Doris是一款快速、可靠的分布式大数据仓库,是由阿里巴巴集团在2016年底开源发起的。它采用了分布式存储和计算技术,可以处理海量的数据,并且可以实现实时查询和快速分析。
Doris 数据仓库有以下特点:
- 分布式计算:利用分布式计算技术,Doris可以将大数据分片并行处理,提高数据处理效率。
- 数据存储:Doris采用了可扩展的列式存储引擎,可以高效地存储海量数据。
- 实时查询:Doris支持实时查询,可以在秒级别内获得结果。
- 多维分析:Doris支持多维分析功能,可以对多维度数据进行聚合和分析。
- 可扩展性:Doris采用分布式存储和计算技术,可以水平扩展,可支持PB级别的数据存储和处理。
总体来说,Doris数据仓库是一套强大的分布式大数据处理系统,适用于需要处理海量数据的企业和组织。
Stream load
Stream load 是一个同步的导入方式,用户通过发送 HTTP 协议发送请求将本地文件或数据流导入到 Doris 中。Stream load 同步执行导入并返回导入结果。用户可直接通过请求的返回体判断本次导入是否成功。Stream load 主要适用于导入本地文件,或通过程序导入数据流中的数据。
基本原理
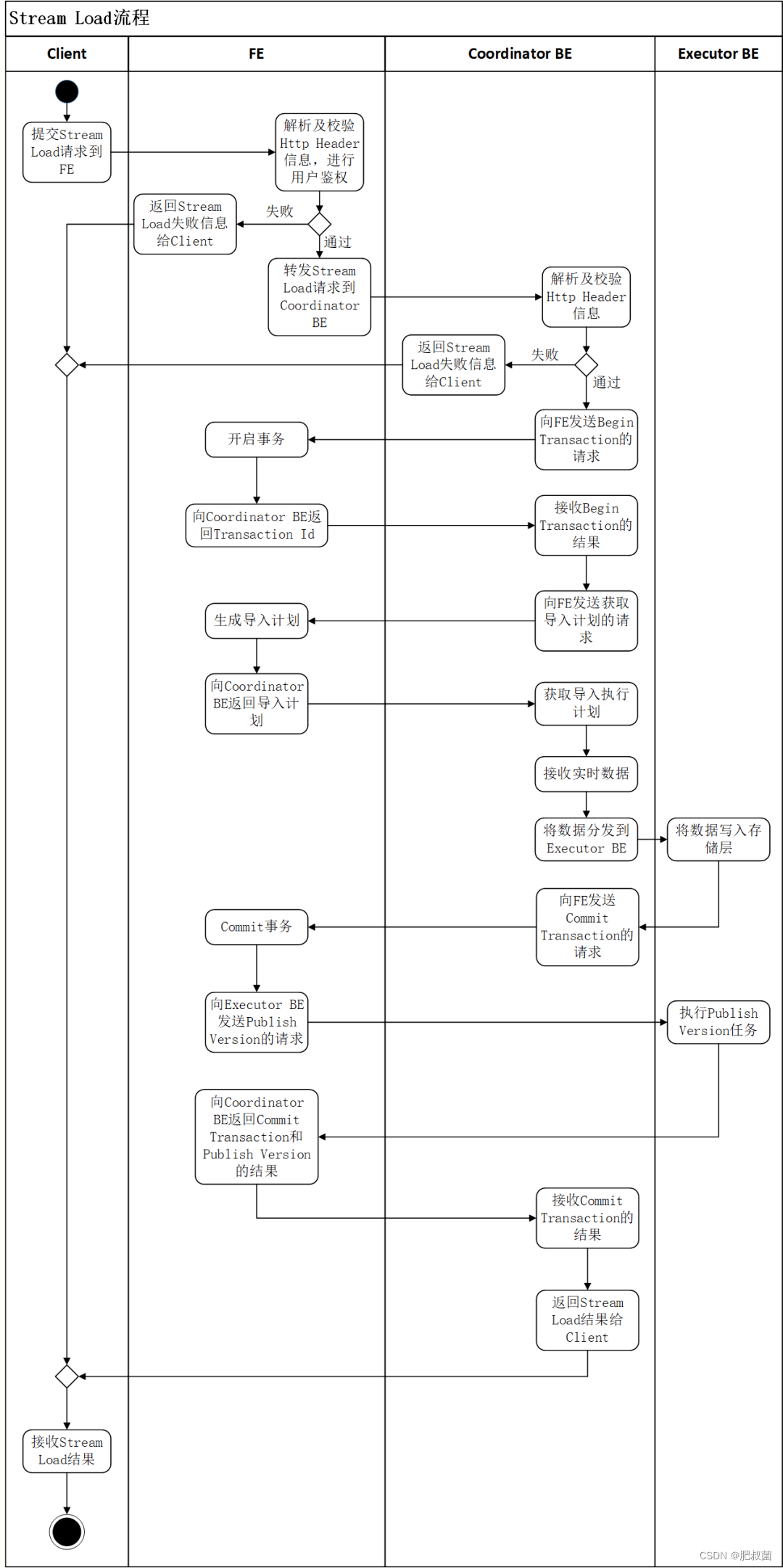
用户将Stream Load的Http请求提交给FE,FE会通过 Http 重定向(Redirect)将数据导入请求转发给某一个BE节点,该BE节点将作为本次Stream Load任务的Coordinator。在这个过程中,接收请求的FE节点仅仅提供转发服务,由作为 Coordinator的BE节点实际负责整个导入作业,比如负责向Master FE发送事务请求、从FE获取导入执行计划、接收实时数据、分发数据到其他Executor BE节点以及数据导入结束后返回结果给用户。用户也可以将Stream Load的Http请求直接提交给某一个指定的BE节点,并由该节点作为本次Stream Load任务的Coordinator。在Stream Load过程中,Executor BE节点负责将数据写入存储层。Stream Load的原理框图。在Coordinator BE中,通过一个线程池来处理所有的Http请求,其中包括Stream Load请求。一次Stream Load任务通过导入的Label唯一标识。用户通过 HTTP 协议提交导入命令。如果提交到 FE,则 FE 会通过 HTTP redirect 指令将请求转发给某一个 BE。用户也可以直接提交导入命令给某一指定 BE。导入的最终结果由 Coordinator BE 返回给用户。
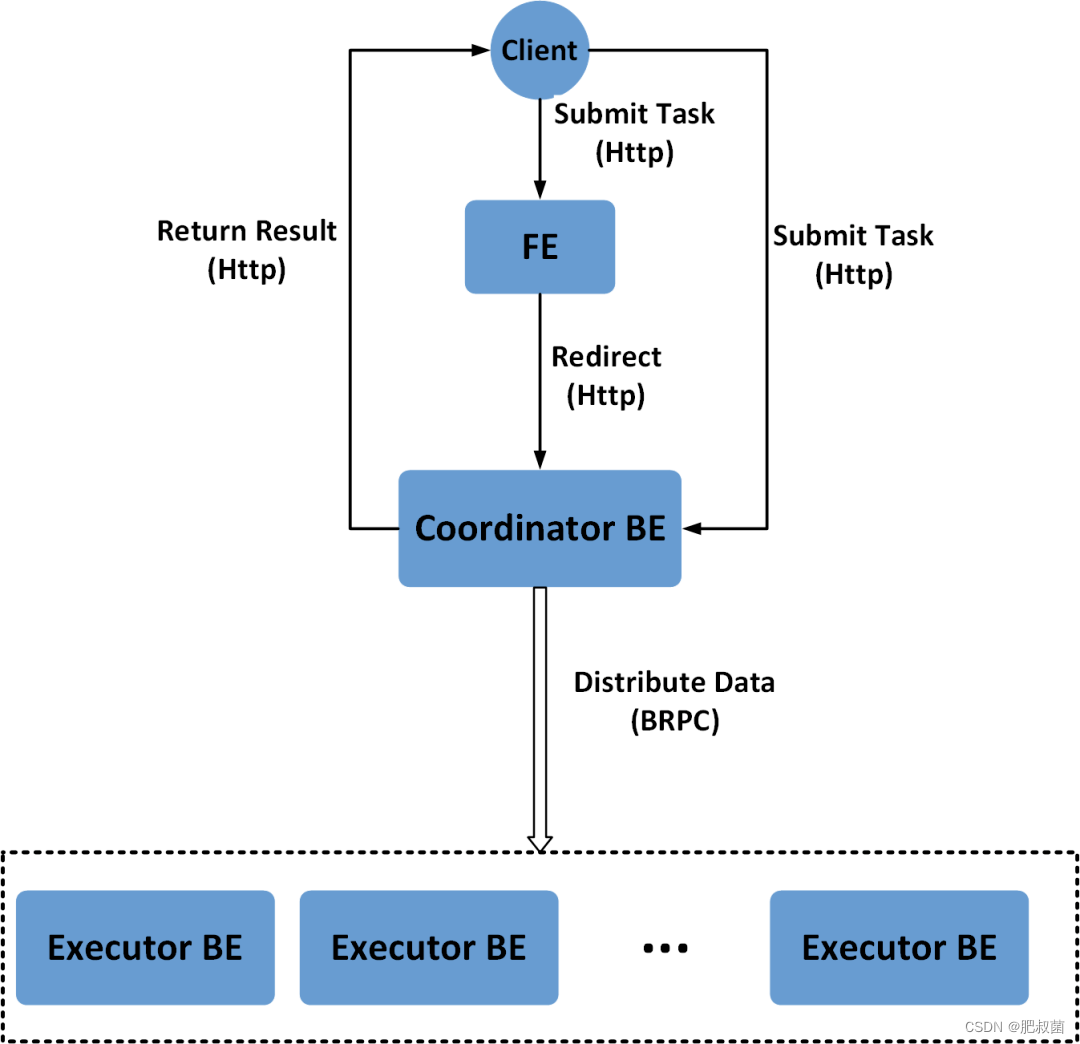
Stream Load的完整执行流程所示:
(1)用户提交Stream Load的Http请求到FE(用户也可以直接提交Stream Load的Http请求到Coordinator BE)。
(2)FE接收到用户提交的Stream Load请求后,会进行Http的Header解析(其中包括解析数据导入的库、表、Label等信息),然后进行用户鉴权。如果Http的Header解析成功并且用户鉴权通过,FE会将Stream Load的Http请求转发到一台BE节点,该BE节点将作为本次Stream Load的Coordinator;否则,FE会直接向用户返回Stream Load的失败信息。
(3)Coordinator BE接收到Stream Load的Http请求后,会首先进行Http的Header解析和数据校验,其中包括解析数据的文件格式、数据body的大小、Http超时时间、进行用户鉴权等。如果Header数据校验失败,会直接向用户返回Stream Load的失败信息。
(4)Http Header数据校验通过之后,Coordinator BE会通过Thrift RPC向FE发送Begin Transaction的请求。
(5)FE收到Coordinator BE发送的Begin Transaction的请求之后,会开启一个事务,并向Coordinator BE返回Transaction Id。
(6)Coordinator BE收到Begin Transaction成功信息之后,会通过Thrift RPC向 FE发送获取导入计划的请求。
(7)FE收到Coordinator BE发送的获取导入计划的请求之后,会为Stream Load任务生成导入计划,并返回给Coordinator BE。
(8)Coordinator BE接收到导入计划之后,开始执行导入计划,其中包括接收Http传来的实时数据以及将实时数据通过BRPC分发到其他Executor BE。
(9)Executor BE接收到Coordinator BE分发的实时数据之后,负责将数据写入存储层。
(10)Executor BE完成数据写入之后,Coordinator BE通过Thrift RPC 向FE发送Commit Transaction的请求。
(11)FE收到Coordinator BE发送的Commit Transaction的请求之后,会对事务进行提交,并向Executor BE发送 Publish Version的任务,同时等待Executor BE执行Publish Version完成。
(12)Executor BE异步执行Publish Version,将数据导入生成的Rowset变为可见数据版本。
(13)Publish Version正常完成或执行超时之后,FE向Coordinator BE返回Commit Transaction和Publish Version的结果。
(14)Coordinator BE向用户返回Stream Load的最终结果。