编者按:随着大语言模型在自然语言处理领域的广泛应用,如何从人类反馈进行强化学习(RLHF)已成为一个重要的技术挑战。并且RLHF需要大量高质量的人工数据标注,这是一个非常费力的过程。
本文作者在数据标注领域具有丰富经验,他在本文深入探讨了RLHF过程中有关数据标注的关键问题。作者首先介绍了数据标注的基本要素,如任务分解、质量控制等,然后具体对比了有监督微调和人类偏好反馈这两类标注的关键差异,包括数据量、任务设计等方面。
作者以自己的丰富经验为基础,剖析了RLHF过程中数据标注的挑战,并给出了许多具体的建议。最后,他还总结了三点精辟见解,并展望了未来的研究方向。本文深入浅出,有助于读者全面理解RLHF过程中的数据标注问题,对AI研究者和实践开发者具有借鉴意义。
以下是译文,enjoy!
作者 | Dr. Dmitry Ustalov
编译 | 岳扬
目录
01 引言 Introduction
02 要标注什么?What to Annotate?
03 数据标注基础快速介绍 A Quick Tour to the Basics of Data Labeling
3.1 利用众包这种方式进行数据标注
3.2 数据标注的核心要素
04 有监督微调的数据标注 Supervised Fine-Tuning
4.1 如何获取文本数据?
4.2 如何对文本数据进行标注?
05 人类偏好反馈的数据标注 Human Preferences
5.1 将数据标注内容排序
5.2 需要标注多少数据?
5.3 奖励模型的结构
06 总结 Conclusion
这篇文章是Dmitry Ustalov和Hugging Face的Nathan Lambert[1],在ICML 2023[2]上发表的部分内容,重点介绍RLHF的数据标注。
想了解该研究的全部内容请浏览:https://doi.org/10.5281/zenodo.8186168

01 引言 Introduction
Who wants to do reinforcement learning from human feedback?
The entire room raises their hands.
Great! And who wants to annotate the data to obtain human feedback?
Only five, maybe ten hands remain.
谁愿意使用RLHF技术?
整个房间的人都举起了手。
太好了!那么,谁想要标注数据来使模型获得人类反馈?
只有五个人举手,也许之前举的十只手仍然还在。
我认为数据标注非常重要,尽管可能并不是每个人都愿意做数据标注。我们都知道,RLHF代表从人类反馈中进行强化学习,这两个方面都很重要。如果我们的基础数据集质量不高,不能很好地展示我们希望从模型中得到的东西,那么仅仅通过分布式训练来实现大型语言模型(LLM)是不够的。
我们希望LLM既有用又无害又诚实。但是计算机还不知道这些词的意思,所以需要人类反馈来调整模型朝着所期望的方向发展,来评估模型的输出,并避免强化学习(RL)中繁琐的reward engineering[3](译者注:类似特征工程)。
02 要标注什么?What to Annotate?
通过学习深度学习,我们可以训练模型。但要问训练 LLM 的最佳方式,却引发很多有趣的讨论。关于 LLM 的能力强弱以及使其性能高效所需的工作量,众说纷纭。以下给出两个经典的案例。有趣的是,这两个案例都来自同一家公司——Meta:
- 在最近发表的一篇预印论文中,Zhou等人[4](2023 年)提出了Superficial Alignment Hypothesis。他们认为模型已经具备了所需的全部知识,用户只需要定义和规定模型所需的输入和输出数据的具体格式即可。因此,他们认为不需要复杂的数据标注方案,只需要少量的指导说明就能完成任务。如果这个假设成立,又将会是一项重大突破,让我们拭目以待这篇论文是否会被接受吧。
- 与此相反,在提出 Llama 2 的那篇论文中,Touvron [5]等人(2023 年)声称 “LLMs 的超强写作能力从根本上说是由 RLHF 驱动的”,这说明需要有相当多的数据标注工作量。
现在再看看另外三个例子,试着看能否发现一些规律。首先是现在著名的 OpenAI 的 InstructGPT 相关图表(Ouyang等人[6],2022 年),然后是 Anthropic 的 Claude 论文中类似的一张图表(Bai等人[7],2022 年),最后但同样重要的是 Meta 的 Llama 2 论文中所提供的图表(Touvron 等人[5],2023 年)。



Training overview of InstructGPT (Ouyang et al., 2022), Claude (Bai et al., 2022), and Llama 2 (Touvron et al., 2023).
这三张图中有三个共同的步骤:
首先,我们通过一个被称为文本语料库的大型文档集合对模型进行预训练,使其能够在推理时预测下一个单词(next word prediction)。这一步不需要进行数据标注。
然后,我们在一个较小的精心编写的问题指令和回复集合上进行有监督微调(SFT)。
最后,利用人类的偏好来改进模型的行为(通过奖励模型(reward modeling)的强化学习过程)。
尽管每个步骤都比较直观,但细节决定成败。需要进行多少数据标注?需要进行多少次迭代?需要哪些类型的文本?需要具备什么样的专业知识?这一切都关乎设计决策。
我们需要通过文本和分数进行快速、准确且大规模的人工审核和调整。对于有监督微调(supervised fine-tuning),我们可以使用合成的、爬取的或已标注的数据。对于奖励模型,我们需要获取人类的偏好数据。
03 数据标注基础快速介绍 A Quick Tour to the Basics of Data Labeling
在我们继续讨论RLHF(强化学习和有监督学习的结合)中数据的重要性之前,需要简要介绍一下数据标注的基础知识。
谁来对数据进行标注?有很多选择:
- 经过训练的专业标注员(专家)
- 众包的非专业标注员(众包)
- 预训练的机器学习模型
- 以上三种方式的任意组合
无论是谁对数据进行标注,我们都必须设计相应的标注指导说明和质量控制手段。
3.1 利用众包这种方式进行数据标注
我将重点介绍众包这种数据标注方式,因为这是最具有扩展性的方法,而且可以很好地推广到其他类型的数据标注。我从 2012 年开始研究众包这种数据标注方式,并在最大的数据标注平台之一工作了四年。根据我的经验,我坚信数据标注的核心挑战是如何让标注者和发布者一样理解任务。
通常,数据标注是在特定的数据标注平台上进行的。有 Label Studio[8]、CVAT[9]、Prodigy[10] 这样的本地部署平台(on-premise platforms),也有 Mechanical Turk[11]、Scale[12]、Toloka[13] 等提供托管服务的平台(hosted platforms)。使用本地部署平台(on-premise platforms)的好处是,需求方可以在自己的基础设施上部署这些平台,并根据自己的需求进行相应的调整。使用提供托管服务的平台的好处是,这些平台提供了便捷的标注工具和支付功能,开箱即用。
3.2 数据标注的核心要素
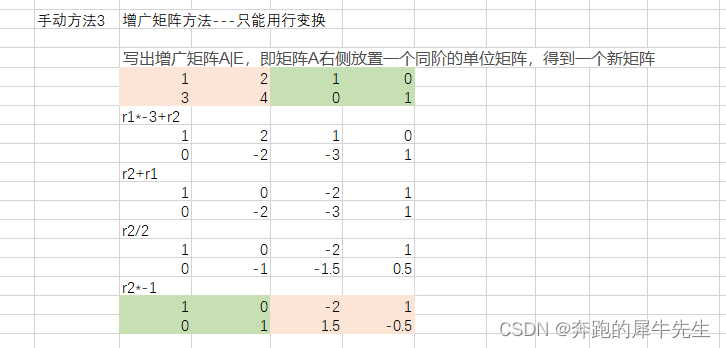
优秀的数据标注项目具备六个核心要素:1) 将标注任务分解成更小、更具体的子任务(decomposition);2) 提供给标注员的明确、详细的指导说明(instruction);3) 标注员执行标注任务所使用的界面或工具(task interface); 4) 用于监控和评估标注质量的方法和策略(quality control methods);5) 标注员在不同时间和不同任务中的一致性水平,以及他们对指导说明的理解程度(annotation reliability);6) 速度与成本之间的权衡(trade-off between speed and cost)。其中最重要的是第1)、2) 项。

成功数据标注项目的六大核心要素
任务分解(decomposition)是将原有的复杂任务分解成一系列更小、更简单的子任务。这些子任务会分配给许多标注员,以便每个子任务都能得到两个或更多不同标注员的回答。
将任务分解的主要优点是可以解决极其棘手的问题。例如,如果我们想对一个图像数据集使用拉框标注,该怎么办呢?我们可以使用包含两个子任务的任务序列:首先我们要求标注员拉一个边界框,然后要求标注员指示该边界框是否被正确绘制。
一个优秀的任务指导说明应当包括标注任务的目标、标注员界面介绍、所需的操作步骤、好的操作和坏的操作示例、处理罕见和非明显情况的说明以及相关参考资料。要在第一次尝试时就写出一份好的说明是非常困难的,可以参考“No Vehicles in the Park”[14]这个案例来了解这个问题,这是一个非常好的例子。
通常,如果任务分解做得好,指导说明和操作界面都会比较简单,标注员会以更高的质量完成任务,用于监控和评估标注质量的方法和策略能够可靠地工作,并且很容易控制和优化标注成本。
现在让我们来到本文的主要内容。
04 有监督微调的数据标注 Supervised Fine-Tuning
在初始的模型训练和有监督微调过程中,通过输入文本内容,模型学习到根据给定语境预测下一个单词的能力。通常,这些文本内容来自于公开可获取的语料库,例如Common Crawl[15]、RefinedWeb[16](Penedo等[17],2023年)、The Pile(Gao等,2020年[18])等。那么,我们如何获取良好的prompt和回答呢?
一些公司已经确定了适合的prompt类型及其比例。比如OpenAI的InstructGPT(Ouyang等,2022年[6]):文本内容生成(45.6%)、开放式问答(12.4%)、头脑风暴(11.2%)、聊天(8.4%)、文本改写(6.6%)、内容摘要(4.2%)、封闭式问答(2.6%)、文本内容分类(3.5%)、其他类型(3.5%)和关键词提取(1.9%)。这些prompt类型及其所占比例并非随意选择的!OpenAI团队通过分析和标注其GPT-3用户交互的日志,按照实际的使用比例构建了该SFT数据集。
除了prompt类型,还有一个主要的问题是我们需要多少数据。通过分析最近发表的论文,我们得到了以下数据(单位:指令跟随数据组数):
- Llama 2 (Touvron et al., 2023[5]): 28K
- InstructGPT (Ouyang et al., 2022[6]): 15K
- Alpaca (Taori et al., 2023[19]): 52K
- Vicuna (Chiang et al., 2023[20]): 70K
- Dolly (Conover et al., 2023[21]): 15K
- OpenAssistant (Köpf et al., 2023[22]): 10K+
- Claude (Bai et al., 2022[7]): 137K + 369K
- WizardLM (Xu et al., 2023[23]): 624K
- LIMA (Zhou et al., 2023[4]): 1K
数据集的大小并不是最重要的,关键是要有高质量的prompt和相应的回答!
4.1 如何获取文本数据?
我们如何获取所需的文本数据呢?有三种方案:
1. 模型使用过程中衍生的数据集(Model-derived datasets) :基于用户与可用模型的交互数据。不过有一些公司禁止其他公司使用这种数据集训练商业竞品,但一些人出于研究目的仍然这样做。
2. 基于网络的数据集(Web-based datasets) :利用来自Reddit、Quora、Stack Exchange等社区的网络公开数据。然而,这些数据的使用是否得到许可通常不清楚,并且还需要进行额外的数据清洗。
- 通过众包形式标注的数据集(Crowdsourced datasets) :通过专家或其他标注员的人工输入来获取数据,这是最安全但也是最费力的一种方案。
以下是五个热门的公开可用数据集及其prompt和相应回答的摘要信息:
- Dolly[24]:由Databricks团队内部专家标注的数据集,包含15,000个条目。
- Alpaca:通过self-instruct方法将175个种子任务转化为52,000个条目,该数据集是使用OpenAI的GPT-3.5模型获得的模型使用过程中衍生的数据集(Model-derived datasets)。
- WizardLM:通过一组规则对Alpaca数据集进行复杂化和重新排列(complicate and re-arrange),获得了一个包含624,000个条目的更大数据集。
- ShareGPT[25]:这是一个浏览器插件,可以下载ChatGPT对话数据并将其存储在服务器(集中式)上。该数据集的使用许可证尚不清楚,但在一个由 70K 条目组成的该数据集子集上,训练出一个性能良好的 Vicuna 模型。
- OpenAssistant[26]:这是一个开源的通过众包形式标注的多语言数据集,包含prompt和指导说明、一个模型和一个让其可重用的数据标注框架。该数据集来自LAION(Stable Diffusion模型使用了该公司的数据集)。但需要确保标注志愿者的交互与用于训练最先进的LLM的交互类似。
无论何时使用过程中衍生的数据集(Model-derived datasets)方案时,我们都可以用人工标注来替换上游模型。
4.2 如何对文本数据进行标注?
初始 prompts 应由专家撰写或从可信的网络语料来源中获取,因为这些内容是有监督微调(SFT)数据的重要组成部分。不过,我们放心地对这些prompt的响应进行标注。
我最喜欢的众包案例之一发表在 Bernstein 等人(2010 年)[27]的一篇论文中,名为 Soylent。还有一组研究人员为Microsoft Word创建了一个插件,该插件无需使用任何机器学习方法,而是使用众包方法非常高效地执行文本摘要。他们提出了一种通用的数据标注模式,称为Find-Fix-Verify,将原始文本摘要任务分解为三个子任务:
- Find(寻找):给定文本样本,找出有问题的片段。
- Fix(修复):给定文本样本和有问题的片段,编写更好的片段。
- Verify(验证):判断所编写的片段是否更好。(是/否)
我们可以采用类似的方法来撰写回复。第一步,可以要求数据标注员根据给定的prompt编写回复。第二步,需要要求验证者验证该回复的好坏。 两者必须具有相同的指导说明,以便编写者和验证者有相同的(编写、评判)准则。
因此,我们要解决的不是看似非常困难的撰写回复问题,而是要解决了一个看似更简单的二元标签(是/否)汇总问题。 该问题在学术研究界已经或多或少得到解决(Zheng等,2017)[28]。对于较小的数据集,应选择多数票,对于包含1,000个以上回复的较大数据集,应使用Dawid-Skene(1979)[29]概率聚合模型。
用于有监督微调的数据标注非常重要,但却很难正确完成。这一切都与设计决策有关。你从哪里获取初始prompt?你是否打算使用合成数据(synthetic data)?你是否会请专业标注员参与?你需要哪些prompt,以及如何汇总数据?我强烈建议在上述验证步骤中使用已被标注的golden tasks来评估标注员(golden tasks仍然是以众包方式进行数据标注方案中最有效的质量控制方法),并且要注意数据的许可证问题。
05 人类偏好反馈的数据标注 Human Preferences
在完成初始语言模型的训练和微调后,我们会对其进行打磨,使其变得有益、无害和诚实。与有监督微调部分不同,根据人类反馈进行强化学习的任务设计更为简单。由于RLHF需要大量的标签,而且我们无法直接将人类意见转化为奖励函数(reward function),因此我们将使用奖励模型(reward model)来实现近似人类评分的效果。
给定prompt和相应的回答后,奖励模型会估算人类对其的评分。因此,我们需要根据 LLM 的训练细节来设计人工标注任务。如果我们为每个prompt只生成两个回答,那么可以坚持采用简单的二元分类任务设计。但如果像InstructGPT一样,有更多的回答呢?情况就变得更加复杂了,我们需要对其进行排序聚合。

对给定prompt的回答两两进行比较
5.1 将数据标注内容排序
有哪些可行的数据标注内容排序方案呢?
- 点对点(Pointwise)方案。 给定prompt和回答,为每个回答提供一个单一的数值分数。遗憾的是,不同的标注者有不同的主观评分标准,这使得进一步使用数据变得更加复杂。有些社区在后处理过程(post-processing)中进行分数标准化(score standardization)(Adelani等人,2022)[29],但这仍然并非进行排序的最可靠方式。
- 列表式(Listwise)方案。 给定prompt和回答,按照从最好到最差(或反之)的顺序进行排序。虽然从标注的角度来看这种方法很直观,但如何将其整合到模型训练过程中尚不清楚。
- 两两比较(Pairwise)方案。 给定prompt和回答,随机选择并标注成对的回答,并使用类似Bradley-Terry(1952)[30]的算法将标注的成对回答转化为单个回答分数。
大多数研究都使用两两比较方案。 可以去阅读OpenAI[31]和Hugging Face[32]公开发布的标注者指南。
5.2 需要标注多少数据?
Touvron等人(2023)[5]已经对现有的人类偏好数据集进行了详细的分析,具体见该论文中的表6:
- Anthropic Helpful[33]: 122K
- Anthropic Harmless[33]: 44K
- OpenAI Summarize:[34] 177K
- OpenAI WebGPT[35]: 20K
- Stack Exchange[36]: 1038K
- Stanford SHP[37]: 75K
- Synthetic GPT-J: 33K
由于人类的偏好是主观的,准备golden tasks变得更加困难。我建议使用其他表现较差的模型的合成数据,或者使用我们模型之前的快照版本,也可以使用不需要深入推理或复杂的思考的prompt对应的回答,或者具有类似主题的其他数据集。我们在过去曾成功应用过一个较小的模型,详见Pavlichenko和Ustalov(2023)[38]的研究。
(译者注:"Golden tasks"是指在标注任务中作为参考或标准的任务。这些任务通常由专家或高质量的标注者完成,其标注结果被认为是准确和可靠的。)
5.3 奖励模型的结构
尽管两两比较这种方案并不难实现,但我们还有另一个设计决策需要做:我们要将哪种粒度的反馈纳入奖励模型?如果我们只比较成对的回答,那么一个回答比另一个回答更好的标准是什么? 仅仅事实上的正确并不足够,因为回答可能是冒犯性的、粗鲁的或具有恶意的。因此,我们可能愿意实行多维的质量标准,如有益性、无害性和诚实性(Bai等人,2022)[7]。但是,您是要针对所有情况训练一个奖励模型,还是要混合三个模型,每个模型都对应专门的标准?

对奖励模型进行有益性(helpful)的标注
奖励模型可以让 LLM 展现其个性,并在有益性、无害性和诚实性之间保持平衡。 然而,我们必须做出一些艰难的设计决策。 每个prompt应有多少个回答?我们的抽样方法是什么?如何构建奖励模型和设计标注任务?如果决定进行数据标注,请使用合成数据进行质量控制。对于较长的文本,我们应该激励数据标注员发挥其专业特长。请注意,在训练完成后,类似的标注方法也可用于红队[39]的后处理步骤。(译者注:红队(Red Team)通常指的是一组人员或团队,负责模拟攻击者的角色,以评估系统的安全性和弱点。在本文中,红队的任务是对训练完成的模型进行进一步的评估和测试,以发现可能存在的漏洞或其他问题,并采取相应的后处理措施来改善模型的性能和可靠性。红队的后处理步骤旨在提高模型的鲁棒性和安全性,以确保其在实际应用中的可靠性和可用性。)
06 总结
以下是读者应该记住的三个关键要点:
- 对于有监督微调(SFT),数据标注规模应为10K+个prompt,对于根据人类反馈进行强化学习(Human Preferences),则应为100K+个prompt。
- 重点关注高质量的小型数据集,而不是较大的不受控数据集,因为数据标注并不容易。
- 数据标注员必须与提出需求方对标注任务的理解方式相同,因此应当在数据标注过程中使用合成数据(synthetic data)和交叉检查(cross-checks)进行质量控制。
目前,我认为未来的数据标注工作主要有三个主题。首先,目前对所需数据规模的估计是基于实验试错,那么对所需数据的理论要求是什么?其次,哪些指令类型更重要,如何找到它们?第三,最佳的流程和任务设计是什么?
在使用众包方式进行标注的方案中,我提到过几种数据汇总技术和质量控制方法。我们团队创建了一个名为Crowd-Kit[40]的开源Python库。该库高效地实现了上述所有方法,提供数据质量和数据标注者间一致性度量方法(译者注:可以帮助研究人员和开发人员了解数据集的可靠程度,并根据需要采取相应的措施来改进数据质量。还可以衡量不同数据标注员标注信息之间的一致性水平,并据此评估数据集的可靠性和一致性。),并提供了数据集加载器以高效地进行数据集的处理和实验。我强烈推荐您在使用通过众包形式标注的数据集(Crowdsourced datasets)时使用它。
参考资料
1.https://open.substack.com/users/10472909-nathan-lambert?utm_source=mentions
2.https://icml.cc/Conferences/2023
3.https://medium.com/toloka/reinforcement-learning-without-reward-engineering-60c63402c59f
4.https://arxiv.org/abs/2305.11206
5.https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
6.https://arxiv.org/abs/2203.02155
7.https://arxiv.org/abs/2204.05862
8.https://labelstud.io/
9.https://www.cvat.ai/
10.https://prodi.gy/
11.https://www.mturk.com/
12.https://scale.com/
13.https://toloka.ai/
14.https://novehiclesinthepark.com/
15.https://commoncrawl.org/
16.https://huggingface.co/datasets/tiiuae/falcon-refinedweb
17.https://arxiv.org/abs/2306.01116
18.https://arxiv.org/abs/2101.00027
19.https://crfm.stanford.edu/2023/03/13/alpaca.html
20.https://lmsys.org/blog/2023-03-30-vicuna/
21.https://www.databricks.com/blog/2023/04/12/dolly-first-open-commercially-viable-instruction-tuned-llm
22.https://arxiv.org/abs/2304.07327
23.https://arxiv.org/abs/2304.12244
24.https://www.databricks.com/blog/2023/04/12/dolly-first-open-commercially-viable-instruction-tuned-llm
25.https://sharegpt.com/
26.https://open-assistant.io/
27.https://doi.org/10.1145/1866029.1866078
28.https://doi.org/10.2307/2346806
29.https://aclanthology.org/2022.wmt-1.72
30.https://doi.org/10.2307/2334029
31.https://docs.google.com/document/d/1MJCqDNjzD04UbcnVZ-LmeXJ04-TKEICDAepXyMCBUb8/edit?usp=sharing
32.https://docs.google.com/document/d/1c5-96Lj-UH4lzKjLvJ_MRQaVMjtoEXTYA4dvoAYVCHc/edit?usp=sharing
33.https://huggingface.co/datasets/Anthropic/hh-rlhf
34.https://huggingface.co/datasets/openai/summarize_from_feedback
35.https://huggingface.co/datasets/openai/webgpt_comparisons
36.https://huggingface.co/datasets/HuggingFaceH4/stack-exchange-preferences
37.https://huggingface.co/datasets/stanfordnlp/SHP
38.https://doi.org/10.1145/3539618.3592000
39.https://huggingface.co/blog/red-teaming
40.https://github.com/Toloka/crowd-kit
本文经原作者授权,由Baihai IDP编译。如需转载译文,请联系获取授权。
原文链接:
https://evalovernite.substack.com/p/rlhf-math-aint-enough