摘要:
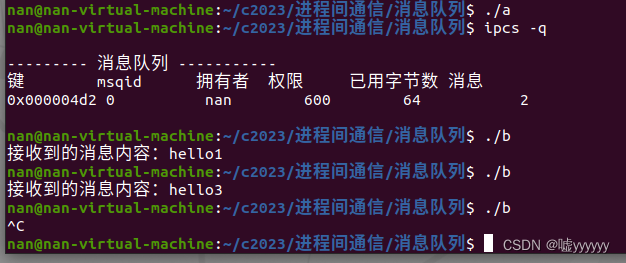
语言是llm(例如ChatGPT)连接众多AI模型(例如hugs Face)的接口,用于解决复杂的AI任务。在这个概念中,llms作为一个控制器,管理和组织专家模型的合作。LLM首先根据用户请求规划任务列表,然后为每个任务分配专家模型。专家执行任务后,LLM收集结果并响应用户。
问题:
1.尽管LLMs在NLP任务中取得了重大成就,但由于文本输入和输出形式的限制,目前的LLMs缺乏处理复杂信息(如视觉和语音)的能力。
2.在现实场景中,一些复杂的任务通常由多个子任务组成,因此需要多个模型的调度和协作,这也超出了语言模型的能力。
3.对于一些具有挑战性的任务,LLMs在零射击或少射击设置中表现出出色的结果,但他们仍然比一些专家(例如,微调模型)弱。
贡献点:
1. 为了补充大型语言模型和专家模型的优势,提出了HuggingGPT。HuggingGPT将llm作为规划和决策的大脑,针对每个特定任务自动调用和执行专家模型,为通用AI解决方案的设计提供了新的途径。
2. 通过将Hugging Face与ChatGPT周围的许多任务特定模型集成,HuggingGPT能够处理涵盖多种模式和领域的广义人工智能任务。HuggingGPT通过模型间的开放协作,为用户提供多模式、可靠的服务。
3. 指出了HuggingGPT(和自治代理)中任务规划的重要性,并制定了一些实验评估来衡量llm的规划能力。
4.在跨语言、视觉、语音和跨模态的多个具有挑战性的人工智能任务上进行的大量实验表明,HuggingGPT在理解和解决来自多个模态和领域的复杂任务方面具有巨大的潜力。
方法:
整体流程
1.任务规划:使用ChatGPT分析用户的请求,了解用户的意图,并通过提示将其分解为可能可解决的任务。
通常,在实际场景中,许多用户请求将包含一些复杂的意图,因此需要编排多个子任务来实现目标。因此,我们制定任务规划作为HuggingGPT的第一阶段,目的是利用LLM分析用户请求,然后将其分解为结构化任务的集合。此外,我们还需要LLM来确定依赖关系以及这些分解任务的执行顺序,以建立它们之间的联系。
2.模型选择:为了解决计划的任务,ChatGPT根据模型描述选择托管在hug Face上的专家模型。
完成任务规划后,HuggingGPT接下来需要将任务和模型进行匹配,即在解析的任务列表中为每个任务选择最合适的模型。为此,我们使用模型描述作为连接各个模型的语言接口。更具体地说,我们首先从机器学习社区(例如,hug Face)获得专家模型的描述,然后通过上下文任务模型分配机制动态选择任务模型。该策略支持增量模型访问(简单地提供专家模型的描述),并且可以更加开放和灵活地使用ML社区。
上下文任务模型分配我们将任务模型分配表述为一个单选问题,其中潜在的模型在给定的上下文中作为选项呈现。通常,HuggingGPT能够根据提示符中提供的用户查询和任务信息,为每个已解析的任务选择最合适的模型。然而,由于最大上下文长度的限制,提示符不可能包含所有相关的模型信息。为了解决这个问题,我们首先根据它们的任务类型过滤掉模型,只保留那些与当前任务类型匹配的模型。对于这些选定的模型,我们将根据它们在hug Face上的下载次数对它们进行排名(我们认为下载可以在一定程度上反映模型的质量),然后选择top-K的模型作为HuggingGPT的候选模型。此策略可以大大减少提示中的令牌使用,并有效地为每个任务选择适当的模型。
3.任务执行:调用并执行每个选定的模型,并将结果返回给ChatGPT。
一旦将特定的模型分配给已解析的任务,下一步就是执行该任务,即执行模型推理。因此,在这个阶段,HuggingGPT会自动将这些任务参数输入到模型中,执行这些模型来获得推理结果,然后将其发送回LLM。在这个阶段有必要强调资源依赖的问题。由于先决条件任务的输出是动态生成的,因此HuggingGPT还需要在启动任务之前动态地指定任务的依赖资源。
4.响应生成:最后,利用ChatGPT整合所有模型的预测并为用户生成响应。
在所有任务执行完成后,HuggingGPT需要生成最终响应。HuggingGPT将前三个阶段(任务规划、模型选择和任务执行)的所有信息集成为这一阶段的简明总结,包括计划任务列表、任务选择的模型以及模型的推断结果。其中最重要的是推理结果,这是HuggingGPT做出最终决策的关键点。这些推理结果以结构化的格式呈现,如对象检测模型中带有检测概率的边界框,问答模型中的答案分布等。HuggingGPT允许LLM接收这些结构化的推理结果作为输入,并以友好的人类语言形式生成响应。此外,LLM不是简单地聚合结果,而是生成主动响应用户请求的响应,从而提供具有置信度的可靠决策。
整体流程如下图所示:语言是llm(例如ChatGPT)连接众多AI模型(例如hugs Face)的接口,用于解决复杂的AI任务。在这个概念中,LLM作为一个控制器,管理和组织专家模型的合作。LLM首先根据用户请求规划任务列表,然后为每个任务分配专家模型。专家执行任务后,LLM收集结果并响应用户。
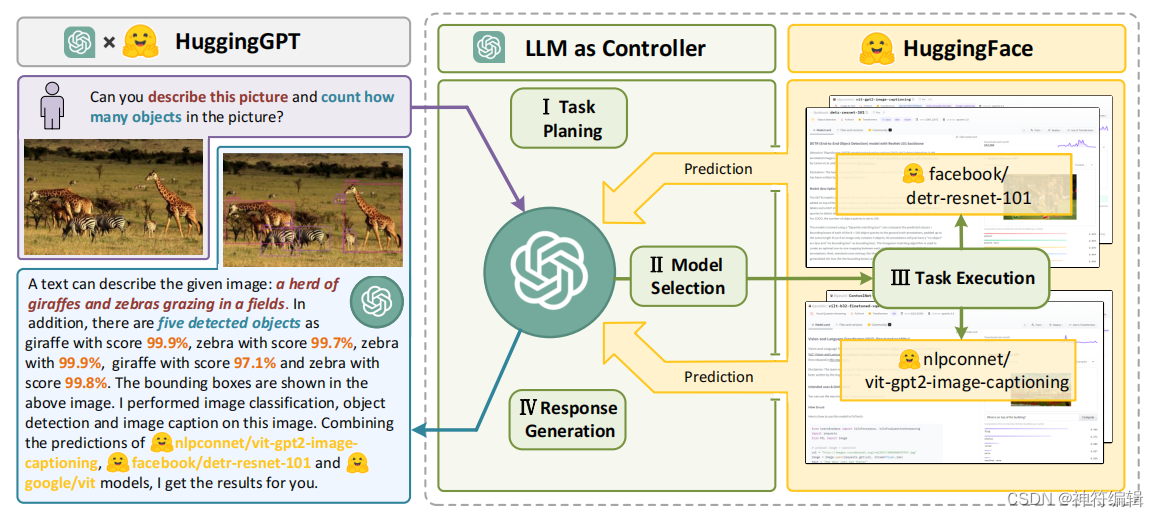
一个huggingGPT的例子,如下图所示。HuggingGPT的工作流程以LLM(如ChatGPT)为核心控制器,专家模型为执行者,分为四个阶段:1)任务规划:LLM将用户请求解析为任务列表,确定任务之间的执行顺序和资源依赖关系;2)模型选择:基于专家模型在hug Face上的描述,LLM为任务分配合适的模型;3)任务执行:混合端点上的专家模型执行分配的任务;4)响应生成:LLM集成专家的推理结果,生成工作流日志汇总,响应用户。

局限性:
(1)HuggingGPT中的规划严重依赖于LLM的能力。因此,我们不能保证生成的计划总是可行和最优的。因此,如何对LLM进行优化,提高LLM的规划能力至关重要;
(2) 在我们的框架中,效率是一个共同的挑战。为了构建这样一个具有任务自动化的协作系统(例如HuggingGPT),它严重依赖于一个强大的控制器(例如ChatGPT)。然而,HuggingGPT在整个工作流程中需要与llm进行多次交互,从而增加了生成响应的时间成本;
(3)令牌长度是使用LLM时的另一个常见问题,因为最大令牌长度总是有限的。虽然有些作品已经将最大长度扩展到32K,但如果我们想要连接众多的模型,这对我们来说仍然是无法满足的。因此,如何简单有效地总结模型描述也是值得探索的问题;
(4)不稳定性的主要原因是llm通常是不可控的。虽然LLM在生成方面很熟练,但在预测过程中仍有可能不符合指令或给出不正确的答案,导致程序工作流程出现异常。如何减少推理过程中的不确定性是设计系统时必须考虑的问题。







![[Java优选系列第2弹]SpringMVC入门教程:从零开始搭建一个Web应用程序](https://img-blog.csdnimg.cn/5cb1ae10caa44fd4bccb1e3e7237861c.webp)