目录
一、前言
二、load 命令使用
2.1 load 概述
2.1.1 load 语法规则
2.1.2 load语法规则重要参数说明
2.2 load 数据加载操作演示
2.2.1 前置准备
2.2.2 加载本地数据
2.2.3 HDFS加载数据
2.2.4 从HDFS加载数据到分区表中并指定分区
2.3 hive3.0+ load 命令新特性
2.3.1 操作演示
三、insert 命令使用
3.1 语法
3.2 insert + select 操作演示
3.2.1 创建一张源表
3.2.2 加载数据
3.2.3 创建一张目标表
3.2.4 使用insert+select插入数据到新表
3.3 multiple inserts
3.3.1 操作演示
3.4 insert 之动态分区插入
3.4.1 动态分区概述
3.4.2 操作演示
3.5 insert 之导出数据
3.5.1 标准语法
3.5.2 其他写法
3.5.3 导出数据操作演示1
3.5.4 导出数据操作演示2
3.5.5 导出数据操作演示3
四、写在文末
一、前言
使用hive对数据表加载数据时方式有很多,比如直接通过insert into插入数据,或者先创建表,然后在hdfs上面上传数据文件进行数据加载的方式等等,本篇将重点介绍如何对hive的table进行数据的导入导出。
二、load 命令使用
在正式开始之前,先来回顾下之前的文章中讲到的一种常用的数据加载方式,即使用load的方式进行数据映射;
总结来说,包括如下几点:
- 在Hive中建表成功之后,就会在HDFS上创建一个与之对应的文件夹,且文件夹名字就是表名;
- 文件夹父路径是由参数hive.metastore.warehouse.dir控制,默认值是/user/hive/warehouse;
- 也可以在建表的时候使用location语句指定任意路径;
默认情况下,当我们创建完成一个table之后,不管路径在哪里,只有把数据文件移动到对应的表文件夹下面,Hive才能映射解析成功,最原始的方式就是使用 hadoop fs –put|-mv 等方式直接将数据移动到表文件夹下,但是,Hive官方推荐使用Load命令将数据加载到表中;
2.1 load 概述
Load英文单词的含义为:加载、装载,所谓加载是指:将数据文件移动到与Hive表对应的位置,移动时是纯复制、移动操作;
纯复制、移动指在数据load加载到表中时,Hive不会对表中的数据内容进行任何转换,任何操作;
2.1.1 load 语法规则
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
或者
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] [INPUTFORMAT 'inputformat' SERDE 'serde'] (3.0 or later)
2.1.2 load语法规则重要参数说明
语法规则之filepath
- filepath表示待移动数据的路径。可以指向文件(在这种情况下,Hive将文件移动到表中),也可以指向目录(在这种情况下,Hive将把该目录中的所有文件移动到表中);
- filepath文件路径支持下面三种形式,要结合LOCAL关键字一起考虑;
filepath可以使用绝对路径或者相对路径
1、相对路径,例如:project/data1;
2、绝对路径,例如:/user/hive/project/data1;
3、具有schema的完整URI,例如:hdfs://namenode:9000/user/hive/project/data1;
语法规则之 local
- 指定LOCAL, 将在本地文件系统中查找文件路径;
1、若指定相对路径,将相对于用户的当前工作目录进行解释;
2、用户也可以为本地文件指定完整的URI-例如:file:///user/hive/project/data1
如果没有指定 local 关键字
- 如果filepath指向的是一个完整的URI,会直接使用这个URI;
- 如果没有指定schema,Hive会使用在hadoop配置文件中参数fs.default.name指定的(不出意外,都是HDFS);
问题:LOCAL本地是哪里?
如果对HiveServer2服务运行此命令,本地文件系统指的是Hiveserver2服务所在机器的本地Linux文件系统,不是Hive客户端所在的本地文件系统
语法规则之 OVERWRITE
如果使用了OVERWRITE关键字,则目标表(或者分区)中的已经存在的数据会被删除,然后再将filepath指向的文件/目录中的内容添加到表/分区中。
2.2 load 数据加载操作演示
模拟从本地加载数据
2.2.1 前置准备
创建三张表,分别演示从本地以及hdfs上面加载数据
create table student_local(num int,name string,sex string,age int,dept string)
row format delimited fields terminated by ',';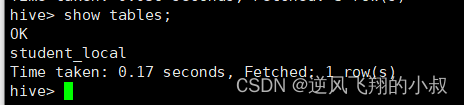
再创建第二张表
create external table student_HDFS(num int,name string,sex string,age int,dept string)
row format delimited fields terminated by ',';
创建第三张分区表,用于演示从HDFS加载数据到分区表
create table student_HDFS_p(num int,name string,sex string,age int,dept string)
partitioned by(country string) row format delimited fields terminated by ',';
2.2.2 加载本地数据
从本地加载数据
LOAD DATA LOCAL INPATH '/usr/local/soft/hivedata/students.txt' INTO TABLE student_local;执行完成后查看表,可以看到数据就加载到表中了;

同时再去检查hdfs目录,可以看到数据也被加载到hdfs目录下了;
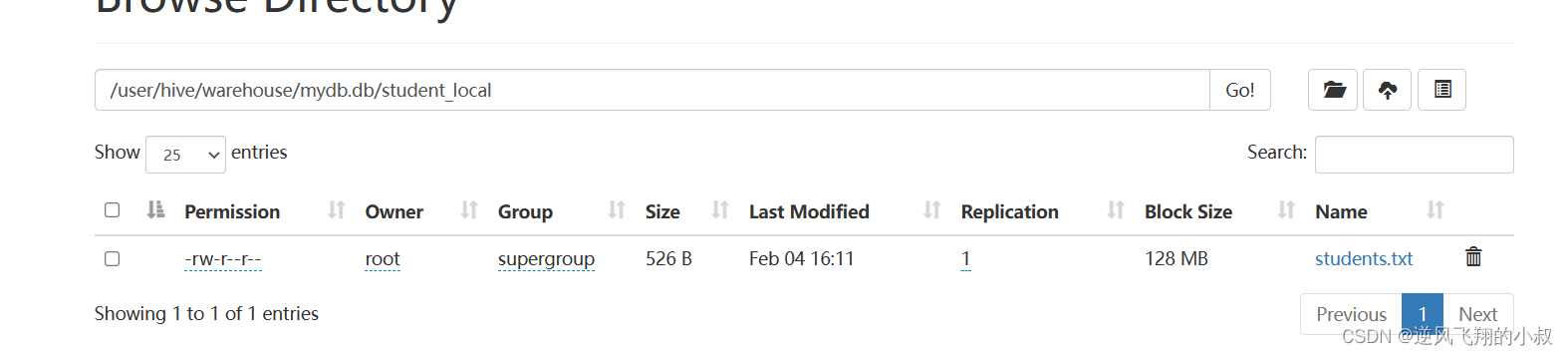
其实,这种操作其底层在执行时,本质上还是执行了是hadoop fs -put上传的操作
2.2.3 HDFS加载数据
将数据上传到hdfs
hdfs dfs -put /usr/local/soft/hivedata/students.txt /

上传成功后,在根目录下就可以看到这个文件了

将上述hdfs根目录下的数据移动到表中
LOAD DATA INPATH '/students.txt' INTO TABLE student_HDFS;

这时再去hdfs的根目录下检查,发现这个数据文件竟然不在了
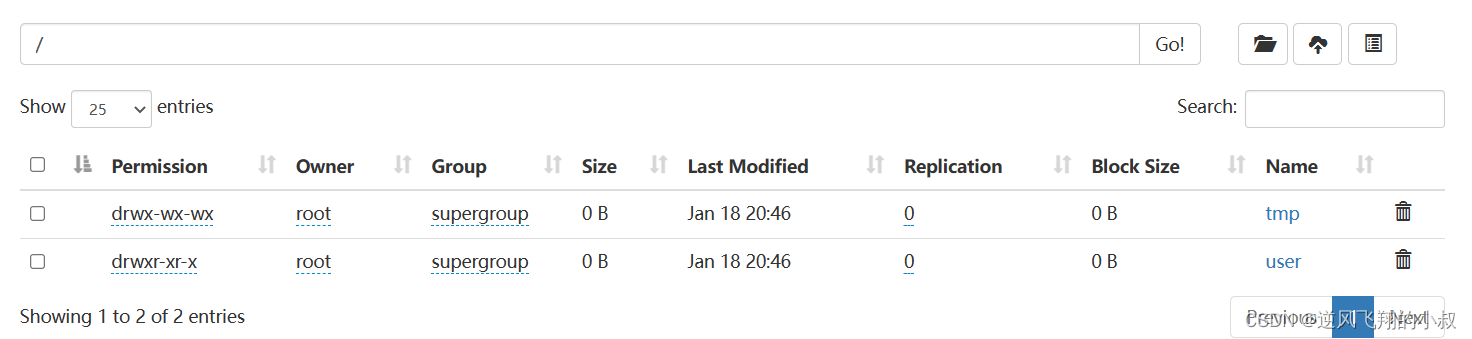
这种加载数据的方式,其本质是hadoop fs -mv 进行数据移动的操作
2.2.4 从HDFS加载数据到分区表中并指定分区
上传数据到根目录
hdfs dfs -put /usr/local/soft/hivedata/students.txt /

使用load命令将数据加载到分区表
LOAD DATA INPATH '/students.txt' INTO TABLE student_HDFS_p partition(country ="China");

2.3 hive3.0+ load 命令新特性
Hive3.0之后,load加载数据时除了移动、复制操作之外,在某些场合下还会将加载重写为INSERT AS SELECT,还支持使用inputformat、SerDe指定输入格式,例如Text,ORC等。
比如,如果表具有分区,则load命令没有指定分区,则将load转换为INSERT AS SELECT,并假定最后一组列为分区列,如果文件不符合预期,则报错。
2.3.1 操作演示
创建一张测试使用的分区表
CREATE TABLE if not exists tab1 (col1 int, col2 int)
PARTITIONED BY (col3 int)
row format delimited fields terminated by ',';创建一个数据文件,格式如下
正常情况下的数据加载
LOAD DATA LOCAL INPATH '/usr/local/soft/hivedata/tab1.txt' INTO TABLE tab1 partition(col3="1");加载完成后可以看到数据已经加载到表中
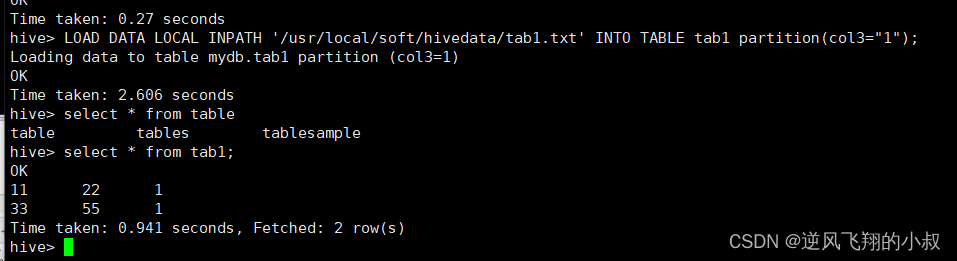
上面谈到hive3.0之后,load命令如果没有指定分区,则将load转换为INSERT AS SELECT,并假定最后一组列为分区列,接下来我们清空该表,使用下面的命令重新执行一次;
LOAD DATA LOCAL INPATH '/usr/local/soft/hivedata/tab1.txt' INTO TABLE tab1;

从hdfs上面可以发现,被成功映射为分区表了;
通过执行过程发现,这个时间有点长,因为底层要将这个操作转化为 INSERT AS SELECT 的操作;
三、insert 命令使用
MySQL这样的RDBMS中,通常使用insert+values的方式来向表插入数据,并且执行速度很快,假如把Hive当成RDBMS,用insert+values的方式插入数据,会如何?
不妨来做过简单的试验吧,创建一张表
create table t_test_insert(id int,name string,age int);
然后向表中插入一条数据
insert into table t_test_insert values(1,"allen",18);
尽管数据可以插入成功,但是执行过程比较漫长,原因在于底层是开启了了MapReduce任务,通过map-reduce任务把数据写入Hive表中;

试想一下,如果在Hive中使用insert+values,对于大数据环境一条条插入数据,用时难以想象,所以Hive官方推荐加载数据的方式:清洗数据成为结构化文件,再使用Load语法加载数据到表中。这样的效率更高。
但是并不意味insert语法在Hive中没有用武之地了,下面介绍hive中insert的其他用法;
insert + select
insert+select表示:将后面查询返回的结果作为内容插入到指定表中,注意OVERWRITE将覆盖已有数据;
3.1 语法
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement;或
INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;
使用insert+select 需要注意:
- 需要保证查询结果列的数目和需要插入数据表格的列数目一致;
- 如果查询出来的数据类型和插入表格对应的列数据类型不一致,将会进行转换,但是不能保证转换一定成功,转换失败的数据将会为NULL;
3.2 insert + select 操作演示
3.2.1 创建一张源表
create table student(num int,name string,sex string,age int,dept string)
row format delimited
fields terminated by ',';

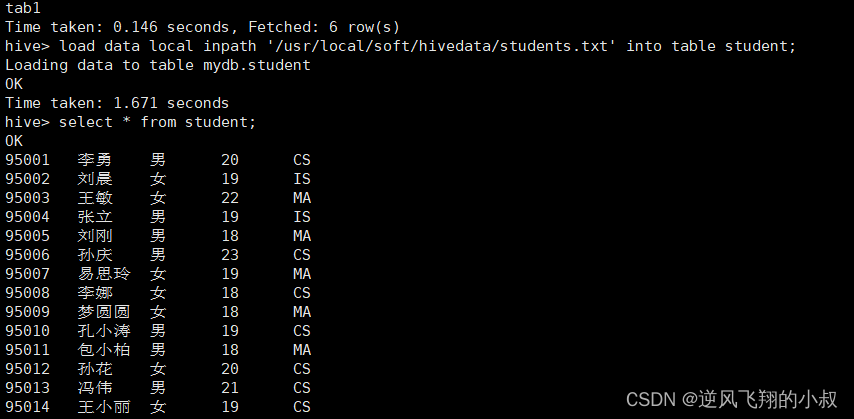
3.2.2 加载数据
load data local inpath '/usr/local/soft/hivedata/students.txt' into table student;
3.2.3 创建一张目标表
该表只有两个字段
create table student_from_insert(sno int,sname string);

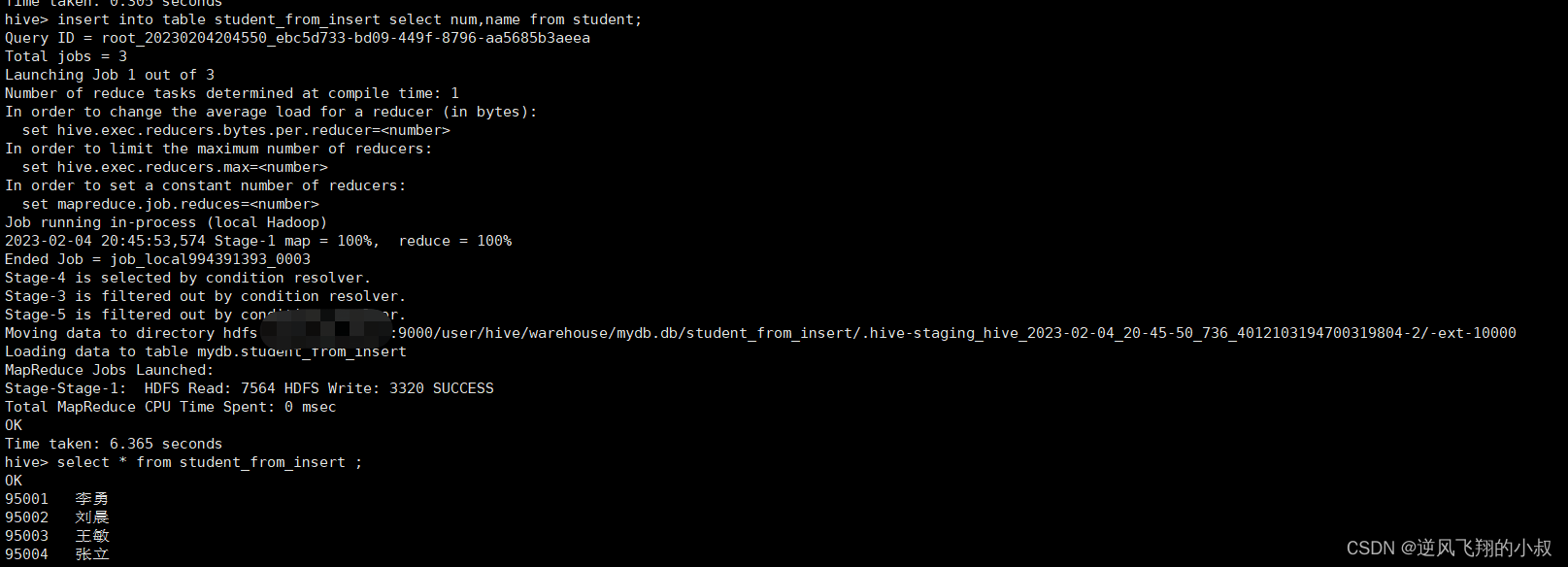
3.2.4 使用insert+select插入数据到新表
不难理解,执行了这条sql之后,student表中的num,name两个字段数据将会填充到student_from_insert表中;
insert into table student_from_insert select num,name from student;
3.3 multiple inserts
顾名思义就是,多次插入,多重插入,其核心功能是:一次扫描,多次插入;
使用该语法的目的就是减少扫描的次数,在一次扫描中,完成多次insert操作;
3.3.1 操作演示
在上面的insert + select 中创建了一张student的表,再创建两张新表,各有一个字段;
create table student_insert1(sno int);
create table student_insert2(sname string);
我们的需求是,从student中查询出sno放到第一个表,然后查询出sname放到另一个表中,如果按照大多数人直观的考虑,可能会像下面这么做:
insert into student_insert1 select num from student;
insert into student_insert2 select name from student;
如果使用多重插入来做的话,就可以使用下面的sql一次性完成;
from student
insert overwrite table student_insert1
select num
insert overwrite table student_insert2
select name;
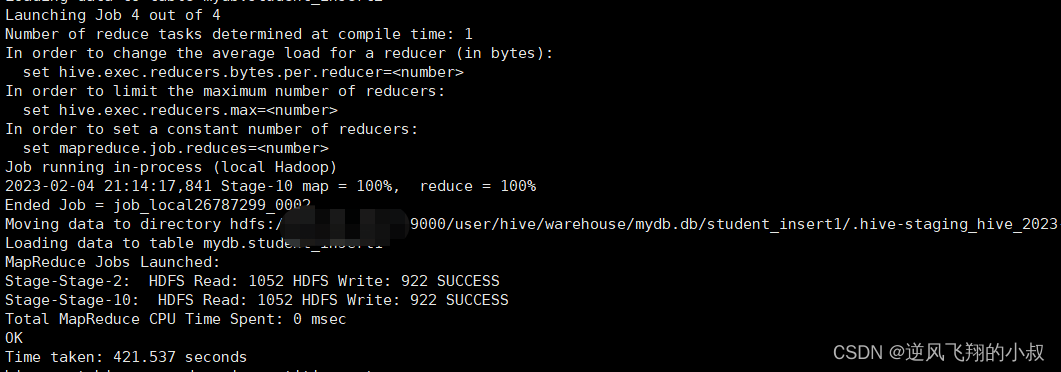
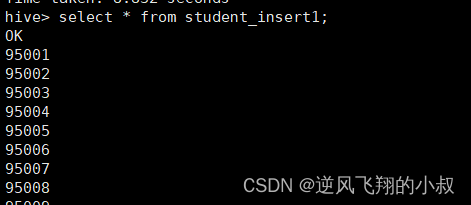
执行完成后,可以检查两个表的数据是否成功插入;
3.4 insert 之动态分区插入
背景说明
对于分区表的数据导入加载,最基础的是通过load命令加载数据,在load过程中,分区值是手动指定写死的,叫做静态分区。
假如说,现在有全球224个国家的人员名单(每个国家名单单独一个文件),导入到分区表中,不同国家不同分区,如何高效实现?如果使用load命令,岂不是要导入224次?这样的话效率就太低了。
3.4.1 动态分区概述
动态分区插入指的是:分区的值是由后续的select查询语句的结果来动态确定的,根据查询结果自动分区。
两个重要参数
| hive.exec.dynamic.partition | true | 需要设置true为启用动态分区插入 |
| hive.exec.dynamic.partition.mode | strict | 在strict模式下,用户必须至少指定一个静态分区,以防用户意外覆盖所有分区;在nonstrict模式下,允许所有分区都是动态的 |
3.4.2 操作演示
首先设置动态分区模式为非严格模式(默认已经开启了动态分区功能)
set hive.exec.dynamic.partition = true;
set hive.exec.dynamic.partition.mode = nonstrict;
在当前库下,已经有一张student表,创建分区表;
create table student_partition(Sno int,Sname string,Sex string,Sage int)
partitioned by(Sdept string);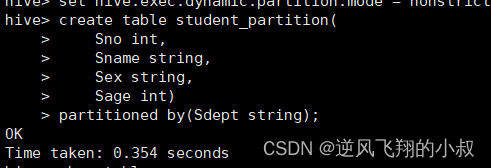
执行动态分区insert操作插入数据
insert into table student_partition partition(Sdept)
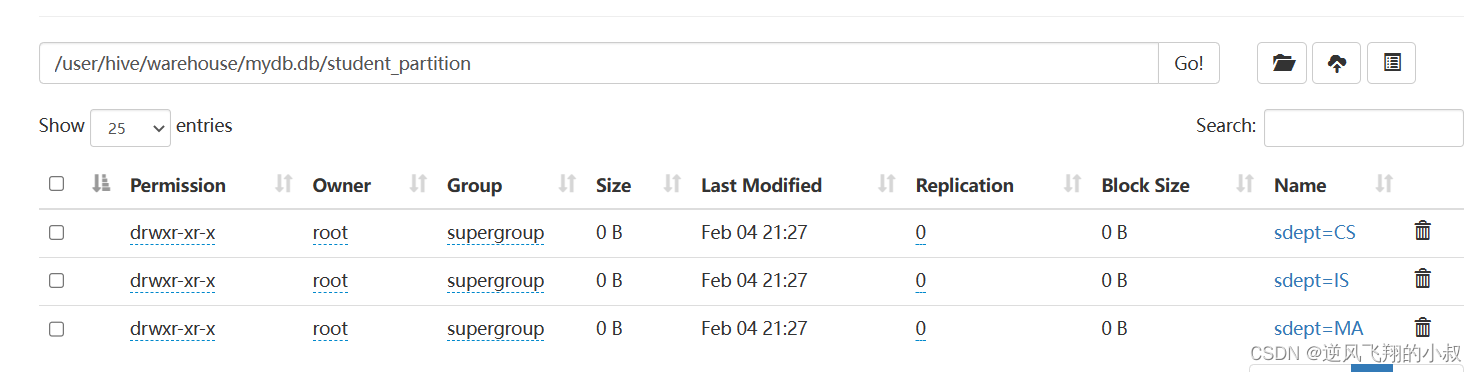
select num,name,sex,age,dept from student;
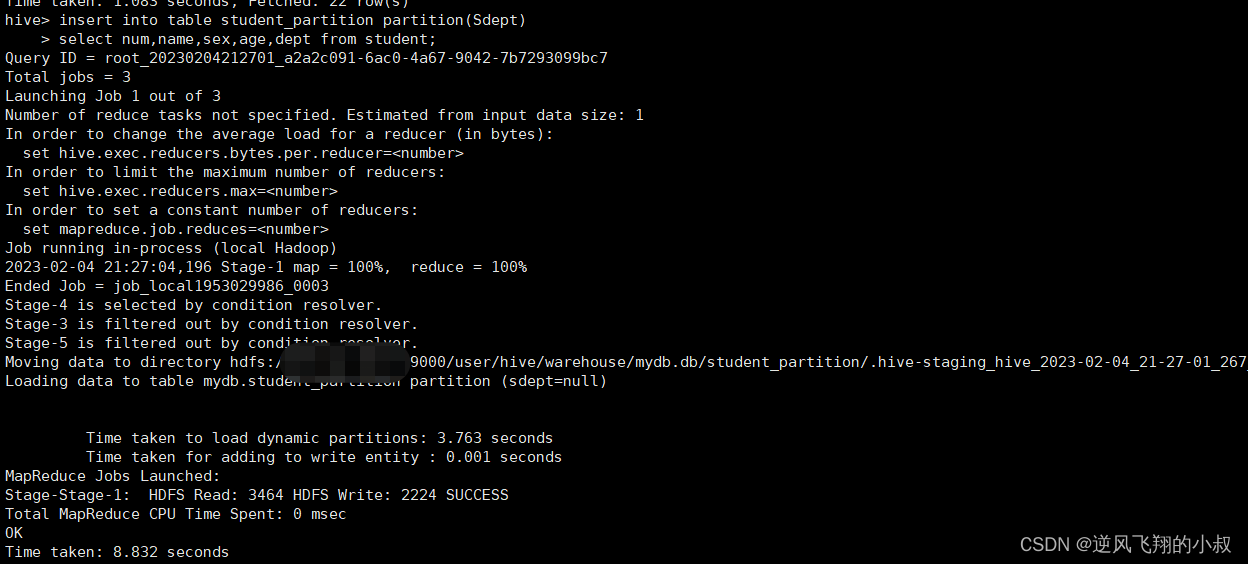
执行完成后,检查hdfs目录,可以发现数据已经按照分区保持了
3.5 insert 之导出数据
Hive支持将select查询的结果导出成文件存放在文件系统中,语法格式如下;
3.5.1 标准语法
INSERT OVERWRITE [LOCAL] DIRECTORY directory1
[ROW FORMAT row_format] [STORED AS file_format]
SELECT ... FROM ...
3.5.2 其他写法
FROM from_statement
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 select_statement1
[INSERT OVERWRITE [LOCAL] DIRECTORY directory2 select_statement2] ...
关于语法补充说明
- 目录可以是完整的URI。如果未指定scheme,则Hive将使用hadoop配置变量fs.default.name来决定导出位置;
- 如果使用LOCAL关键字,则Hive会将数据写入本地文件系统上的目录;
- 写入文件系统的数据被序列化为文本,列之间用\001隔开,行之间用换行符隔开。如果列都不是原始数据类型,那么这些列将序列化为JSON格式。也可以在导出的时候指定分隔符换行符和文件格式;
3.5.3 导出数据操作演示1
在上文中演示时用到了一张student表
导出查询结果到HDFS指定目录下
insert overwrite directory '/data' select num,name,age from student;
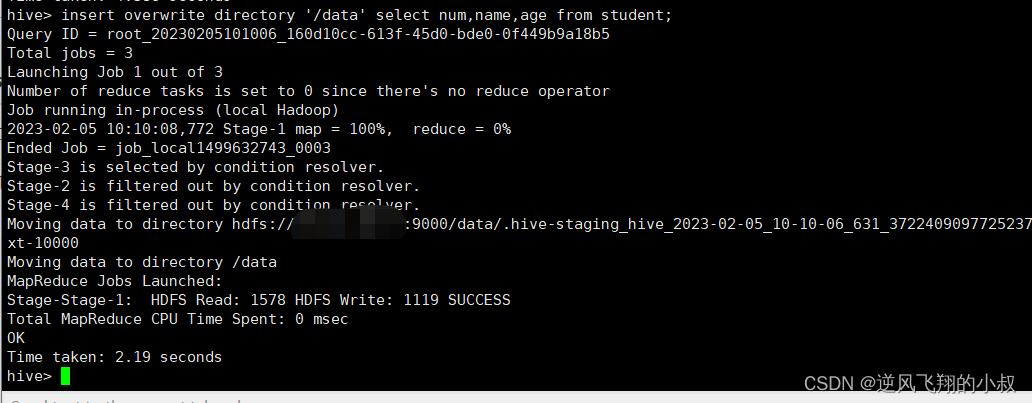
任务完成之后到hdfs目录下检查数据是否导出成功,也可以从hdfs将文件下载下来再次确认数据的正确性;

3.5.4 导出数据操作演示2
接下来我们在导出的时候指定一下分隔符和文件存储格式
insert overwrite directory '/data' row format delimited fields terminated by ','
stored as orc select * from student;
执行上面的导出sql

去hdfs上检查数据是否导出成功

3.5.5 导出数据操作演示3
导出数据到本地文件系统指定目录下
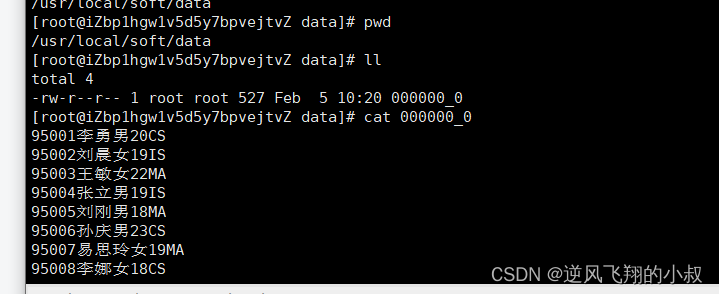
insert overwrite local directory '/usr/local/soft/data' select * from student;
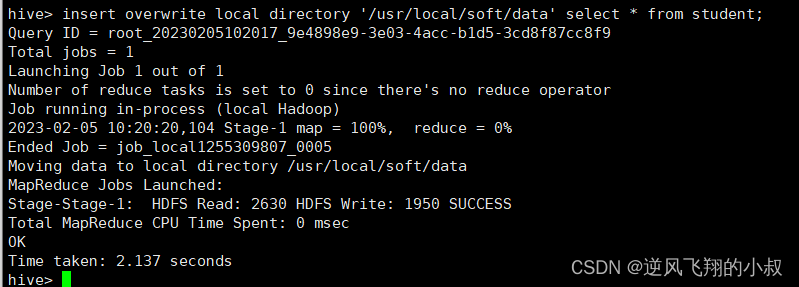
执行完成之后检查本地数据目录下已经有了导出的数据;
四、写在文末
hive的数据导入在日常开发、运维过程中运用的场景非常普遍,且频率非常高,选择合理的数据导入方式可以给开发提升很多效率,有必要深入掌握。