ES 7.6 - API高阶操作篇
- 分片和副本
- 索引别名
- 添加别名
- 查询所有别名
- 删除别名
- 使用别名代替索引操作
- 代替插入
- 代替查询
- 场景实操
- 滚动索引
- 索引模板
- 创建索引模板
- 查看模板
- 删除模板
- 场景实操一把
- 索引的生命周期
- 数据迁移API
- GEO(地理)API
- 索引准备
- 矩形查询
- 圆形查询
- 多边形查询
- 自定义分词器
- 总结
分片和副本
只会CURD的boy可能对es的分片和副本概念都很模糊,更别提要怎么对一个索引设置一个合适的分片和副本大小了
分片:你可以认为是一个存储数据库,有几个分片就有几个库,本质上是将数据分片存储,达到更好的性能和容灾效果
副本:你可以认为是分片的从库,用来同步主分片的数据,平时不接受写的请求,但可以接受读的请求
怎么设置这两者的数量呢?假设ES集群有三个节点,那么分片数设置为3,副本设置为2
为什么这么设置?
首先ES是一个内存怪兽,性能全靠内存,一个分片的数据能全放内存里面这是性能最高的,所以一个节点最好只放一个分片,为什么要副本分片,因为节点有可能宕机,如果没有副本一旦宕机就失去了该主分片的数据读写能力了,有了副本,主分片挂了,副本还能升级为主,对外提供服务,像下面这个图一样,无论哪个节点宕机都不会造成太大的影响,至于数据丢失等问题不在本文讨论范围内
如下图所示:

怎么设置呢?在创建索引的时候就可以设置了
PUT http://{{es_ip}}:{{es_port}}/xxxx(索引名称)
{"settings":{"index": {"number_of_shards": "1", // 主分片数"number_of_replicas": "1" // 每个分片的副本数}}
}索引别名
别名是干嘛的?顾名思义就是可以替代索引的名称做一些操作,举个例子:
索引的设置和mapping一旦创建好后,是不能被修改的,但是后期扩容、字段类型变更怎么办?只能重新创建一个索引然后把旧的索引数据迁移过来吧,这要是停机迁移,那用户不得裂开?
这时候别名的好处就体现出来了,别名就等于是索引的一层代理,像上面那个场景我只需要改一下别名的指向就搞定了,多说无用,直接实操
注意:一个索引可以用多个别名,一个别名也可以赋给多个索引
添加别名
三个添加方式,唯一需要注意的就是is_write_index,这是干嘛的?
想想别名可以同时赋予多个索引,条件查询的时候好说,但插入的时候呢?我要是用别名用来插入,我咋知道要写入哪个索引呢?这个用处就是这个标识写入哪个,要是别名下只有一个索引的话,则不需要指定,默认写入,就好比一个没有负载均衡的代理
# 创建索引时直接添加别名 如下:我为alias_test2 添加了一个alias_test别名
PUT http://{{es_ip}}:{{es_port}}/alias_test2(索引名称)
"aliases": {"alias_test": {}
}# 创建索引后,为索引添加别名
// 1. 先创建索引
PUT http://{{es_ip}}:{{es_port}}/alias_test1 // 先创建索引
// 2.后为这个索引添加一个别名
PUT http://{{es_ip}}:{{es_port}}/alias_test1(索引名称)/_alias(别名命令)/alias_test(别名名称)# 使用别名命令 批量添加
POST http://{{es_ip}}:{{es_port}}/_aliases(别名命令)
{"actions": [{"add": {"index": "alias_test2", // 索引"alias": "data_alias", // 别名"is_write_index":true, // 可写,代表用data_alias别名写入的时候,写入这个alias_test2索引"filter":{ // 可以控制只访问这个索引的部分数据,比如这里就是只能访问id>10的数据"range":{"id":{"gte":10 }}}}}]
}查询所有别名
GET http://{{es_ip}}:{{es_port}}/_alias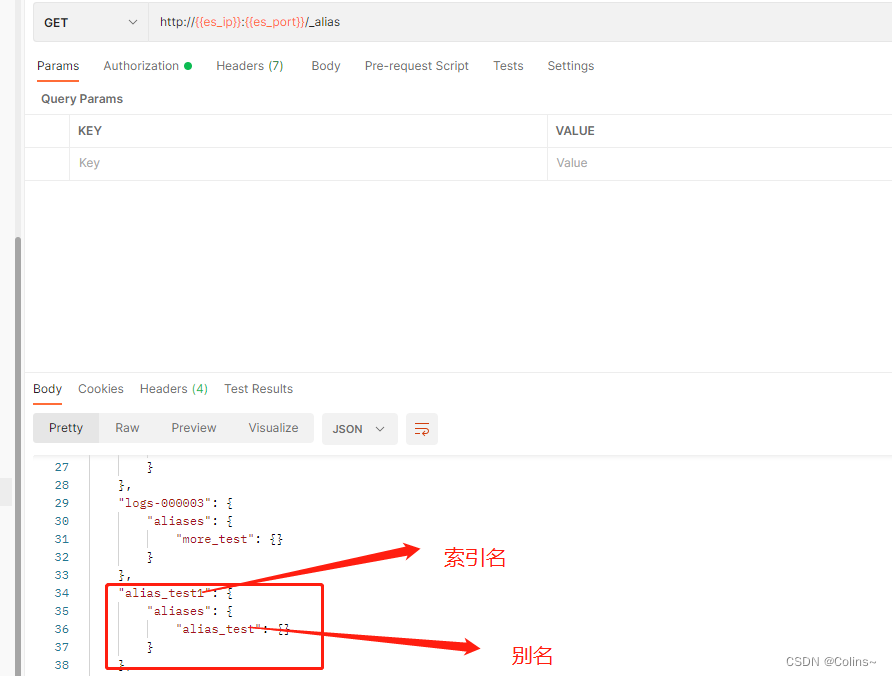
删除别名
# 根据索引删除别名
DELETE http://{{es_ip}}:{{es_port}}/alias_test2(索引名称)/_alias/alias_test(别名名称)# 用别名命令删除
POST http://{{es_ip}}:{{es_port}}/_aliases
{
"actions": [{"remove": {"index": "alias_test2","alias": "alias_test"}}]
}使用别名代替索引操作
代替插入
现在我们alias_test别名下只有alias_test2索引,我们用alias_test2别名来插入个文档,方式和用索引插入一个文档是一样的,此时可以插入
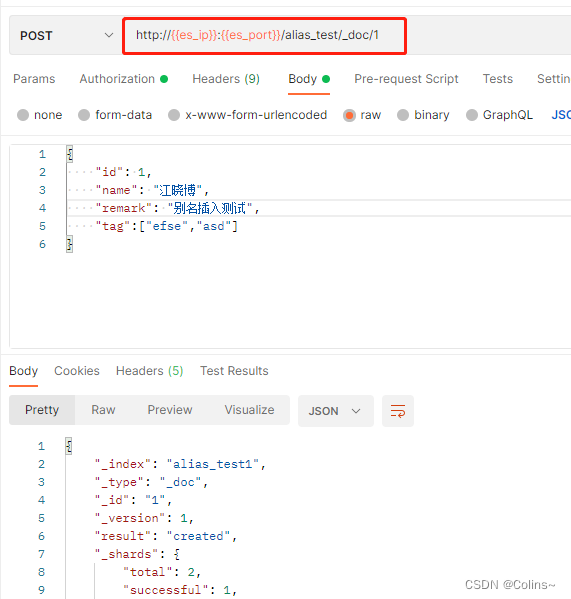
我们再给alias_test1索引添加alias_test别名,再插入试试,就会报错,要怎么解决呢?
- 第一种:插入不用别名,而是用对应索引名称
- 第二种:那就是is_write_index
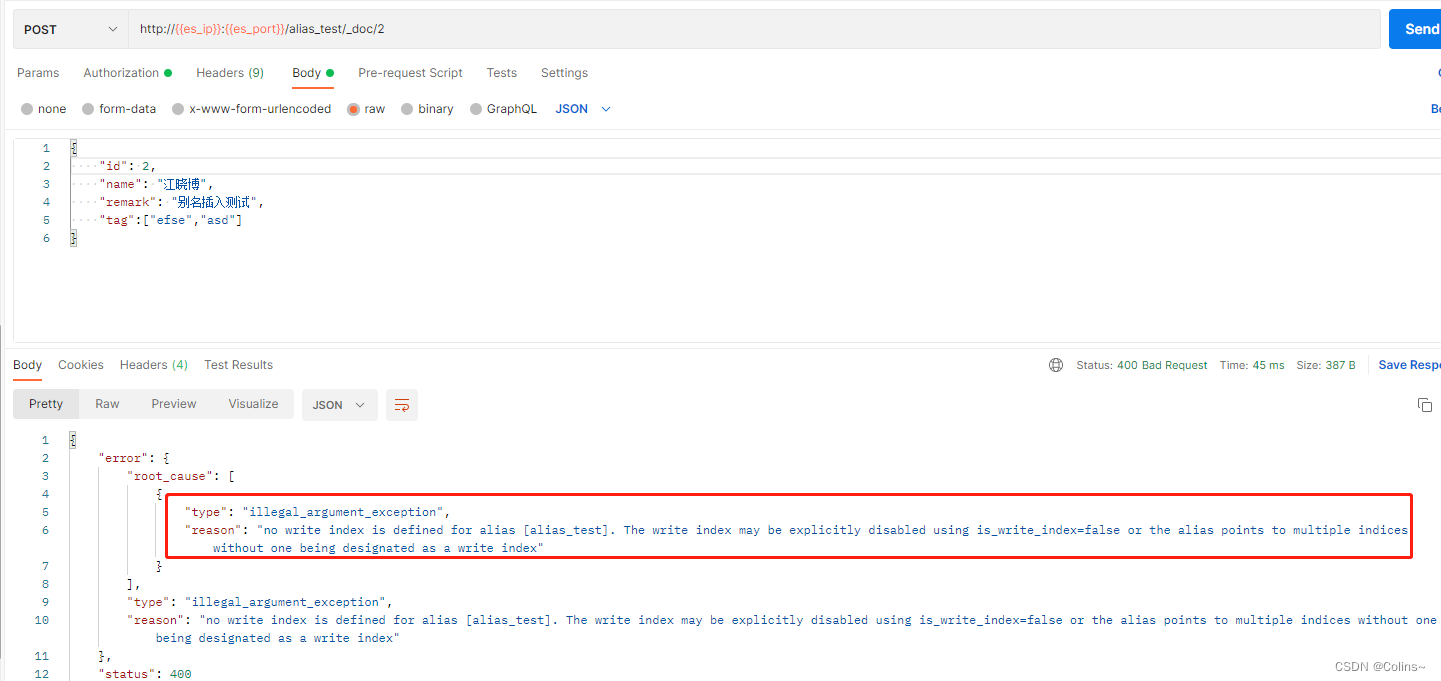
第一种毋庸置疑,咱们试试第二种,给test2加上:
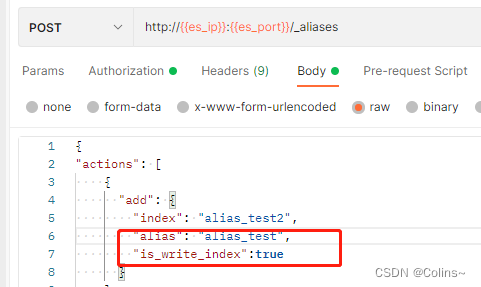
然后就可以正常插入了
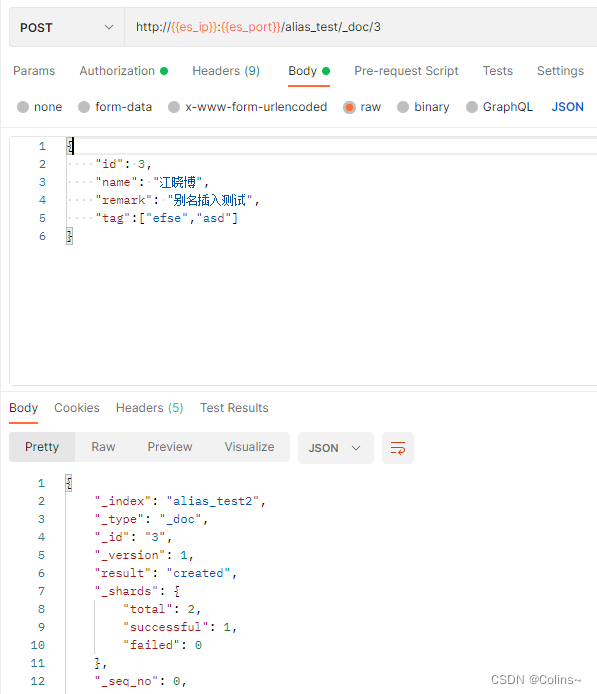
代替查询
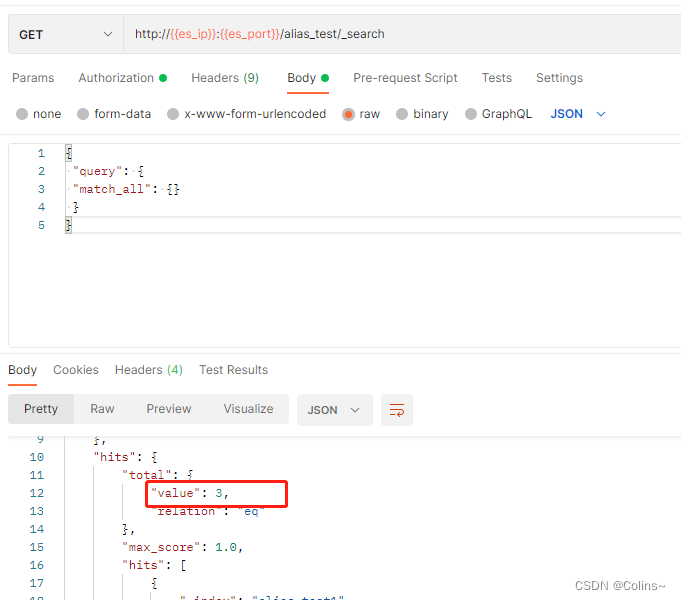
查询可以说一点影响没有,直接查就好了,现在alias_test别名下有两个索引,所以用这个别名查询的时候能同时查询两个索引的数据,所以这也是别名的好处之一
场景实操
怎么无缝迁移,切换索引?
首先前提条件有一个索引(old_index),有一个别名(proxy_index),代码中插入和查询的操作都是针对这个别名操作的(因为这别名下只有这一个索引)
好现在要迁移了,把这个索引数据迁移到新的,并无缝切换
- 创建一个新的索引(new_index)
- 为新的索引设置别名,并指定写入,此时写入的数据会写到新索引,查询会查询两个索引不影响
POST http://{{es_ip}}:{{es_port}}/_aliases
{
"actions": [{"add": {"index": "new_index","alias": "proxy_index","is_write_index":true}}]
}
- 然后数据迁移,把(old_index)数据迁移到(new_index)
- 最后删除(old_index)
以上看似好像很合理对吧,但是有个致命的问题:指定新的别名写入后,那根据ID修改、根据ID删除咋办?
我的建议是使用_delete_by_query和_update_by_query命令来代替,尽量不要用指定ID的处理
如果实在不行,可以看看下面的讨论:
这个不能走别名呀,因为别名下新索引的数据还在迁移过程中,是找不到数据的,所以也有人的方案是把上述流程的2、3步换一下,即先转移数据,转移后再切,这样的话所有操作都针对别名就行了,但是这个我个人觉得还是有个问题,假设迁移数据完成后,设置别名前,刚好又有数据写入了或者刚迁移完的数据,又马上被更新了,这就有几率导致新老索引数据不一致了,这还需要一个数据check任务去校验,我觉得也很蛋疼,那要怎么解决呢?
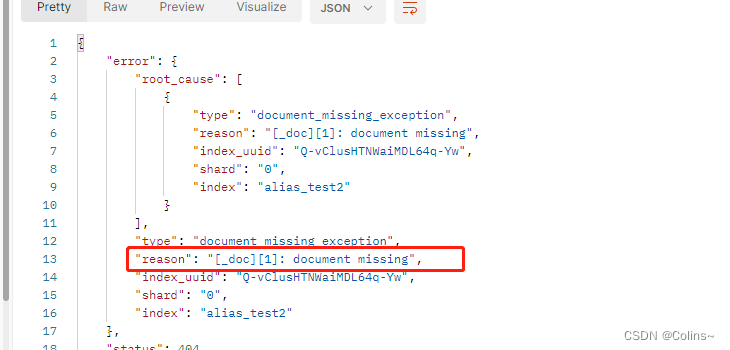
我觉得可以这样:流程上述不变,根据ID修改、根据ID删除一样走别名,在没迁移的过程中这样是没问题的,在迁移的时候就有可能出现文档找不到的错误,我们在代码层面捕捉这个错误,然后再用索引去执行一次就OK了,等于就是用别名找不到的情况下用索引去找,索引切换后,老的索引名会失效?索引名称可以做成动态配置的!
找不到时,报错信息如下:
好了,别名的妙用我就写到这了,咱们开启下一趴!
滚动索引
哈,这玩意又是干嘛的…
咱们试想一个场景,虽然现在有了分片了,但是单个分片数据量还是很很很大,可能包含了几年的数据,但是我们平时搜索一般都是最近一年的数据,这就意味着这些老数据会一直影响我们的查询性能,而且这么大的数据量也导致我们维护啊、迁移啊诸多一遍,能不能让单个分片数据量再缩小一点呢?要是把分片比作分库,那能不能做一个类似分表的操作呢?比如 xxx_table_1、xxx_table_2这样
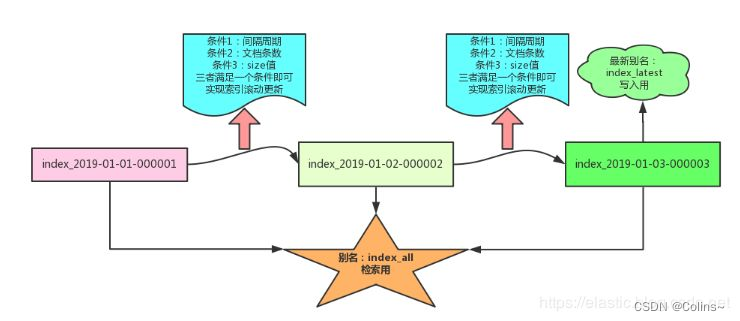
ε=(´ο`*)))唉,聪明的大兄弟可能想到了,切索引不就好了吗…,只要索引结构一致,那不就是分表嘛,但是什么时候切呢?以什么为标准切呢?谁去切呢?这时候就得用上滚动索引API了,这个的本质呢就是可以设置一些阈值,然后在执行这个API的时候呢会判断是否达到了这个阈值,如果达到了就自动帮你创建一个新的索引,后续的写入就会写到这个新的索引里面(基于别名)
网上找了个图:
具体要怎么做呢?就以下几步:
- 创建一个新的索引并设置好别名和mapping
PUT http://{{es_ip}}:{{es_port}}/logs-1
{"aliases": {"rollover_test": {}},"mappings":{"properties": {"id":{"type":"long"},"name":{"type":"text","analyzer":"ik_max_word"},"remark":{"type":"text","analyzer":"ik_max_word"}}}
}- 插入几条数据先
POST http://{{es_ip}}:{{es_port}}/rollover_test/_bulk
{"index": {"_id": 1}}
{"id":1,"name":"滚动测试1","remark":"asdfasdgas爱"}
{"index": {"_id": 2}}
{"id":2,"name":"滚动测试2","remark":"asdfasdgas爱"}
{"index": {"_id": 3}}
{"id":3,"name":"滚动测试3","remark":"asdfasdgas爱"}
{"index": {"_id": 4}}
{"id":4,"name":"滚动测试4","remark":"asdfasdgas爱"}- 执行滚动API
# 试运行,实际不会执行,可以查看执行后的结果
POST http://{{es_ip}}:{{es_port}}/rollover_test(上面索引的别名)/_rollover?dry_run# 直接执行
POST http://{{es_ip}}:{{es_port}}/rollover_test(上面索引的别名)/_rollover
{"conditions": {"max_age": "7d", // 天数:超过7天,滚动一次(创建新索引)"max_docs": 2, // 文档数:超过2个文档就滚动一次"max_size": "5gb" // 索引大小:超过5G滚动一次}
}
返回结果:
{"acknowledged": true,"shards_acknowledged": true,"old_index": "logs-1","new_index": "logs-000002", // 这个就是新的索引名称,新的索引是没有数据的,它并不会转移数据"rolled_over": true,"dry_run": false,"conditions": {"[max_size: 5gb]": false,"[max_docs: 2]": true, // 我们刚刚插入了4条,满足了这个条件,所以为true"[max_age: 7d]": false}
}-
查看效果
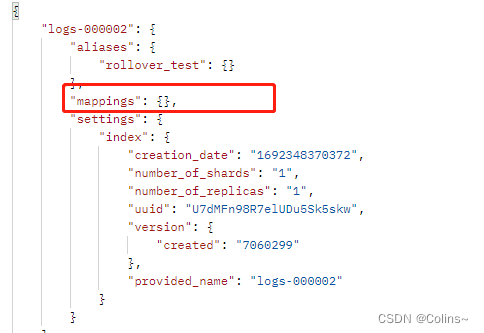
你会发现别名已经转移到了新的索引上面,老的索引已经没有别名了

当我们查看新索引的结构时,你会发现结构居然全是默认的,和老的索引都不一样,而且别名也都迁移过来了,就代表用别名查询不到之前老索引的数据了呀?这不得出大事?要咋办呢?不合理,绝对不合理
要解决这个问题,其实也很简单,就是还需要一个索引,同时在执行滚动API的时候,同时给新索引添加上去,包括结构啥的,就像:
{"conditions": {"max_age": "7d", // 天数:超过7天,滚动一次(创建新索引)"max_docs": 2, // 文档数:超过2个文档就滚动一次"max_size": "5gb" // 索引大小:超过5G滚动一次},........ // 这里添加新索引的配置
}
但是这样也不是非常的合适,能不能自动的就给新增的索引加上配置呢?每次这样多麻烦啊,索引结构一一变,这里也得变。
所以呀,这时候就需要聊聊索引模板这个东西了
**注意:**这种方式几乎全在操作别名,需要注意用ID操作的问题!!!!
索引模板
创建索引模板
PUT http://{{es_ip}}:{{es_port}}/_template(模板命令)/template_1(模板名称)
JSON传参:
{// 索引名称匹配,这里代表匹配所有logs-开头的索引// 意味了创建这样名称的索引的时候,会自动加上下面的配置"index_patterns":[ "logs-*"],"settings":{ // 索引的设置"number_of_shards":1},"aliases" : { // 别名"log_all" : {}},"mappings": { // 映射结构"_source": {"enabled": false},"properties": {"id":{"type":"long"},"name":{"type":"text","analyzer":"ik_max_word"},"remark":{"type":"text","analyzer":"ik_max_word"}}},// 优先级,假设一个索引同时匹配了多个模板,则会按照这个顺序依次加载// 越大,优先级越高,高的配置会覆盖低的"order":0
}咱们新增这个一个模板,再滚动一次上面的看看结果,还是先插入4条数据,然后滚动
# 插入数据
POST http://{{es_ip}}:{{es_port}}/rollover_test/_bulk
{"index": {"_id": 1}}
{"id":1,"name":"滚动测试1","remark":"asdfasdgas爱"}
{"index": {"_id": 2}}
{"id":2,"name":"滚动测试2","remark":"asdfasdgas爱"}
{"index": {"_id": 3}}
{"id":3,"name":"滚动测试3","remark":"asdfasdgas爱"}
{"index": {"_id": 4}}
{"id":4,"name":"滚动测试4","remark":"asdfasdgas爱"}# 滚动 (刚插入数据,会有一段时间才会刷新,这个立马执行这个滚动不一定成功)
POST http://{{es_ip}}:{{es_port}}/rollover_test/_rollover
这时候咱们再来看看这个新的索引logs-000003结构,可以看到结构啊,别名啊都有了,以后每次滚动log_all这个索引都会给新的索引,这样咱们用这个别名查询就可以查询所有的索引啦!
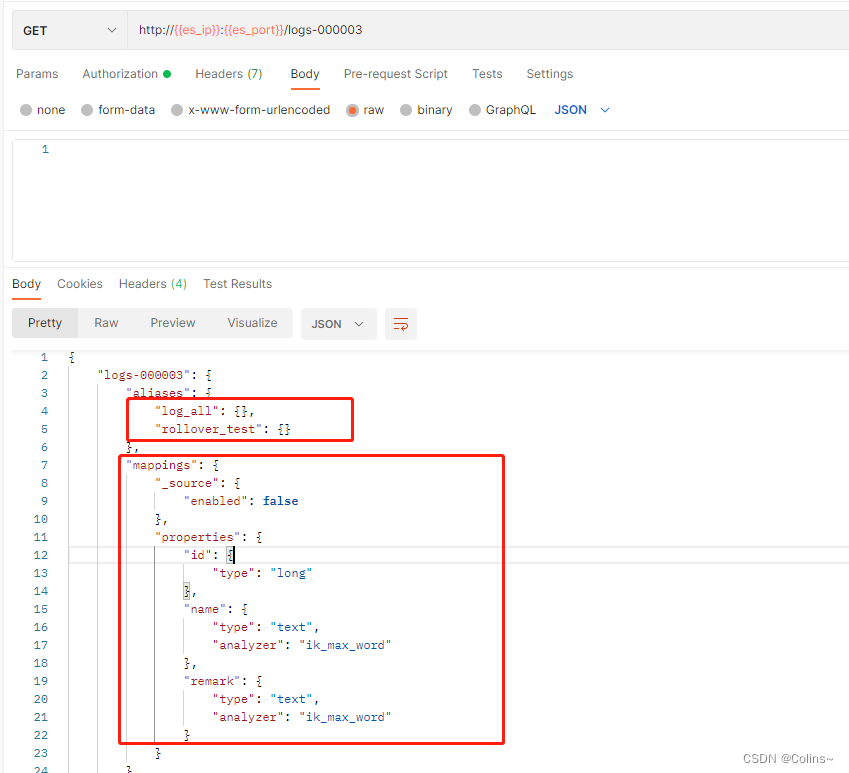
查看模板
# 一次性查询所有templat开头的模板
GET http://{{es_ip}}:{{es_port}}/_template(模板命令)/templat*(模板名称匹配)# 只查询一个模板
GET http://{{es_ip}}:{{es_port}}/_template(模板命令)/template_1(模板名称)删除模板
# 一次性删除所有templat开头的模板
DELETE http://{{es_ip}}:{{es_port}}/_template(模板命令)/templat*(模板名称匹配)# 只删除一个模板
DELETE http://{{es_ip}}:{{es_port}}/_template(模板命令)/template_1(模板名称)场景实操一把
大家可能经常看到一些索引为日期命名,每天更新,就类似以下这种:
xxx-2023-01-01-000001
xxx-2023-01-01-000002
xxx-2023-01-02-000003流程如下:
- 创建日志索引,索引名格式有点区别了这里用这个<logs-{now/d}-000001>,需要编码一次,可以用这个网站:编码网站
PUT http://{{es_ip}}:{{es_port}}/%3Clogs-%7Bnow%2Fd%7D-000001%3E(索引名称需要编码)
JSON传参:
{"aliases": {"logs_rollover": {}, // 这个是用来滚动的别名"logs_query":{} // 这个是用来给所有滚动的日志索引添加的别名,便于搜索所有},"mappings":{"properties": {"id":{"type":"long"},"name":{"type":"text","analyzer":"ik_max_word"},"remark":{"type":"text","analyzer":"ik_max_word"}}}
}
- 添加一个模板
PUT http://{{es_ip}}:{{es_port}}/_template/template_1
JSON传参:
{"index_patterns":[ // 匹配所有日志索引"logs-*"],"settings":{"number_of_shards":1},"aliases" : {"logs_query" : {} // 日志全局索引别名},"mappings": {"_source": {"enabled": false},"properties": {"id":{"type":"long"},"name":{"type":"text","analyzer":"ik_max_word"},"remark":{"type":"text","analyzer":"ik_max_word"}}},"order":0
}
- 添加几条数据
POST http://{{es_ip}}:{{es_port}}/logs_rollover/_bulk
{"index": {"_id": 1}}
{"id":1,"name":"滚动测试1","remark":"asdfasdgas爱"}
{"index": {"_id": 2}}
{"id":2,"name":"滚动测试2","remark":"asdfasdgas爱"}
{"index": {"_id": 3}}
{"id":3,"name":"滚动测试3","remark":"asdfasdgas爱"}
{"index": {"_id": 4}}
{"id":4,"name":"滚动测试4","remark":"asdfasdgas爱"}- 执行滚动
POST http://{{es_ip}}:{{es_port}}/logs_rollover/_rollover
{"conditions": {"max_age": "7d", // 天数:超过7天,滚动一次(创建新索引)"max_docs": 2, // 文档数:超过2个文档就滚动一次"max_size": "5gb" // 索引大小:超过5G滚动一次}
}
-
查看新索引结构
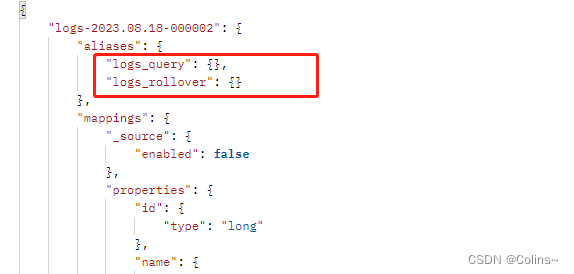
-
查看别名
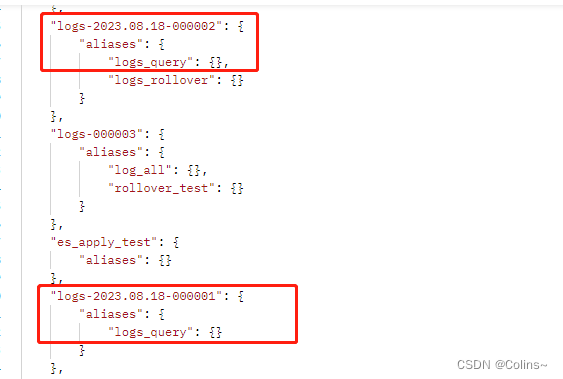
这就搞定了,你可以发现所有日志的索引名称都是非常标准、统一的格式,但这样需要注意的是插入只能用别名logs_rollover,查询只能用别名logs_query,不要用带文档ID的操作
看起来很简单是吧,但你以为这样就完了吗。。。。。。。。。想想这样还有什么缺点?
- 滚动需要人为操作
- 目前别名查询的是所有数据,但完全可以根据时间建很多个别名,如7天、一个月、季度、年,这样是不是会更高效
- 时间已经很久的冷数据怎么办?
- …等等
场景需要灵活运用…,下面提一下索引的生命周期
索引的生命周期
上述说的场景在以前可能都是定时脚本解决的,但是现在索引有了生命周期LLM管理,可以自动的帮我们做很多的事,这种偏运维、也不太好实操,就放个链接给大家简单了解一下吧
ES ILM实践
数据迁移API
如果要迁移索引的数据我是建议用这个_reindex命令,简单示例,并提供几个重要操作:
# 默认同步迁移、单任务执行
POST http://{{es_ip}}:{{es_port}}/_reindex# slices:并行数(最好和主分片数一致) wait_for_completion:异步执行
POST http://{{es_ip}}:{{es_port}}/_reindex?slices=x&wait_for_completion=false
{"source": {"index": "old_index_name", // 旧的索引名称"size": 5000, // 每次迁移的文档数量,这里就是一次批量转移5000个"query": { // 条件迁移,只迁移条件匹配的数据"term": {"user": "kimchy"}}},"dest": {"index": "new_index_name", // 新的索引名称"version_type": "internal" // 版本类型 }
}查看任务进度:
# 如果是异步执行的,会返回一个任务名称,可以根据这个名称查询任务信息
GET http://{{es_ip}}:{{es_port}}/_tasks/(任务名称)
GEO(地理)API
这个就是地理经纬度相关API,比如附近的人,某个地址附近的店,最近距离等等,很多人可能用Redis的GEO来实现,但Redis对于数据的存储量来讲可远远比不上ES
索引准备
操作和普通的其实都差不多,GEO无非就是一个特殊的字段类型,我们先创建一个索引
PUT http://{{es_ip}}:{{es_port}}/geo_test
{"mappings":{"properties": {"name":{"type":"text","analyzer":"ik_max_word"},"location": {"type": "geo_point" // GEO数据类型}}}
}
随意准备一点数据,想要更可观,可以自己去地图上捞一些点,我这里就随意了哈
http://{{es_ip}}:{{es_port}}/geo_test/_bulk
JSON 传参:
{"index": {"_id": 1}}
{"name":"唐聪健1", "location" : { "lat" : 40.12, "lon" : -71.34 }}
{"index": {"_id": 2}}
{"name":"唐聪健2", "location" : { "lat" : 50.12, "lon" : -60.34 }}
{"index": {"_id": 3}}
{"name":"唐聪健3", "location" : { "lat" : 60.12, "lon" : -50.34 }}
{"index": {"_id": 4}}
{"name":"唐聪健4", "location" : { "lat" : 70.12, "lon" : -40.34 }}
{"index": {"_id":5}}
{"name":"唐聪健5", "location" : { "lat" : 80.12, "lon" : -30.34 }}
{"index": {"_id": 6}}
{"name":"唐聪健6", "location" : { "lat" : 85.12, "lon" : -20.34 }}
{"index": {"_id": 7}}
{"name":"唐聪健7", "location" : { "lat" : 35.12, "lon" : -67.34 }}
{"index": {"_id": 8}}
{"name":"唐聪健8", "location" : { "lat" : 55.12, "lon" : -55.34 }}矩形查询
就是查询在一个矩形的框框内,有哪些点
GET http://{{es_ip}}:{{es_port}}/geo_test/_search
{"query": {"bool" : {"must" : {"match_all" : {}},"filter" : {"geo_bounding_box" : { // 矩形的命令"location" : { // 要查询的字段,一定要是GEO类型"top_left" : { // 矩形左上角的点经纬度"lat" : 80.73,"lon" : -30.1},"bottom_right" : { // 矩形右下角的点经纬度"lat" : 40.01,"lon" : -30.12}}}}}}
}圆形查询
就是查询以一个点为中心,半径多少的一个圆形内,有多少个点
GET http://{{es_ip}}:{{es_port}}/geo_test/_search
{"query": {"bool" : {"must" : {"match_all" : {}},"filter" : {"geo_distance" : {"distance" : "1000km", // 半径 单位:km、m、cm、mm、nmi、mi、yd、ft、in"distance_type": "arc", // arc:默认的方式,这种方式计算比较精确,但是比较慢 plane:这种方式计算比较快,但是可能不怎么准,越靠近赤道越准"location" : { // 圆心点"lat" : 40,"lon" : -70}}}}},"sort": [ {"_geo_distance": { // 根据与下面点的的距离排序"location": {"lat" : 40,"lon" : -70},"order": "desc","unit": "m", // 单位米"distance_type": "arc"}}]
}
多边形查询
GET http://{{es_ip}}:{{es_port}}/geo_test/_search
{"query": {"bool" : {"must" : {"match_all" : {}},"filter" : {"geo_polygon" : { // 多边形命令"location" : {"points" : [ // 点集合{"lat" : 40, "lon" : -70}, // 多边形点位经纬度{"lat" : 60, "lon" : -60},{"lat" : 20, "lon" : -20}]}}}}}
}
自定义分词器
之前咱们环境搭建的时候搞了一个IK分词器是吧,但是你会发现百度输入个拼音就出来东西了,想达到这个效果咱们还得去搞个拼音分词器,可以GitHub上面下一个:地址传送门
像之前安装ik一样,搞进去压缩,重启es就ok了,看看效果
GET http://{{es_ip}}:{{es_port}}/_analyze{
"text": "分词测试",
"analyzer": "pinyin"
}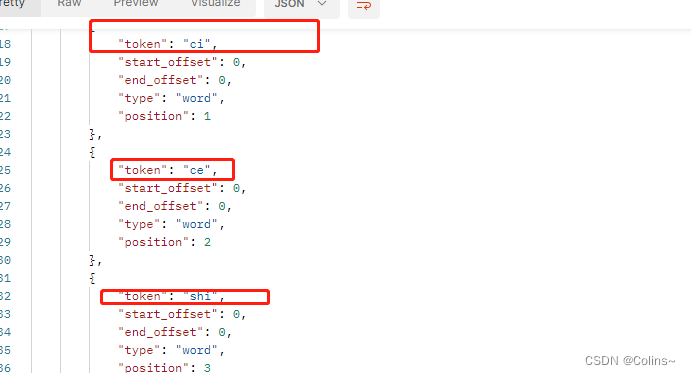
好像还不错?确实用拼音分词了,但是感觉差点意思啊,这都变成一个一个的拼音啊,我们应该是要分词的拼音,然后中文呢?难不成为了拼音舍弃中文分词?又或者要搞两个字段,一个中文分词,一个拼音分词?
肯定不合理!所以我们要自定义分词!!集两者为一体
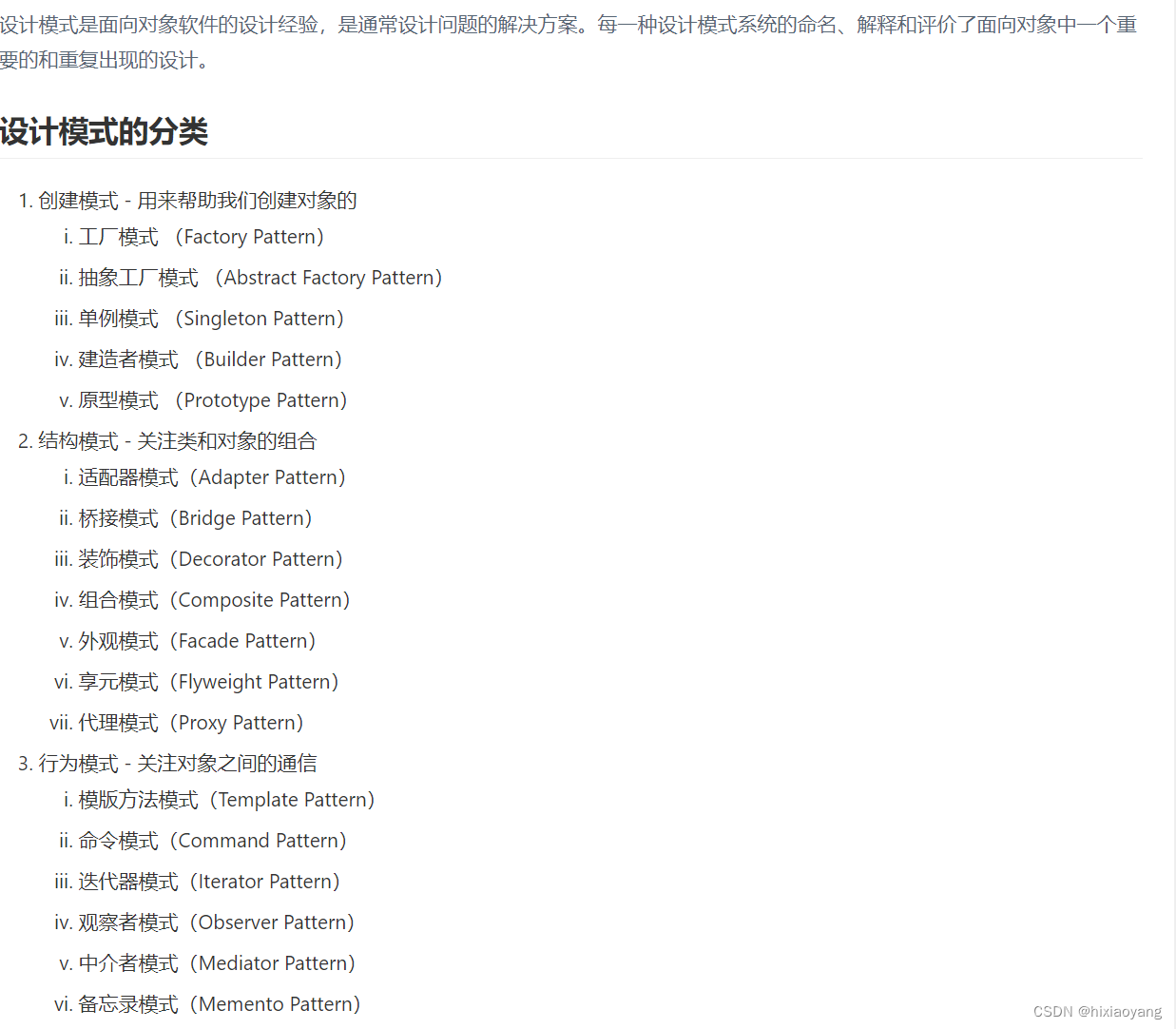
想要自定义分词,首先就得了解分词器的一丢丢原理了,有三个重要的部分:
| 部分 | 含义 |
|---|---|
| Character Filter | 在分词之前对原始文本进行处理,例如去除 HTML 标签,或替换特定字符。 |
| Tokenizer | 定义如何将文本切分为词条或 token。例如,使用空格或标点符号将文本切分为单词 |
| Token Filter | 对 Tokenizer 输出的词条进行进一步的处理,例如转为小写、去除停用词或添加同义词。 |
为了更好的理解,这里贴上一张网图:
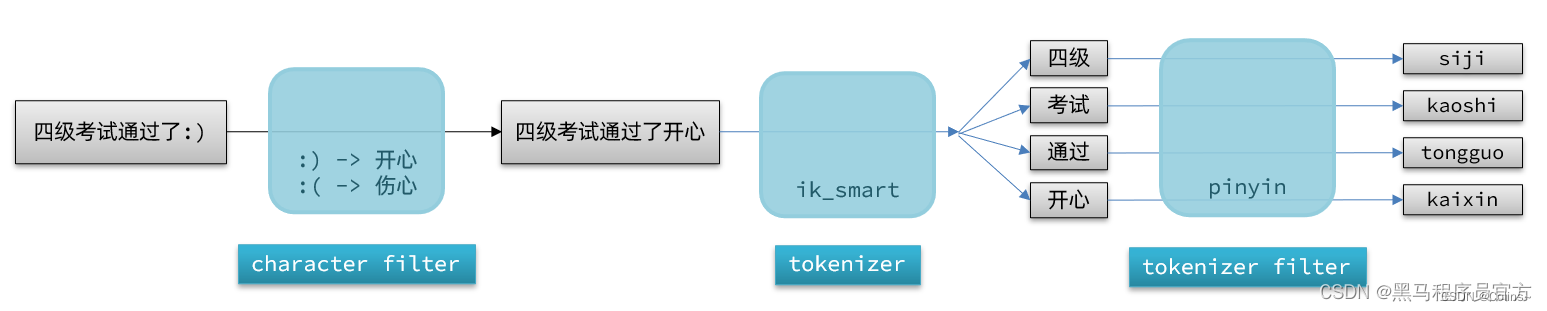
看了这个图,是不是就很清晰了,要达到我们的效果,只需要Tokenizer部分用IK分词器,Token Filter部分用拼音分词器是不是就搞定了,下面咱们实操一把:
# 创建自定义分词的索引
PUT http://{{es_ip}}:{{es_port}}/my_analyzer_test
{"settings": {"analysis": {"analyzer": {"my_analyzer": { // 自定义的分词名称"tokenizer": "ik_smart", // 这个就是 Tokenizer"filter": ["py_filter" // 过滤器]}},"filter": {"py_filter": {"type": "pinyin","keep_full_pinyin": false, // 拼音默认是一个字一个字的分词拼音,所以要关了"keep_joined_full_pinyin": true, // 按照词语拼音"remove_duplicated_term": true, // 删除重复的拼音"keep_original":true // 保留原始的输入,也就是保留汉字的分词}}}},"mappings": {"properties": {"name": {"type": "text","analyzer": "my_analyzer" // mapping这里的分词就要选择我们自定义的分词名称}}}
}
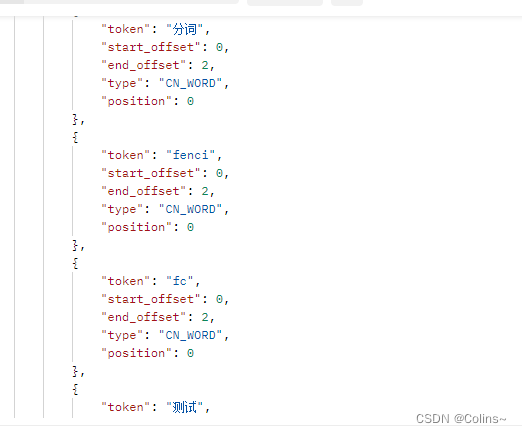
分词测试:
# 注意自定义分词是只属于索引的,索引这里分词命令前面要加上索引的名称
GET http://{{es_ip}}:{{es_port}}/my_analyzer_test/_analyze{
"text": "分词测试",
"analyzer": "my_analyzer" // 自定义分词的名称
}
大功告成!!
总结
本文讲了很多关于ES的进阶用法,让你不再局限于CURD,但是灵活度也就更高了,实际中什么场景用什么样的方案这就得你自己来把控了,本来还想写一些关于这些高阶API的Java应用层面的使用,最后想想还是算了,客户端得自己去摸索摸索才会更深刻;
好了,到了这我相信你比CURD boy应该更上一层楼了,但是你以为这就完了?才开始呢,少年!
这些东西都是ES整体中的冰山一角,更多的东西需要你自己去摸索、去看文档了,相信有了这些作为基础,文档你也基本能搞懂了,下面贴一些文档地址:
- 官方文档(我推荐是看这个,下面参考用)
- ES客户端文档
- ES API中文文档(这个我不知道是什么版本的ES,参考就好)
- 一个ES 中文教程网站(我同样不知道什么版本的,参考就好)
后续会分享一些关于ES的原理以及必须要知道的知识点,理论加上实践,你才能得到升华!