Transformer(Attention Is All You Need)
Attention Is All You Need
参考:跟李沐学AI-Transformer论文逐段精读【论文精读】
摘要(Abstract)
首先摘要说明:目前,主流的序列转录(序列转录:给一个序列,转录为另外一个新的序列)模型都是基于RNN和CNN,且一般都是一个encoder和decoder的架构。在这些encoder和decoder中通常会使用注意力机制。然后,作者接着说,这篇文章提出了一个简单的只使用了注意力机制的模型架构-Transformer,而没有使用RNN或CNN等卷积操作。接着,作者将该架构在两个机器翻译任务上进行实验,可以实现更好的性能和更少的训练时间。
导言(Introduction)
首先作者介绍了RNN、GRN等主流的sequence models,然后作者指出,这里面有两个比较主流的模型,一个叫做语言模型,海有一个是当输出结构化信息比较多的时候的encoder和decoder架构的模型。
然后,作者讲了RNN的特点和缺点,在RNN中给一个序列,其做法是对序列从左往右一步一步往前做的。当前第t个词的状态 h t h_t ht是由前一个词的状态 h t − 1 h_{t-1} ht−1和当前词本身决定的。这样的话RNN就可以把前边学到的历史信息通过 h t − 1 h_{t-1} ht−1放到当下,然后和当前词做一些计算,然后输出。RNN存在的问题比较难以并行。
在第三段,作者指出,Attention机制已经在RNN中使用,主要是用在解决,如何将encoder的信息传递给decoder中。
在导言的最后一段中,作者指出,本篇文章提出了一个叫做Transformer的模型,不再使用之前的RNN layers,而是纯注意力机制。
相关工作(Background)
首先,作者指出如何使用卷积神经网络来替换掉RNN layers来减少时序计算。同时,又指出,使用CNN无法对比较长的序列进行建模。但是,如果使用Transformer的话,每次都能看到所有的像素。但是,CNN比较好的地方是可以做多个输出的channels,一个channel可以认为CNN去识别不一样的模式。为了实现和CNN一样的能够输出多个channel的功能,文中提出了一个叫做Multi-Head Attention机制(多头注意力机制)。
接下来,作者提出了Self-Attention(自注意力机制)。然后最后,作者指出,Transformer是第一个只依赖于自注意力机制的encoder和decoder架构模型。
模型架构(Model Architecture)
首先,作者说明大多数的序列转录模型中都具有encoder和decoder架构。然后,解释encoder是将一个序列表示为中间的向量表示形式,然后decoder是将中间的向量表示形式,表示为最后的输出。这里的输入和输出不一定具有同样的长度(例如:英文转为中文的话,长度不一定是一样的)。但是需要注意的是,在decoder解码的时候,结果输出是一个一个生成的,文中指出这种解码机制叫做自回归(auto-regressive模型,在这个模型中输入又是输出,即:过去时刻的输出又是当前时刻的输入)。
Transformer模型架构是将self-attention、point-wise和FCN(全连接层)堆叠在一起的。整个Transformer模型架构如下图所示。

上图中,左边部分为Transformer的encoder架构,右边部分为decoder架构。其中,encoder的输入是序列(可以是图片序列、语句序列等),decoder的输入是上一个decoder的输出。
编码器encoder
首先,作者介绍了encoder:使用6个完全一样的上图中的encoder组成。作者将6个encoder中的每一个叫做layer,其中每个layer中有两个sub layer。第一个sub layer叫做“Multi-Head self-attention”机制,第二个sub layer叫做point wise FFN(其实就是一个MLP前向传播网络)。对每个子层使用一个残差连接。最后使用一个layer normalization(层级正则化)。其中, L a y e r N o r m ( x + S u b l a y e r ( x ) ) LayerNorm(x+Sublayer(x)) LayerNorm(x+Sublayer(x))表示,针对每个encoder层来说,输入x首先经过sublayer层然后和x进行相加,之后再通过一个Norm层。文中说,将每个encoder层的输出向量维度设置为512。(这里和CNN不一样,在基于CNN架构的模型中对向量的维度是长度方向上减少,而channel方向上增加,这里只是使用一个固定维度为512的向量,所以Transformer相对来说架构比较简单)
解释LayerNorm(以及为什么在Transformer的架构中不使用BatchNorm)

上图中,解释了为什么Transformer中不使用Batch Norm而是使用Layer Norm。
解码器decoder
Transformer中decoder和encoder的架构很相似,数量也是N=6个进行堆叠。不一样的地方在于decoder中加入了第三个sub layer,这个第三子层同样是一个多头注意力机制,其作用为防止decoder在做预测的时候,不能看到当前t时刻之后的输入(因为Transformer中使用了注意力机制,同一时刻理论上所有的输入都是可以看到的,但是这样在解码的时候不合理,所以使用了这个Masked Multi-Head Attention Encoder,即使用一个掩码机制来限制decoder去接受当前时刻t之后的输入,从而保证训练和预测的时候行为是一致的。)
注意力Attention
首先作者介绍了Attention Function的含义:attention function是一个将一个query和一系列key-value对映射为输出(output)的函数。这里的query、keys、values、output都是一些向量。output是values的加权和,所以output的维度和values的维度是一样的。对于每个value对应的权重是该value对应的key与query计算相似度之后得到的。(这里计算相似度的函数不一样就会导致不一样的注意力机制)
Scaled Dot-Product Attention

文中提出的注意力机制中,query和key是等长的,都等于 d k d_k dk,values为 d v d_v dv。作者指出,将query和key做点积,结果作为相似度(如果两个等长向量的内积越大,即余弦值越大,那么两个向量的相似度越大)。将得到的结果除以 d k \sqrt{d_k} dk,即向量的长度。query会和每一个key做内积,然后将得到的结果输入到softmax当中,得到N个非负的且加起来和等于1的权重。然后,将这些权重作用在N个key对应的N个value上面,这样就得到了最后的输出。
实际运算过程中对上述相似度计算过程的处理

query可以写成一个矩阵 Q Q Q(因为不止一个query),且需要注意的是上图中展示的Q(多个query组合得到的矩阵)中的query数量可以和key的数量不一致,但是每个query与key的长度一定是一致的,这样才能做内积。上图中的两个矩阵相乘之后,就可以得到一个 N × M N\times M N×M的矩阵。然后,将该矩阵除以 d k \sqrt{d_k} dk,之后对结果的每一行做softmax即可(行与行之间是独立的)。然后,将结果乘以values即可。最后就可以得到 N × d v N\times d_v N×dv的矩阵。
然后,作者指出了上述提出的注意力机制和传统的注意力机制的区别。一般来说有两种注意力机制:加型注意力(可以处理query和key不等长的情况)。另外一个叫做点积的注意力机制。本文提出的注意力机制基本上和点积注意力机制一样,只是本文的注意力机制中除了 d k \sqrt{d_k} dk。
为什么本文提出的注意力机制需要除以一个 d k \sqrt{d_k} dk
作者解释:当 d k d_k dk不是那么大的时候,其实除与不除基本没有区别。但是对于较长的key和query来说,两者点积之后得到的矩阵,在通过softmax之后,会更加向1和0(两端)靠拢。这样的话,最后计算梯度的时候,梯度会比较小,那么在训练的时候就会出现模型跑不动(训练不起来)情况。

上图左子图中包含Masked Attention,具体来说,假设query和key是等长的,那么对t时刻,query与key计算时,应该只看 k 1 − k t − 1 k_1-k_{t-1} k1−kt−1时刻,而不能看 k t k_t kt及其之后的时刻。(因为 k t k_t kt在t时刻还没有计算出来,但是对于注意力机制来说,实际上query可以看到所有key中内容,且query会与key中左右内容进行计算,计算是可以算的,但是在计算最后注意力机制输出的时候不要使用t时刻以及t时刻之后的key的内容即可,实际操作的时候,mask中将t以及t时刻之后的query与key计算的值换成非常大的负数,那么在通过softmax的时候,这些非常大的负数对应的权重就是0。)
Multi-Head Attention机制

作者在文中说,通过将query/key/value投影到一个低维的向量中,投影h次,然后再做h次的注意力函数,然后将每个函数的输出并到一起,然后再投影得到最终的输出。为什么使用多头注意力机制,是因为本文提出的注意力机制实际上是没有可学习的参数,那么上图中的多头注意力机制中对于query/key/value输入首先通过的Linear线性层中的w和b是可以学习的。也就是说,给h次机会,希望这个多头注意力机制能够学习到不同的投影方法,使得在投影后的那个空间可以匹配得到不同模式需要的相似函数。(这个多头注意力机制与CNN中的多个输出通道有一种相似的感觉)
在实际操作中,作者指出,由于注意力机制中残差连接的存在,输入和输出维度本来就是一样的,那么这个时候使用h个多头注意力机制,对应到每个注意力机制的输出就是原始的单注意力机制/h(这里原始的输入输出维度为512,h=8,那么多头注意力机制中每个头的输入输出维度为512/8=64)
在Transformer架构中使用注意力机制

上图左子图为encdoer,其中首先将input输入复制三份,分别作为Multi-Head Attention中的key/value/query(这就叫做自注意力机制)。右子图中为decoder,其中首先为一个Masked Multi-Head Attention机制(前边已经解释过),然后是一个和encoder一样的Multi-Head Attention(该注意力层中,key/value来自于encoder,而query来自于decoder的第一个Masked Multi-Head Attention)。
Point wise Feed Forward Networks

其实,就是一个全连接前向传播网络,就是一个MLP(多层感知机)。但是,作者指出,和传统的FFN不一样的地方在于,其将序列中的每个点(可以理解为,加入输入是一段英文序列,那么一个点就表示一个单词)做一次FFN,即对每个词作用同样的一个MLP(共享权重)。其中,x表示一个512的向量。其中的 W 1 W_1 W1会将512投影成2048维的向量。然后, W 2 W_2 W2会把2048维的向量又投影回512。
扩展:Transformer与CNN的区别

上图中左边为Transformer的注意力机制,右边为RNN(循环神经网络)。其中,RNN为了得到历史信息,其需要在t时刻使用t-1时刻的信息接入,这种就会造成一个问题,当前t时刻的信息会越来越大。而对于Transformer来说,其做到与RNN相同的获得历史全局信息的过程是使用多个注意力头。
embedding and softmax层
Transformer的输入是多个词源(token),那么在处理的时候需要将每个token映射为一个向量,那么embedding就是针对任何一个token,学习一个长为d的向量来表示。编码器和解码器都有一个embedding过程。最后在softmax之前的Linear线性层也需要一个embedding,这三个embedding层是同样的权重,这样训练起来会简单一些。还有一点,作者在文中说到,将权重乘了 d m o d e l \sqrt{d_{model}} dmodel(原始论文中, d m o d e l d_{model} dmodel就是512)。因为,对于embedding层来说,当学习的向量维度变大之后,那么权重值就会变小,乘以 d m o d e l d_{model} dmodel之后,再将embedding之后的token对应的向量与下边的positional encoding层进行相加,会使得两个向量在一个大概相同的scale进行。
positional encoding层
有这个层的原因是:attention层是不会有时序信息的。具体的公式如下:

上式中,positional encoding是使用周期不一样的sin和cos计算出来的。
为什么使用自注意力机制

上表中,比较了四种不同类型的层的计算复杂度、顺序计算复杂度(就是说下一步计算需要等前边n步计算完成才能进行计算)、最大路径长度(一个信息从一个点走到另一个点需要走多远)。从表中可以看出,当序列的长度和整个模型宽度差不多的时候且深度都一样的话,实际上attention、rnn、cnn三个模型的复杂度基本上是差不多的。但是attention在信息的糅杂性上好一些。
实际上,attention由于对模型做的假设很少,所以需要更多的数据和更大的模型才可以训练收敛。所以现在基于Transformer的模型都是特别大和特别贵。
训练设置(Training Settings)
文中指出,在训练的时候使用AdamW优化器对模型进行优化,同时使用drop out层对模型进行正则化操作,然后还使用Label Smoothing技术(最先出现在Inception V3中)。
Label Smoothing解释:在使用softmax做最后的输出的时候,传统操作是如果输出接近于1,那么才认为是正确的,但是这里采用设置阈值为0.1(表示只要对一个词预测的置信度等于或超过0.1,那么就认为是正确的。)
但是使用这种技术会导致最后的模型不确信度会增加。
Transformer中超参数的比较
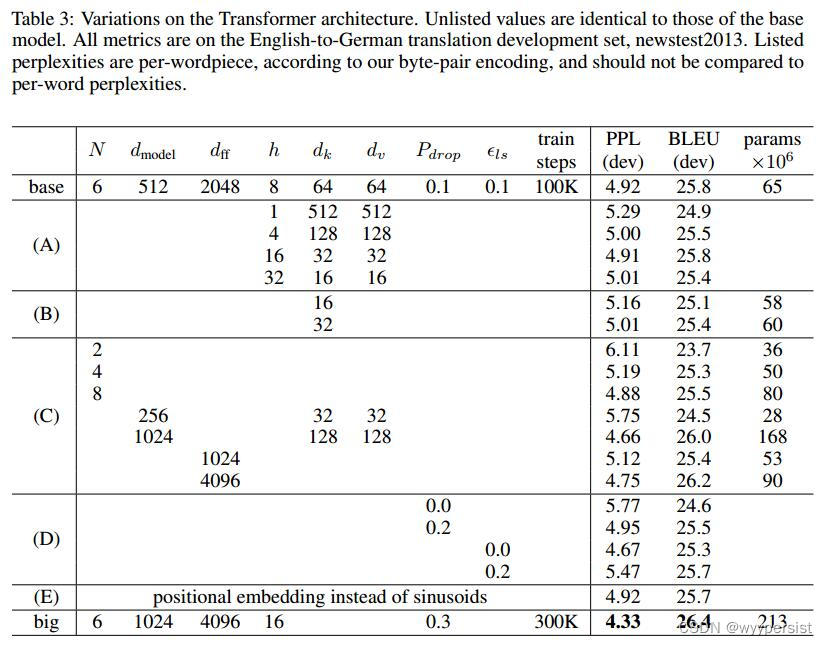
虽然上表中看上去很多超参数,但是在实际训练的时候,其中能调节的:N、 d m o d e l d_{model} dmodel、h(多头注意力中的头的数量h),其他的超参数都是计算得到的。
结论(Conclusion)
结论中首先说明,本文使用Transformer模型应用在机器翻译任务中,同时取代了之前使用较多的RNN layers,转而使用multi-headed slef-attention机制(这个也是Transformer模型的核心所在)。同时,结论又指出,在机器翻译任务上,Transformer相较于RNN或CNN架构的模型,具有更好性能和更快的训练收敛速度。然后,作者又说,对于Transformer这种纯注意力机制的模型感到激动(这在后边的爆发的基于Transformer的各种任务模型架构上得到了印证)。将Transformer模型架构用在输入形式不单纯为文本形式的其他形式,例如图片、视频等也是作者未来研究的方向。同时,使得生成不那么有序列也是未来的研究目标(个人举例:DETR中对N=100个预测框的生成就是一次性得到的)。
评价
这篇文章写作很简洁,一段话基本上就是在写一件事情。在写文章的时候可以将一些不重要的东西放到附录里面。
Attention实际上只是做了整个序列信息的的聚合操作。后边的MLP等层是缺一不可的。如果缺少了这些Attention实际上是什么都学不到的。