目录
获得 HA 的方法
一 没有高可用性 (No high availability)
使用场景
架构组成
架构图
二 半高可用性(Semi HA)
四 基于Raft协议高可用
五 方案对比
注意事项
笔记
orchestrator作为高可用的服务运行。本文档列出了orchestrator实现 HA 的各种方法
获得 HA 的方法
HA 可以通过选择以下任一方式来实现:
orchestrator/raft设置,orchestrator节点通Raft 共识算法进行通信。每个orchestrator节点都有一个私有数据库后端(MySQL或sqlit)。另请参阅Orchestrator/raft 文档- 共享后端设置。多个
orchestrator节点都与同一个后端数据库通信,该后端可能是 Galera/XtraDB Cluster/InnoDB Cluster/NDB Cluster。同步是在数据库级别完成的。
一 没有高可用性 (No high availability)
使用场景
这种适用于测试。本地开发环境。
架构组成
这种架构由 单个orchestrator节点和单个后端数据库组成。
后端数据库可以是MySQL也可以是orchestrator自带的sqlite。
架构图

二 半高可用性(Semi HA)
这种架构只有orc服务有高可用行,后端数据库没有高可用行
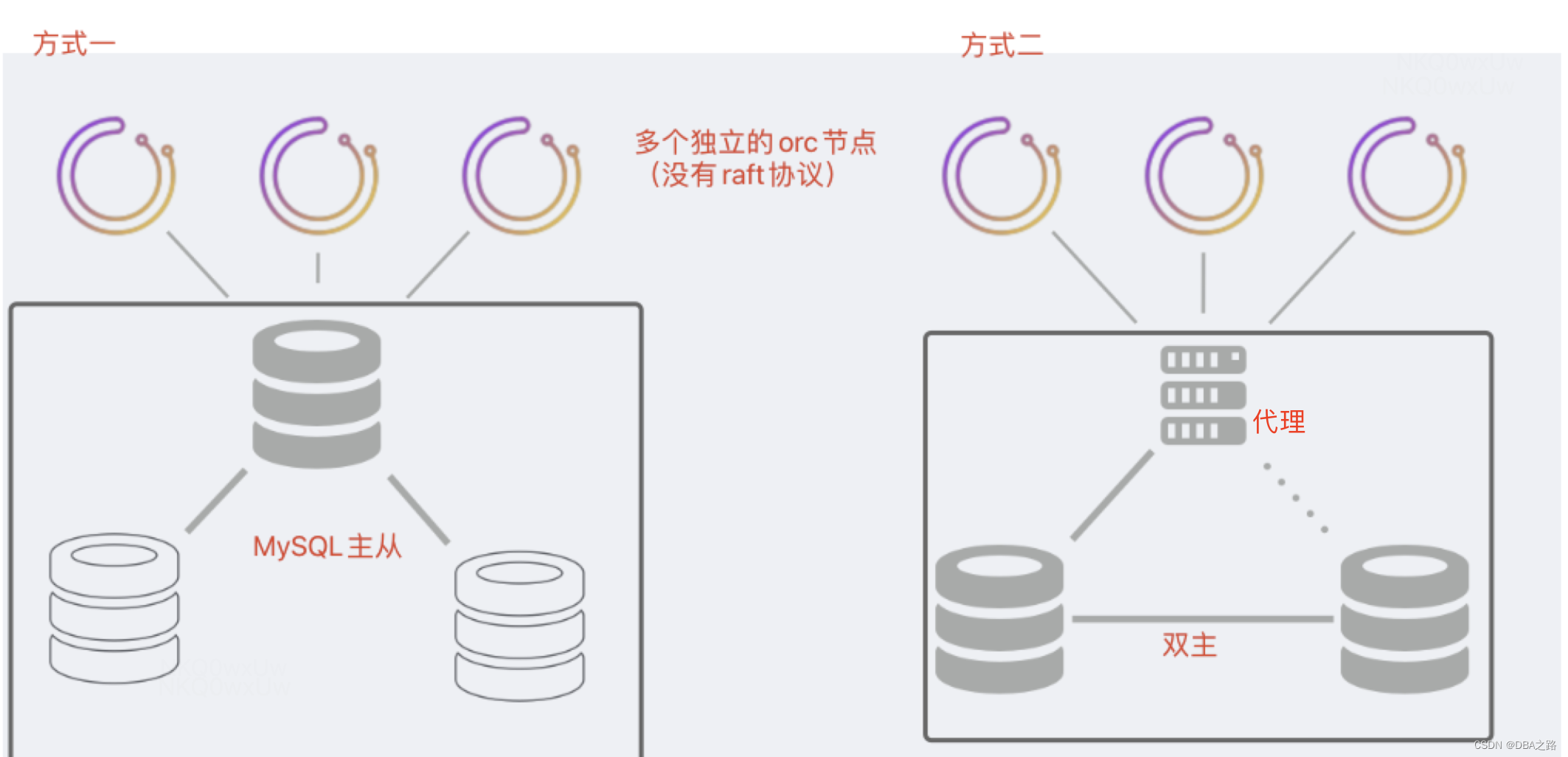
方式一
多个orc节点使用MySQL主从中的master。orc 服务实现了高可用,但是后端数据库却没有。后端数据库是主从架构,每个orc节点不能有自己单独的后端数据库。如果后端数据库的master无法进行故障转移
方式二
多个orc节点使用都配置为代理层的IP 。代理层后端是MySQL双主架构,并且双主架构复制规则设置为statement。
- 代理层一直指向同一个MySQL节点,除非这个MySQL发生了故障
- master 宕机后 orc就会通过代理层去访问另一个数据库节点。但是这个数据库节点数据可能有落后,orc会补充这些丢失 通过持续发现的特性。
orchestrator查询保证基于STATEMENT格式的复制不会导致重复错误,并且主主设置将始终实现一致性。orchestrator即使在进行故障恢复过程中也可以对后端宕机的master进行启动(恢复将在备用master重新启动)- 脑裂是有可能的。 根据您的设置、物理位置、代理类型,可能有不同的
orchestrator服务节点与不同的后端MySQL服务器通信。这种情况可能会导致两个orchestrator服务都认为自己是“活动的”,这两个服务都将独立运行故障转移,这将导致拓扑损坏。
三 基于共享数据库后端高可用(HA via shared backend)

完全的高可用是 通过后端数据库也具有高可用能力 实现。现有的后端数据库解决方案有:
- Galera
- XtraDB Cluster
- InnoDB Cluster
- NDB Cluster
上面的架构都要
- Galera/XtraDB Cluster/InnoDB Cluster 使用单写模式运行。多个
orchestrator节点可能通过代理与写入节点进行通信。如果写节点发生故障,后端集群将提升另一个数据库作为写节点;由您的代理来识别并将orchestrator的流量引导新的写节点。 - Galera/XtraDB Cluster/InnoDB Cluster 在多写模式下运行。一个好的设置建议是将每个
orchestrator节点与数据库服务器部署在同一服务器上。由于复制是同步的,因此不存在裂脑。只有一个orchestrator节点可以成为领导者,并且该领导者只会与数据库节点达成共识。
四 基于Raft协议高可用
以上介绍的三种方式都没有引入Raft共识算法。
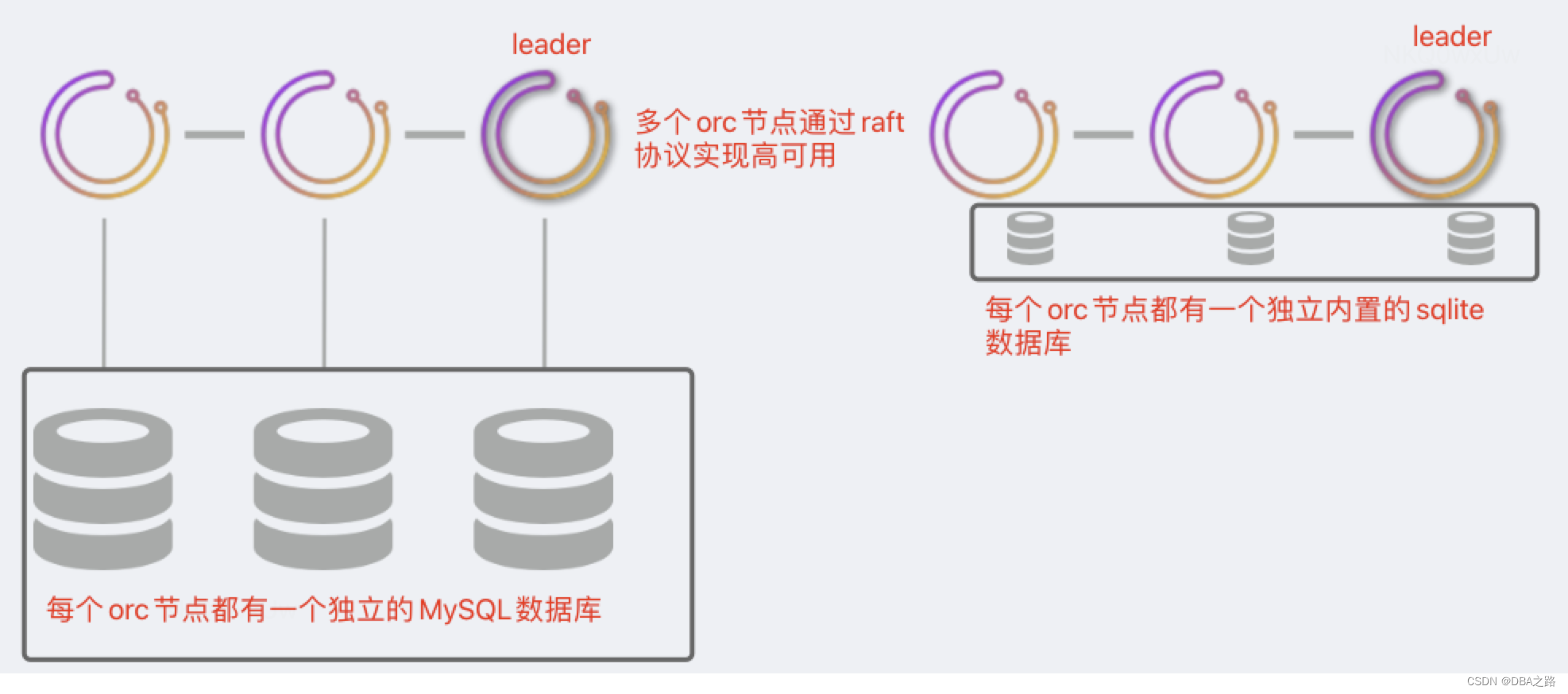
orchestrator节点直接通过Raft共识算法进行通信。每个orchestrator节点都有自己私有的后端数据库(可以是MySQL或者sqlite)。
只有一个orchestrator节点可以成为leader,并且始终是共识?的一部分。然而,所有其他节点都是独立活动的,并且正在轮询您的拓扑。
在这种设置中
- 数据库节点之间没有通信
- orchestrator节点之间通信最少
- 与MySQL拓扑节点的通信次数是orc节点个数的倍数。一个3个节点orc 意味着被监控的MySQL集群中需要被3个独立不同的orc节点探测。
- 建议运行为3个节点或者5个节点
- sqlite是orc内置的 不需要在额外的安装。如果流量较大 建议使用MySQL。
要访问orc服务 ,你只能与leader角色通信。
使用/api/leader-check作为代理的 HTTP 健康状况检查。- 或者使用具有多个
orchestrator后端的orchestrator-client;orchestrator-client将找出领导者的身份并向领导者发送请求。

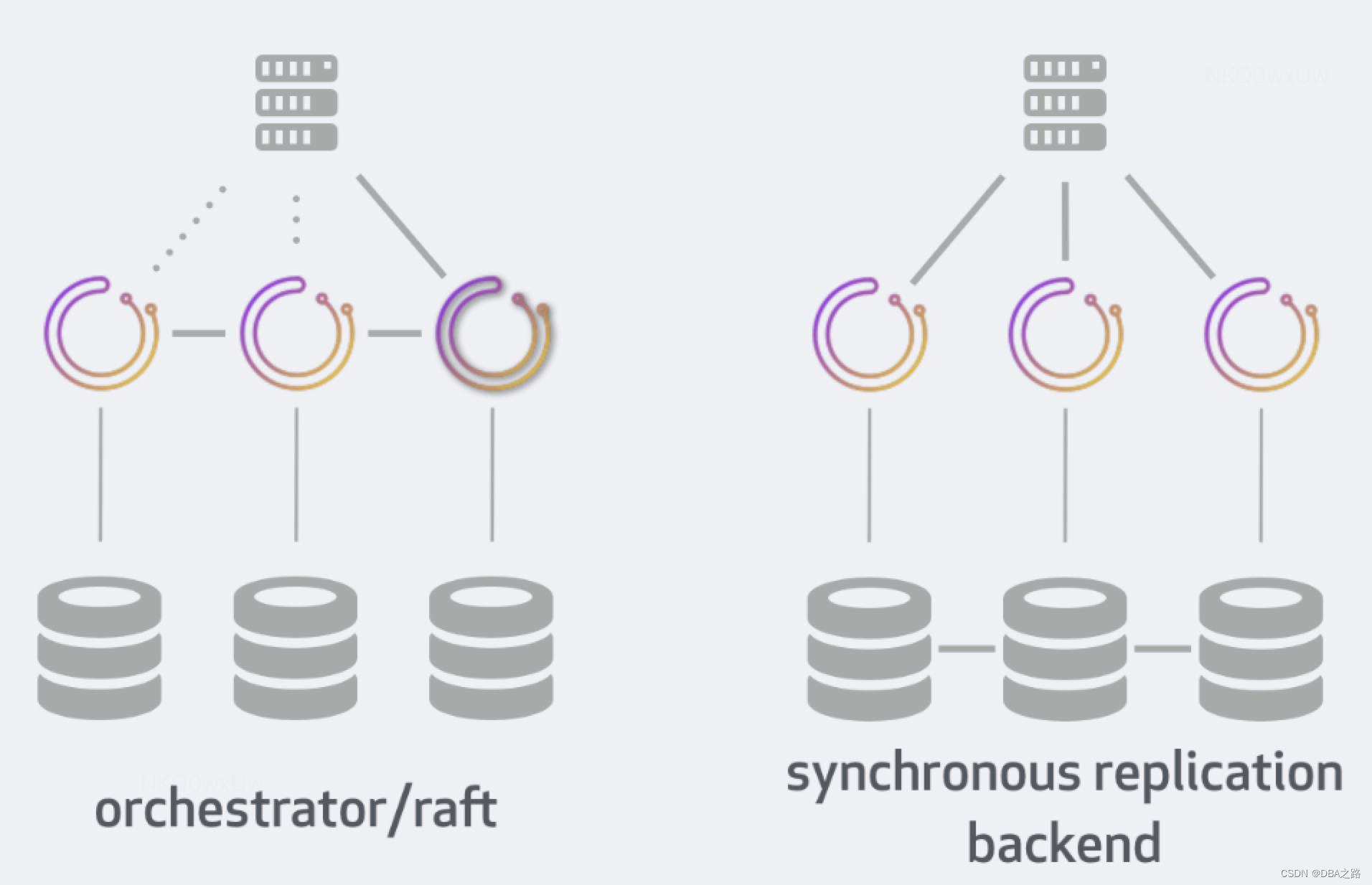
五 方案对比
这比较了两种高可用性部署方法的部署、行为、限制和优势:orchestrator/raft与orchestrator/[galera|xtradb cluster|innodb cluster]
我们将假设并比较:
3数据中心设置(可用区可以算作数据中心)3节点orchestrator/raft设置3 orchestrator节点和galera|xtradb cluster|innodb cluster多写模式(集群中的每个 MySQL 都可以接受写入)- 代理 可以运行
HTTP或者mysql健康检查 MySQL,MariaDB,Percona Server统称为MySQL。
| 比较 | orchestrator/raft | synchronous replication backend |
|---|---|---|
| 通信 | 每个orchestrator节点都有一个私有的后端DB;orchestrator节点通过raft协议进行通信 | 每个orchestrator节点连接到MySQL同步复制组中的不同成员。orchestrator节点之间不进行通信。 |
| 后端数据库 | MySQL 或 sqlite | MySQL |
| 对后端数据库的依赖 | 如果无法访问自己的私有后端数据库,服务会出现 | 如果无法访问自己的私有后端数据库,则服务不健康 |
| 数据库数据一致性 | 跨数据库后端独立。可能会有所不同,但在稳定的系统上会收敛到相同的整体情况 | 单个数据集,跨数据库后端同步复制 |
| 数据库访问 | 千万不要直接写。只有raft节点在协调/合作时访问后端数据库。否则可能会导致不一致。读取没问题 | 可直接访问、写入;所有orchestrator节点/客户端都会看到完全相同的图片 |
| Leader and actions | 单一Leader。只有Leader才能进行恢复。所有节点都可以进行发现(探测)和自我分析 | 单一Leader。只有Leader才能进行发现(探测)、分析和恢复。 |
| HTTP 访问 | 必须只能访问领导者(可以通过代理或强制执行orchestrator-client) | 可以访问任何健康的节点(可以通过代理强制执行)。为了读取一致性,最好只与领导者交谈(可以通过代理或强制执行orchestrator-client) |
| 命令行 | HTTP/API 访问(例如curl,jq)或orchestrator-client使用熟悉的命令行界面封装常见 HTTP/API 调用的脚本 | HTTP/API 和/或orchestrator-client脚本或orchestrator ...命令行调用。 |
| 安装 | orchestrator仅在服务节点上提供服务。orchestrator-client任何地方的脚本(需要访问 HTTP/API)。 | orchestrator服务节点上的服务。orchestrator-client任何地方的脚本(需要访问 HTTP/API)。orchestrator任何地方的客户端(需要访问后端数据库) |
| Proxy | HTTP。只能将流量引导至Leader ( /api/leader-check) | HTTP。必须仅将流量引导至健康节点 ( /api/status);最好只将流量引导至Leader节点 ( /api/leader-check) |
| No Proxy | orchestrator-client与所有后端一起使用orchestrator。orchestrator-client将引导流量至 master。 | orchestrator-client与所有后端一起使用orchestrator。orchestrator-client将引导流量至 master。 |
| 跨机房 | 每个orchestrator节点(以及私有后端)可以在不同的 DC 上运行。节点间通信不多,流量低。 | 每个orchestrator节点(以及关联的后端)可以在不同的 DC 上运行。orchestrator节点不直接通信。MySQL组复制通信频繁。流量主要与拓扑大小和轮询率呈线性关系。写入延迟。 |
| 探测 | orchestrator所有节点探测每个拓扑服务器 | 每个拓扑服务器由单个活动节点探测 |
| 故障分析 | 由所有节点独立执行 | 仅由领导者执行(数据库是共享的,因此所有节点无论如何都会看到完全相同的图片) |
| 故障转移 | 仅由Leader执行 | 仅由Leader节点执行 |
| 抵御失败的能力 |
|
|
| 节点从短暂故障中恢复 | 节点重新加入集群,并根据更改进行更新。 | 数据库节点重新加入集群,并根据更改进行更新。 |
| 节点从长期中断中恢复 | 必须从健康节点克隆数据库。 | 取决于您的 MySQL 后端实现。可能从备份进行 SST/恢复。 |
注意事项
以下是在两种方法之间进行选择时的注意事项:
- 您只有一个数据中心 (DC):选择共享数据库甚至更简单的设置
- 您对 Galera/XtraDB Cluster/InnoDB Cluster 感到满意,并且可以自动设置和维护它们:选择共享数据库后端。
- 您拥有高延迟跨 DC 网络:选择
orchestrator/raft方案。 - 您不想为
orchestrator后端分配 MySQL 服务器:选择orchestrator/raft 和SQLite数据库 - 您有数千个 MySQL 集群:选择MySQL
笔记
- 另一种同步复制设置是单个写入器的同步复制设置。这需要
orchestrator节点和底层集群之间有一个额外的代理,上面没有考虑。