1.版本控制器
所谓的版本控制器,就是能让你了解到⼀个⽂件的历史,以及它的发展过程的系统。通俗的讲就是⼀个可以记录⼯程的每⼀次改动和版本迭代的⼀个管理系统,同时也⽅便多⼈协同作业。
⽬前最主流的版本控制器就是 Git 。Git 可以控制电脑上所有格式的⽂件,对于我们开发⼈员来说,Git 最重要的就是可以帮助我们管理软件开发项⽬中的源代码⽂件!
但是:图⽚、视频这些⼆进制⽂件,虽然也能由版本控制系统管理,但没法跟踪⽂件的变化
2.Git安装(Linux-centos)
1.查看git版本
git–version
2.安装 Git
sudo yum install git -y
3.Git 基本操作
Git是一个版本控制器,用来记录和管理文件的修改以及迭代,它可以记录电脑上所有的文件(二进制文件除外)
只有在Git仓库中的文件才能被Git追踪和管理
1.创建 Git 本地仓库
git init

当前⽬录下多了⼀个 .git 的隐藏⽂件, .git ⽬录是 Git 来跟踪管理仓库的,千万不要⼿动修改这个⽬录⾥⾯的⽂件,会破坏Git仓库
2.配置 Git
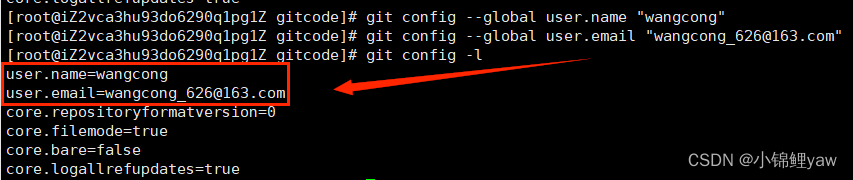
安装 Git 后⾸先要做的事情是设置你的 ⽤⼾名称 和 e-mail 地址
# 加上--global表示全局配置,配置这台机器上的所有git仓库
git config [--global] user.name "Your Name" #改成你的昵称
git config [--global] user.email "email@example.com" #改成邮箱的格式
git config -l #查看git配置
#重置配置(全局配置需要加global)
git config [--global] --unset user.name
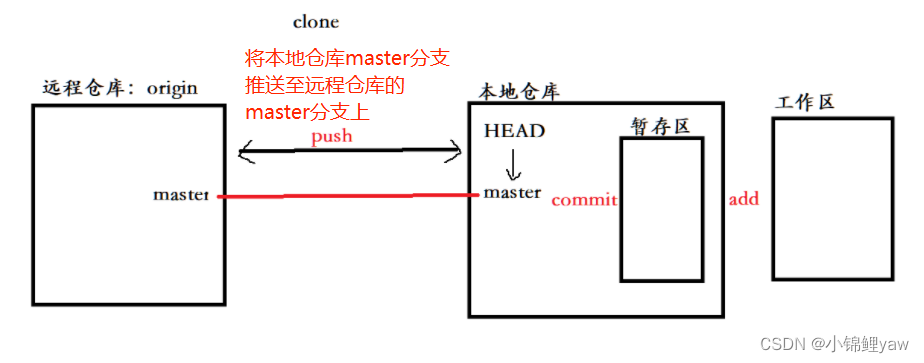
3.认识⼯作区、暂存区、版本库
- ⼯作区:是在电脑上你要写代码或⽂件的⽬录。
- 暂存区:英⽂叫 stage 或 index。⼀般存放在 .git ⽬录下的 index ⽂件(.git/index)中,我们把暂存区有时也叫作索引(index)。
- 版本库:⼜名仓库,英⽂名 repository 。⼯作区有⼀个隐藏⽬录 .git ,它不算⼯作区,⽽是 Git 的版本库。这个版本库⾥⾯的所有⽂件都可以被 Git 管理起来,每个⽂件的修改、删除,Git都能跟踪,以便任何时刻都可以追踪历史,或者在将来某个时刻可以“还原”
下⾯这个图展⽰了⼯作区、暂存区和版本库之间的关系:
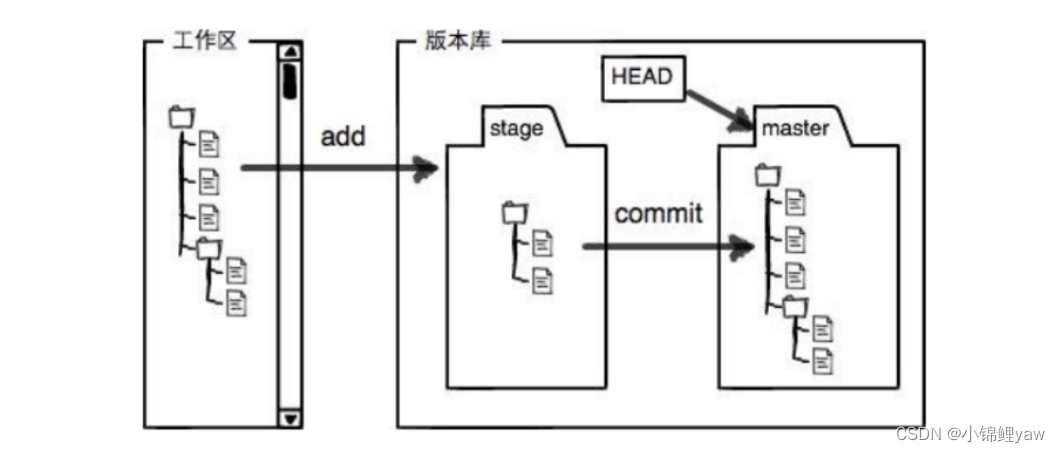
- 当对⼯作区修改(或新增)的⽂件执⾏ git add 命令时,暂存区⽬录树的⽂件索引会被更新
- 当执⾏提交操作 git commit 时,master 分⽀会做相应的更新,可以简单理解为暂存区的⽬录树才会被真正写到版本库中,此时git才能将文件进行管理
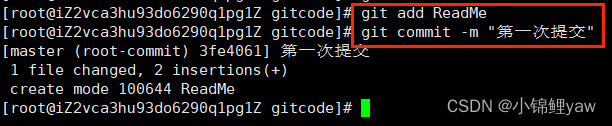
通过新建或粘贴进⽬录的⽂件,并不能称之为向仓库中新增⽂件,⽽只是在⼯作区新增了⽂件。必须要通过使⽤ git add 和 git commit 命令才能将⽂件添加到仓库中进⾏管理!!
objects 为 Git 的对象库,⾥⾯包含了创建的各种版本库对象及内容。当执⾏ git add 命令时,暂存区的⽬录树被更新,同时⼯作区修改(或新增)的⽂件内容被写⼊到对象库中的⼀个新的对象中,就位于".git/objects" ⽬录下,让我们来看看这些对象有何⽤处:
维护这些对象的索引就相当于维护修改的文件版本
总结
总结⼀下,在本地的 git 仓库中,有⼏个⽂件或者⽬录很特殊
- index: 暂存区, git add 后会更新该内容。
- HEAD: 默认指向 master 分⽀的⼀个指针。
- refs/heads/master: ⽂件⾥保存当前 master 分⽀的最新 commit id 。
- objects: 包含了创建的各种版本库对象及内容,可以简单理解为放了 git 维护的所有修改。
4.常用命令
1.添加一个或多个文件添加到暂存区
2.将暂存区内容添加到本地仓库中
3.查看历史提交记录
# 添加一个或多个文件到暂存区git add# 将暂存区内容添加到本地仓库中,注意 git commit 后⾯的 -m 选项,要跟上描述本次提交的 message,由⽤⼾⾃⼰完成,这部分内容绝对不能省略,并要好好描述,是⽤来记录你的提交细节,是给我们⼈看的git commit -m"对提交进行描述"# 查看历史提交记录git loggit log --pretty=oneline #简单的打印一行
4.查看 .git ⽂件
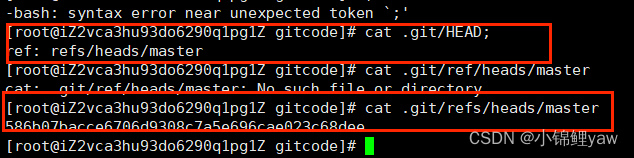
先来看看我们的 .git 的⽬录结构:
- index 就是我们的暂存区,add 后的内容都是添加到这⾥的。
- HEAD 就是我们的默认指向 master 分⽀的指针:
5.打印对象,被维护在Object对象库中
6.查看当前仓库的状态
7.显示暂存区和工作区之间的差异
//打印对象,被维护在Object对象库中
git cat-file -p 数字
// 查看当前仓库的状态
git status
// 显示暂存区和工作区之间的差异
git diff 文件名

8.版本回退
执⾏ git reset 命令⽤于回退版本,可以指定退回某⼀次提交的版本。要解释⼀下“回退”本质是要将版本库中的内容进⾏回退,⼯作区或暂存区是否回退由命令参数决定
git reset 命令语法格式为: git reset [–soft | --mixed | --hard] [HEAD]
- --mixed 为默认选项,使⽤时可以不⽤带该参数。该参数将暂存区的内容退回为指定提交版本内容,⼯作区文件保持不变
- –soft 参数对于⼯作区和暂存区的内容都不变,只是将版本库回退到某个指定版本。
- –hard 参数将暂存区与⼯作区都退回到指定版本,切记⼯作区有未提交的代码时不要用这个命令,因为⼯作区会回滚,你没有提交的代码就再也找不回了,所以使⽤该参数前⼀定要慎重。
- HEAD 说明:
◦ 可直接写成 commit id,表⽰指定退回的版本
◦ HEAD 表⽰当前版本
◦ HEAD^ 上⼀个版本
◦ HEAD^^ 上上⼀个版本
◦ 以此类推…
• 可以使⽤ 〜数字表⽰:
◦ HEAD~0 表⽰当前版本
◦ HEAD~1 上⼀个版本
◦ HEAD^2 上上⼀个版本
◦ 以此类推
9.记录本地的提交命令
# 记录本地的提交命令
git reflog
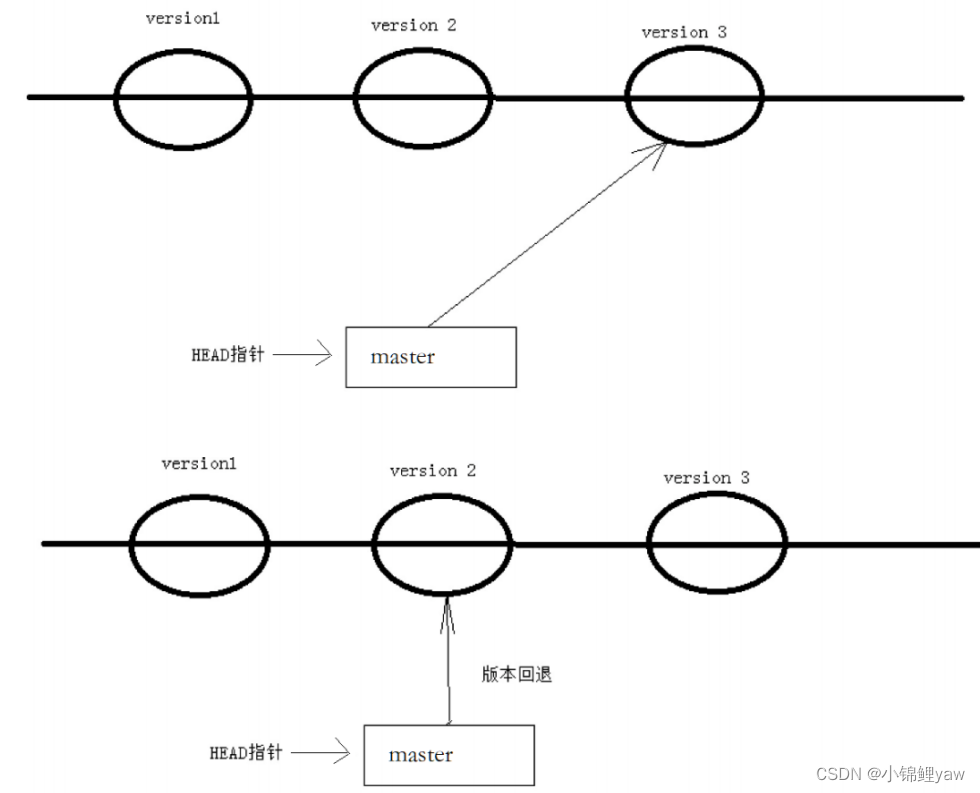
值得说的是,Git 的版本回退速度⾮常快,因为 Git 在内部有个指向当前分⽀(此处是master)的HEAD 指针, refs/heads/master ⽂件⾥保存当前 master 分⽀的最新 commit id 。当我们在回退版本的时候,Git 仅仅是给 refs/heads/master 中存储⼀个特定的version,只是修改master的指向而已
10.撤销修改(⭐前提:没有进行push操作)
⭐前提:没有进行push操作
push会将本地仓库中的代码提交到远程仓库
撤销的目的,就是不影响远程仓库中的代码
如果我们在我们的⼯作区写了很⻓时间代码,越写越写不下去,觉得⾃⼰写的实在是垃圾,想恢复到上⼀个版本
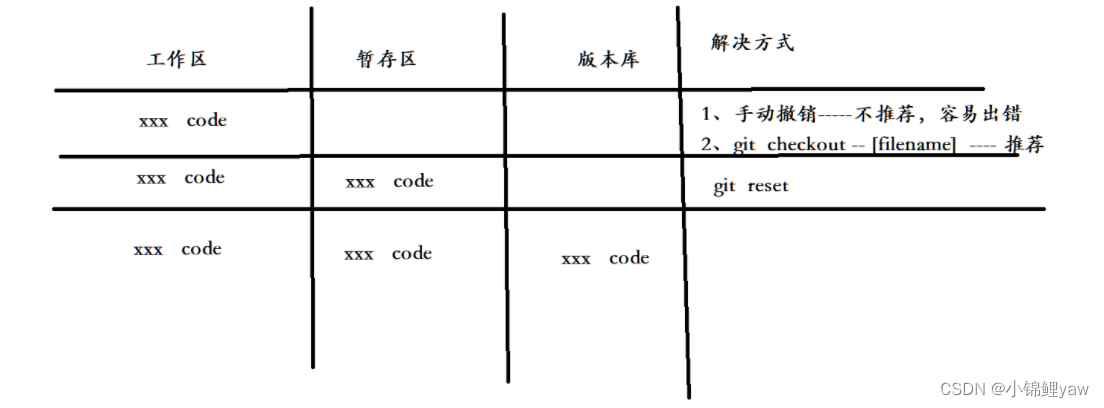
1.情况⼀:对于⼯作区的代码,还没有 add
就是只有工作区中存在代码,
我们只需要撤销工作区中的code
方式一:手动删除,不推荐容易出错
方式二:使用命令
git checkout -- [文件名]
2.情况⼆:已经 add ,但没有 commit
工作区和暂存区都存在代码,版本库中没有
我们需要撤销工作区和暂存区中的代码
方法一:使用git reset --hard HEAD命令一步到位
# 回退到当前版本库中的版本(暂存区和工作区中的code回退到指定版本)
git reset --hard HEAD
方法二:分成两步进行操作
// 先使用默认mixed使暂存区中的code回退到指定版本
git reset HEAD
// 但此时工作区中还为回退
// 此时使用下面的命令将工作区中的code回退即可
git checkout -- [文件名]
3.情况三:已经 add ,并且也 commit 了
工作区,暂存区以及版本库中都存在代码
此时就与上面的版本回退一样了
此时我们使用git reset --hard 版本号 回到指定版本的code即可
⭐没有进行push操作
11.删除⽂件
如果我们使用rm -rf [文件名] 仅仅是将本地工作区中的文件删除了,但是暂存区和版本库并未删除
那么应该怎么删除呢?
1.如果是误删
就可以使用回退到当前版本即可
2.如果确实需要删除这个文件
需要接着使用git rm命令来删除暂存区以及版本库中的文件
# 删除暂存区和版本库中的文件
git rm [文件名]
# 同样需要进行提交
git commit -m"删除了一个文件"
5.分支管理
1.主分支
在版本回退⾥,我们已经知道,每次提交,Git都把它们串成⼀条时间线,这条时间线就可以理解为是⼀个分⽀。截⽌到⽬前,只有⼀条时间线,在Git⾥,这个分⽀叫主分⽀,即 master 分⽀
HEAD 严格来说不是指向提交,⽽是指向master,master才是指向提交的,所以,HEAD 指向的就是当前分⽀
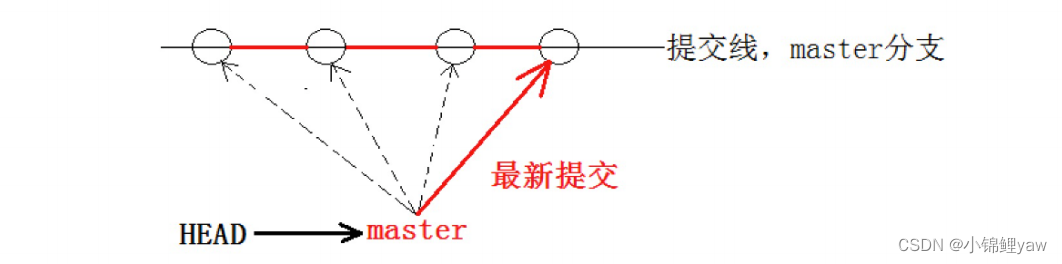

主线可以理解为master主分支,根据master就可以获得这条时间线
既然存在主分支,那么是不是也存在其他的分支,就像下面这样:
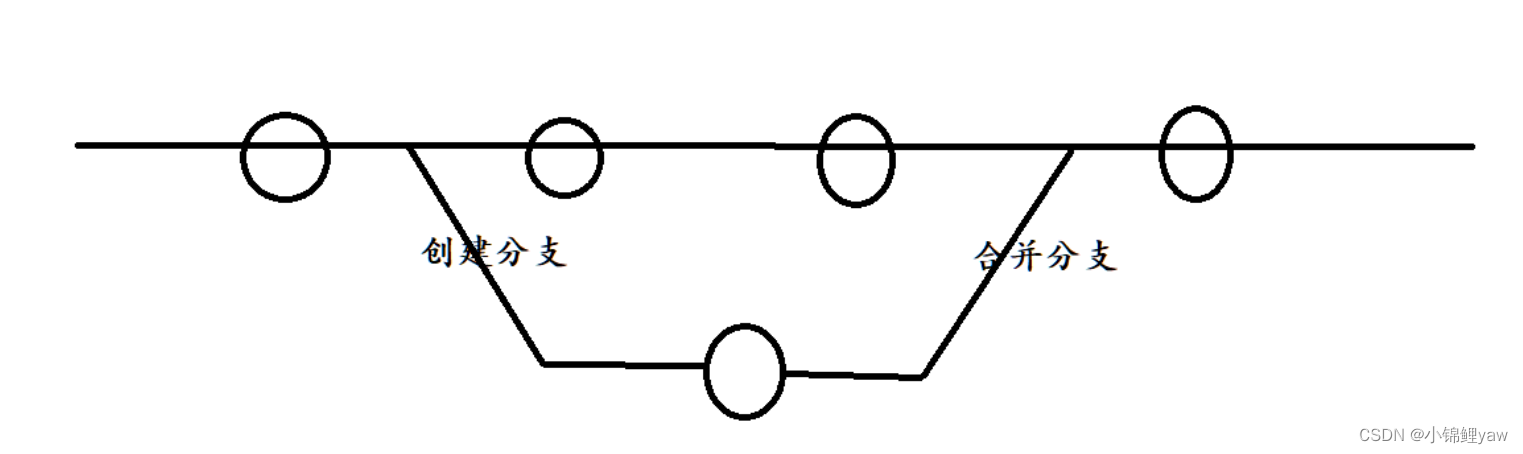
2.分支管理命令
1.查看当前本地所有分支
# 查看当前本地所有分支
git branch
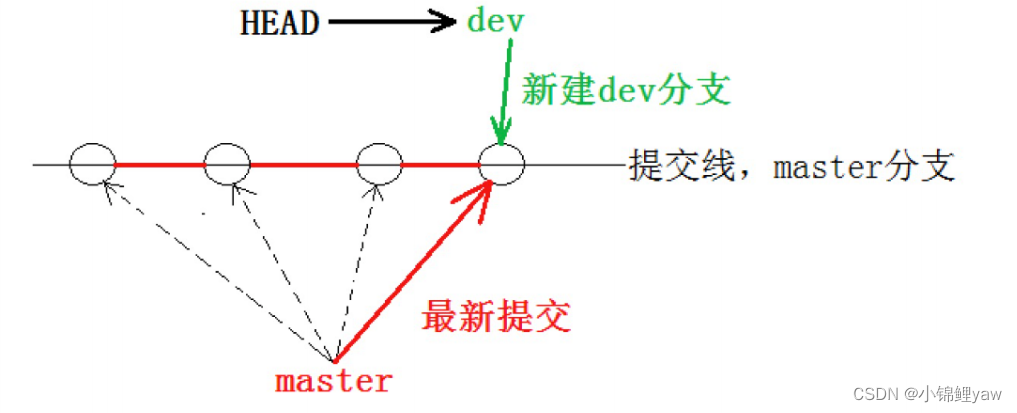
创建本地仓库会创建一个master分支,此时HEAD默认指向master分支,但是HEAD并非只能指向master分支
HEAD可以指向任意分支,HEAD所指的分支才是当前的工作分支

2.创建分支
# 新建一个dev分支
git branch [分支名]


dev指向最新提交,是因为dev是在当前版本上创建的分支
3.将HEAD指向指定分支
# 切换HEAD指针到指定分支
git checkout [分支名]
# 查看当前HEAD所指分支
git branch

此时就如下图所示
4.在分支上修改文件并将其提交至版本库
# 修改ReadeMe文件
vim Reade
# 保存并推出
:wq
# 提交至暂存区
git add ReadeMe
# 提交至版本库
git commit -m"在dev上的commit"
# 此时切换回master分支
git checkout master
# 查看当前所指分支
git branch
# 查看ReadeMe文件
cat ReadeMe
// 此时发现在dev分支上添加的代码不见了
# 切换回dev分支
git checkout dev
# 重新查看ReadeMe文件
cat ReadeMe
// 此时发现修改的文件又回来了,那么这是因为什么呢?
因为我们是在dev分⽀上提交的,⽽master分⽀此刻的提交点并没有变,查看.git文件中的Head指向就可以发现master分支依然指向之前HEAD指向master时的最新版本,如下图所示

5.合并分支
为了在 master 主分⽀上能看到新的提交,就需要将 dev 分⽀合并到 master 分⽀
# 将HEAD指向master分支
git checkout master
# 在master分支下合并分支dev
git merge dev
# 在master分支下查看ReadeMe文件
cat ReadeMe
// 此时发现可以看见最新的修改了
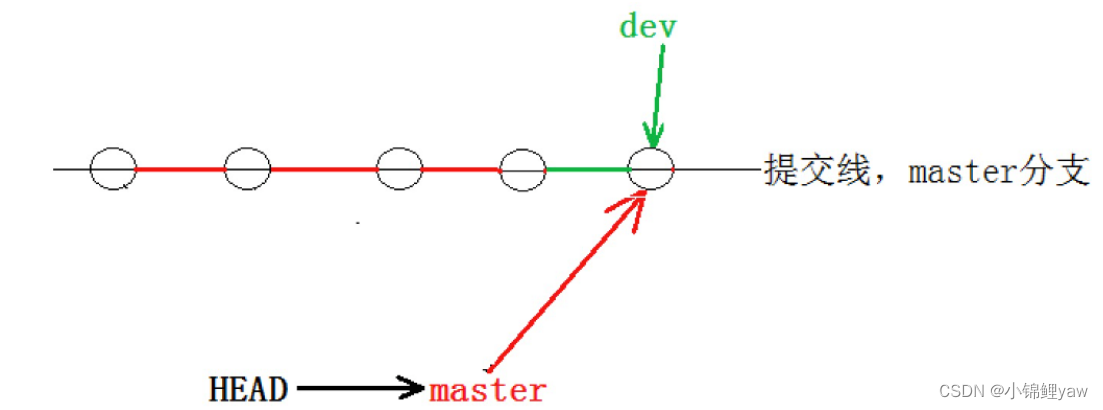
Fast-forward 代表“快进模式”,也就是直接把master指向dev的当前提交,所以合并速度⾮常快
当然,也不是每次合并都能 Fast-forward,我们后⾯会讲其他⽅式的合并

合并后,master 就能看到 dev 分⽀提交的内容了,此时的状态如图如下所⽰
6.删除分支
合并完成后, dev 分⽀对于我们来说就没⽤了, 那么dev分⽀就可以被删除掉,注意如果当前正处于某分⽀下,就不能删除当前分⽀
# 切换当前HEAD指向master分支
git checkout master
# 在master分支上删除dev分支
git branch -d dev
# 查看当前所有分支
git branch
// 此时就只剩下master分支了
此时的状态如图如下所⽰:
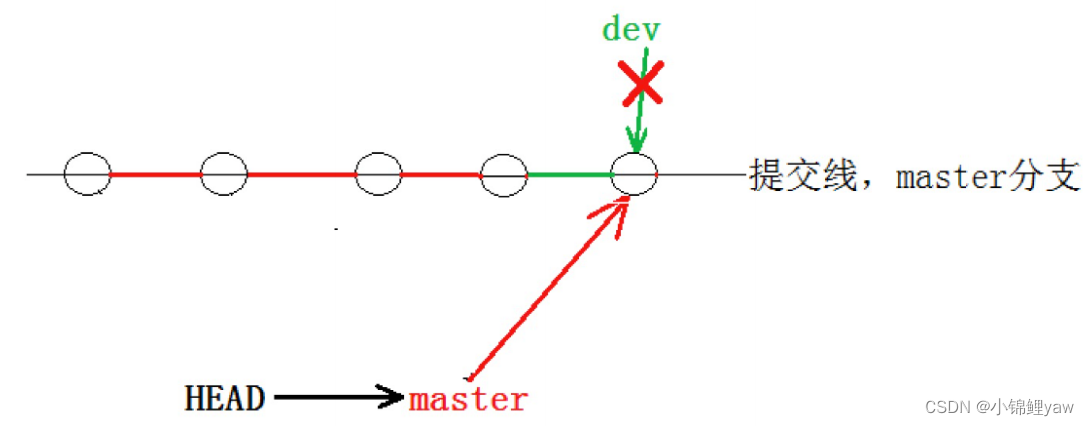
因为创建、合并和删除分⽀⾮常快,所以Git⿎励你使⽤分⽀完成某个任务,合并后再删掉分⽀,这和直接在master分⽀上⼯作效果是⼀样的,但过程更安全
7.分支冲突
可是,在实际分⽀合并的时候,并不是想合并就能合并成功的,有时候可能会遇到代码冲突的问题
我们按照下面的步骤进行操作:
# 创建本地分支dev1
git branch dev1
# 切换dev1分支
git checkout dev1
# 上面两行操作可以合并成一个,创建并且切换分支
git checkout -b dev1
# 修改ReadeMe文件为dev1
vim ReadeMe
# 将ReadeMe文件提交至暂存区
git add ReadeMe
# 将ReadeMe文件提交至版本库
git commit -m"在dev1中修改ReadeMe为dev1dev1"
# 此时切换为master分支
git checkout master
# 在master分支下修改ReadeMe文件为master
vim ReadeMe
# 将ReadeMe文件提交至暂存区
git add ReadeMe
# 将ReadeMe文件提交至版本库
git commit -m"在master中修改ReadeMe为master"
此时状态如下图所示:
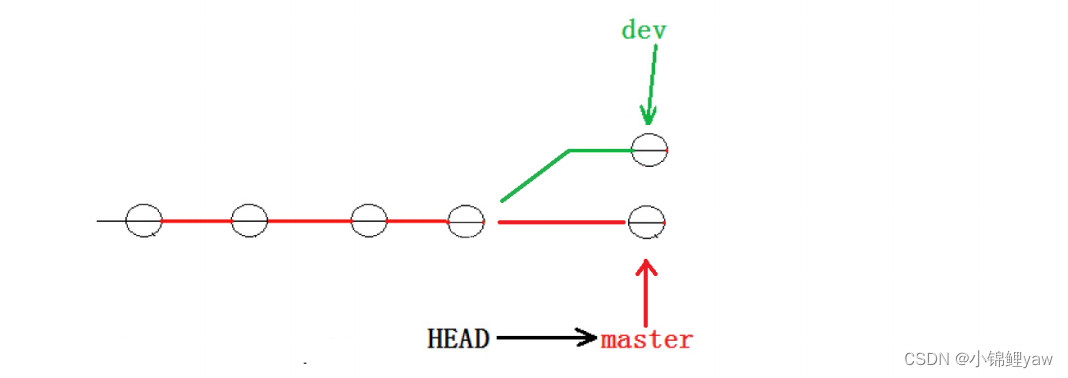
# 现在我们合并的时候git就没办法知晓我们到底需要保存哪个版本的文件,就会发生合并冲突
git merge dev1
这种情况下,Git 只能试图把各⾃的修改合并起来,但这种合并就可能会有冲突,就像下面这样:

此时我们查看ReadeMe文件就会发现:
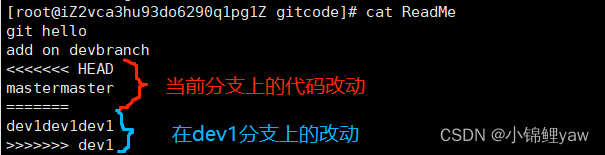
8.手动解决冲突
# 打开ReadeMe文件,手动修复文件
vim ReadeMe
# 将ReadeMe文件提交至暂存区
git add ReadeMe
# 将ReadeMe文件提交至版本库
git commit -m"在master中修改ReadeMe为master"
(不要忘了提交哦!!!)到这⾥冲突就解决完成,此时的状态变成了
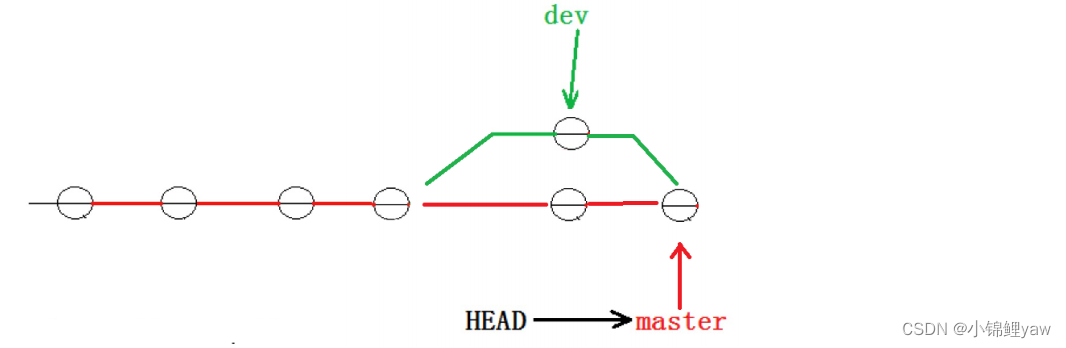 最后,不要忘记 dev1 分⽀使⽤完毕后就可以删除了:
最后,不要忘记 dev1 分⽀使⽤完毕后就可以删除了:
# 在master分支上删除dev1分支
git branch -d dev1
9.git log参数意义
# 查看历史提交日志
# --graph 图示的意思
# --abbrev-commit 将commit id缩写
git log --graph --abbrev-commit

10.分⽀管理策略
通常合并分⽀时,如果可能,Git 会采⽤ Fast forward 模式。还记得如果我们采⽤ Fast forward 模式之后,形成的合并结果是什么呢?回顾⼀下:
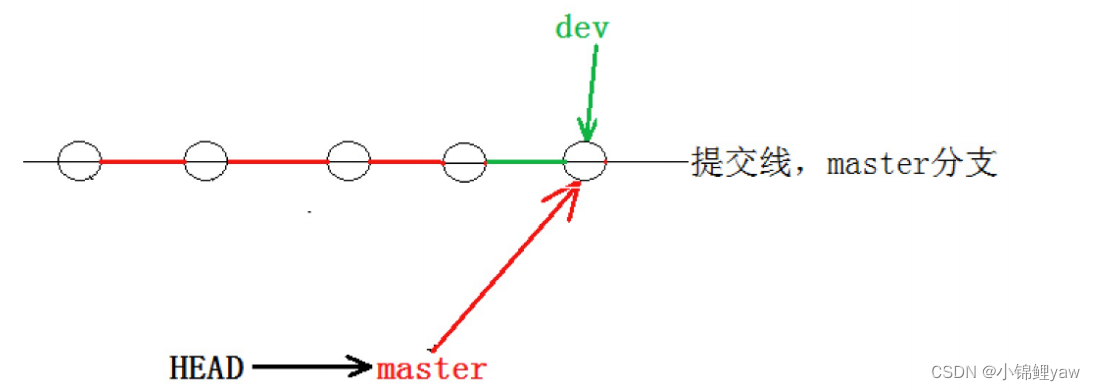
在这种 Fast forward 模式下,删除分⽀后,查看分⽀历史时,会丢掉分⽀信息,看不出来最新提交到底是 merge 进来的还是正常提交的
但在合并冲突部分,我们也看到通过解决冲突问题,会再进⾏⼀次新的提交,得到的最终状态为:
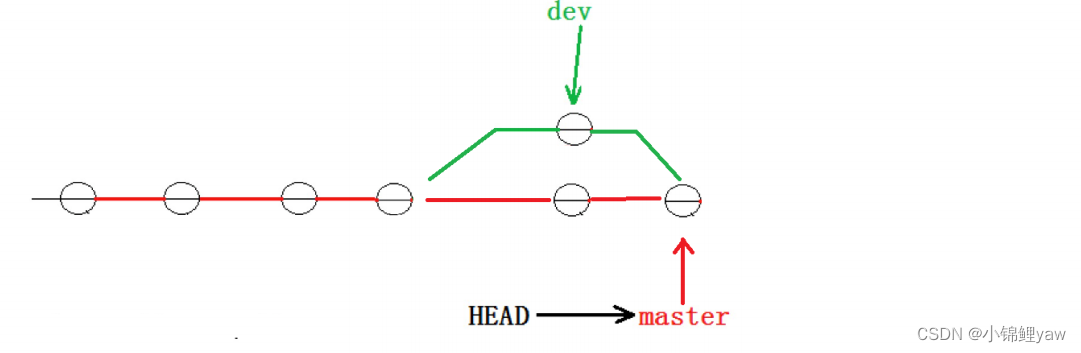
那么这就不是 Fast forward 模式了,这样的好处是,从分⽀历史上就可以看出分⽀信息。例如我们现在已经删除了在合并冲突部分创建的 dev 分⽀,但依旧能看到 master 其实是由其他分⽀合并得到:
11.不使用Fast forward进行合并(建议使用)
Git ⽀持我们强制禁⽤ Fast forward 模式,那么就会在 merge 时⽣成⼀个新的 commit ,这样,从分⽀历史上就可以看出分⽀信息
# --no--ff 不使用Fast forward进行合并
# -m"" 并且进行提交
git merge --no-ff -m"提交时的信息" [需要合并的分支]
可以看到,不使⽤ Fast forward 模式,merge后就像下图这样:
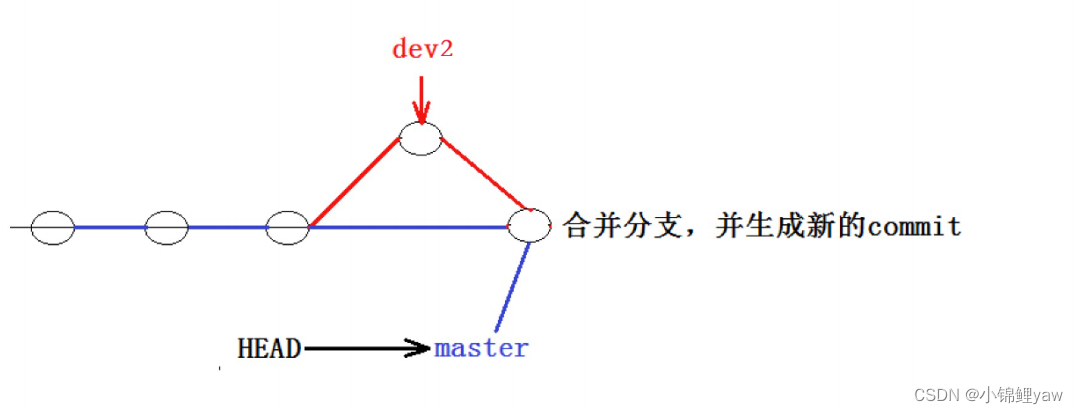
所以在合并分⽀时,加上 --no-ff 参数就可以⽤普通模式合并,合并后的历史有分⽀,能看出来曾经做过合并,⽽ fast forward 合并就看不出来曾经做过合并
6.分⽀策略
1.团队合作分支管理
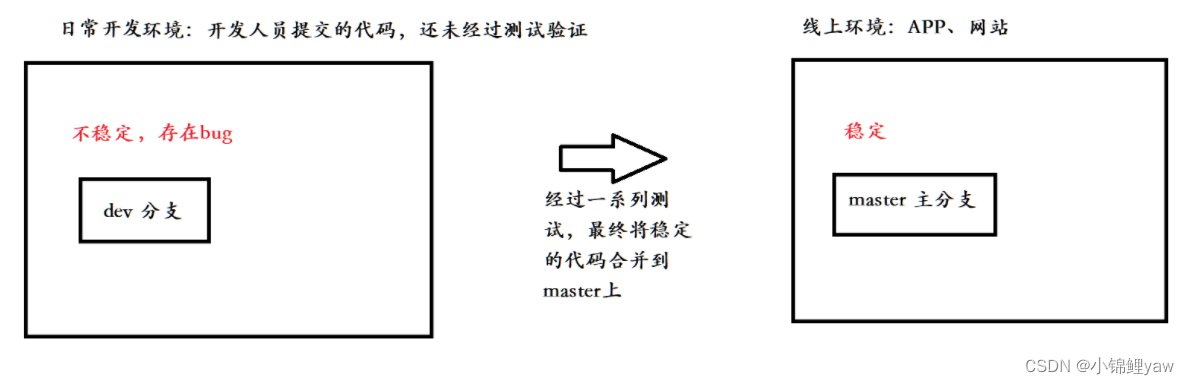
在实际开发中,我们应该按照⼏个基本原则进⾏分⽀管理:
⾸先,master分⽀应该是⾮常稳定的,也就是仅⽤来发布新版本,平时不能在上⾯⼲活
那在哪⼲活呢?
⼲活都在dev分⽀上,也就是说,dev分⽀是不稳定的,到某个时候,⽐如1.0版本发布时,再把dev分⽀合并到master上,在master分⽀发布1.0版本;
你和你的⼩伙伴们每个⼈都在dev分⽀上⼲活,每个⼈都有⾃⼰的分⽀,时不时地往dev分⽀上合并就可以了。
所以,团队合作的分⽀看起来就像这样:
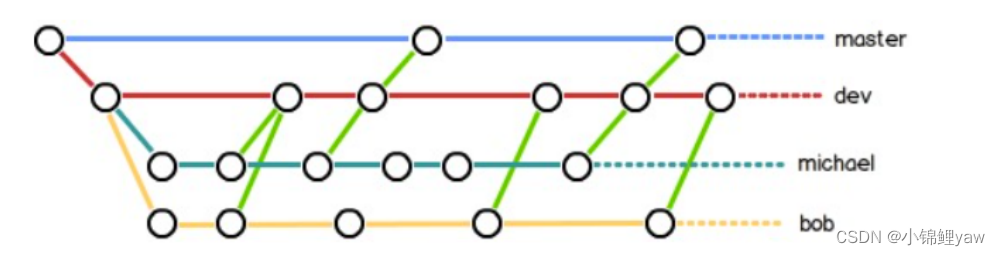
2.bug 分⽀
假如我们现在正在 dev2 分⽀上进⾏开发,开发到⼀半,突然发现 master 分⽀上⾯有 bug,需要解决。在Git中,每个 bug 都可以通过⼀个新的临时分⽀来修复,修复后,合并分⽀,然后将临时分⽀删除
可现在 dev2 的代码在⼯作区中开发了⼀半,还⽆法提交,怎么办?
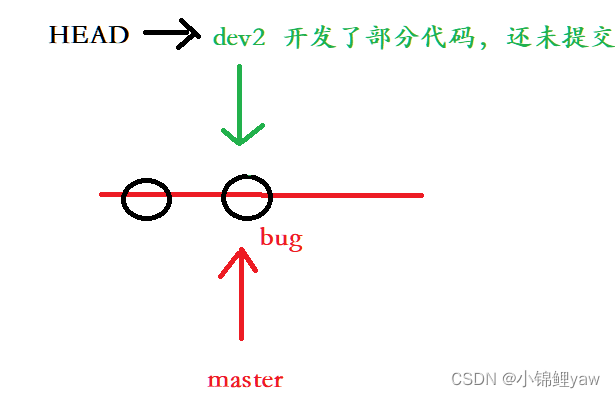
# 切换到dev2分支上
git checkout dev2
# 在dev2分支上开发代码
vim ReadeMe
# 切换到master分支
git checkout master
# 查看ReadeMe文件
cat ReadeMe
此时我们发现master分支上可以看见dev2分支对ReadeMe文件的修改
因为是在工作区中查看,并且master和dev2指向同一个版本
但是我们不想让dev2影响到master分支,应该怎么办呢?
3.将工作区中的信息进行储藏
Git 提供了 git stash 命令,可以将当前的⼯作区信息进⾏储藏,被储藏的内容可以在将来某个时间恢复出来
# 切换到dev2分支
git checkout dev2
# 将dev2工作区中的内容保存
git stash
# 查看工作区状态
git status

储藏 dev2 ⼯作区之后,由于我们要基于master分⽀修复 bug,所以需要切回 master 分⽀,再新建临时分⽀来修复 bug
# 切换到master分支
git checkout master
# 创建并切换分支
git checkout -b fix_bug
# 修复BUG
vim ReadeMe
# 别忘记add以及commit
git add ReadeMe
git connit -m"修复BUG版本"
# 切换回master
git checkout master
# 不使用fast合并分支
git merge --no-ff -m"修复bug" fix_bug
# 查看ReadeMe
cat ReadeMe
# 删除分支
git branch -d fix_bug
# 切换回dev2分支
git checkout dev2
# 查看文件
cat ReadeMe
⼯作区是⼲净的,刚才的⼯作现场存到哪去了?⽤ git stash list 命令看看:
# 查看存储区
git stash list
⼯作现场还在,Git 把 stash 内容存在某个地⽅了,但是需要恢复⼀下,如何恢复现场呢?我们可以使⽤ git stash pop 命令,恢复的同时会把 stash 也删了
4.恢复存储区的代码
# 恢复存储区的代码
git stash pop
另外,恢复现场也可以采⽤ git stash apply 恢复,但是恢复后,stash内容并不删除,你需要⽤ git stash drop 来删除
但我们注意到了,修复 bug 的内容,并没有在 dev2 上显⽰。此时的状态图为
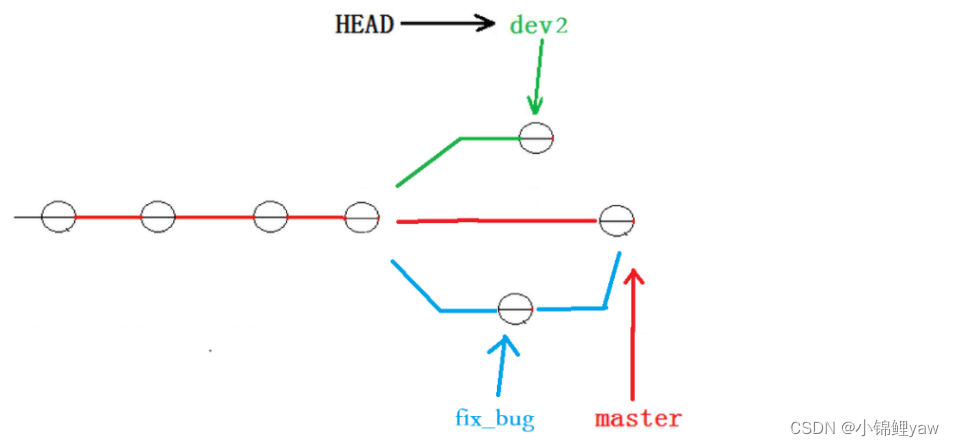
Master 分⽀⽬前最新的提交,是要领先于新建 dev2 时基于的 master 分⽀的提交的,所以我们在 dev2 中当然看不⻅修复 bug 的相关代码
我们的最终⽬的是要让 master 合并 dev2 分⽀的,那么正常情况下我们切回 master 分⽀直接合并即可,但这样其实是有⼀定⻛险的
是因为在合并分⽀时可能会有冲突,⽽代码冲突需要我们⼿动解决(在 master 上解决)。我们⽆法保证对于冲突问题可以正确地⼀次性解决掉,因为在实际的项⽬中,代码冲突不只⼀两⾏那么简单,有可能⼏⼗上百⾏,甚⾄更多,解决的过程中难免⼿误出错,导致错误的代码被合并到 master 上。
此时的状态为: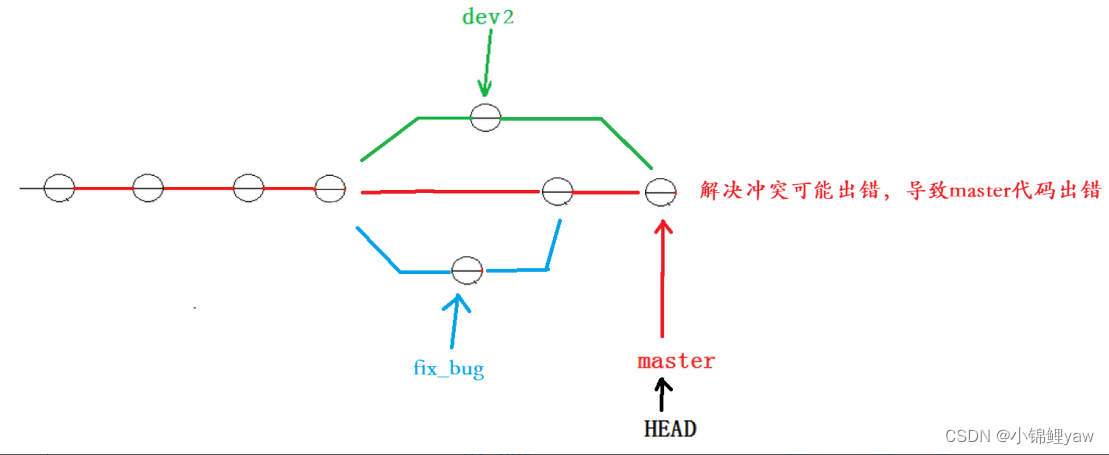
解决这个问题的⼀个好的建议就是:最好在⾃⼰的分⽀上合并下 master ,再让 master 去合并dev ,这样做的⽬的是有冲突可以在本地分⽀解决并进⾏测试,⽽不影响 master 。此时的状态为:
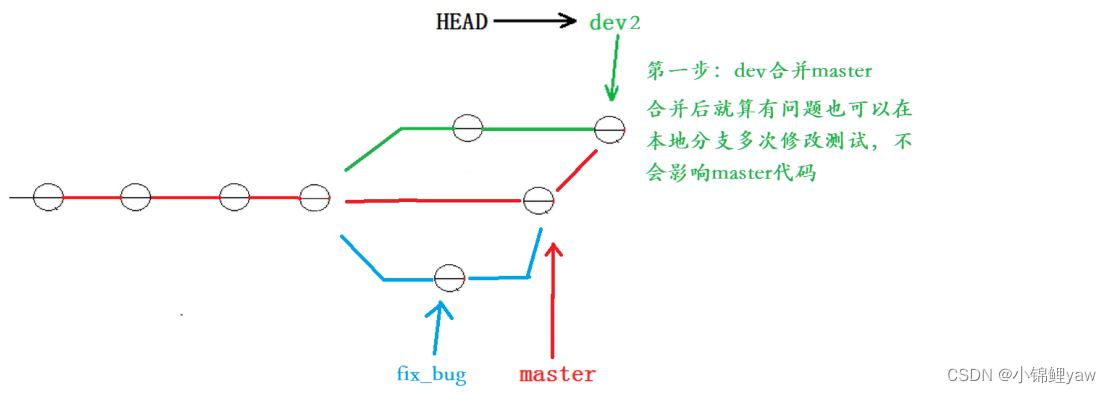
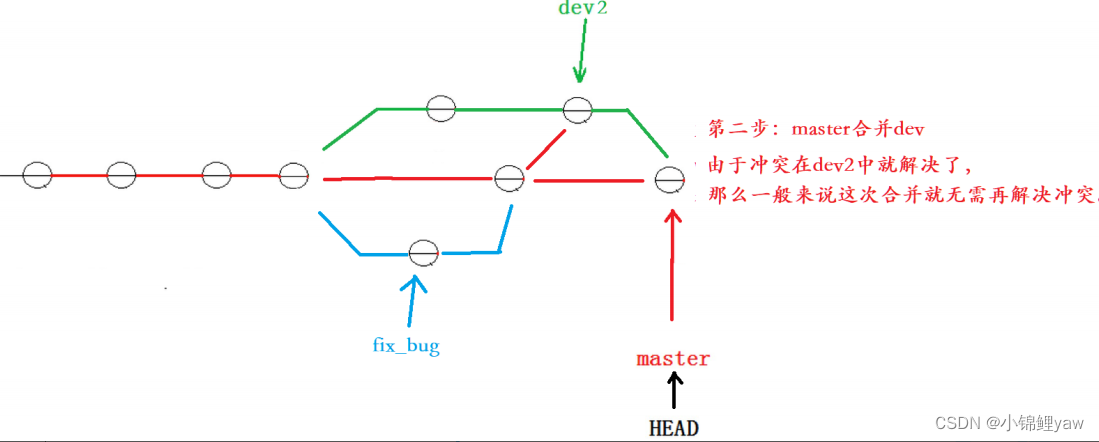
5.修复bug流程
# 将dev2上的代码进行存储
git stash
# 切换到master分支
git checkout branch
# 新建一个修复bug的分支,并切换到bug分支上
git checkout -b fix_bug
# 在bug分支上修复bug
vim ReadeMe
# 别忘记add和commit
git add ReadeMe
git commit -m"修复bug"
# 切换回master分支
git checkout master
# 不使用master合并修复bug的分支
git merge --no-ff -m"合并bug分支" fix_bug
# bug修复完成,删除fix_bug分支
git branch -d fix_bug
# 回到dev2工作分支
git checkout dev2
# 恢复存储
git stash pop
# 开发完成进行提交
git add ReadeMe
git commit -m"在dev2上开发完成ReadeMe"
# 在dev2分支合并master
git merge --no-ff -m"在dev2分支上合并master" master
# 切换到master
git checkout master
# 在master分支上合并dev2
git merge --no-ff -m"在master分支上合并dev2" dev2
# bug修复彻底完成
6.删除临时分⽀
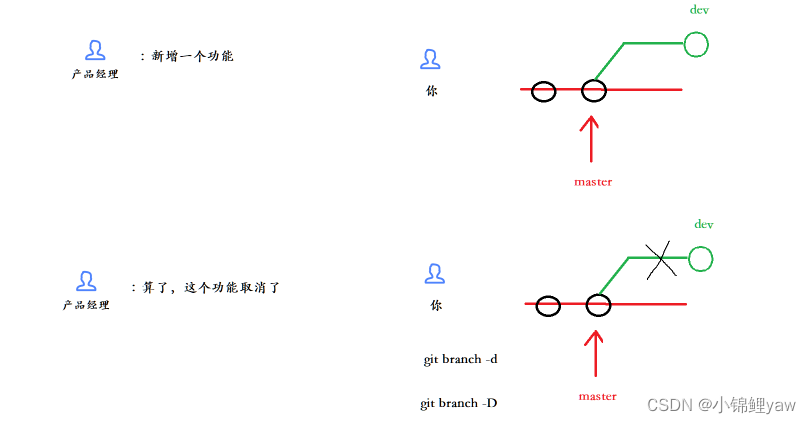
如果我们今天正在某个 feature 分⽀上开发了⼀半,被产品经理突然叫停,说是要停⽌新功能的开发。虽然⽩⼲了,但是这个 feature 分⽀还是必须就地销毁,留着⽆⽤了。这时使⽤传统的 git branch -d 命令删除分⽀的⽅法是不⾏的
这时候把d改成D就可以强制删除成功了
# 强制删除分支
git branch -D [分支名]
7.总结:分支的作用
分⽀在实际中有什么⽤呢?假设你准备开发⼀个新功能,但是需要两周才能完成,第⼀周你写了50%的代码,如果⽴刻提交,由于代码还没写完,不完整的代码库会导致别⼈不能⼲活了。如果等代码全部写完再⼀次提交,⼜存在丢失每天进度的巨⼤⻛险。
现在有了分⽀,就不⽤怕了。你创建了⼀个属于你⾃⼰的分⽀,别⼈看不到,还继续在原来的分⽀上正常⼯作,⽽你在⾃⼰的分⽀上⼲活,想提交就提交,直到开发完毕后,再⼀次性合并到原来的分⽀上,这样,既安全,⼜不影响别⼈⼯作。
并且 Git ⽆论创建、切换和删除分⽀,Git在1秒钟之内就能完成!⽆论你的版本库是1个⽂件还是1万个⽂件
7.理解分布式版本控制系统
1.中央服务器
我们⽬前所说的所有内容(⼯作区,暂存区,版本库等等),都是在本地也就是在你的笔记本或者计算机上。⽽我们的 Git 其实是分布式版本控制系统!什么意思呢?
那我们多人开发难道是大家围在一台电脑上开发吗?
当然不是了,git也想到了这个问题
⽐⽅说你在⾃⼰电脑上改了⽂件A,你的同事也在他的电脑上改了⽂件A,这时,你们俩之间只需把各⾃的修改推送给对⽅,就可以互相看到对⽅的修改了
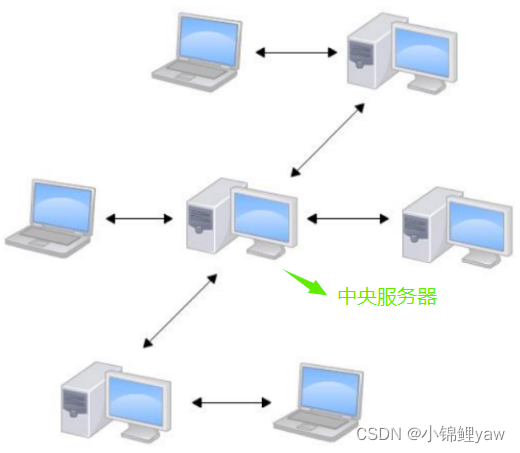
分布式版本控制系统通常也有⼀台充当中央服务器的电脑,但这个服务器的作⽤仅仅是⽤来⽅便“交换”⼤家的修改,没有它⼤家也⼀样⼲活,只是交换修改不⽅便⽽已。有了这个“中央服务器”的电脑,这样就不怕本地出现什么故障了(⽐如运⽓差,硬盘坏了,上⾯的所有东西全部丢失,包括git的所有内容)
2.远程仓库
1.新建远程仓库
1新建仓库步骤

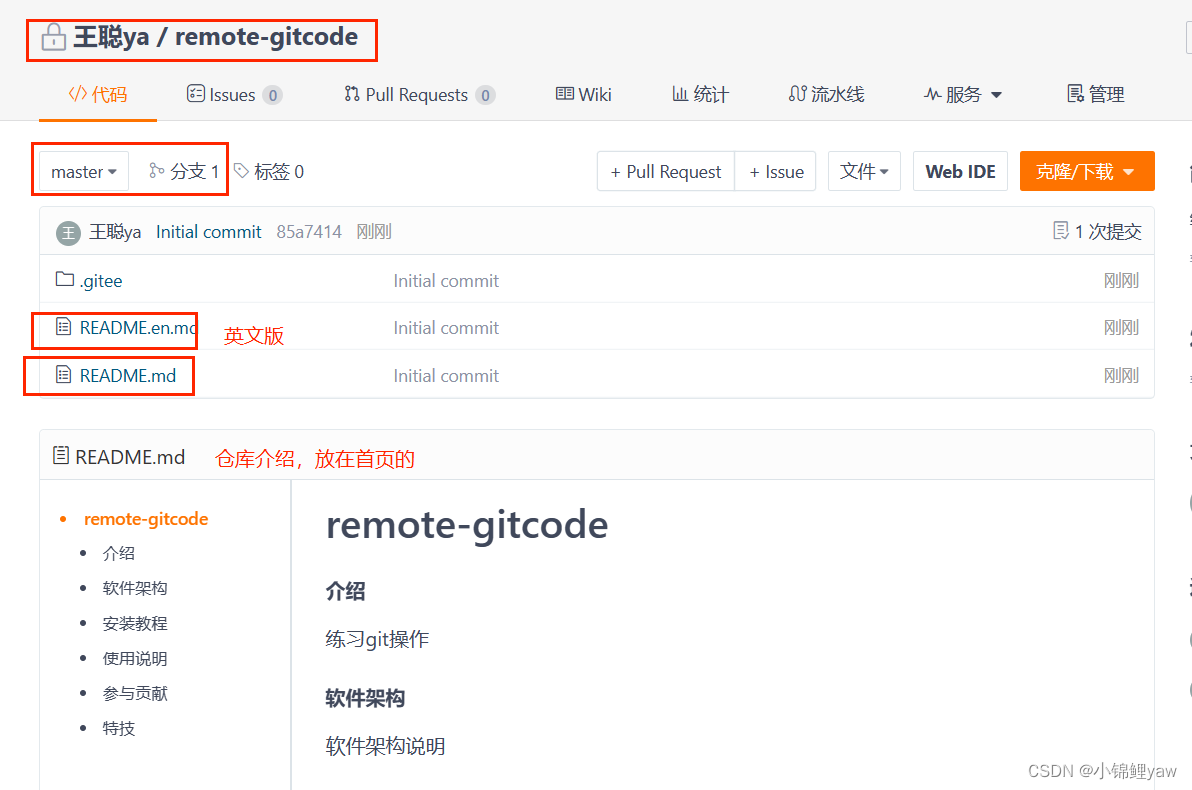
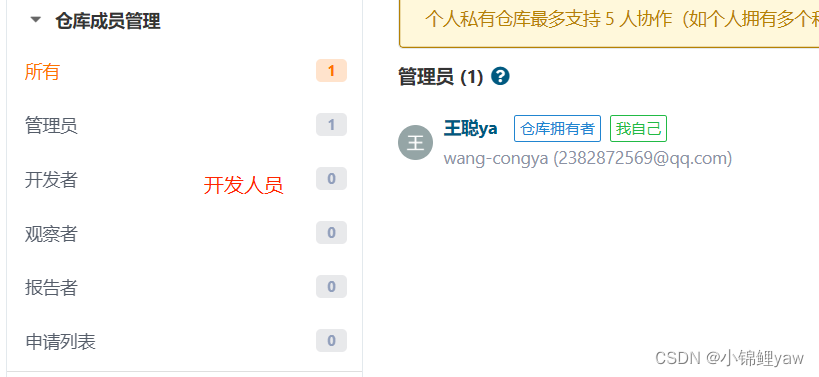
2.仓库成员管理

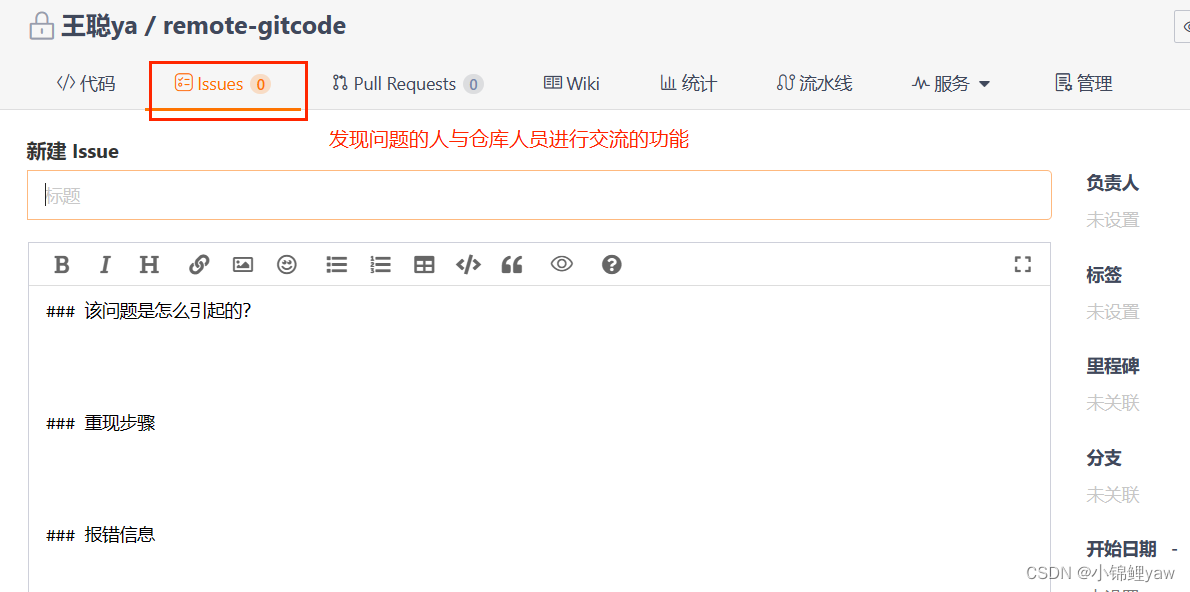
3.交流问题Issue
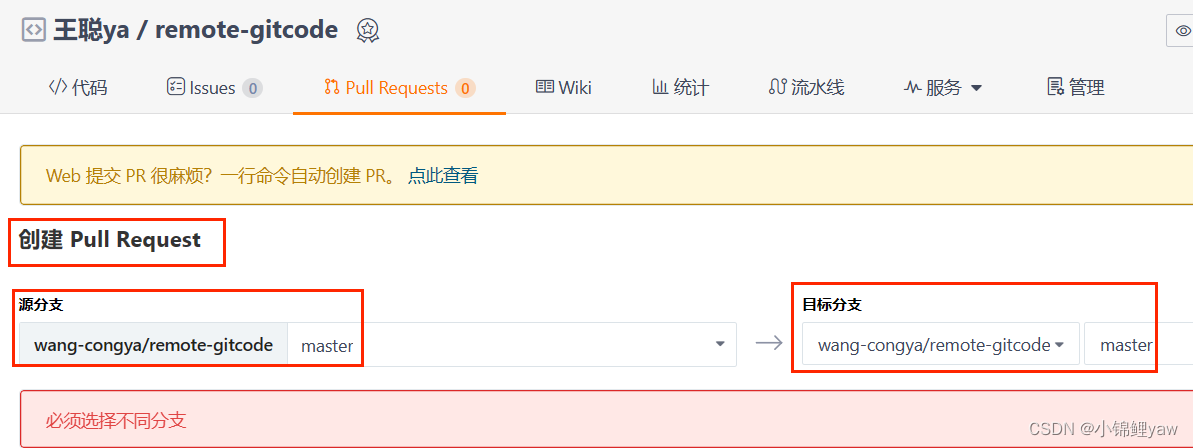
4.合并申请单 Pull Request
开发完成后向master主分支合并分支是非常不安全的,实际开发中不会被允许
Pull Request就相当于是一个合并申请单,开发者向管理员发起申请合并的操作,等管理员同意之后,会有专门的人员来进行合并
详细介绍链接:Pull Request
3.克隆远程仓库
1.使用使HTTPS ⽅式
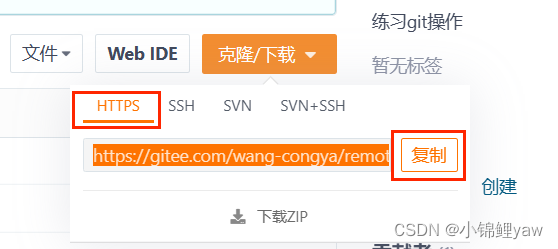
# 使用HTTP的方式克隆远程仓库
git clone [远程仓库链接]
# 查看远程仓库名字
git remote -v

表示当前仓库具有推送和拉取的权限
2.使用SSH的方式
SSH 协议使⽤了公钥加密和公钥登陆机制,体现了其实⽤性和安全性,使⽤此协议需要将我们的公钥放上服务器,由 Git 服务器进⾏管理
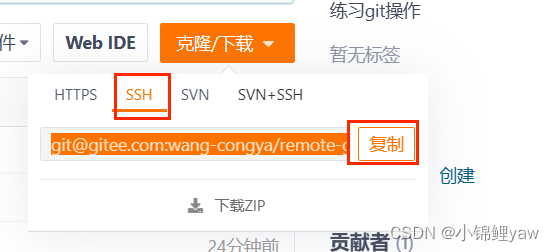
# 使用SSH的方式克隆仓库
git clone git@gitee.com:wang-congya/remote-gitcode.git
使⽤ SSH ⽅式克隆仓库,由于我们没有添加公钥到远端库中,服务器拒绝了我们的 clone 链接。需要我们设置⼀下
没看明白,下次再说
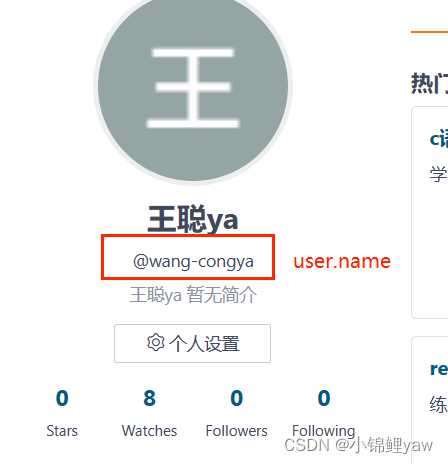
4.修改user.name和email配置
首先我们查看一下git配置,需要注意一下本地仓库与远程仓库的name,与email的配置要相同,如果忘记了,可以在个人信息中查看
修改git配置
git --global user.name "wang-congya"
git --global user.email "wangcong_626@163.com"
5.向远程仓库推送
需要有权限才能推送,并且需要将远程仓库与本地仓库的分支进行连接,master分支在克隆的时候会自动连接
# 创建一个文件写入hello git
vim file.txt
# 提交至暂存区以及版本库
git add file.txt
git commit -m""
# 查看状态
git status
# 向远程仓库推送并合并到远程分支
git pull <远程主机名> <远程分⽀名>:<本地分⽀名>
# 如果远程分⽀是与当前分⽀合并,则冒号后⾯的部分可以省略。
4 git pull origin master
# 按照提示输入git的名称和密码即可
"wang-congya"
密码就是账号密码
6.拉取远程仓库
有时候,远程仓库是要领先于本地仓库⼀个版本,为了使本地仓库保持最新的版本,我们需要拉取下远端代码,并合并到本地。Git 提供了 git pull 命令,该命令⽤于从远程获取代码并合并本地的版本
# 拉取远程仓库并合并到本地分支上
git pull <远程主机名> <远程分⽀名>:<本地分⽀名>
# 如果远程分⽀是与当前分⽀合并,则冒号后⾯的部分可以省略。
git pull origin master
# 查看当前仓库状态
git status
7.配置 .gitignore
在⽇常开发中,我们有些⽂件不想或者不应该提交到远端,⽐如保存了数据库密码的配置⽂件,那怎么让 Git 知道呢?
在 Git ⼯作区的根⽬录下创建⼀个特殊的 .gitignore ⽂件,然后把要忽略的⽂件名填进去,Git 就会⾃动忽略这些⽂件了
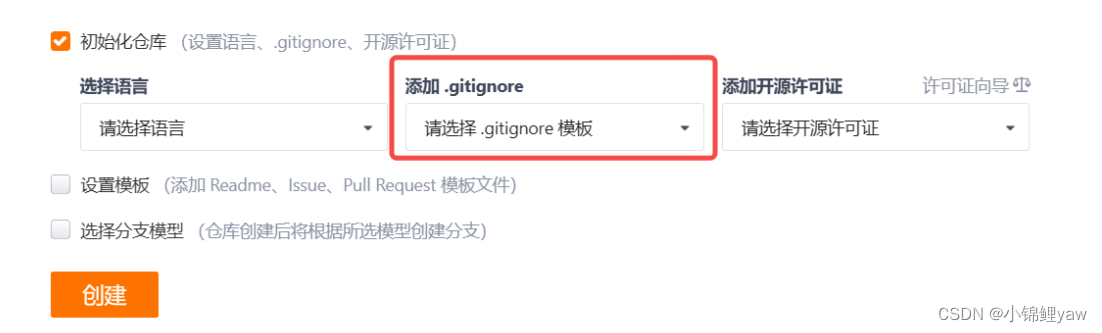
不需要从头写 .gitignore ⽂件,gitee 在创建仓库时就可以为我们⽣成,不过需要我们主动勾选⼀下:
# 强制添加,尽量不使用
git add -f [文件名]
# 修改.gitignore
# 表示忽略所有以.so结尾的文件
*.so
# 表示不忽略b.so文件
!b.so
# 查看某个文件被忽略的原因
git check-ignore -v a.so


![[Go版]算法通关村第十四关白银——堆高效解决的经典问题(在数组找第K大的元素、堆排序、合并K个排序链表)](https://img-blog.csdnimg.cn/79f2bfad071c49a5925f0781bbe91659.png)