目录
- 前置知识
- 循环依赖的产生
- Spring里面的3个Map
- 课程内容
- 一、只有一级缓存的推理演进
- 1.1 直接将实例化后生成的对象放入到单例池里面
- 1.1 引入一个中间Map存实例化后的早期对象(疑似二级缓存)
- 1.3 解决1.2需要被代理的问题(疑似二级缓存)
- 1.4 为什么要三级缓存
- 学习总结
前置知识
循环依赖的产生
说到循环依赖大家都不陌生,循环依赖的代码,就是如下:
@Component
public class CircularA {@AutowiredCircularB b;
}@Component
public class CircularB {@AutowiredCircularA a;
}但是大家有没有想过,循环依赖是如何产生的,然后又是怎么解决的呢?这里,我想给大家推演一下,就像咱是Spring作者一样,思考如何循环依赖。
Spring里面的3个Map
在这里,我还是想提前给大家先大概解释一下,在获取单例bean的时候,Spring源码出现的3个Map。分别如下:
Map<String, Object> singletonObjects:一级缓存。这个就是我们常说的单例池,这里存放的bean,是经历了完整Spring生命周期的,【走完了Spring所设计的生命周期】(这里的经历完整生命周期不是说非得要经历什么实例化前后、初始化前后。简单说,是:Spring认可的,成熟的Bean)Map<String, Object> earlySingletonObjects:二级缓存。直接直译过来,这里存的是【早期单例Bean】。何为早期?就是相对前面的【成熟Bean】,【还没有走完生命周期】的Bean。Map<String, ObjectFactory<?>> singletonFactories:三级缓存。直译过来是【单例bean的工厂】。其实我还是喜欢用一个之前提到过的专有名词去解释:生产Bean的钩子方法缓存。
课程内容
一、只有一级缓存的推理演进
我们先来看个图,在没有三级缓存之前,只有一个一级缓存的时候,如果A依赖了B,B依赖了A,那么就会造成下面的现象:
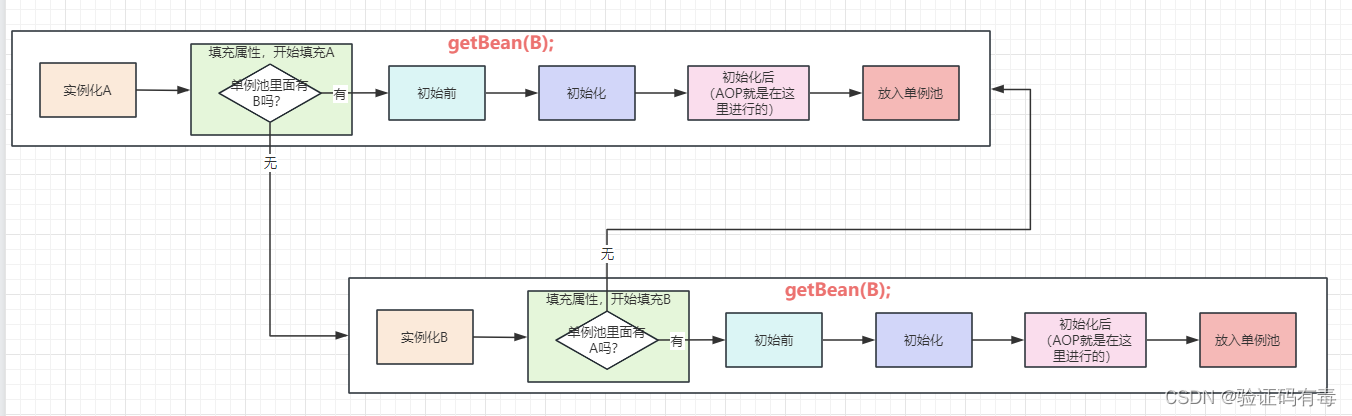
很显然,在我们刚开创建的过程中,单例池里面是不会有对象B,也不会有对象A的。毕竟它们才走到第二步【注入属性】,它是在最后一步才会把生成好的对象放入单例池中。所以,上图的情况,如果没有外部干预的话,在这两个bean之间就形成了一个闭环,无法解开了。这显然不是我们想要的结果,对吧。那这个问题该如何解决呢?
1.1 直接将实例化后生成的对象放入到单例池里面
这时候一个很正常的想法是,我提前放入到单例池里面不就行了吗,如下所示:
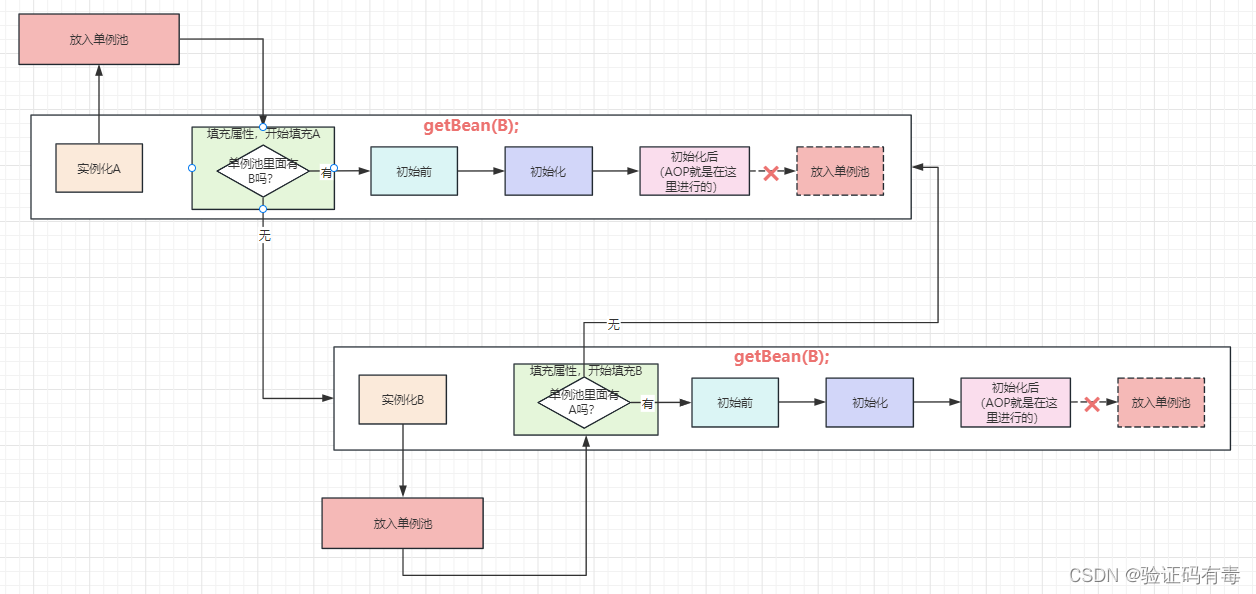
这样不就打破了吗?嘿嘿嘿
只能说有点道理,但不多。因为,在多线程环境下,可能会把【没初始化完】的bean暴露出去。这时候如果有人来访问单例池,直接拿到了这个BeanA,然后去调用里面的方法,在没有【属性注入】过的情况下,不就G了吗?是的,这就是并发安全问题!这里只能直接pass这个方案了
1.1 引入一个中间Map存实例化后的早期对象(疑似二级缓存)
一个很正常的思考,我新增一个Map,在实例化后即刻存起来不就得了呗。反正都已经实例化了,地址已经固定了,后面再怎么操作都是对这个地址上的对象操作,提前把这个对象暴露出去,完全不影响结果啊。
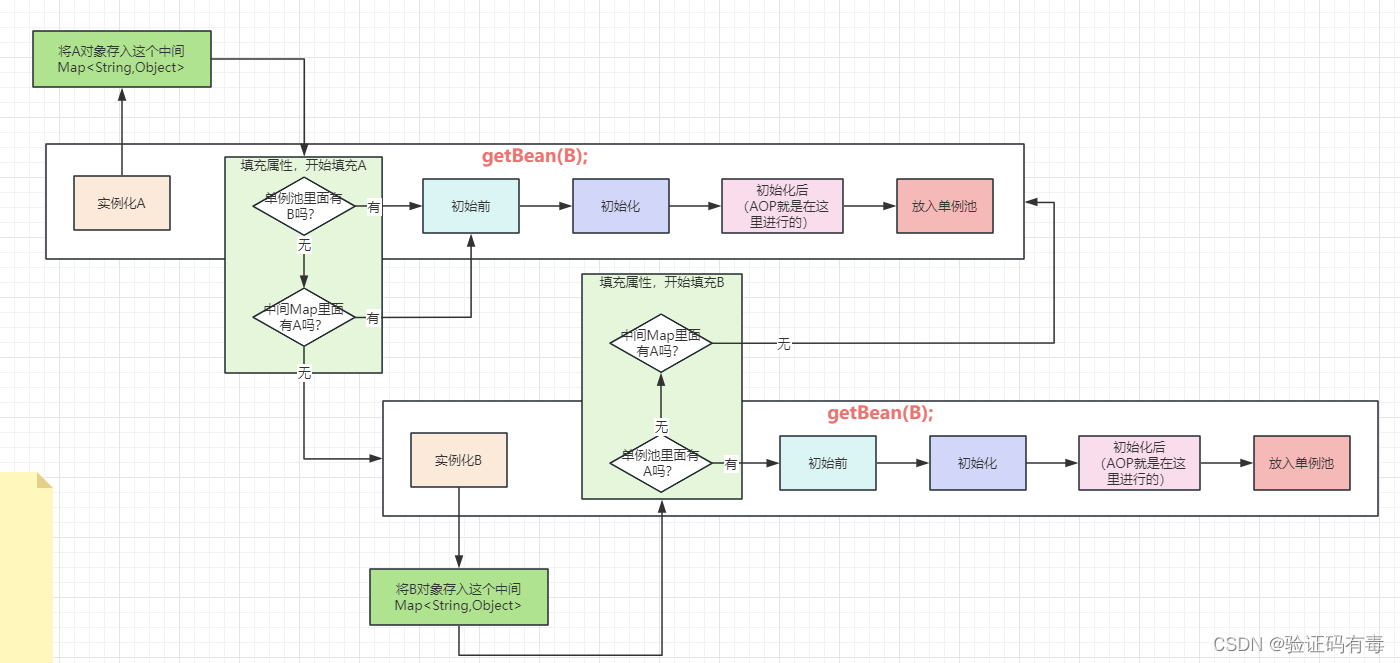
如上图所示,那我新增一个中间缓存Map来存储之前实例化后的对象,总可以吧?嗯,从流程图上来看,这个真的好像是最终答案了。
不过,如果这时候我问你【AOP在哪?】,阁下将如何应对呢?很显然啊,这里存放的是原始对象,那如果我需要的是被代理的对象呢?看吧,这样稍微一推敲,又出现问题了。那好,我们继续完善这个方案就是了
1.3 解决1.2需要被代理的问题(疑似二级缓存)
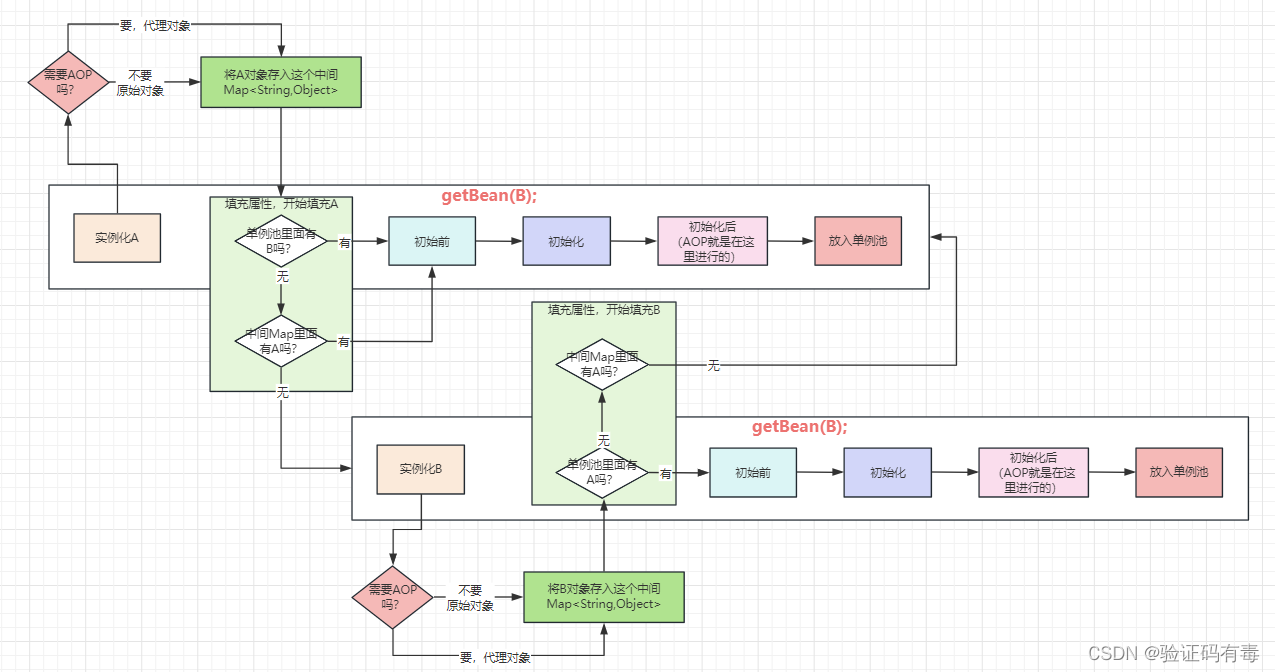
就这样,多加上一步AOP过程不就行了嘛,嘿嘿嘿。不过按照惯例,我已经【嘿嘿嘿】了,所以肯定得问一句:真的行吗?哈,真的行!确实没问题了。那为什么,还要三级缓存呢?
1.4 为什么要三级缓存
讲到这里,我就要开始装逼了。(我甚至怀疑Spring这么写也是在【装逼】,哈哈,开个玩笑)

其实这个网上挺多论调的,我也是总结了百家之长,再结合我课堂上老师说的,总结出了以下结论:(算是个人之见,大家参考一下)
- 生命周期被打破!这个我认为是最重要的原因,但是也比较难被理解的一点。怎么理解呢?大家还记得我以开始怎么形容Spring的吗?Spring的核心是什么?大家知道AOP的实现是在一块吗?
- 第一个问题:Spring是实现了AOP技术的IOC容器
- 第二个问题:Spring的核心是IOC跟AOP,但是,所有的基础都来自于IOC
- 第三个问题:AOP的实现,是在bean生命周期的【初始化后】阶段。因为,AOP技术目前的实现,也是基于Spring提供的众多拓展点里面的某些个而已。比如AOP的实现就使用了:BeanPostProcessor。这里透露出来的意思是什么呢?我认为,它的意思是:在Spring内部,都只是把AOP当作额外拓展而已。就好像是我们基于Spring的拓展点实现了Mybatis,实现了SpringMVC一样的道理。
PS:所以到了这里大家伙知道这个【生命周期被打破】如何理解了吗?如果我们在实例化后就做判断是否需要做AOP的话,等于,还没【属性注入】,还没做【初始化前】、【初始化】、【初始化后】等等生命周期呢,就要开始了。并且呀,在实现这个AOP的过程中,你还得调用类似如下的方法:
for(BeanPostProcessor bp : this.beanPostProcessorsCache) {bp.postProcessAfterInitialization(bean); }但是这个代码,其实在后面的【初始化后】也会被调用的。我猜有的朋友会这么说:那我循环遍历实现了AOP的那几个指定的,实现了AOP的BeanPostProcessor不就行了吗?嗯,说实在确实行。不过,如果我们站在Spring的角度来看:AOP不过也是我IOC的一个拓展内容而已。这么来看的话,这么实现就侵入有点大了,而且语义上也稍微变了。
- 循环依赖出现频率。我想我呢问大家,你在实际使用场景中,循环依赖出现的多吗?弟弟我写Java代码4年多,我印象中就几次而已。so,你看看上面的解决方案如何?它每一次实例化生成Bean之后都做了判断!是否有点多余呢?
- 代码风格!说这个就很抽象了,但是对于Spring这种优秀的源码来说又有点情有可原。这句话怎么理解呢?
其实2、3要结合起来,一起建立在【1】最后的挣扎上,即我还是要在【实例化】完成后就开始判断是否需要AOP。