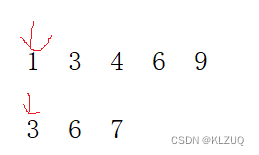聚集索引和非聚集索引
聚集索引和非聚集索引的根本区别是表记录的排列顺序和与索引的排列顺序是否一致。
1、聚集索引
聚集索引表记录的排列顺序和索引的排列顺序一致(以InnoDB聚集索引的主键索引来说,叶子节点中存储的就是行数据,行数据在物理储器中的真实地址就是按照主键索引树形成的顺序进行排列的),所以查询效率快,只要找到第一个索引值记录,其余就连续性的记录在物理也一样连续存放。聚集索引对应的缺点就是修改慢,因为为了保证表中记录的物理和索引顺序一致,在记录插入的时候,会对数据页重新排序(因为在真实物理存储器的存储顺序只能有一种,而插入新数据必然会导致主键索引树的变化,主键索引树的顺序发生了改变,叶子节点中存储的行数据也要随之进行改变,就会发生大量的数据移动操作,所以效率会慢)。因为在物理内存中的顺序只能有一种,所以聚集索引在一个表中只能有一个。
2、非聚集索引
非聚集索引制定了表中记录的逻辑顺序,但是记录的物理和索引不一定一致(在逻辑上数据是按顺序排存放的,但是物理上在真实的存储器中是散列存放的),两种索引都采用B+树结构,非聚集索引的叶子层并不和实际数据页相重叠,而采用叶子层包含一个指向表中的记录在数据页中的指针方式。非聚集索引层次多,不会造成数据重排。所以如果表的读操作远远多于写操作,那么就可以使用非聚集索引。
3、对比两种索引的例子
聚集索引就类似新华字典中的拼音排序索引,都是按顺序进行,例如找到字典中的“爱”,就里面顺序执行找到“癌”。而非聚集索引则类似于笔画排序,索引顺序和物理顺序并不是按顺序存放的。总的来说,聚集索引的叶节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块
索引创建Demo
CREATE DATABASE `IndexDemo`
go
USE `IndexDemo`
go
CREATE TABLE `ABC`
(
`A` INT NOT NULL,
`B` CHAR(10),
`C` VARCHAR(10)
)
go
INSERT INTO `ABC` SELECT 1,'B','C'
UNION SELECT 5,'B','C'
UNION SELECT 7,'B','C'
UNION SELECT 9,'B','C'
go
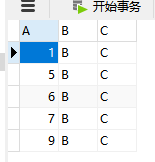
SELECT * FROM abc
这个时候插入一条数据,
INSERT INTO `abc` VALUES('6','B','C')此时的查询记录如下:

添加聚集索引,再查询数据显示则如下,此时发现表的顺序发生了变化,此时的排序按A字段的递增排序。这就说明了使用聚集索引如果插入新数据会进行重新排序

4、聚集索引和非聚集索引的区别总结:
- 聚集索引一个表只能有一个,而非聚集索引一个表可以存在多个
- 聚集索引存储记录是物理上连续存在,而非聚集索引是逻辑上的连续,物理存储并不连续
- 聚集索引:物理存储按照索引排序;聚集索引是一种索引组织形式,索引的键值逻辑顺序决定了表数据行的物理存储顺序
- 非聚集索引:物理存储不按照索引排序;非聚集索引则就是普通索引了,仅仅只是对数据列创建相应的索引,不影响整个表的物理存储顺序.
- 索引是通过B+树的数据结构来描述的,我们可以这么理解聚簇索引:索引的叶节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。
5、其他问题
我们需要搞清楚以下几个问题:
第一:聚集索引的约束是唯一性,是否要求字段也是唯一的呢? 不要求唯一!
分析:如果认为是的朋友,可能是受系统默认设置的影响,一般我们指定一个表的主键,如果这个表之前没有聚集索引,同时建立主键时候没有强制指定使用非聚集索引,SQL会默认在此字段上创建一个聚集索引,而主键都是唯一的,所以理所当然的认为创建聚集索引的字段也需要唯一。
结论:聚集索引可以创建在任何一列你想创建的字段上,这是从理论上讲,实际情况并不能随便指定,否则在性能上会是恶梦。
第二:为什么聚集索引可以创建在任何一列上,如果此表没有主键约束,即有可能存在重复行数据呢?
粗一看,这还真是和聚集索引的约束相背,但实际情况真可以创建聚集索引。
分析其原因是:如果未使用 UNIQUE 属性创建聚集索引,数据库引擎将向表自动添加一个四字节 uniqueifier 列。必要时,数据库引擎 将向行自动添加一个 uniqueifier 值,使每个键唯一。此列和列值供内部使用,用户不能查看或访问。
第三:是不是聚集索引就一定要比非聚集索引性能优呢?
如果想查询学分在60-90之间的学生的学分以及姓名,在学分上创建聚集索引是否是最优的呢?
答:否。既然只输出两列,我们可以在学分以及学生姓名上创建联合非聚集索引,此时的索引就形成了覆盖索引,即索引所存储的内容就是最终输出的数据,这种索引在比以学分为聚集索引做查询性能更好。就是说我们用学分去建立非聚集索引,那么搜索出来之后结点中的索引数据区只存有学分的数据,还需要根据叶子节点中数据区中的地址去查询,但是如果直接将要查询的学分字段和姓名字段创建一个联合索引(也是非聚集索引),这样在索引树中查找到数据之后直接就能在节点的索引数据区取得两个索引值,就不用再通过叶子节点中数据区里面的地址再去查询一次了。
第四:在MySQL数据库中通过什么描述聚集索引与非聚集索引的?
索引是通过B+树的形式进行描述的,我们可以这样区分聚集与非聚集索引的区别:InnoDB中的聚集索引的叶节点就是最终的数据节点,InnoDB中的非聚集索引叶子节点指向的是相应数据的的主键值。而MyISAM中非聚集索引的主键索引树和二级索引树的叶节仍然是索引节点,但它有一个指向最终数据的指针。
第五:在主键是创建聚集索引的表在数据插入上为什么比主键上创建非聚集索引表速度要慢?
聚集索引的缺点是对表进行修改速度较慢,这是为了保持表中的记录的物理顺序与索引的顺序一致,而把记录插入到数据页的相应位置,必须在数据页中进行数据重排,降低了执行速度。插入数据时速度要慢(时间花费在“物理存储的排序”上,也就是首先要找到位置然后插入)。非聚集索引指定了表中记录的逻辑顺序,但记录的物理顺序和索引的顺序不一致,聚集索引和非聚集索引都采用了B+树的结构,但非聚集索引的叶子层并不与实际的数据页相重叠,而采用叶子层包含一个指向表中的记录在数据页中的指针的方式。非聚集索引比聚集索引层次多,添加记录不会引起数据顺序的重组。这就是为什么主键上创建非聚集索引比主键上创建聚集索引在插入数据时要快的真正原因。
知识来源:
【2023年面试】mysql聚簇索引和非聚簇索引的区别_哔哩哔哩_bilibili
【MySQL】聚集索引和非聚集索引 - 知乎