文章目录
- 一、显存带宽和理论显存带宽
- 1. 显存带宽
- 2. 理论显存带宽
- 1)计算公式
- 2)举例
- 二、利用CUDA计算理论显存带宽
一、显存带宽和理论显存带宽
1. 显存带宽
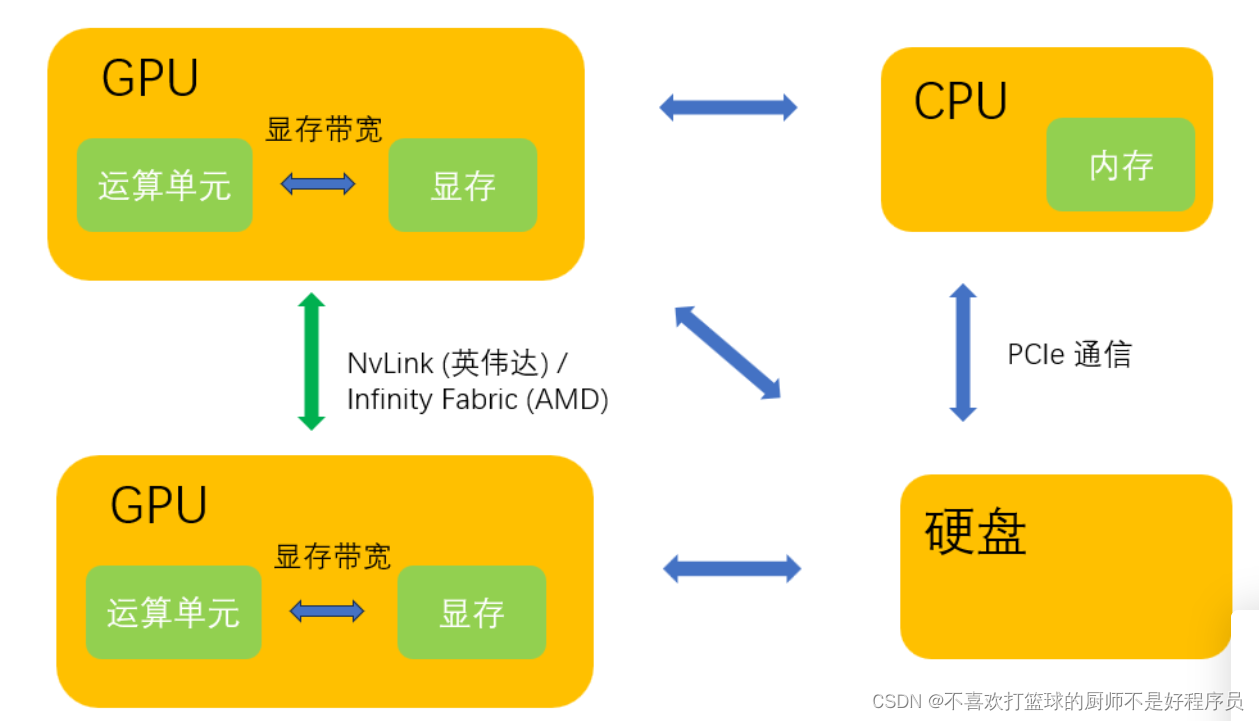
显存带宽是指显存和GPU计算单元之间的数据传输速率。
显存带宽越大,意味着数据传输越快,那么GPU整体的计算速度也会越快。所以该指标可以作为我们评估核函数运行速度的评价指标。
2. 理论显存带宽
1)计算公式
理论显存带宽由具体硬件所定义。计算公式为:
理论显存带宽 = 显存频率(Hz) * 显存位宽(bit) / 8 * 2
// 这里除以8是因为位宽的单位是bit,我们要转成 byte
// * 2 是因为 DDR(double data rate)
2)举例
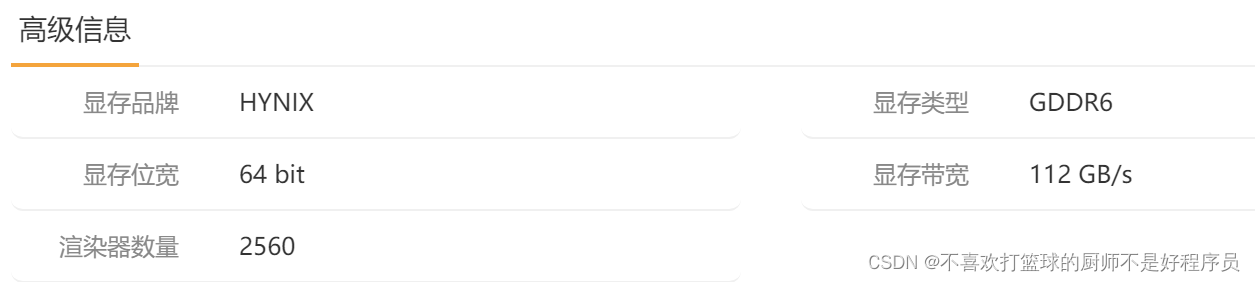
以我的笔记本电脑为例:
GPU型号: NVIDIA GeForce RTX 3050 4GB Laptop GPU
显存频率:7001000 kHz
显存位宽:64 bit理论显存带宽 = (7001000 * 1000)Hz * (64 / 8)byte * 2 = 112016000000 byte/s ≈ 112 GB/s
与鲁大师的检测结果一致:
二、利用CUDA计算理论显存带宽
主要使用到了cudaGetDeviceProperties()函数。该函数用于获取GPU的相关属性信息。
具体代码如下:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"void CalTheoreticalBandWidth()
{int deviceCount;cudaGetDeviceCount(&deviceCount); // 获取设备上的GPU个数for (int i = 0; i < deviceCount; ++i) {cudaDeviceProp deviceProp;cudaGetDeviceProperties(&deviceProp, i); // 获取当前GPU的相关属性std::cout << "GPU: " << i << std::endl;std::cout << "Name: " << deviceProp.name << std::endl;std::cout << "Bit width: " << deviceProp.memoryBusWidth << " bit" << std::endl;std::cout << "Memory clock rate: " << deviceProp.memoryClockRate << " kHz" << std::endl;int bw = static_cast<size_t>(deviceProp.memoryClockRate) * 1000 * deviceProp.memoryBusWidth / 8 * 2 / 1000000000;std::cout << "Theoretical band width = " << bw << " GB/s" << std::endl;}
}
运行结果:
GPU: 0
Name: NVIDIA GeForce RTX 3050 4GB Laptop GPU
Bit width: 64 bit
Memory clock rate: 7001000 kHz
Theoretical band width = 112 GB/s