompt Learning)
-
Prompt learning 是一种使用预训练语言模型的方法,它不会修改模型的权重。在这种方法中,模型被给予一个提示(prompt),这个提示是模型输入的一部分,它指导模型产生特定类型的输出。这个过程不涉及到对模型权重的修改,而是利用了模型在预训练阶段学习到的知识和能力。
-
In-context learning 是指模型在处理一系列输入时,使用前面的输入和输出作为后续输入的上下文。这是Transformer模型(如GPT系列)的一种基本特性。例如,当模型在处理一个对话任务时,它会使用对话中的前几轮内容作为上下文,来生成下一轮的回答。这个过程也不涉及到对模型权重的修改。
总的来说,prompt learning 和 in-context learning都是利用预训练语言模型的方法,它们都不会修改模型的权重。它们的主要区别在于,prompt learning关注的是如何通过设计有效的提示来引导模型的输出,而in-context learning则关注的是如何利用输入序列中的上下文信息来影响模型的输出。
- Prompt tuning,又称为"prompt engineering",是一种优化技术,它涉及到寻找或生成能够最大限度提高模型性能的提示。这可能涉及到使用启发式方法、人工智能搜索算法,或者甚至是人工选择和优化提示。Prompt tuning的目标是找到一种方式,使得当给定这个提示时,模型能够生成最准确、最相关的输出。
思维链(Chain-of-Thought, CoT):开山之作
Chain-of-thought(CoT) prompting 是一种利用自然语言编程的技巧,可以提高ChatGPT在复杂推理问题上的准确率。思维链提示的原理是参考人类解决问题的方法,从输入问题开始的一系列自然语言形式的推理过程,直到得到最后输出结论。思维链就是让语言模型逐步推理,通过依次生成多个中间步骤z1,z2,…,zn(这些中间过程称为thoughts),前面的生成结果会作为后续的模型输入,直到得到最终结果y。
思维链提示的实现方法大致如下:
首先,选择一个适合思维链提示的任务,例如数学、常识或符号推理等,需要多步骤的推理过程。然后,为任务准备一些样例,每个样例包含输入问题、思维链和输出结论。思维链是一系列自然语言形式的推理步骤,从输入问题开始,直到得到输出结论。接着,将样例作为上下文输入给大语言模型,例如GPT-3或PaLM等,让模型学习样例中的推理模式。最后,给模型一个新的输入问题,让模型生成思维链和输出结论。模型会根据样例中的推理模式,生成一系列合理的推理步骤,并给出最终的答案。
这就是思维链提示的基本实现方法。当然,还有一些改进和优化的方法,例如使用多数投票、自洽性检查、自我训练等等。
假设您想让 ChatGPT 回答一个数学问题:
一、如果您直接给出问题,ChatGPT 回答不一定正确,例如:Q: 一个人以每小时5公里的速度骑自行车,骑了1小时后,又以每小时10公里的速度骑了2小时,他一共骑了多少公里?那么ChatGPT可能会直接给出答案,但不一定正确,也不会显示推理过程。二、提供思维链示例,那么ChatGPT可能会按照类似的方式给出答案和推理过程,并且更可能正确。例如:Q: 一个人以每小时5公里的速度骑自行车,骑了1小时后,又以每小时10公里的速度骑了2小时,他一共骑了多少公里?
A: 思维链:
第一段路程 = 速度 x 时间 = 5 x 1 = 5公里
第二段路程 = 速度 x 时间 = 10 x 2 = 20公里
总路程 = 第一段路程 + 第二段路程 = 5 + 20 = 25公里 输出结论:25公里Q: 一个人以每小时10公里的速度骑自行车,骑了半小时后,又以每小时15公里的速度骑了1小时,他一共骑了多少公里?
CoT Prompting 作为一种促进语言模型推理的方法具有几个吸引人的特点:
-
首先,从原则上讲,CoT 允许模型将多步问题分解为中间步骤,这意味着可以将额外计算资源分配给需要更多推理步骤的问题。
-
其次,CoT 提供了对模型行为的可解释窗口,提示了它可能是如何得出特定答案的,并提供了调试推理路径错误之处的机会(尽管完全描述支持答案的模型计算仍然是一个未解决问题)。
-
第三,在数学应用题、常识推理和符号操作等任务中都可以使用思维链推理(CoT Reasoning),并且在原则上适用于任何人类能够通过语言解决的任务。
-
最后,在足够大规模现成语言模型中很容易引发 CoT Reasoning ,只需在少样本提示示例中包含一些连贯思路序列即可。
通过思维链,我们可以看到大语言模型的强与弱:
-
它强在,模型规模的提高,让语义理解、符号映射、连贯文本生成等能力跃升,从而让多步骤推理的思维链成为可能,带来“智能涌现”。
-
它弱在,即使大语言模型表现出了前所未有的能力,但思维链暴露了它,依然是鹦鹉学舌,而非真的产生了意识。
没有思维链,大模型几乎无法实现逻辑推理。但有了思维链,大语言模型也可能出现错误推理,尤其是非常简单的计算错误。Jason Wei 等的论文中,曾展示过在 GSM8K 的一个子集中,大语言模型出现了 8% 的计算错误,比如6 * 13 = 68(正确答案是78)。
自洽性(Self-Consistency): 多路径推理
谷歌研究者提出一种名为「self-consistency」(自洽性)的简单策略,不需要额外的人工注释、训练、辅助模型或微调,可直接用于大规模预训练模型。显著提高了大型语言模型的推理准确率。该研究在三种大型语言模型上评估一系列算术推理和常识推理任务的自洽性,包括 LaMDA-137B、PaLM-540B 和 GPT-3 175B。研究者发现,对于这几种规模不同的语言模型,自洽方法都能显著提高其推理能力。与通过贪心解码(Wei et al., 2022)生成单一思维链相比,自洽方法有助于在所有推理任务中显著提高准确性,如下图 2 所示。

具体步骤如下:
首先,使用一组手动编写的思维链示例对语言模型进行提示;
接着,从语言模型的解码器中采样一组候选输出,生成一组不同的候选推理路径;
最后,通过在生成的答案中选择最自洽的答案来集成结果。
在实验调查中,研究者发现思维链提示与相结合,会比单独使用仅考虑单一生成路径的思维链产生好得多的结果。
思维树(Tree-of-Thoughts, ToT): 续写佳话
Tree of Thoughts(TOT),它允许语言模型在解决问题的中间过程进行探索,通过考虑多种不同推理路径并进行评估,同时具备向前看跟向后回溯的能力以获得更佳决策选择。
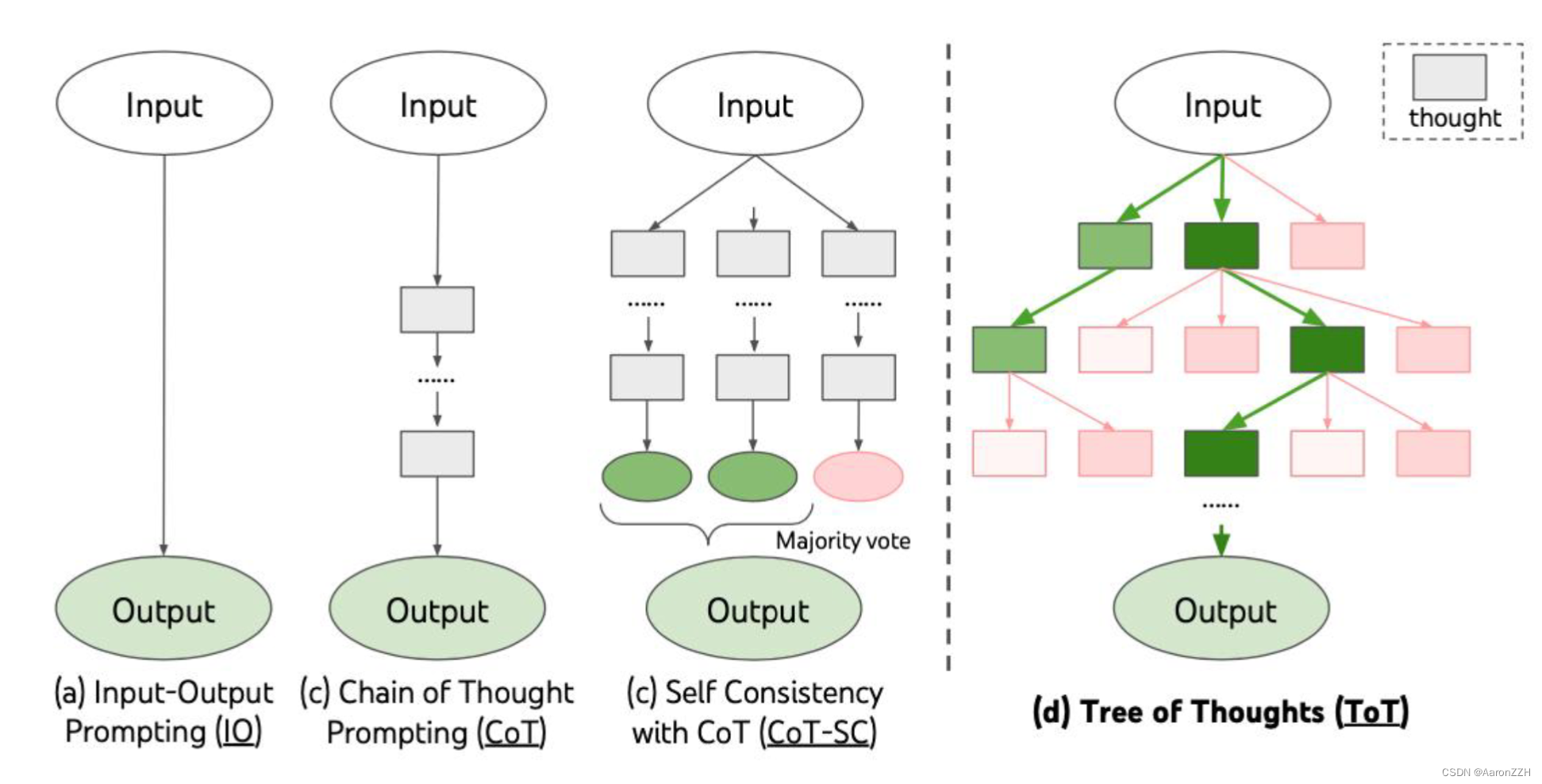
TOT 使语言模型可以去探索多个推理路径。把解决问题视作在一棵树上的搜索,树上的每个节点代表当前的状态s=[x,z1,…,zi],状态包括原始的问题以及到目前为止的思考过程。一个完整的Tree of Thoughts包括以下4个过程:
-
Thought decomposition 思维分解
如何将推理中间过程 分解 成多个想法步骤。不同于CoT会在没有明确分解的情况下连续对thoughts采样,ToT 会根据问题属性去设计和分解中间的想法过程。每个想法应该足够小,使得语言模型可以生成有潜力跟多样的样本(生成一本书就太长了,很难保证连贯性),同时又应该足够大,使得语言模型可以评估该想法解决问题的潜力(只生成一个token就太小,很难去评估对于解决问题的帮助)。
-
Thought generator 思维生成,根据当前状态生成候选想法。
-
State evaluator 状态评估。
让状态评估器评估它们对于解决问题的帮助,以确定哪些状态值得继续探索,以及以何种方式探索。
-
Search algorithm 搜索算法。
Tree of Thought支持插入多种依赖于树的搜索算法,论文中探索了其中两种相对简单的搜索算法。 a) BFS,广度优先算法,每一步中保留最优潜力的K个状态。 b) DFS,深度优先算法,优先探索最优潜力的状态,直到得到最终结果(解决了问题),或者超过当前状态被评估不可能解决问题就停止,如果是后者的话可以退回父节点,继续进行探索。
从概念上讲,ToT 作为LM通用问题求解方法具有几个优势:
(1) 泛化性。IO、CoT、CoT-SC 和自我完善都可以看作是ToT的特殊情况(即有限深度和广度的树;图1)
(2) 模块化。基本LM以及思考分解、生成、评估和搜索过程都可以独立变化。
(3) 适应性。可以适应不同的问题属性、LM能力和资源约束。
(4) 方便性。无需额外训练
ToT 为复杂推理问题提供了一种新的解决方案,虽然用户可以灵活调整其中的模块,但是往往需要更多的资源(例如更多次数的模型调用)才能提升某个任务下的表现。虽然目前这种方式没涉及模型训练,但是利用ToT的相关任务来微调语言模型可以进一步提升语言模型解决问题的能力,例如将模型训练中预测下一个token的任务改成考虑下一个段落的选择。