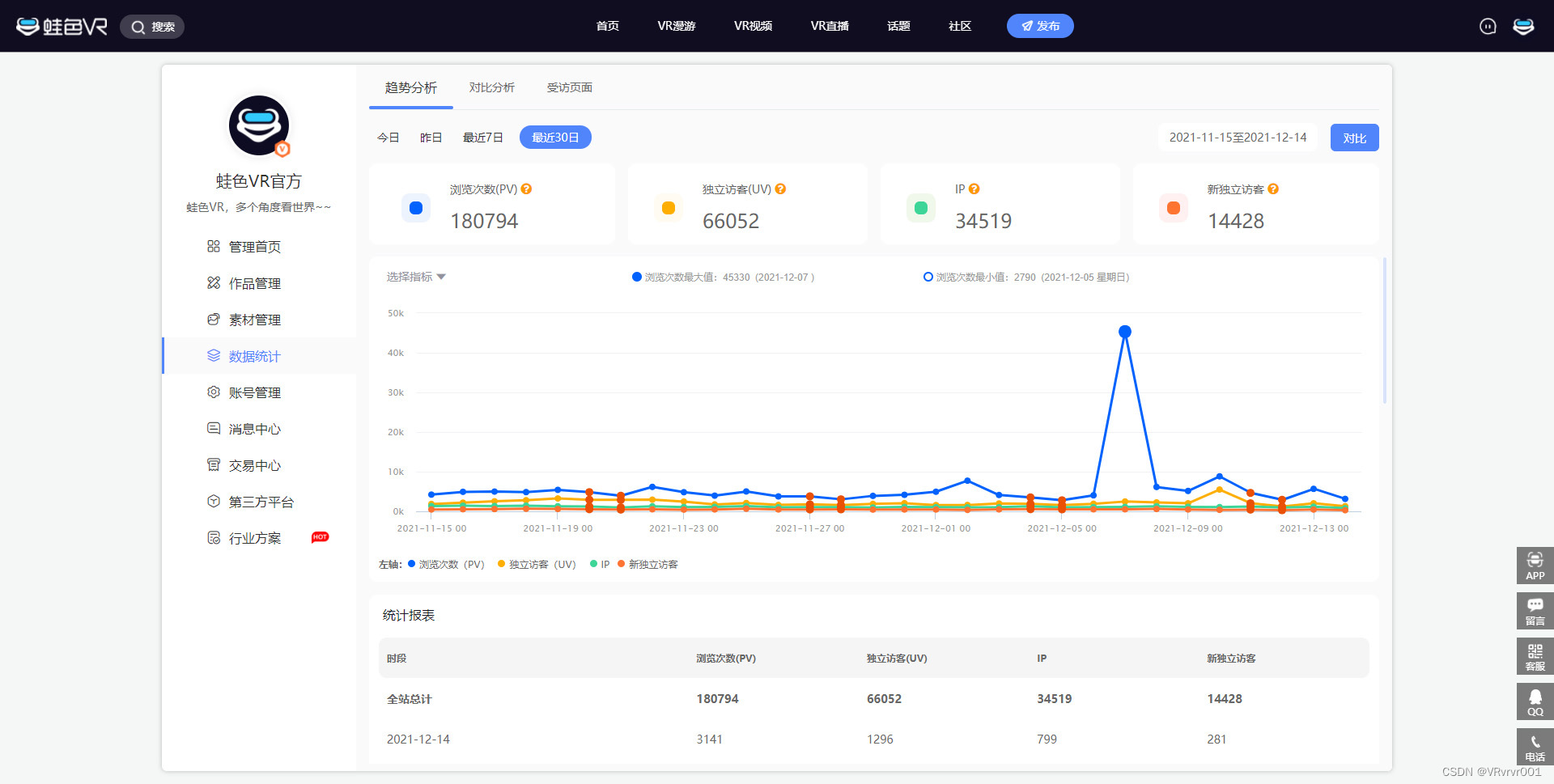
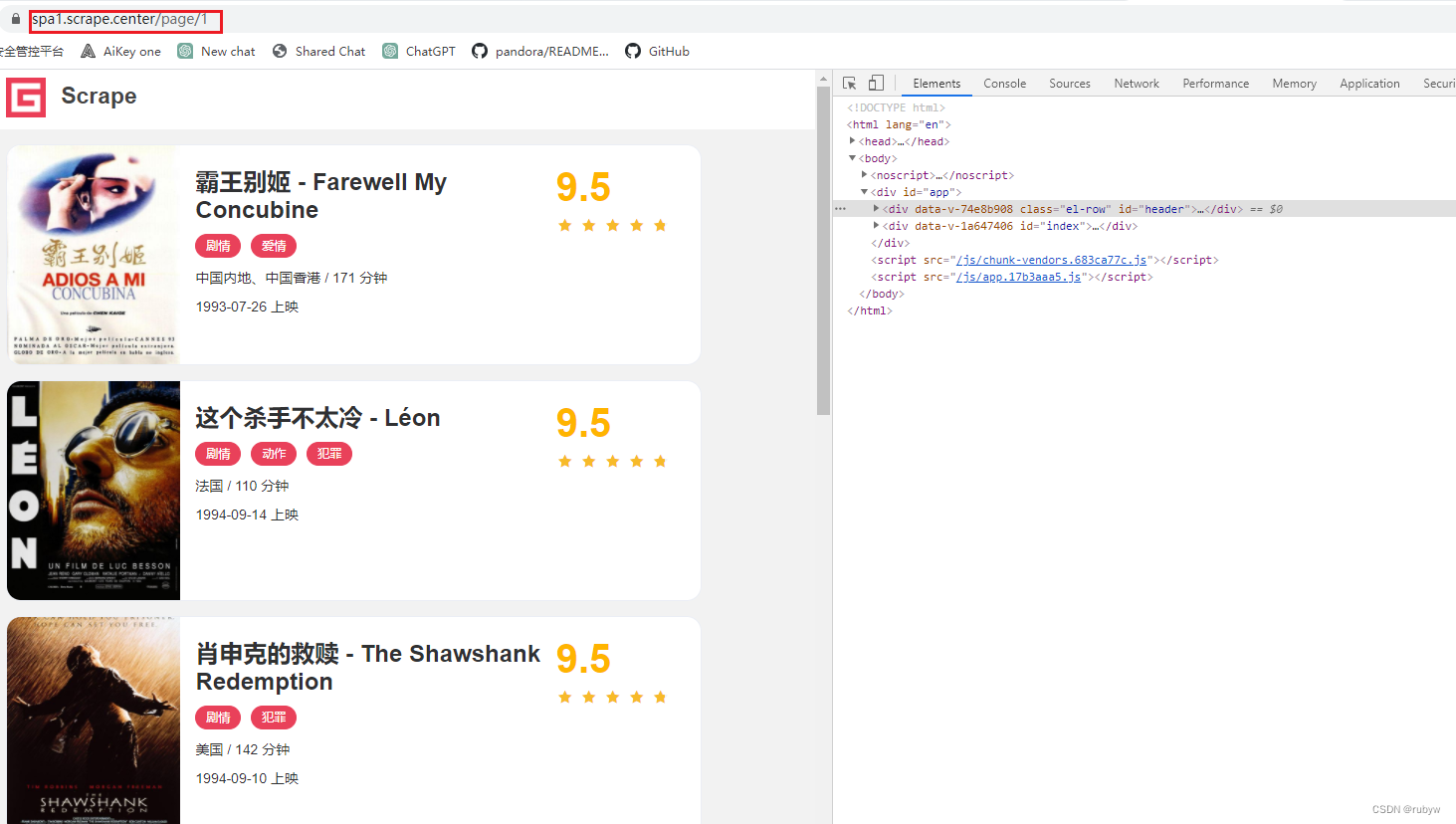
观察翻页时详情页面url地址变化规律
import json
from os import makedirs
from os.path import exists
import requests
import logging
import re
from urllib.parse import urljoin
import multiprocessing# 定义了下日志输出级别和输出格式
logging.basicConfig(level=logging.INFO,format='%(asctime)s - %(levelname)s: %(message)s')BASE_URL = 'https://ssr1.scrape.center'
TOTAL_PAGE = 10RESULTS_DIR = 'results'
exists(RESULTS_DIR) or makedirs(RESULTS_DIR)# 爬取列表页
def scrape_page(url):"""scrape page by url and return its html:param url: page url:return: html of page"""logging.info('scraping %s...', url)try:response = requests.get(url)if response.status_code == 200:return response.textlogging.error('get invalid status code %s while scraping %s',response.status_code, url)except requests.RequestException:logging.error('error occurred while scraping %s', url, exc_info=True)# 爬取详情列表页
def scrape_index(page):"""scrape index page and return its html:param page: page of index page:return: html of index page"""index_url = f'{BASE_URL}/page/{page}'return scrape_page(index_url)# 解析详情列表页
def parse_index(html):"""parse index page and return detail url:param html: html of index page"""pattern = re.compile('<a.*?href="(.*?)".*?class="name">')items = re.findall(pattern, html)if not items:return []for item in items:detail_url = urljoin(BASE_URL, item)logging.info('get detail url %s', detail_url)yield detail_url# 爬取详情页
def scrape_detail(url):"""scrape detail page and return its html:param page: page of detail page:return: html of detail page"""return scrape_page(url)# 解析详情页正则匹配方法
def parse_detail(html):"""parse detail page:param html: html of detail page:return: data"""cover_pattern = re.compile('class="item.*?<img.*?src="(.*?)".*?class="cover">', re.S)name_pattern = re.compile('<h2.*?>(.*?)</h2>')categories_pattern = re.compile('<button.*?category.*?<span>(.*?)</span>.*?</button>', re.S)published_at_pattern = re.compile('(\d{4}-\d{2}-\d{2})\s?上映')drama_pattern = re.compile('<div.*?drama.*?>.*?<p.*?>(.*?)</p>', re.S)score_pattern = re.compile('<p.*?score.*?>(.*?)</p>', re.S)# 结果只有一个,用 search 方法提取即可# 结果有多个,使用 findall 方法提取,结果是一个列表cover = re.search(cover_pattern, html).group(1).strip() if re.search(cover_pattern, html) else Nonename = re.search(name_pattern, html).group(1).strip() if re.search(name_pattern, html) else Nonecategories = re.findall(categories_pattern, html) if re.findall(categories_pattern, html) else []published_at = re.search(published_at_pattern, html).group(1) if re.search(published_at_pattern, html) else Nonedrama = re.search(drama_pattern, html).group(1).strip() if re.search(drama_pattern, html) else Nonescore = float(re.search(score_pattern, html).group(1).strip()) if re.search(score_pattern, html) else Nonereturn {'cover': cover,'name': name,'categories': categories,'published_at': published_at,'drama': drama,'score': score}# 解析详情页pq方法
from pyquery import PyQuery as pq
def parse_detail(html):"""parse detail page:param html: html of detail page:return: data"""doc = pq(html)cover = doc('img.cover').attr('src')name = doc('a > h2').text()categories = [item.text() for item in doc('.categories button span').items()]published_at = doc('.info:contains(上映)').text()published_at = re.search('(\d{4}-\d{2}-\d{2})', published_at).group(1) \if published_at and re.search('\d{4}-\d{2}-\d{2}', published_at) else Nonedrama = doc('.drama p').text()score = doc('p.score').text()score = float(score) if score else Nonereturn {'cover': cover,'name': name,'categories': categories,'published_at': published_at,'drama': drama,'score': score}# 保存数据
def save_data(data):"""save to json file:param data::return:"""name = data.get('name')data_path = f'{RESULTS_DIR}/{name}.json'json.dump(data, open(data_path, 'w', encoding='utf-8'),ensure_ascii=False, indent=2)# main 方法
def main(page):"""main process:return:"""index_html = scrape_index(page)detail_urls = parse_index(index_html)for detail_url in detail_urls:detail_html = scrape_detail(detail_url)data = parse_detail(detail_html)logging.info('get detail data %s', data)logging.info('saving data to json file')save_data(data)logging.info('data saved successfully')# 多进程加速
if __name__ == '__main__':pool = multiprocessing.Pool()pages = range(1, TOTAL_PAGE + 1)pool.map(main, pages)pool.close()





![[uni-app] 海报图片分享方案 -canvas绘制](https://img-blog.csdnimg.cn/71f0bc27fe5f47ad9bf9aca5cdf0b053.png)