文章目录
- 一. 前言
- 二. 从宏观层面看页
- 三. 页的基本内容
- 3.1 页的数据结构
- 3.2 用户空间内的数据行结构
- 3.3 页目录
- 四. 问题集
- 4.1 索引 和 数据页 有什么区别
- 4.2 页的大小是什么决定的
- 4.3 页的大小对哪些情况有影响
- 4.4 一般情况下说的链表有哪几个
- 4.5 如果页的空间满了怎么办
- 4.6 如果页的空间空了怎么办
- 4.7 删除的数据何时被清理
- 4.8 数据页和B+树及索引的关系
- 总结
- 附录
- 参考文档
一. 前言
周末没啥计划,把大佬的<MySQL是怎样运行的>又翻了出来,重新学习一下页的概念。
页这个东西,看起来不怎么显眼,但是深层的东西都会碰到他,又爱又恨,逼着人必须弄懂。
二. 从宏观层面看页
高并发里面有一种提高性能的思路是 :通过批处理一次性处理大量数据,避免频繁的网络流量和IO。
MySQL 的页就是基于这种概念,磁盘是存放数据的载体,而数据处理会发生了内存中,所以流程大致分为:
- S1 : 首先对数据进行切分,划分成若干页
- S2 : 每次读取的时候,都直接把一整页读取到内存中
- S3 : 外部读取的时候,直接对内存中的数据进行读取和操作
- S4 : 如果发生了修改操作,需要把内存的内容刷新到磁盘上
页的好处
这里比较模糊的是为什么要衍生出一个页,而不是通过行级别进行处理。
- 首先解决的就是 IO 问题,当然如果说每个页只读一条,那么这种就不算优势,但是我们大批量读取的时候,往往是查询连续的数据 , 相对而言取舍后,效率就更高了。
- 避免碎片化,行的级别太低了,大小也不同,使用行的时候,存储空间不便于分配
- 提高并发和锁,可以通过控制事务到一个页里面,减少事务的粒度
- 提高维护性和通用性 ,当发生重整时,页的处理会更简单
三. 页的基本内容
页的概念与索引关联的概中主要包括 :
- 页 (Page): 页是数据存储的基本单位,是一个固定大小的数据块,通常是16K
- 行 (Row): 行是数据库中的基本数据单位 ,代表表中的一个记录
- 分组(Group):将一个页里面除了删除的记录进行逻辑划分,取每组最后一条记录作为偏移量标志位
- 槽(Slot):每个分组的最后一条数据会在页目录里面作为一个指针存在,这个指针就是一个槽
页目录 (Page Directory):用来管理数据页的一种数据结构,目录内记录了指针,索引等位置信息
3.1 页的数据结构

- File Header 和 Page Header 包含了该页的基础属性和状态信息等
- Infimum / Supremum 是虚拟的行记录,用于限定记录的边界,他们都是虚拟的,不表示任何存在
- Infimum 标识比该页任何值都要小的值
- Supremum 标识比该页任何值都要大的值
- 用户记录和空闲记录是实际的存储空间,随着插入数据空闲空间会越来越小
- 页面目录用来存储记录的相对位置,通过稀疏目录的方式加快了查询的数据
- File Trailer 目的是为了保证数据的完整性,其中会存放一个校验和保证数据是正确的
插入数据带来的结构变化
3.2 用户空间内的数据行结构
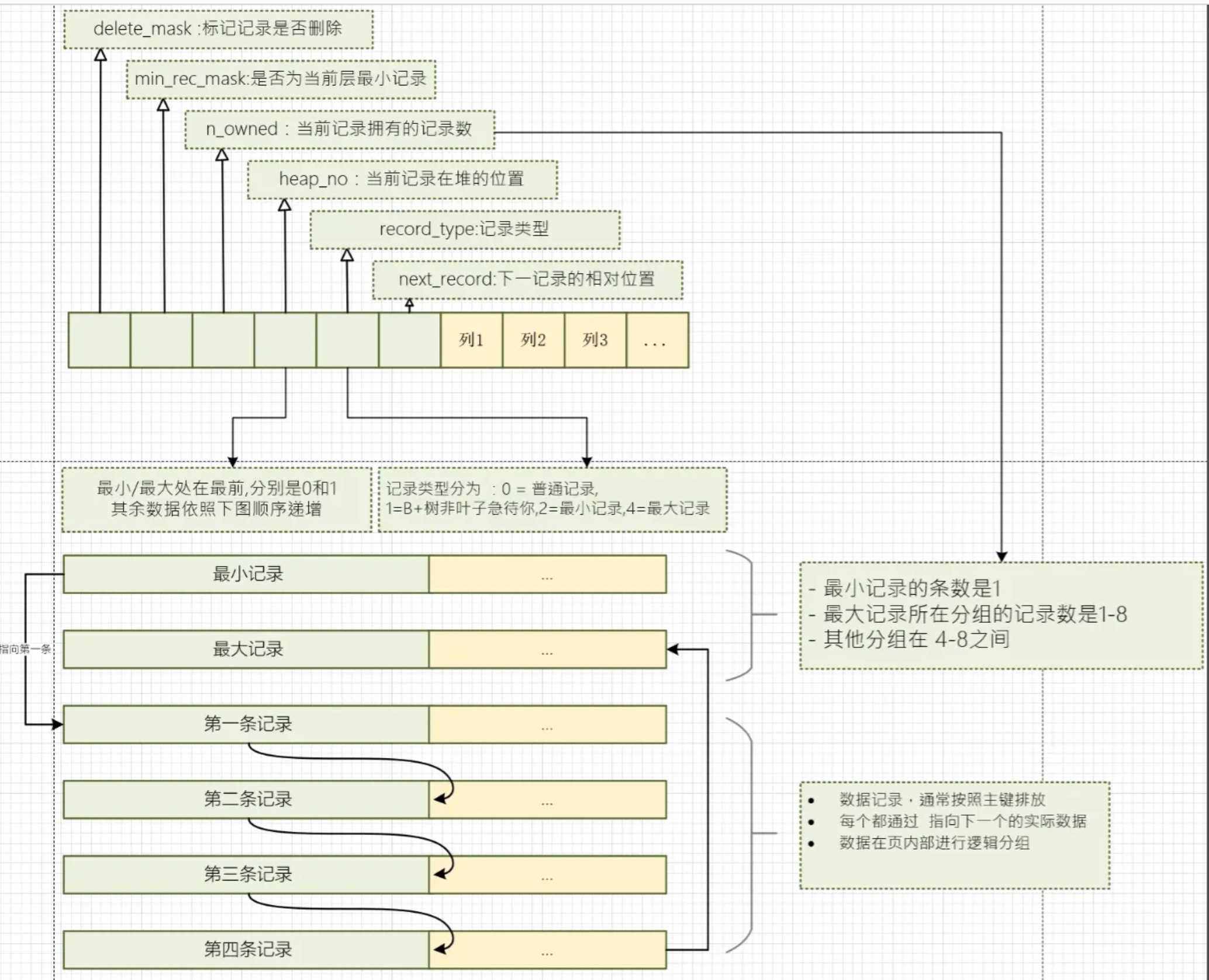
其中主要的参数是 :
- n_owned:当前记录拥有的记录数 ,通过该数据来确定每组数据的大小
- heap_no:当前记录在堆的位置,最小和最大的heap_no 分别是 0,1 ,标识在最上面
- next_record:下一记录的相对位置 , 用于保证数据成一个链表结构
3.3 页目录
我们或多或少都接触过数组或者集合,对于数组的查询方式有很多,正序或者逆序,或者效率更高的二分法
前提 : MySQL 的数据按照行记录进行存储,在一个表中,行的数据是有序的
目录 :但是不论多么优良的算法,在大数据量的场景下,还是会有很高的性能损耗,而 MySQL 为了解决这种场景,采取的是目录的方式。 目录中通过槽和分组,得到了一个数据的精简模型,通过精简的数据快速查询对应的分组,再在分组里面进行循环查找
槽和分组
有个资料里面说的是一个数据行就对应一个槽,也有说多个记录一个槽,我这里倾向于后一种说法,即稀疏目录。
页目录存放了记录的相对位置,每个相对位置即为一个槽,在InnoDB 里面是使用稀疏目录 (sparse directory), 即一个槽会属于多个记录 (4-8条)
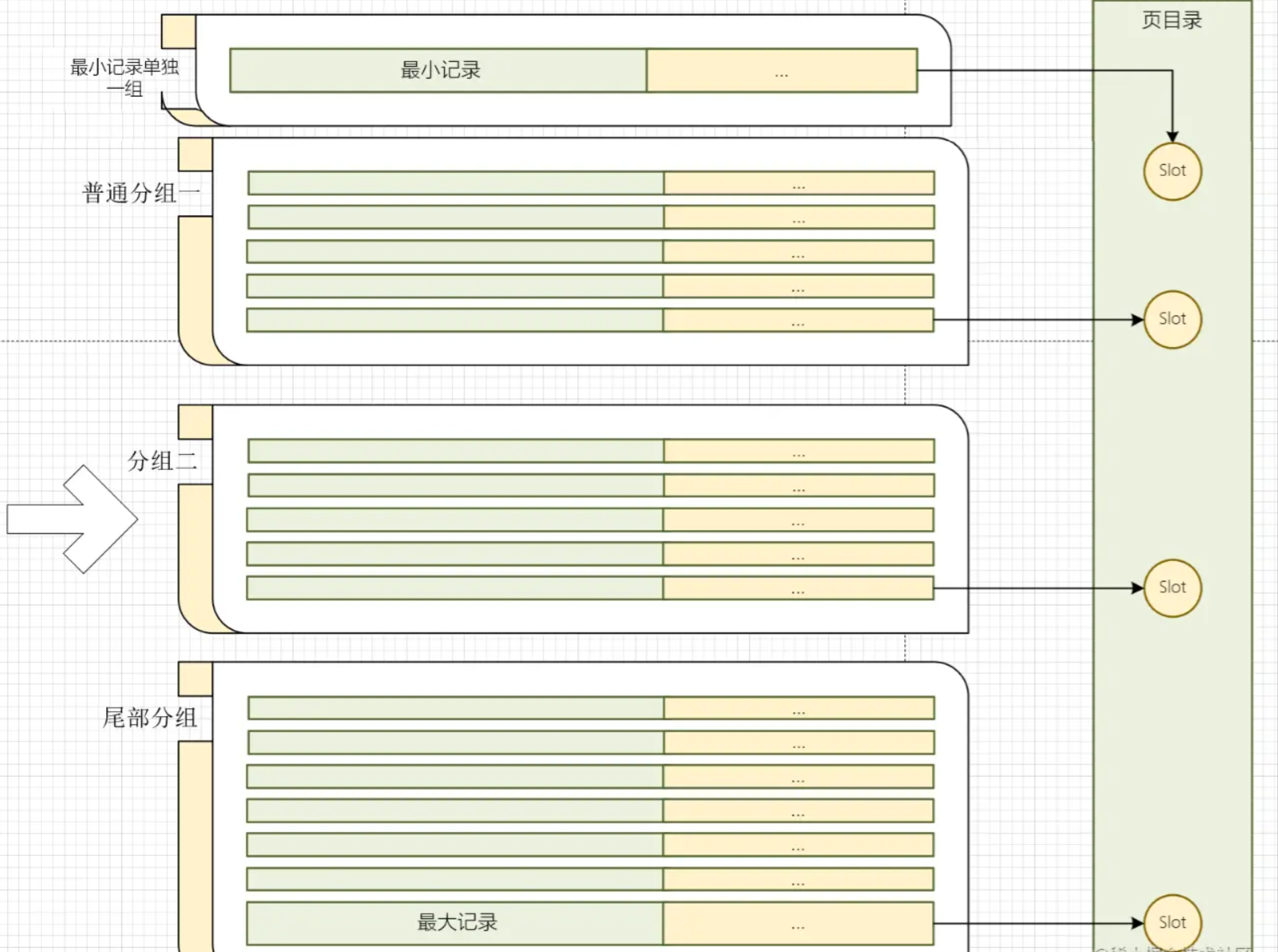
-
最小记录的条数是1
-
最大记录所在分组的记录数是1-8
-
其他分组在 4-8之间
-
指向原理
- 查询数据时,首先通过二分法在页目录中进行查询
- 当查询到分组范围后,再通过分组里面的 next_record 查询具体的数据
四. 问题集
4.1 索引 和 数据页 有什么区别
- 两者不是同一个东西,存储的数据和结构都不同
- 在索引中,每一个 B+树节点对应一个索引页,一个索引页中存储索引键值和指向指针
- 数据查询时,通过根索引页开始,遍历索引树,从而拿到指向数据行的指针
- InnoDB 会通过索引中的数据行指针定位到数据页 (直接通过物理地址指向槽号)
除了这些页,InnoDB 中还有存放表空间头部信息的页,Buffer 页等。
4.2 页的大小是什么决定的
- 页的大小是由创建数据库表时指定的存储参数 innodb_page_size 决定的
- 参数一旦设置就不能更改,不然就得刷页里面大量的数据
CREATE TABLE my_table (...) ENGINE = InnoDB ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8 PAGE_COMPRESSED=1 PAGE_SIZE=64K;
4.3 页的大小对哪些情况有影响
- 索引效率 :前面说了,索引过程中会通过每页的最大最小进行快速匹配,而较大的页一定程度上会使相同数据量情况下拥有更少的页,从而降低索引节点的数量,索引树高度也因此降低。查询效率会有所提高
- 内存占用 :较大的页会在内存中占用更多的空间。因为读取时,每次都是读取一整页,所以内存每次读取得更多。
- 其他硬件影响 :更大的页会影响磁盘IO和CPU,IOPS 方面都会带来更多的压力
总结 :提高效率,但是增加了系统负载。
4.4 一般情况下说的链表有哪几个
一个列里面的数据行之间通过 next_record 形成的单向链表
上文说到了每个数据行上面会有个 next_record 参数,该参数记录了真实数据达到下一条记录的真实数据的偏移量,这里有几点值得注意 :
- 这里的顺序不是插入数据,而是主键值由小到大的顺序
- 上一条指向的是下一条的value的位置,而不是 Header 头的位置

不同数据页之间组成的双向链表
上面的结构图看过了,每个页里面都会包含 File Header 和 Page Header 两个对象。
- Page Header : 记录当前页的状态信息和规则,例如槽数,记录数,剩余空间数等等
- File Header : 记录当前页的标准信息,包括页的编号,页所在的表空间,上一页页号和下一页页号
而**双向成方式不言而喻,都知道上页 (FIL_PAGE_PREV) 和 下页(FIL_PAGE_NEXT)的页号了,那访问完全没问题了 , 由于都只存了上一个和下一个,也就形成了标准的链表结构。
补充 : 上面看到的这种通常是指 LRU 链表,还有一个双向链表是 Flush List (刷新链表),这个链表是在数据页发生修改后,使用刷新链表可以让数据按照一定的顺序刷新到磁盘上
4.5 如果页的空间满了怎么办
- 首先,页的的大小是在存储引擎创建的时候就确定了,所以空间固定。
- 其次页内数据是按照主键进行排序,所以这个时候插入铁定空间超了
在这种场景下,会触发页分裂 ,此时 InnoDB 会执行下列操作 :
- S1 : 创建新的数据页
- S2 : 按照排序方式将部分数据迁移到新页
- S3 : 更新上下页关系和对应的索引关系
这里由于页是双向链表进行的关联,所以插入并不会对数据结构进行大的破坏,只需要对应的上下页进行更新就行了。
4.6 如果页的空间空了怎么办
既然会有页分裂,那就有可能会出现分裂的页不均衡的情况,长时间下去,就会形成很多空闲块,这样的结构也是不合理的,不仅会占用不必要的空间,还会导致查询性能降低。
为了避免这些问题,InnoDB 会有页合并的功能 , 原理和上面的类型。相邻页尝试合并,然后重新更新引用和索引。
4.7 删除的数据何时被清理
之前看到了数据被删除后,其目录数据里面的 delete_mask 会被置为已删除。
此时的数据处在逻辑删除的状态,通过上面说的 next_record (下一记录的相对位置)指向后续存在的正常数据。
这样做的目的主要是避免碎片,提高删除的性能(只需要修改标识和引用),同时保证了删除的事务。
但是长此以往就会有大量的删除数据占用空间,为了避免这种情况,InnoDB 会定期的进行清理,同时重新整理数据页。
4.8 数据页和B+树及索引的关系
-
数据页是为了存储数据行的,存放的是二进制数据,通常数据行按照主键的顺序存放
-
B+树是一种数据结构,也是索引的结构,B+树结构让索引更加有效和便于管理
-
索引中的B+树叶子节点存储了索引条目,每个条目对应一个数据行的物理指针(通常是数据行的槽号)
- 当获得槽号后,就直接通过槽号读取想要的数据,并且返回
页和索引是相辅相成的,如果没有索引,页就需要在单向链表里面向下寻找,直到找到对应的数据
总结
页是存储的基础,也是索引的基础,了解了页后面就可以深入的了解索引了。
这一块没了解太深,毕竟这东西其实我应用的场景几乎没有,主要是不弄清楚后面读起来很难受。
尽量做到了自己去输出东西,整理了一些问题,但是毕竟站在别人修好的路上面,有些东西不能保证一定是对的,也有可能是我理解有误,如果有问题建议去看原文或者官方文档。
附录
头部信息对于我们日常业务中几乎是没太大用的,这里只记录几个我认为和上文有一定关联的参数 :
-
页头部信息
- PAGE_N_DIR_SLOTS : 页目录中的槽数量
- PAGE_N_HEAP : 本页中的记录数量
- PAGE_GARBAGE : 已删除记录中的字节数
- PAGE_LAST_INSERT :最后插入记录的位置
- PAGE_DIRECTION :记录插入的方向
- PAGE_N_RECS : 该页中记录的数量
- PAGE_LEVEL : 当前页在 B+树中所处的层级
- PAGE_INDEX_ID : 索引ID
-
文件头部信息
- FIL_PAGE_OFFSET : 页号
- FIL_PAGE_PREV : 上一个页的页号
- FIL_PAGE_NEXT : 下一个页的页号
- FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID : 页属于哪个表空间
参考文档
-
小册 : MySQL是怎样运行的
-
MySQL 技术内幕