1.容器适配器
适配器是一种设计模式,该种模式是将一个类的接口转换成客户希望的另外一个接口。
容器适配器是STL中的一种重要组件,用于提供不同的数据结构接口,以满足特定的需求和限制。容器适配器是基于其他STL容器构建的,通过改变其接口和行为,使其适应不同的应用场景。
STL中有三种常见的容器适配器:stack、queue和priority_queue。
虽然stack和queue中也可以存放元素,但在STL中并没有将其划分在容器的行列,而是将其称为容器适配器,这是因为stack和队列只是对其他容器的接口进行了包装,STL中stack和queue默认使用deque,比如:


而priority_queue默认使用vector

2.stack的介绍和使用
stack的介绍
-
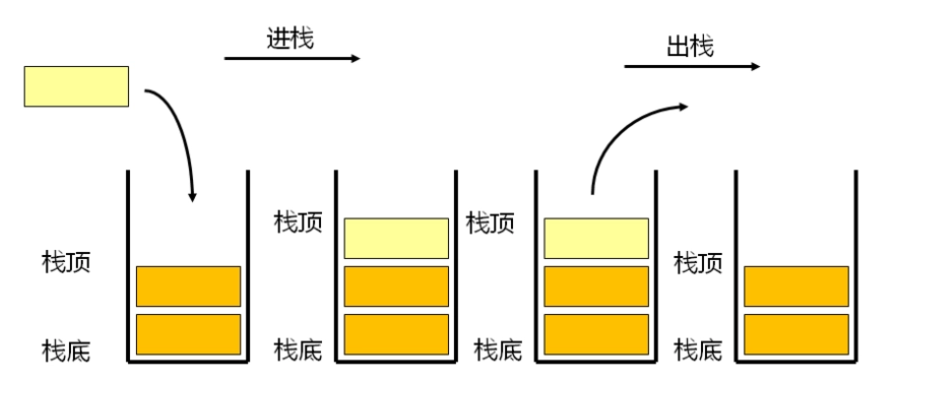
stack是一种容器适配器,专门用在具有后进先出操作的上下文环境中,其删除只能从容器的一端进行元素的插入与提取操作。
-
stack是作为容器适配器被实现的,容器适配器即是对特定类封装作为其底层的容器,并提供一组特定的成员函数来访问其元素,将特定类作为其底层的,元素特定容器的尾部(即栈顶)被压入和弹出。
-
stack的底层容器可以是任何标准的容器类模板或者一些其他特定的容器类,这些容器类应该支持以下操作:
-
empty:判空操作
-
back:获取尾部元素操作
-
push_back:尾部插入元素操作
-
pop_back:尾部删除元素操作
-
-
标准容器vector、deque、list均符合这些需求,默认情况下,如果没有为stack指定特定的底层容器, 默认情况下使用deque。
stack的使用
当你使用 std::stack 时,你可以使用以下一些重要的成员函数:
push(const T& value): 将元素value压入栈顶。pop(): 弹出栈顶元素,不返回其值。top(): 返回栈顶元素的引用,但不将其从栈中移除。size(): 返回栈中元素的数量。empty(): 检查栈是否为空,返回布尔值。swap(stack& other): 将当前栈与另一个栈other进行交换。
#include <iostream>
#include <stack>int main() {std::stack<int> myStack;// 将元素压入栈顶myStack.push(10);myStack.push(20);myStack.push(30);std::cout << "栈顶元素: " << myStack.top() << std::endl; // 输出:30std::cout << "栈的大小: " << myStack.size() << std::endl; // 输出:3myStack.pop(); // 弹出栈顶元素if (!myStack.empty()) {std::cout << "弹出元素后的栈顶元素: " << myStack.top() << std::endl; // 输出:20}std::stack<int> anotherStack;anotherStack.push(50);myStack.swap(anotherStack); // 交换两个栈的内容std::cout << "交换后 myStack 的大小: " << myStack.size() << std::endl; // 输出:1return 0;
}
stack的模拟实现
#pragma once
#include <deque>namespace phw {template<class T, class Container = std::deque<T>>class stack {public:void push(const T &x) {_con.push_back(x);}void pop() {_con.pop_back();}T &top() {return _con.back();}const T &top() const {return _con.back();}size_t size() const {return _con.size();}bool empty() const {return _con.empty();}void swap(stack<T, Container> &st) {_con.swap(st._con);}private:Container _con;};
}// namespace phw
3.queue的介绍和使用
queue的介绍
-
队列是一种容器适配器,专门用于在FIFO上下文(先进先出)中操作,其中从容器一端插入元素,另一端 提取元素。
-
队列作为容器适配器实现,容器适配器即将特定容器类封装作为其底层容器类,queue提供一组特定的 成员函数来访问其元素。元素从队尾入队列,从队头出队列。
-
底层容器可以是标准容器类模板之一,也可以是其他专门设计的容器类。该底层容器应至少支持以下操作:
-
empty:检测队列是否为空
-
size:返回队列中有效元素的个数
-
front:返回队头元素的引用
-
back:返回队尾元素的引用
-
push_back:在队列尾部入队列
-
pop_front:在队列头部出队列
-
-
标准容器类deque和list满足了这些要求。默认情况下,如果没有为queue实例化指定容器类,则使用标 准容器deque。
queue的使用
push(const T& value): 将元素value添加到队列的尾部。pop(): 弹出队列的头部元素,不返回其值。front(): 返回队列头部元素的引用。back(): 返回队列尾部元素的引用。size(): 返回队列中元素的数量。empty(): 检查队列是否为空。swap(queue& other): 交换两个队列的内容。
示例:
#include <iostream>
#include <queue>int main() {std::queue<int> myQueue;// 向队列尾部添加元素myQueue.push(10);myQueue.push(20);myQueue.push(30);std::cout << "队列头部元素: " << myQueue.front() << std::endl; // 输出:10std::cout << "队列尾部元素: " << myQueue.back() << std::endl; // 输出:30std::cout << "队列大小: " << myQueue.size() << std::endl; // 输出:3myQueue.pop(); // 弹出队列头部元素std::cout << "弹出元素后的队列头部元素: " << myQueue.front() << std::endl; // 输出:20std::queue<int> anotherQueue;anotherQueue.push(50);myQueue.swap(anotherQueue); // 交换两个队列的内容std::cout << "交换后 myQueue 的大小: " << myQueue.size() << std::endl; // 输出:1return 0;
}
queue的模拟实现
#pragma once
#include <deque>namespace phw//防止命名冲突
{template<class T, class Container = std::deque<T>>class queue {public://队尾入队列void push(const T &x) {_con.push_back(x);}//队头出队列void pop() {_con.pop_front();}//获取队头元素T &front() {return _con.front();}const T &front() const {return _con.front();}//获取队尾元素T &back() {return _con.back();}const T &back() const {return _con.back();}//获取队列中有效元素个数size_t size() const {return _con.size();}//判断队列是否为空bool empty() const {return _con.empty();}//交换两个队列中的数据void swap(queue<T, Container> &q) {_con.swap(q._con);}private:Container _con;};
}// namespace phw
4.priority_queue的介绍和使用
priority_queue的介绍
std::priority_queue 用于实现优先队列数据结构。优先队列是一种特殊的队列,其中的元素按照一定的优先级顺序进行排列,而不是按照插入的顺序。
std::priority_queue 使用堆(heap)数据结构来维护元素的顺序,通常用于需要按照一定规则获取最高优先级元素的场景。在默认情况下,std::priority_queue 会以降序排列元素,即最大的元素会被放置在队列的前面。你也可以通过提供自定义的比较函数来改变排序顺序。
priority_queue的使用
构造函数
默认构造函数: 创建一个空的优先队列。
std::priority_queue<T> pq; // 创建一个空的优先队列,T 是元素类型
带有比较函数的构造函数: 可以指定一个自定义的比较函数,用于确定元素的优先级顺序。
std::priority_queue<T, Container, Compare> pq;
T是元素类型。Container是底层容器类型,默认情况下使用std::vector。Compare是比较函数类型,用于确定元素的顺序。默认情况下,使用operator<来比较元素。
示例:
#include <iostream>
#include <queue>int main() {// 构造一个默认的优先队列,元素类型为 int,使用默认比较函数 operator<std::priority_queue<int> pq1;// 构造一个优先队列,元素类型为 int,使用自定义的比较函数 greater,实现最小堆std::priority_queue<int, std::vector<int>, std::greater<int>> pq2;// 构造一个优先队列,元素类型为 std::string,使用默认比较函数 operator<std::priority_queue<std::string> pq3;// 构造一个优先队列,元素类型为 double,使用 lambda 表达式作为比较函数,实现最大堆auto cmp = [](double a, double b) { return a < b; };std::priority_queue<double, std::vector<double>, decltype(cmp)> pq4(cmp);return 0;
}
成员函数
-
push(): 向优先队列中插入元素。
pq.push(value); // 插入元素 value -
pop(): 移除队列顶部的元素(即最高优先级元素)。
pq.pop(); // 移除队列顶部元素 -
top(): 获取队列顶部的元素(即最高优先级元素)。
T highestPriority = pq.top(); // 获取最高优先级元素 -
empty(): 检查队列是否为空。
bool isEmpty = pq.empty(); // 如果队列为空则返回 true,否则返回 false -
size(): 获取队列中的元素数量。
int numElements = pq.size(); // 获取队列中的元素数量
示例:
#include <iostream>
#include <functional>
#include <queue>
using namespace std;
int main(){priority_queue<int> q;q.push(3);q.push(6);q.push(0);q.push(2);q.push(9);q.push(8);q.push(1);while (!q.empty()){cout << q.top() << " ";q.pop();}cout << endl; //9 8 6 3 2 1 0return 0;
}
自定义比较函数
你可以通过提供自定义的比较函数来改变元素的排序顺序。比较函数应该返回 true,如果第一个参数应该排在第二个参数之前。
struct MyComparator {bool operator()(const T& a, const T& b) {// 自定义比较逻辑}
};std::priority_queue<T, Container, MyComparator> pq;
priority_queue的模拟实现
priority_queue的底层实际上就是堆结构,实现priority_queue之前,我们先认识两个重要的堆算法。(下面这两种算法我们均以大堆为例)
堆的向上调整算法
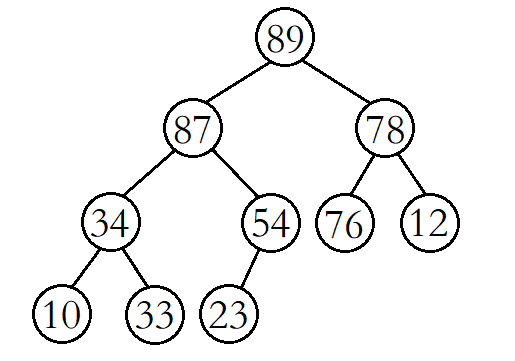
以大堆为例,堆的向上调整算法就是在大堆的末尾插入一个数据后,经过一系列的调整,使其仍然是一个大堆。
调整的基本思想如下:
1、将目标结点与其父结点进行比较。
2、若目标结点的值比父结点的值大,则交换目标结点与其父结点的位置,并将原目标结点的父结点当作新的目标结点继续进行向上调整;若目标结点的值比其父结点的值小,则停止向上调整,此时该树已经是大堆了。
例如,现在我们在该大堆的末尾插入数据88。
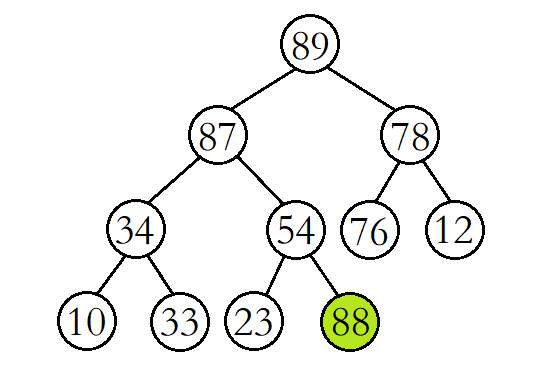
我们先将88与其父结点54进行比较,发现88比其父结点大,则交换父子结点的数据,并继续进行向上调整。
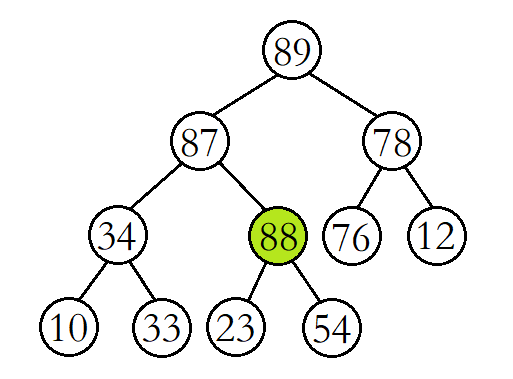
此时将88与其父结点87进行比较,发现88还是比其父结点大,则继续交换父子结点的数据,并继续进行向上调整。
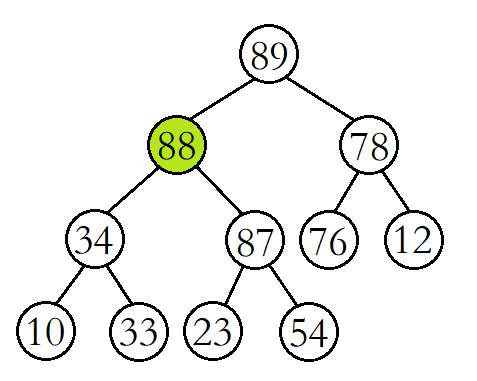
这时再将88与其父结点89进行比较,发现88比其父结点小,则停止向上调整,此时该树已经就是大堆了。
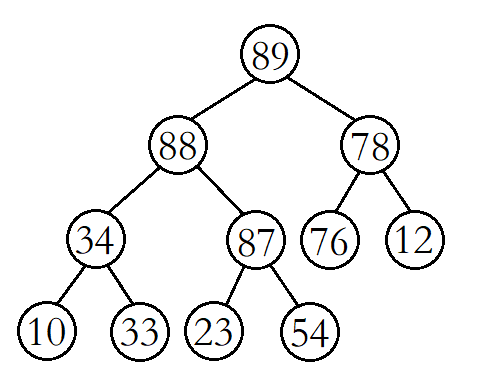
堆的向上调整算法代码:
void AdjustUp(int child) {int parent = (child - 1) / 2;while (child > 0) {// 默认less ,也就是parent<childif (_comp(_con[parent], _con[child]))// 通过所给比较方式确定是否需要交换结点位置{// 将父结点与孩子结点交换swap(_con[child], _con[parent]);// 继续向上进行调整child = parent;parent = (child - 1) / 2;} else// 已成堆{break;}}
}
堆的向下调整算法
以大堆为例,使用堆的向下调整算法有一个前提,就是待向下调整的结点的左子树和右子树必须都为大堆。
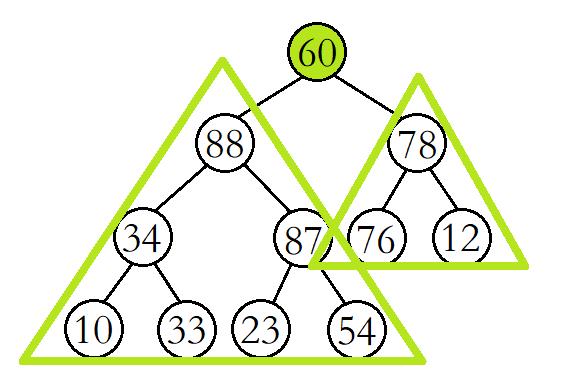
调整的基本思想如下:
1、将目标结点与其较大的子结点进行比较。
2、若目标结点的值比其较大的子结点的值小,则交换目标结点与其较大的子结点的位置,并将原目标结点的较大子结点当作新的目标结点继续进行向下调整;若目标结点的值比其较大子结点的值大,则停止向下调整,此时该树已经是大堆了。
例如,将该二叉树从根结点开始进行向下调整。(此时根结点的左右子树已经是大堆)
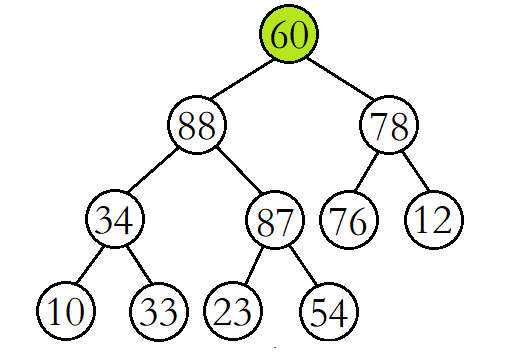
将60与其较大的子结点88进行比较,发现60比其较大的子结点小,则交换这两个结点的数据,并继续进行向下调整。
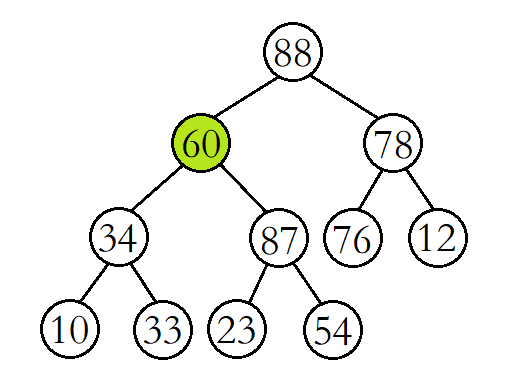
此时再将60与其较大的子结点87进行比较,发现60比其较大的子结点小,则再交换这两个结点的数据,并继续进行向下调整。
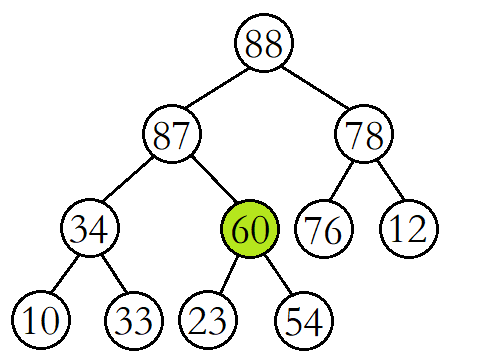
这时再将60与其较大的子结点54进行比较,发现60比其较大的子结点大,则停止向下调整,此时该树已经就是大堆了。

堆的向下调整算法代码:
void AdjustDown(int n, int parent) {int child = 2 * parent + 1;while (child < n) {//_comp(_con[child], _con[child + 1])表示child<child+1if (child + 1 < n && _comp(_con[child], _con[child + 1])) {child++;}// parent<childif (_comp(_con[parent], _con[child]))// 通过所给比较方式确定是否需要交换结点位置{// 将父结点与孩子结点交换swap(_con[child], _con[parent]);// 继续向下进行调整parent = child;child = 2 * parent + 1;} else// 已成堆{break;}}
}
模拟实现代码:
// 优先级队列使用vector作为其底层存储数据的容器,priority_queue就是堆
// 默认情况是大堆#include <iostream>
#include <vector>
using namespace std;
namespace phw {// 仿函数less(使内部结构为大堆)template<class T>struct less {bool operator()(const T &x, const T &y) {return x < y;}};// 仿函数greater(使内部结构为小堆)template<class T>struct greater {bool operator()(const T &x, const T &y) {return x > y;}};// 优先级队列template<class T, class Container = vector<T>, class Compare = greater<T>>class priority_queue {public:// 堆的向上调整void AdjustUp(int child) {int parent = (child - 1) / 2;while (child > 0) {// 默认less ,也就是parent<childif (_comp(_con[parent], _con[child]))// 通过所给比较方式确定是否需要交换结点位置{// 将父结点与孩子结点交换swap(_con[child], _con[parent]);// 继续向上进行调整child = parent;parent = (child - 1) / 2;} else// 已成堆{break;}}}// 堆的向下调整void AdjustDown(int n, int parent) {int child = 2 * parent + 1;while (child < n) {//_comp(_con[child], _con[child + 1])表示child<child+1if (child + 1 < n && _comp(_con[child], _con[child + 1])) {child++;}// parent<childif (_comp(_con[parent], _con[child]))// 通过所给比较方式确定是否需要交换结点位置{// 将父结点与孩子结点交换swap(_con[child], _con[parent]);// 继续向下进行调整parent = child;child = 2 * parent + 1;} else// 已成堆{break;}}}// 插入元素到队尾(并排序)void push(const T &x) {_con.push_back(x);AdjustUp(_con.size() - 1);// 将最后一个元素进行一次向上调整}// 弹出队头元素(堆顶元素)void pop() {swap(_con[0], _con[_con.size() - 1]);_con.pop_back();AdjustDown(_con.size(), 0);// 将第0个元素进行一次向下调整}// 访问队头元素(堆顶元素)T &top() {return _con[0];}const T &top() const {return _con[0];}// 获取队列中有效元素个数size_t size() const {return _con.size();}// 判断队列是否为空bool empty() const {return _con.empty();}private:Container _con;// vector容器Compare _comp; // 比较方式};
}// namespace phw
(_con[0], _con[_con.size() - 1]);_con.pop_back();AdjustDown(_con.size(), 0);// 将第0个元素进行一次向下调整}// 访问队头元素(堆顶元素)T &top() {return _con[0];}const T &top() const {return _con[0];}// 获取队列中有效元素个数size_t size() const {return _con.size();}// 判断队列是否为空bool empty() const {return _con.empty();}private:Container _con;// vector容器Compare _comp; // 比较方式};
}// namespace phw
![[Linux]命令行参数和进程优先级](https://img-blog.csdnimg.cn/img_convert/19270880a25074f42260e9062c83a050.png)