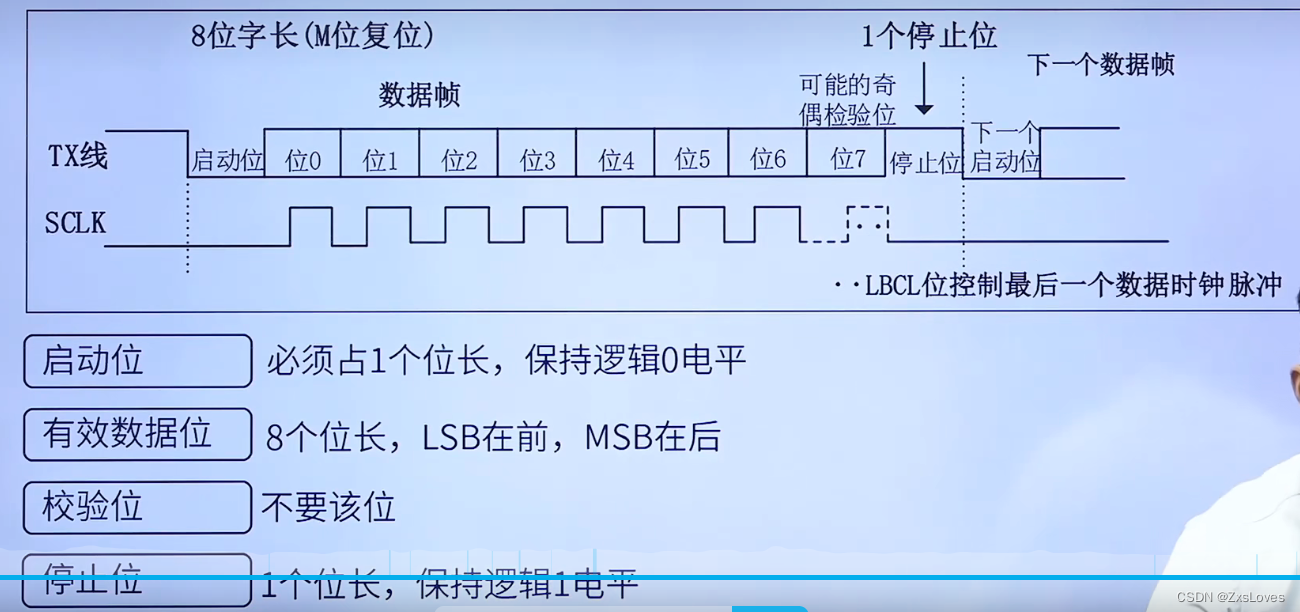
随着全球气候的不断变化,对于天气数据的获取、分析和预测显得越来越重要。本文将介绍如何使用Python编写一个简单而强大的天气数据爬虫,并结合相关库实现对历史和当前天气数据进行分析以及未来趋势预测。

1 、数据源选择
- 选择可靠丰富的公开API或网站作为我们所需的天比回溯和实时信息来源;
- 建议选用具备长期稳定性、提供多种查询参数(如城市、日期范围等)以及详尽准确地返回结果能力。
2、构建爬虫程序
使用第三方库(例如requests, BeautifulSoup)发起HTTP请求并解析响应内容。
- 根据API或网页结构设计相应URL链接格式;
- 提取关键字段(温度、湿度等) 并保存至数据库/文件.
import requests
from bs4 import BeautifulSoup
def get_weather_data(city):url = f"https://www.weather.com/{city}"# 发送GET请求获取页面内容response = requests.get(url)if response.status_code == 200:soup = BeautifulSoup(response.text, 'html.parser')# 解析HTML页面,提取所需字段# 获取温度temperature = soup.find('span', class_='temperature').text# 获取湿度humidity = soup.find('div', class_='humidity-value').textreturn {'city': city,'temperature': temperature,'humidity': humidity}else:print("请求出错,请检查网络连接或URL是否正确。")
3、历史记录与当前情况分析
对已获得到有效原始资料做进一步处理.
- 清洗无效值 ( 如空缺数值);
- 统计每日最高/最低温度频次, 风向风速比例统计;
- 绘制图表或可视化展示数据变化趋势.
import pandas as pd
def analyze_weather_data(data):df = pd.DataFrame(data)
# 数据清洗,去除空缺数值df.dropna(inplace=True)# 分析每日最高/ 最低气温频次
min_temp_freq = df['Min Temperature'].value_counts()max_temp_freq= df['Max Temperature'].value_counts()print("每日最低气温频率:")print(min_temp_freq)
print("\n\n")#print max temp frequency print "Daily Max Temperatures Frequency:"print(max_temps_frequency)
4、气候变化预测模型建立
使用机器学习/统计方法进行未来天气回归和分类。
- 选择适合的算法(如线性回归、ARIMA, LSTM等);
- 准备训练集和测试集,并对特征工程进行处理;
- 训练模型,评估并优化其准确度。
from sklearn.linear_model import LinearRegression
def weather_prediction(X_train, y_train, X_test):# 创建线性回归模型model = LinearRegression()# 拟合训练数据model.fit(X_train, y_train)# 使用模型预测结果predictions = model.predict(X_test)return predictions
5 、结果分析与呈现:
对历史记录及未来趋势做出相应结论。
- 分析不同季节/地区间温差波动;
- 验证结果是否符合实际观察值;
- 可使用图表、报告形式将结果直观呈现给用户。
通过Python爬取天气数据并进行气候变化分析与预测,我们能够更好地了解全球和特定地区的天比回溯信息,并基于此构建相应的预测模型。请注意,气候变化是一个复杂而多样化的主题,在进行分析和预测时需要综合考虑各种因素,并谨慎解读结果。
在实际应用中,请确保遵守相关法律法规以及数据提供方的服务条款;同时也要意识到天比回溯受多个因素影响,无法完全准确地进行长期趋势预测。