前言:
在7月底的一篇文章中,九章智驾提到,数据闭环能力是自动驾驶下半场的“入场券”,这一观点在行业内引起了广泛共鸣。
在数据闭环体系中,仿真技术无疑是非常关键的一环。仿真的起点是数据,而数据又分为真实数据跟合成数据。随着真实数据“规模小、质量低、使用难度大”等问题日渐暴露,合成数据越来越受重视。
顾名思义,合成数据(synthetic data)就是通过计算机技术生成的数据,而不是由真实事件产生的数据。但合成数据又具备“可用性”,能够在数学上或统计学上反映原始数据的属性,因此也可以用来训练、测试并验证模型——OpenAI 的 GPT-4,就采用了大量前一代模型 GPT-3.5 生产的数据来进行训练。
在2022年底,笔者曾写过5篇关于自动驾驶仿真的科普文,但这几篇文章对合成数据的着墨不多。过去的两个月里,笔者在学习合成数据的过程中,又遇到了不少疑问,带着这些疑问,笔者请教了十多位业内专家,然后形成“合成数据科普文”系列。
在本系列文章的撰写过程中,笔者得到了光轮智能CEO谢晨、图森首席科学家王乃岩、辰韬资本赵磊、复睿微电子张俊川、百度仿真专家徐志健、昆易电子方志刚、“车路慢慢”运营者李漫漫、PanoSim王文威等朋友的支持,在此表示感谢。
自动驾驶合成数据科普一:
不做真实数据的“颠覆者”,做“杠杆”
自动驾驶的仿真,最早就是以合成数据为主。这里讲的合成数据,主要是指由人工基于规则搭建的场景,这背后的技术,就是业内常说的WorldSim。通常,基于WorldSim搭建的场景,还需要用Unreal等游戏引擎来做图像渲染。直到今天,WorldSim+游戏引擎仍然是自动驾驶行业用得最多的合成技术之一。
看起来,基于WorldSim+游戏引擎的合成数据能在一定程度上弥补真实数据不足的问题,然而,在实际使用中,这种合成数据存在一个很难克服的短板:真实度还不够高。用更专业的术语来说是“保真度”不够高。
这一痛点,决定了基于WorldSim+游戏引擎的合成数据基本上只能用来做测试,很难用于做算法训练。
为了避开WorldSim+游戏引擎技术的这一短板,有一些公司试图将真实道路数据“转换成数学模型”。然而,这一设想实施起来困难重重。
但合成数据“可用性”的提升,并未因此而停止。
真正能帮合成数据提升可用性的,是更高的保真度和更强的泛化能力。GAN、VAE和Diffusion Model等模型在自动驾驶仿真中的应用,已经证明了这一点;而当下广受追捧的NeRF技术,也需要保证泛化能力才有可能被广泛应用。
当下大热的AI大模型能,也将在自动驾驶仿真中占有一席之地。事实上,AI大模型+NeRF的组合,被一些从业者视为帮合成数据攻克保真度和泛化能力这两大难题的关键武器。
随着合成数据面临的主要难题被一一攻克,真实数据“规模小、质量低、使用难度大”的问题也不再那么令人担忧。
通常,在谈起合成数据时,人们本能地以为它的主要价值是弥补真实数据“数量不足”的问题。但这可能是一个严重的误解。
在笔者看来,真实数据的最主要问题并不是“太少”,而是“质量低,使用难度大”。所以,哪怕真实数据的规模很大,合成数据仍然是必不可少的。不信的话,看看“最不缺”真实数据的特斯拉是怎么做的吧——特斯拉也在使用合成数据!
在国内,各家已有自动驾驶量产车型上路的主机厂也不缺真实数据,但这些数据的利用率究竟“高达”20%、10%还是1%,其实是存在很大的疑问的。
不过,真实数据质量低、使用难度大给主机厂带来的困扰,恰合也就是合成数据的用武之地。
有意思的是,不同于L4公司普遍用合成数据来“弥补”真实数据的不足,一些以提供合成数据服务为主业的公司更倾向于将合成数据定位为真实数据的“杠杆”。在后者看来,合成数据的使命和愿景并不是要去顶替真实数据,而是要做真实数据的“放大器”,帮助主机厂或自动驾驶公司提高真实数据的使用效率。
下面,我们将以1.1万字的篇幅来盘点一下“合成数据究竟能解决真实数据的哪些痛点”。
一、兼顾隐私保护与数据的可用性
在真实场景中,自动驾驶车辆的传感器采集到的信息经常包括车牌、人脸,但出于隐私保护的需求,这些数据通常大都无法直接使用,而是得先做脱敏或加密才行。但脱敏不仅意味着一笔额外的成本,而且,如果脱敏处理不好,数据的价值也会大打折扣,甚至根本无法使用。
但如果是根据实际需求搭建一些不包含隐私信息的数据,就可在兼顾隐私保护的前提下确保数据的可用性。
在美国和欧洲,合成数据已经是一个很大的产业了,但在中国,合成数据还处于萌芽阶段,其中有一个重要的原因是:
美欧国家在文化和法律层面都会对隐私保护比较讲究,因此,企业不得不通过采用合成数据来避免高度依赖真实数据所带来的风险;而在中国,长期以来,无论在文化层面还是法律层面,隐私都没有受到足够的重视,所以,企业可以“肆无忌惮”地使用真实数据,这也导致了中国缺乏合成数据发展的土壤。
但情况正在发生变化。一方面,在中国,普通个体关于隐私保护的权利意识在觉醒;另一方面,法律层面也不允许企业肆意滥用各种隐私数据了。
单从隐私保护的角度考虑,国内公司也将越来越多地降低对真实数据的依赖程度。
二、避开高精地图的资质障碍
除了图商等极少数有资质的公司,大多数公司都无法通过路采获取真实数据的方式来绘制高精地图,为了避开这一问题,很多公司推出了“去高精地图”方案,但这一方案对公司的前融合算法能力、规控算法能力都提出了新的挑战,实际上,真正能落地的公司并不多。
但如果能用合成数据来制作高精地图,那问题就简单得多了。
在中国,我们尚未看到有公司采用合成数据来制作高精地图,但在美国,已经有了类似的先例了。
2021年11月,在一场题为 Under the Hood的活动上,Cruise仿真技术战略主管 Sid Gandhi 披露,在向新的城市拓展时,他们不必重新绘制城市地图来跟踪车道变更或街道封闭等“不可避免发生的环境变化”,而是利用一项名为 WorldGen 的技术,准确、大规模地生成整个城市,“从奇特的布局到最小的细节”。
为了确保最佳的世界创建,Cruise 考虑了一天 24 小时不同时间段的照明和天气条件等因素,甚至系统地测量了旧金山一系列路灯的光线。
对于无法在现实路况下收集的特定场景,Cruise则使用 Morpheus。Morpheus 是一个可以根据地图上的特定位置生成合成数据的系统。
据曾担任过Cruise仿真负责人的光轮智能CEO谢晨说:
Crusie的 WorldGen和Morpheus并不是用合成数据来做高精地图,而是对真实世界做3D重建。但无论如何,将车道变更或街道封闭及“从奇特的布局到最小的细节”都纳入3D重建中,重建后的信息元素已经很接近高精地图了。
在美国,自动驾驶公司采集真实道路数据并不会受到如在中国这般严格的限制,但Crusie仍然采用了合成数据,这给那些被高精地图政策束缚了手脚的中国公司提供了一种新思路。
此外,今后受数据合规相关法规政策影响的,就不限于高精地图数据了,还有用于感知算法训练的数据回传。
(这一点,九章在6月30日发的《“去高精地图”跟“轻高精地图”有啥区别?落地的挑战又是啥?》一文的第七章“感知算法训练或将受到数据合格政策的影响”部分已做过详细的分析,并在此后也从其他平台发布的类似内容中得到进一步印证,在此不再赘述。)
可以想见,接下来,用真实道路数据做算法训练的难度是越来越大了——不是没法做,关键是对车端脱敏的要求太高了,甚至可能还需要跟有测绘资质的图商合作。
受这一政策冲击较少的公司,应该就是那些率先开始拥抱合成数据的公司。
三、高效生成在真实场景中很难获取的Corner Case
大家都清楚,自动驾驶系统很难彻底取代人,最关键的原因是对各种corner case的应对能力不足,而应对能力的不足又源于数据量不够。这正是合成数据大有可为的地方。
大量的corner case,在真正发生前,没有人能想得到——预期功能安全第三象限里面的“unknown,unsafe”一类,所以无法在真实道路上做模拟。这类corner case,没法通过基于人工规则的合成数据(WorldSim)来生成,也没法通过对真实世界做3D重建的技术(NeRF)来生成,但有望通过基于AIGC的合成数据来获取。
有的corner case,尽管人能想象得到“大概会怎样”,但毕竟太危险(known,unsafe),所以,也不适合在真实道路上做模拟。这种corner case,没法通过NeRF技术来生成,但可以通过WorldSim来生成。当然,也有望通过AIGC来生成。
有的corner case,算不上有多么unsafe,但在真实世界中确实很罕见。如雨、雾、雪和极端光线等极端天气跟某种极端交通流的组合。这些,也需要通过合成数据技术(同上,不包括NeRF)来生成。
(为何这一章会在多处提到了有许多corner case无法通过当下大热的NeRF技术来生成?这个问题的答案,我们将在本系列的第二篇文章中做详细的阐释。)
有许多corner case,真实数据中其实有的,但无奈真数据中corner case的密度太低,挖掘成本太高,这个时候,工程师们如果没有足够的耐心或“实在等不及”,则直接选择合成数据便是最佳策略。
有了合成数据,主机厂或自动驾驶公司便可在几小时内模拟数百万个行人(现实中,这通常需要几个月才能完成)。这些模拟可能涵盖不同照明条件、目标位置和恶劣环境下(暴雨、极寒、浓雾等)的示例。或者,可以插入随机噪声来模拟脏污的摄像头、雾水和其他视觉障碍物。
此外,真实数据由于高度受制于采集场景的限制,所以,corner case在样本的分布上也很难有效满足算法的需求。而合成数据,可以有针对性地生成分布状况更满足训练需求的corner case,这更有助于提升算法的性能。
四、“非必要,不采集”,降低数据采集、回传及存储环节的成本
许多主机厂都声称已经量产上路的自动驾驶车型每天都在回传数据,但这个所谓的“数据回传”究竟实现到什么程度、所谓的“影子模式”是否真的落地了,一直是个玄学。
之前只有为数不多的测试车的时候,数据的问题相对好办,毕竟,“回传”可以通过硬盘来解决,筛选可以在云端做,然而,在量产车上,通过硬盘来解决数据“回传”的道路走不通了,筛选出有效数据这个工作就要在车端完成。
在3月份的《自动驾驶数据闭环系列之一:理想丰满,现实骨感》一文中,我们提到,在量产车上采集数据会占用一些系统资源,比如计算、存储等。
理论上,可以假设计算资源、网络带宽等都不受限制,但在实际落地过程中,如何保证采集数据不影响量产车上自动驾驶系统的正常运行,例如,如何不影响自动驾驶系统的延迟等,这是一个需要解决的问题。
因此,在设计的时候,就需要考虑到采集数据等对自动驾驶系统运行的影响。
此外,在数据量特别大的时候,数据回传的成本也会非常高。
单车每日回传的数据量大概为百兆级。在研发阶段,车辆总数可能只有几十辆或者几百辆,但是到了量产阶段,车辆数目的量级可以达到上万、几十万甚至更多。那么,量产阶段,整个车队日产生的数据量就是很大的数字。据某数据管理供应商提供的信息,某造车新势力每个月仅用来做数据回传的流量费就高达“大几千万”。
另一方面,急剧增加的数据量还给存储空间以及数据处理的速度都带来了挑战。
量产之后,数据处理的延迟需要和研发阶段保持在同一个量级。但如果底层的基础设施跟不上,数据处理的延迟就会随着数据量的增长而相应地增加,这样会极大地拖慢研发流程的进度。对于系统迭代来讲,这种效率的降低是不可接受的。
一位业界专家告诉九章智驾:
目前,我们还没有看到哪家公司具备处理量产车上回传的大规模数据的能力。即使是某家在数据闭环层面做得比较前沿的造车新势力,即便是每辆量产车每天只回传5分钟的数据,他们也难以应对这样的数据量,因为当前的存储设备、文件读取系统、计算工具等都还无法应对极大的数据量。
要应对越来越大的数据量,底层的基础设施以及平台的设计都需要相应升级。
工程团队需要开发完善的数据访存SDK。由于视觉数据、雷达数据的文件尺寸都非常大,数据的访问、查询、跳转、解码过程都需要效率足够高,否则会大大拖慢研发进度。
如果能做到尽可能多地使用合成数据来模拟一些场景,只有在合成数据无法满足要求的时候再回传真实数据,即“非必要,不采集、不回传”,那跟数据采集、回传和存储相关的成本就会大幅度下降。
五、自带完美标签,不用再做标注
车端数据在回传到云端后,需要先做好标注后才能使用。据称,在大模型用于数据标注后,已经有高达80%的数据标注可以通过自动化的方式来完成,但还有至少20%涉及复杂场景、多目标、语义复杂的数据需要由人工来完成“精标”。
当下大热的BEV+Transformenr技术,对数据标注的需求进一步上升。
以往,需要标注的主要是前视摄像头的数据,2D 标注框+ 3D 位置就已经是标注的全部内容了;而今,在BEV+Transformer方案下, 所有相关的摄像头(可能超过7个)能看到的所有障碍物、车道线、车辆的运动状态都需要对应的标注, 并且还要统一在同一坐标系下,还有大量的语义信息也需要标注,而标注成本,也从之前的每帧10元左右上涨到每帧30-40元,甚至更高。
人工标注的工作量远超外人想象。据毫末智行数据智能科学家贺翔在6月底的一场自动驾驶公开课上的说法,一张关于十字路口的照片,要把位置、天气、拥挤状况、其道路使用者、广告牌等各种元素都标注出来,并能在此基础上做场景筛选,可能100个标签也不够用。
假如车上有8-12个摄像头、1-2个激光雷达,10秒钟的视频里面可能有上千张图片,标注成本得几千元。
一般的检测框,一分钟的内容,标注需要一小时左右;点云分割,一分钟的内容,标注需要几个小时;但对更复杂的任务做4D标注,可能一分钟的任务需要花超过一天时间才能完成。
后面要做端到端的算法训练,在给这一帧的内容打标签时,还得考虑该标签如何跟其他帧的内容做关联。
总的趋势是,自动驾驶行业对标注的要求越来越高了,这意味着,投入到一分钟视频上的标注成本越来越高了。
在7月底的一场沙龙上,某自动驾驶公司COO称,在数据处理的高峰期,他们曾同时跟超过100家标注公司合作,不仅直接成本很高,而且,供应商管理的复杂度也极高。
做人工标注,如何在数据量极大的情况下,保证标注结果的准确率、一致性也是一大挑战。想象一下,标注工人连续几天坐在办公桌前做同样的工作时间,几乎就像在工厂的传送带上工作一样, 在这种情形下,ta一定会时不时地犯一些奇怪的错误。
如果标注的结果不准确、不完整,那基于这些数据训练出来的模型的性能就会受到影响。
但合成数据自带图像和激光雷达的“真值”标签,包括 2D 和 3D 边界框、语义和实例分割、深度、光流、运动矢量、关键点等。并且,对被遮挡行人/物体这种很难做人工标注的场景,合成数据也可以自带完美标签。
在成本方面,与需要标注的真实数据相比,自带标签的合成数据也具有明显优势。
合成数据服务商AI.Reverie 认为,人工标注一张图片可能需要6美元(这还不算数据回传、筛选及存储的成本),但通过合成数据技术生成同样一张自带标签的图片只需要6美分。
诚然,合成数据无法完全取代真实数据,但合成数据使用率的上升,对真实数据的依赖度下降,就可以减少因为真实数据“不好用”而产生的不必要的成本。
全球数据标注龙头公司Scale AI已敏锐地意识到了这一趋势。
过去几年,算法训练对数据标注的饥渴需求,造成了一个很有意思的现象是:自动驾驶公司和主机厂的自动驾驶业务都没挣到钱,但做数据标注的公司却挣到钱了。全球数据标注龙头Scale AI甚至因此而估值超过73亿美元。
不过,Scale AI也已经意识到,随着合成数据的应用逐渐深入,数据标注业务的营收会受到不小的冲击。因此,在2022上半年,该公司推出了一个名为Scale Synthetic的合成数据平台,宣布进入合成数据产业。他们甚至称,合成数据是自己在2022年的“首要任务”。
数据标注龙头进军合成数据,逻辑是“在别人能干掉我之前,我先掌握他们的技能,大不了自己干掉自己”,这算是一场自我革命了。
作为被合成数据“革命”的对象,数据标注公司积极拥抱合成数据,这又从反面进一步印证了自带标签的合成数据相比于真实数据的优势。
六、可编程,可交互
看起来,各家公司手上都积累了不少真实数据,但真实数据用来做仿真,有个很严重的痛点是:复用性差。
比如,在做路采的时候,车辆的芯片平台、传感器架构及制动系统是怎样的,那我在仿真系统里做测试时,车辆的这些硬件配置也必须跟路采时所用的车辆配置一致。
某工具链公司的仿真负责人说:
在用真实道路数据做仿真的情况下,一旦传感器的位置或者型号有变更,这一组数据的价值就降低,甚至会‘作废’。
究其原因,真实数据在使用时无法调整任何参数,而只能做简单的“回放”——也被称为“回灌”(LogSim)。
复睿微电子仿真负责人张峻川在一次公开分享中提到,WorldSim(用合成数据做仿真)像在玩游戏,而LogSim(用真实道路数据做仿真)则更像是电影,你只能看,没法参与,没法生成与原始记录不同的传感器数据,因此,LogSim天然没法解决交互性的问题。
可以想见,没法解决交互问题的LogSim,只能用于测试验证一个现成的算法“是不是OK”,却不能用于从头来训练一个算法。
确有一些公司曾尝试把采集到的场景里面的元素都完成参数化,但目前还没有成熟的案例落地。
但合成数据天然具有可编程性,很多参数都是可以调整的,因此,数据复用的难度将大幅度降低。
(合成数据的可编程性或泛化能力、可复用性,因AI的参与度而有所不同,总的来说,AI的参与度越高,合成数据的泛化能力越强,这一点,我们将在本系列的第二篇文章中做更详细的分析,在此暂不赘述。)
丰田及其投资的合成数据公司Parallel Domain都将合成数据称为 Programmable Data即“可编程数据”。Parallel Domain在其官网上称:“我们可以对我们希望在训练数据中获得的任何输出进行编程......通过组合参数扫描,为每辆车生成数据,乘以每种照明条件、每种天气条件,每种油漆颜色。”
英伟达在对外介绍合成数据时经常提到一个词“域随机化”(Domain Randomization),即通过在合成数据的生成过程中引入各种随机性和变化,使得生成的数据能够覆盖更广泛的场景。
英伟达说的“域随机化”,包括改变某个特定对象的颜色、光照、纹理、材质、变换等多种属性,也包括添加和修改传感器的位置和参数,以及定义其他道路使用者的运动状态。此外,改变一天的时间、太远的位置、温度、道路的湿度,也是“域随机化”的一部分。
在理想的情况下,用轿车去采集的数据,如果把视角调整成卡车视角,那这一组数据就可以用于训练卡车的感知算法。
专注于人类数据的Synthesis AI甚至能够以编程方式自定义人的面部数据集。为满足DMS方向客户的需求,Synthesis 生成了大约 100,000 个涵盖不同性别、年龄、体重指数、肤色和种族的“合成人”。
通过该平台,数据科学家可以定制化身的姿势以及头发、面部表情、注释方向、发型、服装(例如面具和眼镜)以及环境方面(例如照明,甚至虚拟相机的“镜头类型”)。
对合成数据做编程的最大意义是,可以让corner cace都可以泛化出数千个“变体”,由此,训练出来的模型会具有很强的鲁棒性和泛化能力,从而更容易适应真实世界中的各种变化和不确定性。
此外,合成数据生成过程的参数化,使机器学习工程师能够更好地控制每次迭代,并让数据集中已存在内容的更有可追溯性。
七、 通过随机化及调整场景分布来解决“过拟合”的问题
在学习合成数据的过程中,笔者注意到,不少开发者都反映,基于真实数据训练出的模型,很容易出现“过拟合”(Overfitting)的问题。
所谓过拟合,指模型在训练数据上表现良好,但在新的、未见过的数据上表现较差的情况。当模型过度拟合时,它学习到了训练数据中的细节和噪声,而无法泛化到新的数据上。
那么,真实数据是不是要比合成数据更有可能引发模型的“过拟合”问题?
光轮智能CEO谢晨认为:
严格地说,“过拟合”跟训练数据是真实数据还是合成数据并没有必然关系,真正导致“过拟合”的,是训练数据集中的场景分布跟真实世界不一致,导致数据集可能无法捕捉到真实世界的复杂性和多样性——而不管这个“数据集”究竟是真实数据集还是合成数据集。
谢晨举例说:
比如,很多自动驾驶系统在晚上或者雨天表现不太好,这是因为他们当初做训练数据采集的时候,采的大部分都是白天和晴天的数据。
英伟达仿真产品经理Matt Cragun也做过类似的解释:
如果大部分真实数据都是在白天条件下收集的,那么在该数据集上训练的算法在夜间或弱光条件下可能表现不佳。
再比如,仿真公司Applied Intuition发现,某个感知模型很难准确地检测到骑自行车的人和起摩托车的人,原因在于,在用于训练这个模型的真实数据集中,骑行者出现的频率远低于车辆和步行者——前者出现的频率不到后者的1/170。
那么,该如何避免“过拟合”的问题呢?笔者从ChatGPT 3.5上得到的对策有8条,如下图所示:
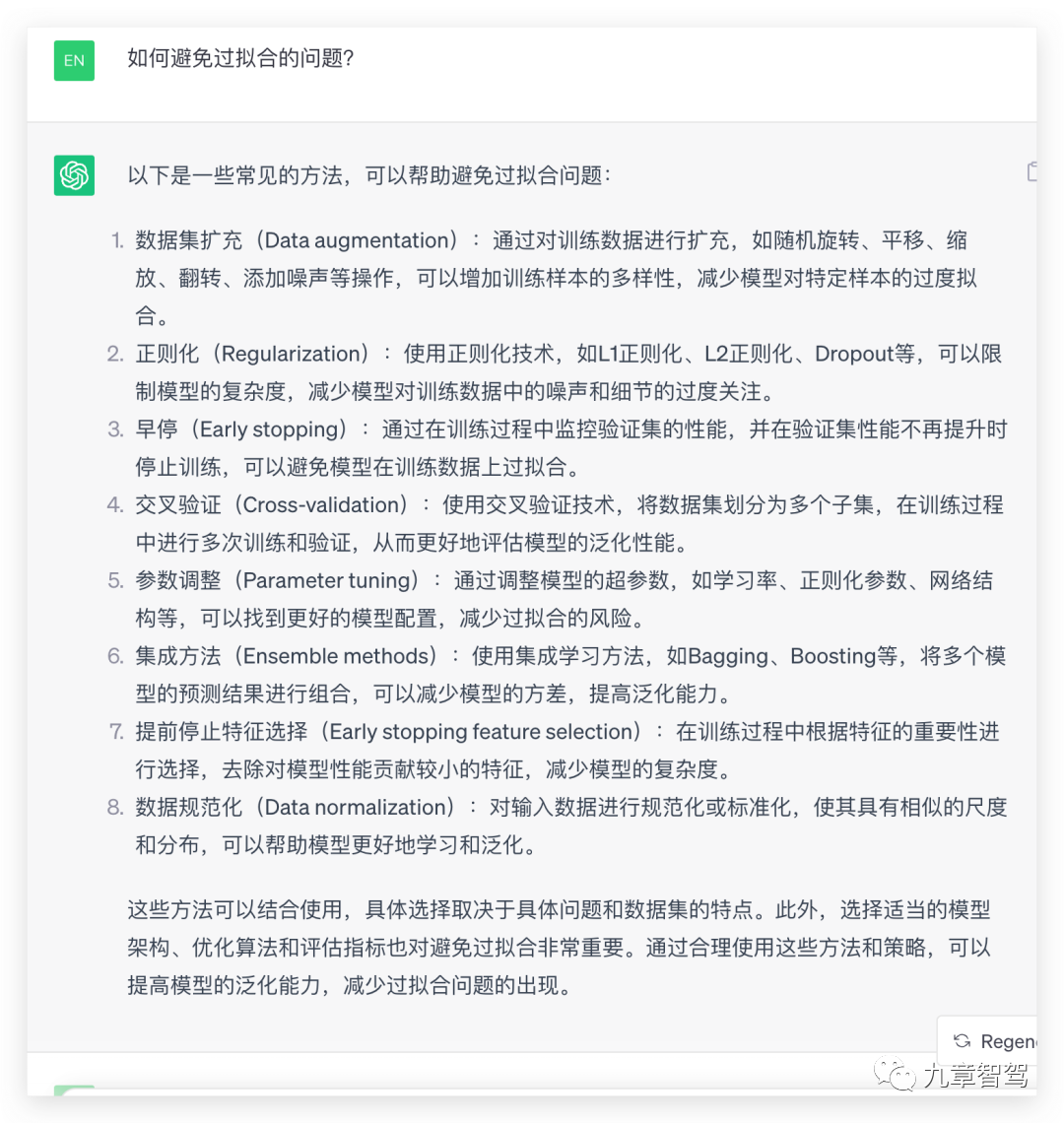
其中,跟训练数据相关的对策是如下两条:
1. 通过对训练数据进行扩充,如随机旋转、平移、缩放、翻转、添加噪声等操作,增加训练样本的多样性;
2.对输入数据进行规范化或标准化,使其具有相似的尺度和分布,可以帮助模型更好地学习和泛化。
鉴于真实数据是“死的”,无法编程,因此,要对真实数据做如上操作,基本上是不太可能的。所以,更容易用来解决“过拟合”问题的训练数据,基本只能是合成数据了。
英伟达主要通过合成数据的域随机化来克服“过拟合”问题。所谓域随机化,即在合成数据的生成过程中引入各种随机性和变化(这也是对合成数据做泛化的一种特殊形式),使得生成的数据能够覆盖更广泛的场景。
比如,英伟达曾在测试中发现,某个基于合成数据训练出来的模型未能在大多数真实图像上充分检测到门,因为它在模拟中过度拟合了门的纹理。为了防止门的纹理过度拟合,英伟达仿真团队在 30 种不同的类木纹理中对门的纹理应用了随机化。
与此类似的是,为了使模型对墙壁上的 QR 码等噪声具有鲁棒性,英伟达仿真团队还应用了 DR overtexture,将墙壁的纹理随机化为不同的纹理,包括 QR 码和其他合成纹理。
再比如,英伟达还发现,某个基于合成数据训练的模型在低温照明条件下有很多误报,其原因在于,仿真环境中的照明保持稳定和恒定,而在现实中,照明条件多种多样。为避免同类问题再次发生,英伟达仿真团队在合成数据中的天花板灯上添加了光温 域随机化,以随机化灯光的移动、强度和颜色。
曾担任过英伟达自动驾驶仿真主管的谢晨也认同英伟达在解决“过拟合”问题上采取的思路。
谢晨补充说:
光轮智能在生产合成数据的过程中,坚持的一个原则是“守正出奇”,即在客户特别需要的增量数据方面,他们按照客户的要求做定制;在客户不特别提要求的地方,他们尽量让各种场景的分布贴近真实世界。
比如,将高速路和城市道路的分布比例、白天和晚上的分布比例、雨雪天气和晴天的分布比例设置得尽量跟真实世界一致。
基于这种数据训练出的模型,就不太容易出现“过拟合”的问题。
我们在上文中提到,针对基于真实数据训练出的感知模型很难检测到骑行者的问题,Applied Intution公司将其原因归结为“骑自行车和骑摩托车手的人在数据集中出现的频率远低于行人和汽车”,然后,他们采取的对策是,往训练数据集中添加一些骑行者出现频率比较高的合成数据。
Applied Intution将原本基于100%的真实数据集训练出来的模型设定为“基线模型”,然后在实验中发现,与基线模型相比,将合成数据跟真实数据混合在一起做训练,感知模型对骑行者的识别结果得到了显著改善。
Applied Intuion进一步发现,先在合成数据上对模型做预训练,然后再在 100% 的真实数据上对其进行微调,则模型对骑行者的识别能力可显示出特别明显的提升——无论合成数据在训练数据集中的占比是多少,基于该数据集训练出的模型在性能上始终优于基线模型。

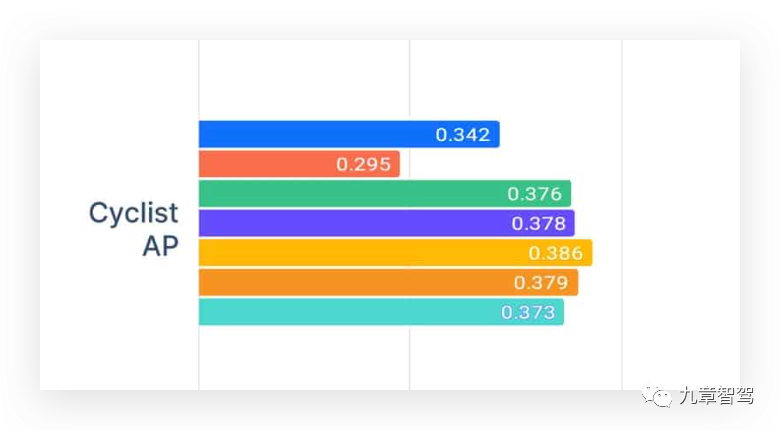
(按类别的 mAP 分数。与 100% 真实世界数据的基线相比,混合训练和微调实验提高了骑行者的 mAP 分数。图片摘自Applied Intution官网。)
在下方的两组图片中,左侧的图片显示,仅根据真实世界数据训练的基线模型无法检测到距自车较近的骑行者,而右侧图片则显示,根据合成数据进行预训练的可以模型成功检测到该骑行者。


可以看到,尽管“过拟合”跟训练数据是真实数据还是合成数据并没有必然关系,但由于合成数据更容易解决“分布比例”的问题,因此,总体上来说,合成数据确实更有可能解决“过拟合”的问题。
在谈到“过拟合”的话题时,谢晨进一步解释说:
“过拟合”是用一个低维的东西去打高维时比较常见的问题,在本质上,这其实是一个小模型的问题,往后看,随着参数量越来越多、模型越来越大,“过拟合”的问题会越来越轻。
谢晨提到,Waymo之前仅感知就有200多个模型,但接下来可能会用1个大模型统领所有这些模型,等大模型出来了,“过拟合”的问题就会大幅度减少。
鉴于真实数据不仅量不够,且使用难度大,对Waymo来说,要训练大模型,就必须依赖合成数据。据悉,Waymo最近计划将合成数据的使用率提升1000倍。
八、给真实数据“加杠杆”
前段时间,在学习合成数据的过程中,笔者突然想到一个问题:莫非,Waymo和Cruise这些美国的无人驾驶公司,坚持“一条道走到黑”、死磕L4的最大底气是,他们在赌合成数据?一旦合成数据对提升算法效果的价值能跟真实数据相媲美,他们就不用再担心“数据不够用”了?
起初,这只是笔者单方面的猜测,但随后,笔者也带着这一猜测跟曾担任过Cruise仿真主管的谢晨做过一些交流,谢晨是认可笔者这一猜测的。
当然了,对真实道路数据不足的L4公司来说,用合成数据去补充、代替或“颠覆”真实数据,或多或少总会有一些无奈的成分在里面。那么,像光轮智能这样的第三方合成数据服务商,是如何给合成数据定位的呢?
谢晨称:
他们并不打算用合成数据取代真实数据(承认合成数据也无法代表现实世界的多样性),而是用合成数据及相关技术来提升真实数据的使用效率。
在主机厂或自动驾驶公司把真实数据提供给他们后,他们可以拿这些数据去基于NeRF技术做3D重建或泛化,并且加上Sim2Real(用Diffusion Model来提升数据保真度),这就把真实数据转换成了合成数据;然后,再在仿真系统里将这些合成数据跟真实数据“混搭”,通过这种“混搭”,以真实数据为主的数据集也间接地具备了“泛化能力”。
事实上,重建后产生新的数据,并且真实数据“混搭”,也是真实数据实现“泛化”的最有效方式。
通过这种“混搭”或泛化,真实数据的使用效率将大幅度上升。
真实数据跟合成数据“混搭”的比例,英伟达等多家公司实践的结果是,7:3(即合成数据占30%)的效果比较理想。
7:3这个比例,相当于在真实数据的基础上再增加了超过40%的数据量,但由于新增的那40%都是合成数据,有很强的泛化能力、可以做N多次排列组合,那么,最终用于算法训练的corner case的数量就不是增加了40%,而是增加了几十倍、甚至是几百倍!
由此可见,合成数据非但不是真实数据的“竞争对手”“颠覆者”,反而还可以给真实数据“加杠杆”“赋能”。
如果能利用好合成数据这个“杠杆”,其他主机厂或自动驾驶公司也有条件拥有“特斯拉量级”的corner case数据。
在聊到这里时,笔者又临时想到了一个问题:这样看来,合成数据公司跟传统做LogSim和WorldSim的仿真公司并不是竞争对手,而可能是合作伙伴?
谢晨说:
没错。我们其实已经跟一些做工具链的公司谈合作了,他们手上有一些真实数据,但这些数据的3D重建、泛化等工作,会交给光轮智能来做。
九、有望“搞定”感知的仿真
当前,自动驾驶行业做的仿真,基本上仅限于规控的仿真,因为,感知的仿真实在太难做了。但过去的两个多月里,笔者在学习合成数据时发现,几乎所有做自动驾驶合成数据的公司,都会拿仿真感知的仿真来举例。
看起来,随着合成数据的日渐成熟,困扰自动驾驶行业很久的感知难题终于有望取得突破了。由于规控的仿真已相对成熟,那一旦感知仿真突破,端到端的仿真就没多大障碍了。
这个主题比较复杂,一两段话也说不清楚,我们将在本系列的第四篇文章中做更详细的分析。敬请期待。
十、使仿真可以真正服务于研发
在过去的一两年里,特斯拉、Waymo、Cruise与英伟达这些公司的仿真部门,服务的对象首先是公司的研发部门,然后才是测试部门;而国内大部分公司的仿真,服务的对象仅限于自己或客户公司的测试部门。
这种区别背后的原因在于,在特斯拉、Waymo、Cruise、英伟达这些公司的仿真,既可以用来做算法的测试验证,也可以用来做算法训练;而国内大部分公司的仿真,只能用来做测试验证。
又是什么导致了这种不同呢?对合成数据的拥抱程度、所使用的合成数据的可用性。
我们在上文已经提到过,真实数据无法泛化、缺乏交互能力,所以,基于真实数据的仿真,只能用于对算法的逻辑做测试验证,而不能用于算法训练。
那么,基于合成数据的仿真,能用来做算法训练吗?这个也得看合成数据的质量了——只有同时满足“泛化能力足够强”和“保真度足够高”这两个标准的才可以。
基于WorldSim的合成数据,保真度无法保证,泛化能力也一般;基于当下大热的NeRF技术生成的合成数据,保真度是没什么问题了,但泛化能力也仅局限于“调整视角/传感器的安装位置”......因此,这些尽管也会被用于算法训练,但效果并不是很理想。
不过,随着AI大模型日渐成熟,并且,大模型在合成数据生成过程中的参与度越来越高,合成数据逐渐具备了同时兼顾保真度和泛化能力的可能性。比如,由Diffusion Model和World Model生成的合成数据。这样的合成数据,就可以用来做算法训练了。
如果能进一步将AI大模型跟NeRF结合起来,那合成数据在算法训练方面可发挥的空间就更大了。这一路线或可帮助那些真实数据不多、但合成数据技术足够强、并且拥抱合成数据也足够积极的公司取得一定的竞争优势,至少是减少他们的劣势。
合成数据,或许正是一直被外界质疑为“数据不够”的Waymo、Cruise和Zoox这些美国公司敢于“一条道走到黑”、死磕L4的底气所在吧。事实上,这几家公司一直将合成数据作为其技术栈的核心组成部分之一。
国内的主机厂中,蔚来通过积极拥抱合成数据,已开始用仿真来支持研发。接下来,随着合成数据的价值赢得越来越多的认可,应该会有更多主机厂拥抱这一趋势吧。
而对第三方仿真公司来说,只有在服务对象从客户公司的测试部门拓展至研发部门,能对算法训练做出自己的贡献时,他们才算是最大程度地实现了自己的“人生价值”。
结语:
我们在前面已多次提到多,数据闭环能力,是自动驾驶下半场的“入场券”。重要的话不嫌多,在这里可以再重复一遍。
合成数据是数据闭环体系的重要组成部分,并且,合成数据不仅具备很多真实数据不具备的优势,而且还可以给真实数据“加杠杆”,因此,我们也可以认为,那些率先拥抱合成数据的公司,等于率先拿到了自动驾驶的“入场券”。
而那些合成数据服务商,则相当于是在生产和销售自动驾驶下半场的“入场券”。
提供这一入场券的公司,在国外,除英伟达这样的巨头外,还有Applied Intution、Parallel Domain、Cognata、Datagen等初创公司。
其中,Applied Inntution成立于2017年,但该公司早在2020年就已经盈利;在2021年底,该公司的估值达到了36亿美元;2023年5月,该公司以7000万美元现金收购了无人驾驶卡车公司Embark。
该公司的业务仅聚焦于自动驾驶这个单一赛道,能在成立三年内就盈利,并在此后估值飙涨,甚至还能拿出足够的现金来收购其他公司,也足见美国自动驾驶驾驶公司及资本市场对拥抱合成数据的积极程度。
在国内,百度、华为云及51World等公司近些年一直在探索合成数据,而在近一两年新成立的公司中,光轮智能是一个典型代表。
创办光轮智能之前,谢晨曾先后担任Crusie仿真主管、英伟达自动驾驶仿真主管、蔚来自动驾驶仿真主管,在各家公司都经历了基于合成数据的仿真从0到1的过程。目前,光轮智能核心技术团队的几名骨干成员也有类似的经历。
虽然成立比较晚,但成立晚有一个优势就是,光轮智能充分吸收了其他公司在自动驾驶仿真方面的一些经验教训,因而,从一开始就避开了很多坑。谢晨认为,仿真要做好,必须“虚实结合”,并且,比较要要将仿真跟AI深度结合。
关于仿真跟AI的结合,谢晨说:
目前,大多数公司的做法是用AI来辅助仿真,而我们的思路在则是用仿真来辅助AI。
那么,究竟什么是“虚实结合”,什么是“用AI辅助仿真”,什么又是“用仿真辅助AI”呢?这些内容,我们将在本系列的第二篇文章中做更详细的展开。敬请期待。
参考资料:
自动驾驶数据闭环系列之一:理想丰满,现实骨感
https://mp.weixin.qq.com/s/A4bLFRdIfYwG81LBanJDYg
Synthesis AI raises $17M to generate synthetic data for computer vision
https://techcrunch.com/2022/04/28/synthesis-ai-raises-17m-to-generate-synthetic-data-for-computer-vision/
10 Top Synthetic Data Startups to Watch in 2023
https://www.startus-insights.com/innovators-guide/synthetic-data-startups/
Synthetic Data - Generative AI's killer application
https://www.linkedin.com/pulse/synthetic-data-generative-ais-killer-application-sriraman-sri-/
Building continuous integration & continuous delivery for autonomous vehicles on Google Cloud
https://cloud.google.com/blog/products/containers-kubernetes/how-cruise-tests-its-avs-on-a-google-cloud-platform
Is Synthetic Training Data the Future of Machine Learning?
https://www.ayadata.ai/blog-posts/is-synthetic-training-data-the-future-of-machine-learning
Cruise 制定了“如何”使机器人出租车成为现实的计划
https://techcrunch.com/2021/11/05/cruise-lays-out-its-plan-for-how-it-will-make-robotaxis-a-reality/?
使用可编程数据教学家庭机器人
https://medium.com/toyotaresearch/teaching-home-robots-73f7d5e3601f
SPIGAN: PRIVILEGED ADVERSARIAL LEARNING FROM SIMULATION
https://openreview.net/pdf?id=rkxoNnC5FQ
Scale AI 进入合成数据游戏
https://techcrunch.com/2022/02/02/scale-ai-gets-into-the-synthetic-data-game/
Scaling up Synthetic Supervision for Computer Vision
https://medium.com/toyotaresearch/scaling-up-synthetic-supervision-for-computer-vision-902689d16216
Browse a collection of synthetic data tools and companies
https://syntheticdata.carrd.co/
Synthetic Data for Safe Driving
https://synthesis.ai/2021/08/05/synthetic-data-for-safe-driving/
合成数据概述:技术、应用和市场状况
https://actvp.vc/stories/tpost/ghgm11emt1-overview-of-synthetic-data-technology-ap
CARLA-GEAR: A Dataset Generator for a Systematic Evaluation of Adversarial Robustness of Vision Models
https://arxiv.org/pdf/2206.04365.pdf
适合决策AI研究的自动驾驶模拟器评测
http://www.rlchina.org/topic/343
https://zhuanlan.zhihu.com/p/548771774
Introducing UniSim, one of the core groundbreaking technologies powering Waabi World
https://waabi.ai/introducing-unisim-one-of-the-core-groundbreaking-technologies-powering-waabi-world/
适合决策AI研究(强化学习)的自动驾驶模拟器
https://zhuanlan.zhihu.com/p/548771774
Generative AI-empowered Simulation for Autonomous Driving in Vehicular Mixed Reality Metaverses
https://arxiv.org/pdf/2302.08418.pdf
[CVPR2023 Highlight] UniSim: 自动驾驶仿真系统
https://zhuanlan.zhihu.com/p/636695025
如何评价CVPR 2023的best paper?
https://www.zhihu.com/question/607381076/answer/3084877656
端到端的胜利!CVPR23 里的自动驾驶:UniAD&UniSim
https://mp.weixin.qq.com/s/hdjnF86R-30k2SFK1dSKBA
Quantifying the Simulation–Reality Gap for Deep Learning-Based Drone Detection
https://www.mdpi.com/2079-9292/12/10/2197
SYNTHETIC DATASETS FOR AUTONOMOUS DRIVING: A SURVEY
https://arxiv.org/pdf/2304.12205.pdf
Synthetic Data and Autonomous Vehicles
https://natecibik.medium.com/synthetic-data-and-autonomous-vehicles-408748e5bbb0
UC Berkeley, Waymo & Google’s Block-NeRF Neural Scene Representation Method Renders an Entire San Francisco Neighbourhood
https://medium.com/syncedreview/uc-berkeley-waymo-googles-block-NeRF-neural-scene-representation-method-renders-an-entire-san-e9a5aebd8823
Waymo Releases Block-NeRF 3D View Synthesis Deep-Learning Model
LIKEDISCUSSPRINT
https://www.infoq.com/news/2022/02/waymo-NeRF-3D-view-synthesis/
Block-NeRF AI recreates a virtual San Francisco neighborhood using 2.8 million photos
https://www.dpreview.com/news/2152415204/block-NeRF-ai-recreates-a-virtual-san-francisco-neighborhood-using-2-8-million-photos
使用特定于传感器的合成数据开发自主系统
https://anyverse.ai/synthetic-data/developing-an-autonomous-system-with-sensor-specific-synthetic-data-wrapping-up/
Synthetic data to develop a trustworthy autonomous driving system | Chapter 10
https://anyverse.ai/artificial-intelligence/synthetic-data-to-develop-a-trustworthy-autonomous-driving-system-chapter-10/
Gathering data for autonomous driving in adverse weather conditions
https://anyverse.ai/synthetic-data/gathering-data-autonomous-driving-adverse-weather-conditions/
Synthetic data for Computer Vision
https://www.cvedia.com/what-is-synthetic-data
什么是生成对抗网络(GAN)与合成数据
https://www.xulong.net.cn/gan-synthetic-data-22970/
如何获得用于自动驾驶训练的可靠合成数据?
https://www.zhihu.com/question/507527196/answer/2280153792
合成数据在实现 ADAS 和自动驾驶方面发挥真正作用
https://zhuanlan.zhihu.com/p/420690863
使用合成数据实现自动驾驶摄像感知系统聚焦远场物体
https://zhuanlan.zhihu.com/p/635265463
Waymo is using AI to simulate autonomous vehicle camera data
https://venturebeat.cohttps://zhuanlan.zhihu.com/p/635265463m/ai/waymo-is-using-ai-to-simulate-autonomous-vehicle-camera-data/
一文看懂DRIVE Replicator:合成数据生成加速自动驾驶汽车的开发和验证
https://developer.nvidia.com/zh-cn/blog/drive-replicator-synthetic-data-generation/
Synthetic Data Is About To Transform Artificial Intelligence
https://www.forbes.com/sites/robtoews/2022/06/12/synthetic-data-is-about-to-transform-artificial-intelligence/?sh=3ef44ce07523
Parallel Domain says autonomous driving won’t scale without synthetic data
https://techcrunch.com/2022/11/16/parallel-domain-says-autonomous-driving-wont-scale-without-synthetic-data
Accelerate Your AI Progress with Synthetic Data: 10 Reasons to Start Now
https://paralleldomain.com/accelerate-your-ai-progress-with-synthetic-data
Creating Synthetic Data with Nvidia Omniverse Replicator
https://docs.edgeimpulse.com/experts/featured-machine-learning-projects/nvidia-omniverse-replicator
Nvidia launches Omniverse Replicator synthetic data generation engine
https://www.automotivetestingtechnologyinternational.com/news/nvidia-launches-omniverse-replicator-synthetic-data-generation-engine.html
NVIDIA 表示 Isaac Sim 和 Isaac Replicator 缩小了模拟与现实的差距
https://www.robotics247.com/article/nvidia_says_isaac_sim_isaac_replicator_close_the_simulation_to_reality_gap
NVIDIA Omniverse Replicator For DRIVE Sim Accelerates AV Development, Improves Perception Results
https://www.publicnow.com/view/A8150FC0BEFC3CEE97CBE49002A74711959E1F11
When Real-World Data is Not Enough
https://www.digitalengineering247.com/article/when-real-world-data-is-not-enough
Synthetic Data Generation Using Omniverse
https://medium.com/weboccult-technologies/synthetic-data-generation-using-omniverse-2f6d7039d386
NVIDIA Omniverse Replicator Generates Synthetic Training Data for Robots
https://developer.nvidia.com/blog/generating-synthetic-datasets-isaac-sim-data-replicator/
使用 Omniverse Replicator 构建自定义合成数据生成管道
https://developer.nvidia.com/blog/build-custom-synthetic-data-generation-pipelines-with-omniverse-replicator/
How to Generate Synthetic Data with NVIDIA DRIVE Replicator
https://www.nvidia.com/en-us/on-demand/session/gtcspring23-se50004/
一文看懂DRIVE Replicator:合成数据生成加速自动驾驶汽车的开发和验证
https://developer.nvidia.com/zh-cn/blog/drive-replicator-synthetic-data-generation/
The rising role of synthetic data in the automotive industry
https://www.automotivetestingtechnologyinternational.com/industry-opinion/the-rising-role-of-synthetic-data-in-the-automotive-industry.html
Case Study: Improving Object Detection Performance by Leveraging Synthetic Data
https://blog.applied.co/synthetic-data-for-training
Introducing GAIA-1: A Cutting-Edge Generative AI Model for Autonomy
https://wayve.ai/thinking/introducing-gaia1/
MARS: An Instance-aware, Modular and Realistic Simulator for Autonomous Driving
https://arxiv.org/pdf/2307.15058.pdf
对抗生成网络(Generative Adversarial Net)
https://blog.csdn.net/stdcoutzyx/article/details/53151038?ydreferer
上海AI Lab | 最新端到端自动驾驶综述,来龙去脉详尽梳理
https://mp.weixin.qq.com/s/X6d2kjzr7Bhdx0-FZvw3Vw
浅谈基于NeRF的三维重建技术
https://www.eefocus.com/article/1545527.html
反渲染(Inverse Rendering)三维重建及神经辐射场(NeRF)核心
https://zhuanlan.zhihu.com/p/628804009
【NeRF】AIGC高阶魔法——3D场景重建与渲染
https://zhuanlan.zhihu.com/p/615875635
炸锅了,竟有这种好东西,那我可不困了!
https://course.zhidx.com/download/detail/NjUyYmQxZjU4N2JmZjliNzZlMjM=
改进扩散模型作为 GAN 的替代方案,第 1 部分
https://developer.nvidia.com/blog/improving-diffusion-models-as-an-alternative-to-gans-part-1/
Diffusion预训练成本降低6.5倍,微调硬件成本降低7倍!Colossal-AI完整开源方案低成本加速AIGC产业落地
https://www.dazuoshe.com/diffusionyuxunlianchengbenji.html
Diffusion Model一发力,GAN就过时了???
https://www.163.com/dy/article/HF7L02FJ0511DSSR.html
diffusion model 最近在图像生成领域大红大紫,如何看待它的风头开始超过 GAN ?
https://www.zhihu.com/question/536012286/answer/2533146567
AIGC 和自动驾驶会有关系吗?
https://zhuanlan.zhihu.com/p/593475163
World Model揭开自动驾驶GPT时代的面纱
https://zhuanlan.zhihu.com/p/642207999?utm_id=0