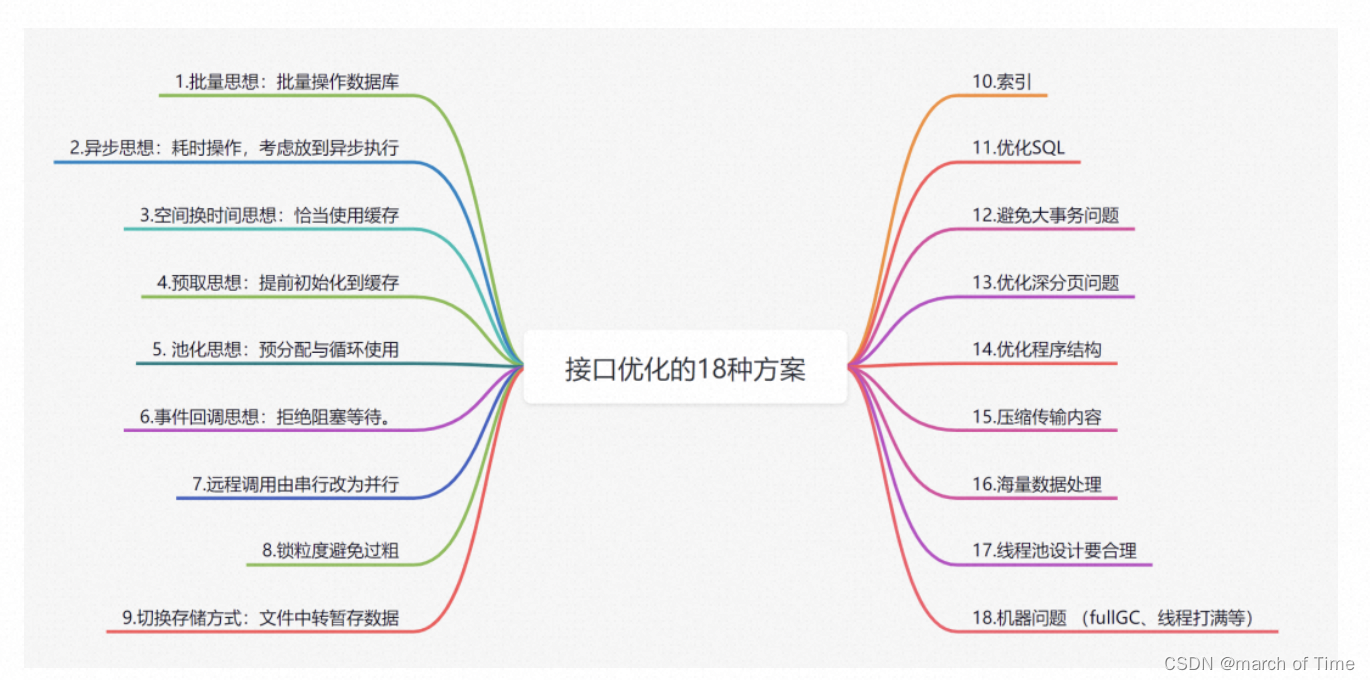
目录
- 批量
- 异步、回调
- 缓存
- 预取
- 池化
- 并行
- 锁粒度
- 索引
- 大事务
- 海量数据
批量
- 批量思想:批量操作数据库
优化前:
//for循环单笔入库
for(TransDetail detail:transDetailList){
insert(detail);
}
优化后:
batchInsert(transDetailList);
异步、回调
异步思想:耗时操作,考虑放到异步执行
耗时操作,考虑用异步处理,这样可以降低接口耗时。
将接口的耗时操作或IO操作改为异步执行,可以让接口在等待耗时操作完成的同时继续处理其他请求,提高并发处理能力。可以使用 CompletableFuture、CompletableFuture、@Async 注解等方式实现异步调用。
事件回调思想:拒绝阻塞等待。
如果你调用一个系统B的接口,但是它处理业务逻辑,耗时需要10s甚至更多。然后你是一直阻塞等待,直到系统B的下游接口返回,再继续你的下一步操作吗?这样显然不合理。
我们参考IO多路复用模型。即我们不用阻塞等待系统B的接口,而是先去做别的操作。等系统B的接口处理完,通过事件回调通知,我们接口收到通知再进行对应的业务操作即可。
缓存
空间换时间思想:恰当使用缓存。
在适当的业务场景,恰当地使用缓存,是可以大大提高接口性能的。缓存其实就是一种空间换时间的思想,就是你把要查的数据,提前放好到缓存里面,需要时,直接查缓存,而避免去查数据库或者计算的过程。
这里的缓存包括:Redis缓存,JVM本地缓存,memcached,或者Map等等。
预取
预取思想:提前初始化到缓存
预取思想很容易理解,就是提前把要计算查询的数据,初始化到缓存。如果你在未来某个时间需要用到某个经过复杂计算的数据,才实时去计算的话,可能耗时比较大。这时候,我们可以采取预取思想,提前把将来可能需要的数据计算好,放到缓存中,等需要的时候,去缓存取就行。这将大幅度提高接口性能。
池化
池化思想:预分配与循环使用
大家应该都记得,我们为什么需要使用线程池?
线程池可以帮我们管理线程,避免增加创建线程和销毁线程的资源损耗。
如果你每次需要用到线程,都去创建,就会有增加一定的耗时,而线程池可以重复利用线程,避免不必要的耗时。 池化技术不仅仅指线程池,很多场景都有池化思想的体现,它的本质就是预分配与循环使用。
比如TCP三次握手,大家都很熟悉吧,它为了减少性能损耗,引入了Keep-Alive长连接,避免频繁的创建和销毁连接。当然,类似的例子还有很多,如数据库连接池、HttpClient连接池。
以下是一些常见的应用池化思想的应用场景和实践方法:
连接池:数据库连接池是应用池化思想的一个典型应用。在项目中使用连接池可以避免频繁地创建和销毁数据库连接,提高数据库访问的性能。常见的连接池实现有 Apache Commons DBCP、HikariCP 等。
线程池:线程池是管理和复用线程资源的一种机制。在项目中使用线程池可以避免频繁地创建和销毁线程,提高线程的利用率和性能。Java 提供了 ThreadPoolExecutor 类来实现线程池,可以根据具体需求进行配置和使用。
对象池:对象池是管理和复用对象资源的一种机制。在项目中使用对象池可以避免频繁地创建和销毁对象,提高对象的利用率和性能。常见的对象池实现有 Apache Commons Pool 等。
缓存池:缓存池是将数据或计算结果缓存起来供后续使用的一种机制。在项目中使用缓存池可以减少重复计算的开销,提高系统的响应速度。常见的缓存池实现有 Redis、Ehcache 等。
资源池:除了上述具体的池化实现外,还可以根据项目的需求创建其他类型的资源池,如连接资源池、文件资源池等。通过池化思想可以有效地管理和复用资源,提高系统的性能和稳定性。
并行
远程调用由串行改为并行
假设我们设计一个APP首页的接口,它需要查用户信息、需要查banner信息、需要查弹窗信息等等。如果是串行一个一个查,比如查用户信息200ms,查banner信息100ms、查弹窗信息50ms,那一共就耗时350ms了,如果还查其他信息,那耗时就更大了。其实我们可以改为并行调用,即查用户信息、查banner信息、查弹窗信息,可以同时并行发起。
锁粒度
在高并发场景,为了防止超卖等情况,我们经常需要加锁来保护共享资源。但是,如果加锁的粒度过粗,是很影响接口性能的。
下面是一些常见的方法来限制锁的粒度:
细粒度锁:使用更小的锁范围来减少锁竞争。例如,可以将锁粒度从整个对象降低到对象的某个字段或方法上。
分离锁:将数据结构拆分成多个部分,并为每个部分使用独立的锁。这样不同部分之间的操作可以并行执行,减少锁竞争。
读写分离锁:对于读多写少的场景,可以使用读写锁(ReadWriteLock)来实现。读操作可以共享锁,而写操作需要独占锁。这样可以提高并发性能,因为多个读操作可以同时进行,而写操作会互斥。
锁分段:对于数据结构较大且操作并发较高的情况,可以将数据结构分成多个段,并为每个段使用独立的锁。这样不同段之间的操作可以并行执行,减少锁竞争。
无锁算法:对于特定的场景,可以使用无锁算法来替代锁。无锁算法利用原子操作和无锁数据结构,实现线程安全的并发访问。
乐观锁:在某些情况下,可以使用乐观锁机制,避免使用独占锁。乐观锁假设并发冲突较少,通过版本号或时间戳等机制来检测和解决并发冲突。
减少锁持有时间:尽量减少在锁内的操作时间,将非必要的操作移到锁外。这样可以缩小锁的范围,减少锁竞争。
索引
提到接口优化,很多小伙伴都会想到添加索引。没错,添加索引是成本最小的优化,而且一般优化效果都很不错。
索引优化这块的话,一般从这几个维度去思考:
你的SQL加索引了没?
你的索引是否真的生效?
你的索引建立是否合理?
关于索引原理可以参考:索引原理
大事务
避免大事务问题
为了保证数据库数据的一致性,在涉及到多个数据库修改操作时,我们经常需要用到事务。而使用spring声明式事务,又非常简单,只需要用一个注解就行@Transactional
所谓大事务问题就是,就是运行时间长的事务。由于事务一致不提交,就会导致数据库连接被占用,即并发场景下,数据库连接池被占满,影响到别的请求访问数据库,影响别的接口性能。
大事务引发的问题主要有:接口超时、死锁、主从延迟等等。因此,为了优化接口,我们要规避大事务问题。我们可以通过这些方案来规避大事务:
RPC远程调用不要放到事务里面
一些查询相关的操作,尽量放到事务之外
事务中避免处理太多数据
海量数据
海量数据处理,考虑NoSQL
之前看过几个慢SQL,都是跟深分页问题有关的。发现用来标签记录法和延迟关联法,效果不是很明显,原因是要统计和模糊搜索,并且统计的数据是真的大。最后跟组长对齐方案,就把数据同步到Elasticsearch,然后这些模糊搜索需求,都走Elasticsearch去查询了。
我想表达的就是,如果数据量过大,一定要用关系型数据库存储的话,就可以分库分表。但是有时候,我们也可以使用NoSQL,如Elasticsearch、Hbase等。