参考书籍:8.6. 循环神经网络的简洁实现 — 动手学深度学习 2.0.0 documentation
参考视频:54 循环神经网络 RNN【动手学深度学习v2】_哔哩哔哩_bilibili
一.介绍
循环神经网络RNN(Recurrent Neural Network )是一类广泛应用于序列数据建模和处理的神经网络模型。相比于传统的前馈神经网络,RNN在处理序列数据时引入了时间维度的循环连接,使得网络能够保持对先前信息的记忆和上下文依赖。
RNN的一个关键特点是其内部的循环结构,允许信息在网络中进行传递和交互。在RNN中,每个时间步的输入不仅包括当前时间步的输入数据,还包括前一时间步的隐藏状态(hidden state)。隐藏状态可以看作是网络对过去观察的记忆,它会被传递到下一个时间步并与当前输入一起用于计算当前时间步的输出和隐藏状态。
RNN可以灵活地处理不定长度的序列数据,并且能够捕捉序列中的时间依赖关系。这使得RNN广泛应用于自然语言处理(NLP)、语音识别、机器翻译、时间序列预测等任务。然而,传统的RNN在处理长期依赖关系时可能会遭遇梯度消失或梯度爆炸等问题,限制了其在处理长序列任务中的表现。
二.RNN结构
首先看一个简单的循环神经网络如,它由输入层、一个隐藏层和一个输出层组成:

参看博文:史上最详细循环神经网络讲解(RNN/LSTM/GRU) - 知乎
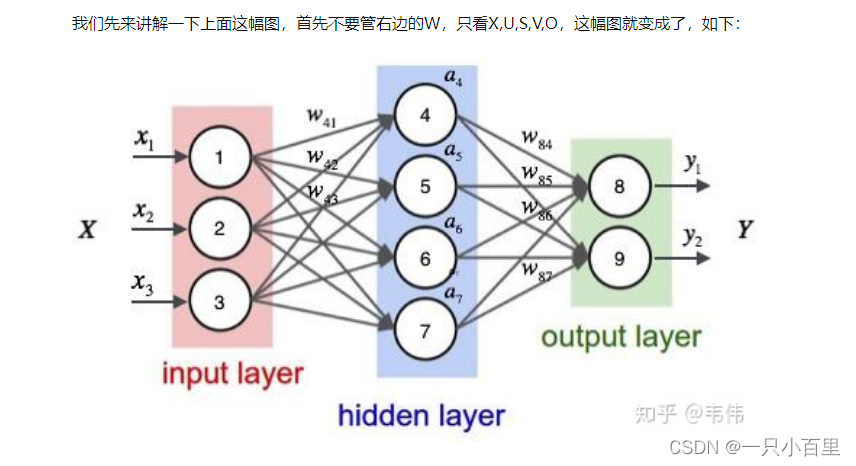
不看W的话,上面那幅图展开就是全连接神经网络,其中X是一个向量,也就是某个字或词的特征向量,作为输入层,如上图也就是3维向量,U是输入层到隐藏层的参数矩阵,在上图中其维度就是3X4,S是隐藏层的向量,如上图维度就是4,V是隐藏层到输出层的参数矩阵,在上图中就是4X2,O是输出层的向量,在上图中维度为2。
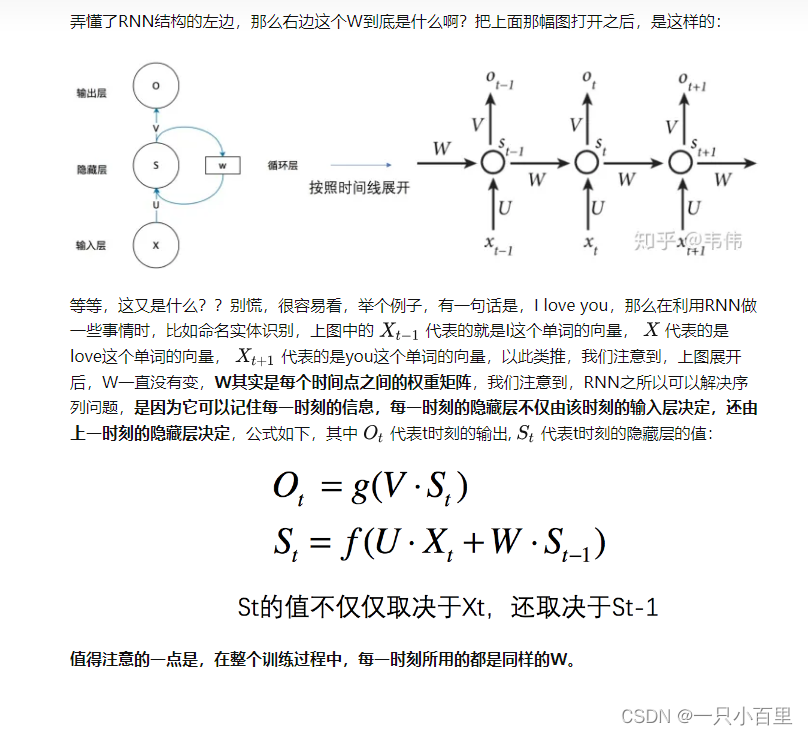
注意: 1. 这里的W,U,V在每个时刻都是相等的(权重共享).
2. 隐藏状态可以理解为: S=f(现有的输入+过去记忆总结)
三.RNN的反向传播
参考博客:深度学习之RNN(循环神经网络)_笨拙的石头的博客-CSDN博客


四.RNN存在的问题
以下是 RNN 存在的一些问题以及其原因:
-
长期依赖性问题:RNN 在处理长序列时,往往难以捕捉到序列中较远位置之间的依赖关系。这是因为 RNN 的隐藏状态(即记忆)通过不断迭代的方式传递,长期依赖的信息在传递过程中会逐渐衰减,导致难以有效地捕捉到远距离的依赖。
-
梯度消失和梯度爆炸问题:在 RNN 的训练过程中,反向传播算法通过计算梯度来更新模型参数。然而,在 RNN 中,梯度信息需要通过时间步展开的过程进行反向传播,这导致梯度在时间维度上呈指数级衰减或爆炸。梯度消失/爆炸会导致模型难以收敛或训练过程不稳定。
-
训练速度慢:由于 RNN 的序列依赖性,每个时间步的计算都需要依次进行,难以并行化。这导致 RNN 的训练速度相对较慢,尤其是在处理长序列时。
为了解决这些问题,研究人员提出了一些改进的 RNN 模型,其中最常见的是长短期记忆网络(LSTM)和门控循环单元(GRU)。
LSTM 和 GRU对于梯度消失或者梯度爆炸的问题处理方法主要是:
对于梯度消失: 由于它们都有特殊的方式存储”记忆”,那么以前梯度比较大的”记忆”不会像简单的RNN一样马上被抹除,因此可以一定程度上克服梯度消失问题。
对于梯度爆炸:用来克服梯度爆炸的问题就是gradient clipping,也就是当你计算的梯度超过阈值c或者小于阈值-c的时候,便把此时的梯度设置成c或-c。
五.实现
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2lbatch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)5.1定义模型
num_hiddens = 256
rnn_layer = nn.RNN(len(vocab), num_hiddens)
state = torch.zeros((1, batch_size, num_hiddens))
state.shape
X = torch.rand(size=(num_steps, batch_size, len(vocab)))
Y, state_new = rnn_layer(X, state)
Y.shape, state_new.shape为一个完整的循环神经网络模型定义了一个RNNModel类。 注意,rnn_layer只包含隐藏的循环层,我们还需要创建一个单独的输出层。
#@save
class RNNModel(nn.Module):"""循环神经网络模型"""def __init__(self, rnn_layer, vocab_size, **kwargs):super(RNNModel, self).__init__(**kwargs)self.rnn = rnn_layerself.vocab_size = vocab_sizeself.num_hiddens = self.rnn.hidden_size# 如果RNN是双向的(之后将介绍),num_directions应该是2,否则应该是1if not self.rnn.bidirectional:self.num_directions = 1self.linear = nn.Linear(self.num_hiddens, self.vocab_size)else:self.num_directions = 2self.linear = nn.Linear(self.num_hiddens * 2, self.vocab_size)def forward(self, inputs, state):X = F.one_hot(inputs.T.long(), self.vocab_size)X = X.to(torch.float32)Y, state = self.rnn(X, state)# 全连接层首先将Y的形状改为(时间步数*批量大小,隐藏单元数)# 它的输出形状是(时间步数*批量大小,词表大小)。output = self.linear(Y.reshape((-1, Y.shape[-1])))return output, statedef begin_state(self, device, batch_size=1):if not isinstance(self.rnn, nn.LSTM):# nn.GRU以张量作为隐状态return torch.zeros((self.num_directions * self.rnn.num_layers,batch_size, self.num_hiddens),device=device)else:# nn.LSTM以元组作为隐状态return (torch.zeros((self.num_directions * self.rnn.num_layers,batch_size, self.num_hiddens), device=device),torch.zeros((self.num_directions * self.rnn.num_layers,batch_size, self.num_hiddens), device=device))5.2训练与预测
device = d2l.try_gpu()
net = RNNModel(rnn_layer, vocab_size=len(vocab))
net = net.to(device)
d2l.predict_ch8('time traveller', 10, net, vocab, device)结果:'time travellerzzzazzzzzz'
很明显,这种模型根本不能输出好的结果。 接下来,我们使用 8.5节中 定义的超参数调用train_ch8,并且使用高级API训练模型。
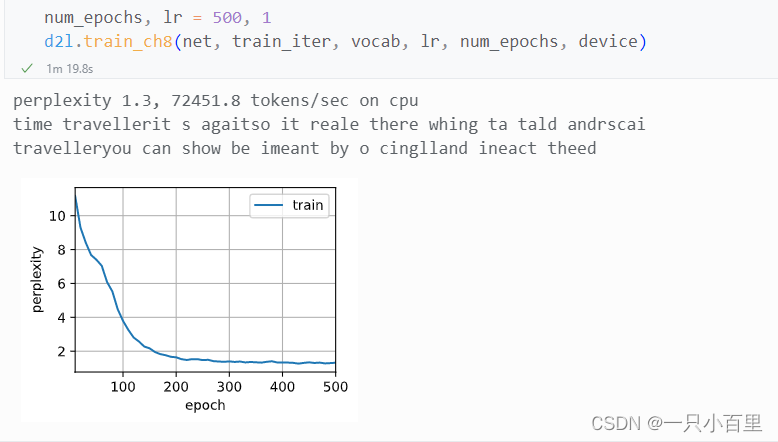
num_epochs, lr = 500, 1
d2l.train_ch8(net, train_iter, vocab, lr, num_epochs, device)结果: