目录
绪论
1、tomact
1.1 核心组件
1.2 什么是 servlet
1.3 什么是 JSP?
1.4 Tomcat 功能组件结构
1.5 Tomcat 请求过程
2、Tomcat 服务部署
2.1 tomcat自身优化:
2.2 内核优化
2.3 jvm
2.3.1 jvm配置
2.3.2 Tomcat配置JVM参数
2.3.3 jvm优化
3、tomcat虚拟主机配置
4、Tomcat多实例部署
5、nginx+tomcat实现动静分离
6、补充 四层、七层反向代理做动静分离和负载均衡
绪论
Tomcat是一个开源的Web应用服务器,并提供了一个运行Java Web应用程序的容器。就是处理动态请求和基于java代码的页面开发。可以在html当中希尔java代码,tomcat哭解析html页面当中的java代码,可移植性动态请求,包括动态页面
优点:免费,开源可以进行二次开发,可配置性强、可以根据需要自定义配置、包括端口号虚拟主机等等,安全性:tomcat自带安全机制、库配置用户认证、授权以及加密传输,部署应用快捷、tomcat会自动运行
1、tomact
1.1 核心组件
· Web 容器:完成 Web 服务器的功能。
web
tomcat web应用服务
web --可以通过http(s)来访问的一个页面---文件
web容器封装了一组文件, 集中化管理--一组组员的对象
· Servlet 容器:名字为 catalina,用于处理 Servlet 代码。
servlet是用于处理Web请求和生成动态Web内容的Java类s
· JSP 容器:用于将 JSP 动态网页翻译成 Servlet 代码。
只是用于安装定制的规则,格式来显示静态页面
index.php -- php
index.jsp--- tomcat
nginx ---html
1.2 什么是 servlet
Servlet是Java技术中用于开发Web应用程序的关键组件之一。
它主要用于处理HTTP请求、生成动态内容以及与客户端进行交互。以下是Servlet在Web开发中的主要用途:
处理HTTP请求: Servlet充当了Web应用程序的控制器,能够处理来自客户端(如浏览器)的HTTP请求。根据请求的类型(GET、POST等)和参数,Servlet可以执行不同的操作,如读取数据、验证用户输入等。
生成动态内容: Servlet可以生成动态的HTML、XML、JSON等内容,以响应客户端请求。它可以将从数据库、文件或其他数据源中检索的数据嵌入到生成的内容中,从而呈现个性化和实时的页面。
业务逻辑处理: Servlet可以包含与应用程序相关的业务逻辑。它可以执行各种操作,如数据处理、计算、格式化等,以根据客户端请求生成相应的输出。
会话管理: Servlet可以处理用户会话,跟踪用户在不同请求之间的状态。通过会话管理,
Servlet可以在用户访问不同页面时保持用户的状态信息,实现购物车、用户登录等功能。
表单处理: Servlet可以处理通过HTML表单提交的数据。它可以从请求中获取表单数据,执行验证和处理,然后生成适当的响应,如显示错误消息或确认页面。
与数据库交互: Servlet可以连接到数据库,执行查询和更新操作,从而从数据库中检索或存储数据。这使得Servlet能够将动态数据集成到生成的内容中。
1.3 什么是 JSP?
JSP 全称 Java Server Pages,是一种动态网页开发技术。它使用 JSP 标签在HTML网页中插入 Java 代码。
标签通常以 <% 开头,以 %> 结束。
JSP 是一种 Java servlet,主要用于实现 Java web 应用程序的用户界面部分。
JSP 通过网页表单获取用户输入数据、访问数据库及其他数据源,然后动态地创建网页。
1.4 Tomcat 功能组件结构
Tomcat 的核心功能有两个,分别是负责接收和反馈外部请求的连接器 Connector,和负责处理请求的容器 Container。
其中连接器和容器相辅相成,一起构成了基本的 web 服务 Service。每个 Tomcat 服务器可以管理多个 Service。
●Connector:负责对外接收和响应请求。它是Tomcat与外界的交通枢纽,监听端口接收外界请求,
并将请求处理后传递给容器做业务处理,
最后将容器处理后的结果响应给外界。
●Container:负责对内处理业务逻辑。其内部由 Engine、Host、Context和Wrapper 四个容器组成,
用于管理和调用 Servlet 相关逻辑。
●Service:对外提供的 Web 服务。主要包含 Connector 和 Container 两个核心组件,以及其他功能组件。
Tomcat 可以管理多个 Service,且各 Service 之间相互独立。
1.5 Tomcat 请求过程
` 用户在浏览器中输入网址,请求被发送到本机端口 8080,被在那里监听的 Connector 获得;
` Connector 把该请求交给它所在的 Service 的 Engine(Container)来处理,并等待 Engine 的回应;
` 请求在 Engine、Host、Context 和 Wrapper 这四个容器之间层层调用,
最后在 Servlet 中执行对应的业务逻辑、数据存储等。
` 执行完之后的请求响应在 Context、Host、Engine 容器之间层层返回,最后返回给 Connector,
并通过 Connector 返回给客户端。
2、Tomcat 服务部署
在部署 Tomcat 之前必须安装好 jdk,因为 jdk 是 Tomcat 运行的必要环境
· 关闭防火墙,将安装 Tomcat 所需软件包传到/opt目录下
jdk-8u201-linux-x64.rpm
apache-tomcat-9.0.16.tar.gz
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
· 安装JDK配置环境变量
cd /opt
rpm -ivh jdk-8u201-linux-x64.rpm
vim /etc/profile.d/java.sh写入
export JAVA_HOME=/usr/java/jdk1.8.0_201-amd64
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
export PATH=$JAVA_HOME/bin:$PATH
解释:

保存退出
source /etc/profile.d/java.sh
java -version
首先使用文本工具编写java源代码,比如 Hello.java
vim Hello.java
public class Hello {
public static void main(String[] args){
System.out.println("Hello world!");
}
}
保存退出
javac Hello.java
java Hello
· 安装启动Tomcat
cd /opt
tar zxvf apache-tomcat-9.0.16.tar.gz
mv apache-tomcat-9.0.16 /usr/local/tomcat
cd /usr/local/tomcat/bin
netstat -antp | grep 8080没有输出,说明没有8080
./startup.sh
浏览器:20.0.0.60:8080
开启mange页面:

cd manger
cd META-INF
vim context.xml
找到这一行:

保存退出
cd ..到tomcat目录下
cd conf
vim tomcat-users.xml

cd ..
cd bin
./shutdown.sh
./startuo.sh

解释:server status
jvm:解就是java的虚拟机,是java应用程序在计算机上运行的核心组件。jvm负责将编译后的java字节码(.class文件)解释或者编译成本地的机器码,计算机能够执行。jvm还提供了内存管理、垃圾回收、线程管理。确保java程序在不同的平台可以有一致性的功能
2.1 tomcat自身优化:
启动配置优化:第一次启动tomcat会发现启动速度很慢,十几秒到一分钟
需要修改jdk的参数:
vim /usr/java/jdk1.8.0_201-amd64/jre/lib/security/java.security

自身主配置文件的优化:
redirectPort:如果某连接器支持的协议是http,但是当接收客户端发来的请求时https就会启用此端口(8443)
maxthreads:tomcat使用线程来处理请求的,可以创建的最大线程数,也就是并发连接数。默认是200
minsparethreads:最小空闲线程数,开启tomcat时,会有多少线程,默认为0
maxSparethreads:最大备用线程,一旦创建的线程超过这个值,tomcat会关闭不再需要的端口线程。默认为-1,也就是不限制,一般不指定
URIEncoding:URL的格式编码,默认为utf-8,需要分别制定,所以一般不动
connectionTimeout:网络连接超时,单位毫秒,为0永不超时,一般为2000毫秒
enablelookups:是否反向解析域名,为了能够获取远程的主机名,一般设置为false,直接返回IP地址,提高了处理能力
disableUploadTimeout上传时是否使用超时机制。应设置为 true。
connectionUploadTimeout上传超时时间,毕竟文件上传可能需要消耗更多的时间,这个根据你自己的业务需要自己调,以使Servlet有较长的时间来完成它的执行,需要与上一个参数一起配合使用才会生效。
acceptCount指定当所有可以使用的处理请求的线程数都被使用时,可传入连接请求的最大队列长度,超过这个数的请求将不予处理,默认为 100 个。
compression是否对响应的数据进行GZIP压缩,off:表示禁止压缩;on:表示允许压缩(文本将被压缩)、force:表示所有情况下都进行压缩,默认值为 off,压缩数据后可以有效的减少页面的大小,一般可以减小 1/3 左右,节省带宽。
compressionMinSize表示压缩响应的最小值,只有当响应报文大小大于这个值的时候才会对报文进行压缩,如果开启了压缩功能,默认值就是 2048。
compressableMimeType压缩类型,指定对哪些类型的文件进行数据压缩。
noCompressionUserAgents="gozilla, traviata"对于以下的浏览器,不启用压缩
常见的MIME类型
文本: text/plain、text/html、text/css、text/javascript
图像: image/jpeg、image/png、image/gif
音频: audio/mpeg、audio/ogg、audio/wav
视频: video/mp4、video/webm、video/quicktime
应用程序: application/pdf、application/json、application/xml
MIME类型在确保互联网上的不同类型文件被软件和应用程序正确解释和处理方面发挥着关键作用!
2.2 内核优化
Linux内核优化中主要针对两个配置文件 /etc/security/limits.conf 和/etc/sysctl.conf
通常是利用调用内核参数的程序sysctl -a 查询出最优内核参数,然后写入 /etc/sysctl.conf 文件内的。
[root@www opt]# sysctl -a |grep fs.file-max
fs.file-max = 197221 #查询出的文件句柄数量上限。
sysctl: reading key "net.ipv6.conf.all.stable_secret"
sysctl: reading key "net.ipv6.conf.default.stable_secret"
sysctl: reading key "net.ipv6.conf.ens33.stable_secret"
sysctl: reading key "net.ipv6.conf.lo.stable_secret"
sysctl: reading key "net.ipv6.conf.virbr0.stable_secret"
sysctl: reading key "net.ipv6.conf.virbr0-nic.stable_secret"
文件句柄(File Handle)是操作系统用于跟踪和管理打开的文件或资源的数据结构。
在操作系统中,每个打开的文件、网络连接、设备等都会被分配一个唯一的句柄,
操作系统通过这个句柄来标识和访问这些资源。
句柄数是指操作系统能够同时管理的句柄的数量。在一个计算机系统中,
许多应用程序和进程需要打开和使用文件、网络连接等资源。每个资源都需要一个句柄来进行操作。
如果系统的句柄数限制太低,就可能导致应用程序无法打开足够的文件、网络连接或其他资源,
从而影响系统的性能和可用性。
因此,调整句柄数的设置是确保系统能够处理并发连接和资源请求的重要一环。
在高负载的服务器环境中,适当地增加句柄数的限制可以提高系统的并发能力和性能。
但是过于激进地增加句柄数可能会消耗过多的系统资源,因此需要根据实际需求和硬件配置进行调整。
65535 为Linux系统最大打开文件数
* soft nproc 65535
* hard nproc 65535
* soft nofile 65535
* hard nofile 65535
* soft nproc 65535: 最大进程数软限制为 65535,即可以使用 ulimit -u 命令查看和修改的值。
* hard nproc 65535: 最大进程数硬限制为 65535,即最大可分配的进程数。
* soft nofile 65535:最大打开文件数软限制为 65535,即可以使用 ulimit -n 命令查看和修改的值。
* hard nofile 65535:最大打开文件数硬限制为 65535,即最大可分配的文件数。
其他调试内核参数的查看: sysctl -a
kernel.sysrq = 0: 禁用了内核的SysRq功能,SysRq允许在系统崩溃或出现问题时执行一些调试操作。
kernel.core_uses_pid = 1: 设置核心转储文件名中包含进程ID,有助于标识是哪个进程导致了核心转储。
kernel.msgmnb 和 kernel.msgmax: 增加IPC消息队列的默认和最大大小,用于进程间通信。
kernel.shmmax 和 kernel.shmall: 调整共享内存的最大大小和分配页面数。
net.ipv4.ip_forward = 0: 禁用IP数据包的转发功能,通常用于不充当路由器的系统。
net.ipv4.conf.default.rp_filter 和 net.ipv4.conf.all.rp_filter: 控制反向路径过滤,提高网络安全性。
net.ipv4.icmp_echo_ignore_all: 允许或禁止系统响应ping请求。
net.ipv4.icmp_echo_ignore_broadcasts: 禁止系统对广播和多播地址的ICMP回显和时间戳请求作出响应。
net.ipv4.conf.default.accept_source_route: 不接受源路由,增加网络安全性。
net.ipv4.tcp_syncookies = 1: 启用SYN Cookies,保护系统免受TCP SYN 攻击。
net.ipv4.tcp_max_tw_buckets = 6000: 设置允许的TIME_WAIT套接字最大数量,避免服务器性能下降。
net.ipv4.tcp_sack = 1: 启用有选择的应答(SACK)来提高TCP性能。
net.ipv4.tcp_window_scaling = 1: 启用TCP窗口缩放功能,允许大窗口的TCP传输。
net.ipv4.tcp_rmem, net.ipv4.tcp_wmem: 调整TCP套接字读取和写入缓冲区大小。
net.ipv4.tcp_mem: 设置TCP缓冲区的最小、默认和最大值。
net.core.wmem_default, net.core.rmem_default, net.core.rmem_max, net.core.wmem_max: 调整网络核心 缓冲区的大小。
net.core.netdev_max_backlog: 控制网络接口接收数据包的排队队列大小。
net.ipv4.tcp_max_orphans: 设置系统允许的孤立TCP连接最大数量。
net.ipv4.tcp_max_syn_backlog: 控制系统允许的三次握手队列长度。
net.ipv4.tcp_synack_retries 和 net.ipv4.tcp_syn_retries: 设置SYN-ACK和SYN请求的重试次数。
net.ipv4.tcp_tw_recycle 和 net.ipv4.tcp_tw_reuse: 启用TIME_WAIT套接字快速回收和重用。
net.ipv4.tcp_fin_timeout: 设置TCP连接FIN(关闭连接)的超时时间。
net.ipv4.tcp_keepalive_time: 设置TCP keepalive探测包发送频率,以检测连接状态。
net.ipv4.ip_local_port_range: 设置本地端口范围,用于分配本地应用程序端口。
net.ipv6.conf.all.disable_ipv6 和 net.ipv6.conf.default.disable_ipv6: 禁用IPv6。
net.netfilter.nf_conntrack_max 和其他 net.netfilter.nf_conntrack_*: 控制连接跟踪和防火墙相关设置。
net.nf_conntrack_max: 设置最大连接跟踪项数。
vm.overcommit_memory = 0: 控制内存超额分配策略,避免OOM killer杀掉进程。
vm.swappiness = 0: 设置内存交换行为,降低内存交换。
fs.file-max = 999999: 设置进程可以同时打开的最大文件句柄数。
net.ipv4.tcp_max_tw_buckets = 6000: 设置操作系统允许的TIME_WAIT套接字最大数量。
net.ipv4.ip_local_port_range = 1024 65000: 设置系统允许的本地端口范围。
net.ipv4.tcp_tw_recycle = 1: 启用TIME_WAIT套接字快速回收。
2.3 jvm
2.3.1 jvm配置
catalina.sh就是server代码。以及容器的配置
![]()

./shutdown.sh
./startup.sh
2.3.2 Tomcat配置JVM参数
-Xms: 设置JVM的初始堆大小,即Java堆的最小大小。例如:-Xms512m表示设置初始堆大小为512MB。
-Xmx: 设置JVM的最大堆大小,即Java堆的最大大小。例如:-Xmx1024m表示设置最大堆大小为1GB。
-XX:NewSize: 设置新生代的初始大小。例如:-XX:NewSize=128m表示设置新生代的初始大小为128MB。
-XX:MaxNewSize: 设置新生代的最大大小。例如:-XX:MaxNewSize=256m表示设置新生代的最大大小为256MB。
-Xmnsize: 设置新生代的大小。与-XX:NewSize和-XX:MaxNewSize不同,-Xmnsize直接设置新生代的大小,
而不是设置初始大小和最大大小。
-XX:NewRatio: 设置新生代与老年代的比例。例如:-XX:NewRatio=2表示新生代的大小是老年代大小的1/2。
-XX:SurvivorRatio: 设置Eden区与Survivor区的比例。
例如:-XX:SurvivorRatio=8表示Eden区的大小是Survivor区大小的1/8。
-Xss: 设置线程栈的大小。例如:-Xss256k表示设置线程栈的大小为256KB。
2.3.3 jvm优化

3、tomcat虚拟主机配置
一台服务器上在一个tomcat中会部署多个虚拟机

创建两个网页:

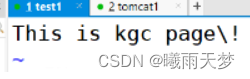
保存退出
保存退出

![]()
![]()

访问www.kgc.com就是访问/usr/localtomcat/webapps/kgc/index.jsp
![]()
![]()
![]()
到虚拟机的浏览器:
www.kgc.com:8080
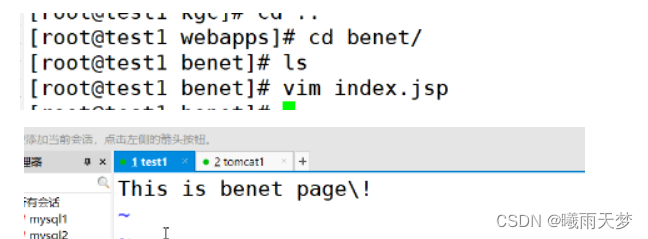
4、Tomcat多实例部署
· 安装好 jdk
· 安装 tomcat
cd /opt
tar zxvf apache-tomcat-9.0.16.tar.gz
mkdir /usr/local/tomcat
mv apache-tomcat-9.0.16 /usr/local/tomcat/tomcat1
cp -a /usr/local/tomcat/tomcat1 /usr/local/tomcat/tomcat2
· 配置 tomcat 环境变量
vim /etc/profile.d/tomcat.sh 加入
#tomcat1
export CATALINA_HOME1=/usr/local/tomcat/tomcat1
export CATALINA_BASE1=/usr/local/tomcat/tomcat1
export TOMCAT_HOME1=/usr/local/tomcat/tomcat1
#tomcat2
export CATALINA_HOME2=/usr/local/tomcat/tomcat2
export CATALINA_BASE2=/usr/local/tomcat/tomcat2
export TOMCAT_HOME2=/usr/local/tomcat/tomcat2
source /etc/profile.d/tomcat.sh 修改 tomcat2 中的 server.xml 文件,要求各 tomcat 实例配置不能有重复的端口号
· vim /usr/local/tomcat/tomcat2/conf/server.xml 修改
<Server port="8006" shutdown="SHUTDOWN"> #22行,修改Server prot,默认为8005 -> 修改为8006
<Connector port="8081" protocol="HTTP/1.1" #69行,修改Connector port,HTTP/1.1 默认为8080 -> 修改为8081
<Connector port="8010" protocol="AJP/1.3" redirectPort="8443" />
#116行,修改Connector port AJP/1.3,默认为8009 -> 修改为8010
· 分别把启动文件指向tomcat 1 2,修改各 tomcat 实例中的 startup.sh 和 shutdown.sh 文件,添加 tomcat 环境变量
vim /usr/local/tomcat/tomcat1/bin/startup.sh
跳到最后一行添加:
export CATALINA_BASE=$CATALINA_BASE1
export CATALINA_HOME=$CATALINA_HOME1
export TOMCAT_HOME=$TOMCAT_HOME1
· vim /usr/local/tomcat/tomcat1/bin/shutdown.sh
export CATALINA_BASE=$CATALINA_BASE1
export CATALINA_HOME=$CATALINA_HOME1
export TOMCAT_HOME=$TOMCAT_HOME1
· vim /usr/local/tomcat/tomcat2/bin/startup.sh
export CATALINA_BASE=$CATALINA_BASE2
export CATALINA_HOME=$CATALINA_HOME2
export TOMCAT_HOME=$TOMCAT_HOME2
· vim /usr/local/tomcat/tomcat2/bin/shutdown.sh
export CATALINA_BASE=$CATALINA_BASE2
export CATALINA_HOME=$CATALINA_HOME2
export TOMCAT_HOME=$TOMCAT_HOME2
· 启动各 tomcat 中的 /bin/startup.sh
/usr/local/tomcat/tomcat1/bin/startup.sh
/usr/local/tomcat/tomcat2/bin/startup.sh
netstat -natp | grep java
浏览器访问测试
http://192.168.233.21:8080
http://192.168.233.21:8081
5、nginx+tomcat实现动静分离
需要三台tomcat但是刚才多实例做了一个8080和一个8081,就可以只需要两台

虚拟机:test1(客户端),nginx1,tomcat1(8080,8081),tomcat2
实验:
nginx:

在http模块中配:

配置处理动态请求的location:

响应一个静态请求:在动态下面


tomcat1:

vim index.jsp

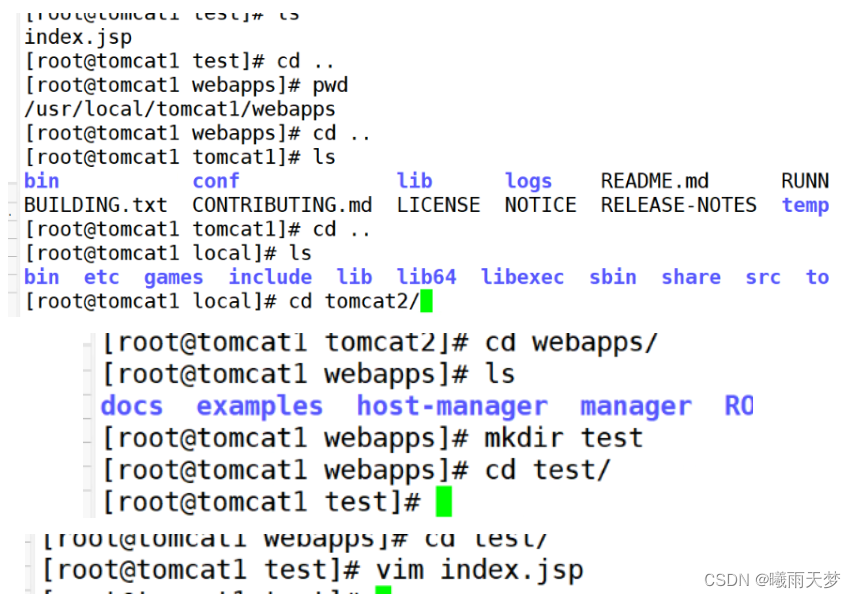




tomcat2:



tomcat1:
到里面的tomcat2

注释:之前这里的路径错误,需要修改成 /usr/local/tomcat2/webapps/test
之前的: 到里面的tomcat1
也修改一下
最后 ./startup.sh
systemctl restart nginx
以上为配置动态
静态:
nginx:

把照片拖到html下面,注意要和index.html的名字对应
浏览器:nginx的主机地址(20.0.0.30)会看到图片
最终:浏览器20.0.0.30/index.jsp请求动态
浏览器20.0.0.30请求静态
此时动静分离完成
用客户端来访问:
客户端地址/index.jsp动态
客户端地址/index.html(20.0.0.30/index.html)
6、补充 四层、七层反向代理做动静分离和负载均衡
实现:

需要:目前所有的都已经安装nginx和tomcat
192.168.146.20 tomcat(两个)
192.168.146.30 tomcat
192.168.146.50 七层反向代理(nginx)
192.168.146.60 七层反向代理(nginx)
192.168.146.70 四层反向代理(nginx)
192.168.146.30 客户机
七层反向代理如:

四层反向代理如:
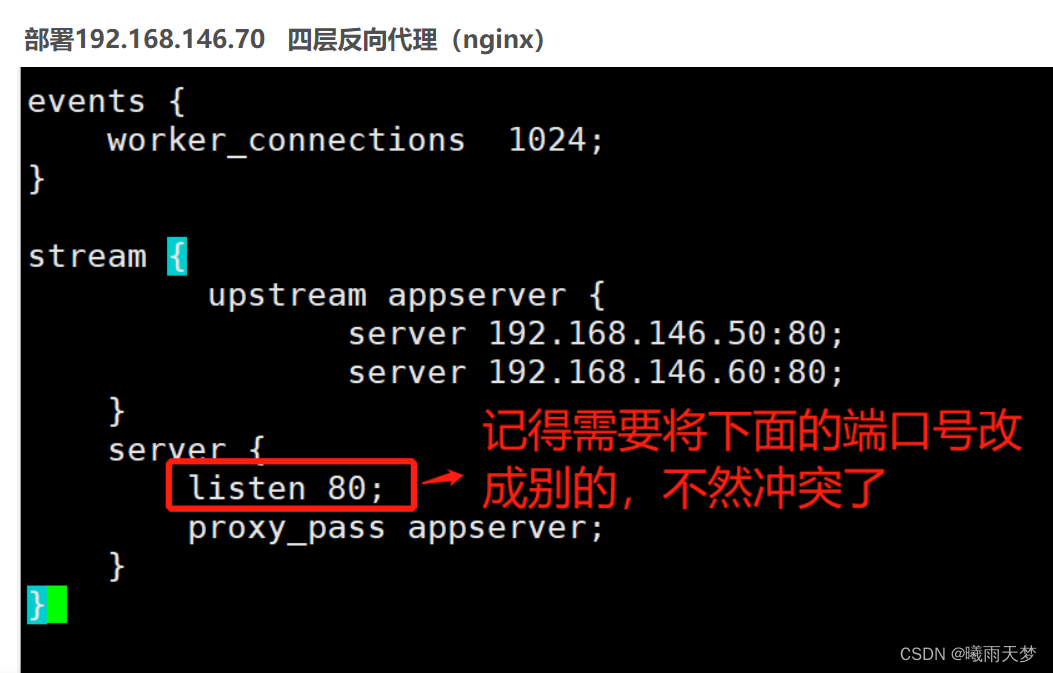
解题思路:
优先nginx web1和2配置7层反向代理,nginx1配置四层反向代理










![[Java优选系列第2弹]SpringMVC入门教程:从零开始搭建一个Web应用程序](https://img-blog.csdnimg.cn/5cb1ae10caa44fd4bccb1e3e7237861c.webp)