向量数据库:AI时代的新基座
人工智能在无处不在影响着我们的生活,而人工智能飞速发展的背后是需要对越来越多的海量数据处理,传统数据库已经难以支撑大规模的复杂数据处理。特别是大模型的出现,向量数据库横空出世。NVIDIA CEO黄仁勋在NVIDIA GTC Keynote演讲中首次提到了向量数据库,并强调它在构建专有大型语言模型组织中的重要性。作为新一代AI处理器,大型模型提供了强大的数据处理能力,而向量数据库则成为了存储能力的关键基础。
向量数据库是一种专门用于存储和查询向量数据的数据库系统,它采用向量化计算,能够快速处理大规模复杂数据,相较于关系型数据库有着更高的性能。与传统数据库相比,向量数据库可以处理高维数据,例如图像、音频和视频等,从而解决了传统关系型数据库的瓶颈。此外,向量数据库可以利用分布式、云计算和边缘计算等技术轻松地扩展到多个节点,从而实现数据处理规模的扩大,并提高向量数据的存储、管理和查询的稳定性。
我们不禁要问,向量数据库相比于传统数据库有如此亮眼的表现,背后是哪些核心技术在支撑呢?
向量数据库的核心技术
什么是向量数据?
向量数据是由多个数值组成的序列,可以表示一个数据量的大小和方向。通过Embedding技 术,图像、声音、文本都可以被表达为一个高维的向量,比如一张图片可以转换为一个由像素值构成的向量。
在计算机科学和数据科学中,向量数据广泛应用于各种领域,如机器学习、图像处理、自然语言处理等。例如,在机器学习中,数据通常以向量的形式表示,每个维度表示一个特征,从而可以进行各种模型的训练和预测。通过对向量数据进行计算,可以进行相似度比较、聚类分析、分类和预测等任务。向量数据的处理和分析对于许多领域的数据科学和人工智能应用至关重要。
什么是向量数据库?
向量数据库是一种专门用于存储和查询向量数据的数据库系统。 向量数据库支持对向量数据进行各种操作,例如向量检索,根据给定的向量,找出数据库中与之最相似的向量;例如向量聚类:根据给定的相似度度量,将数据库中的向量分类,例如根据图片的内容或风格,将图片分成不同的主题。
向量数据库有哪些技术上的难点?
向量数据库主要有高维度、稀疏性、异构性和动态性四大难点。高维度是指向量数据通常包含大量元素,具有较高的维度,维度越高,对数据库性能的要求也就越高;稀疏性是指向量数据中很多元素的值可能为零或接近零,只有少数元素具有显著非零值,分布越稀疏越难以处理;异构性是指向量数据中的元素可能具有不同的类型或含义,表示不同的特征或属性;动态性是指向量数据可能随着时间或环境的变化而发生变化,可以是实时更新的,更新的频率越高,对数据库的查询、检索等要求也就越高。

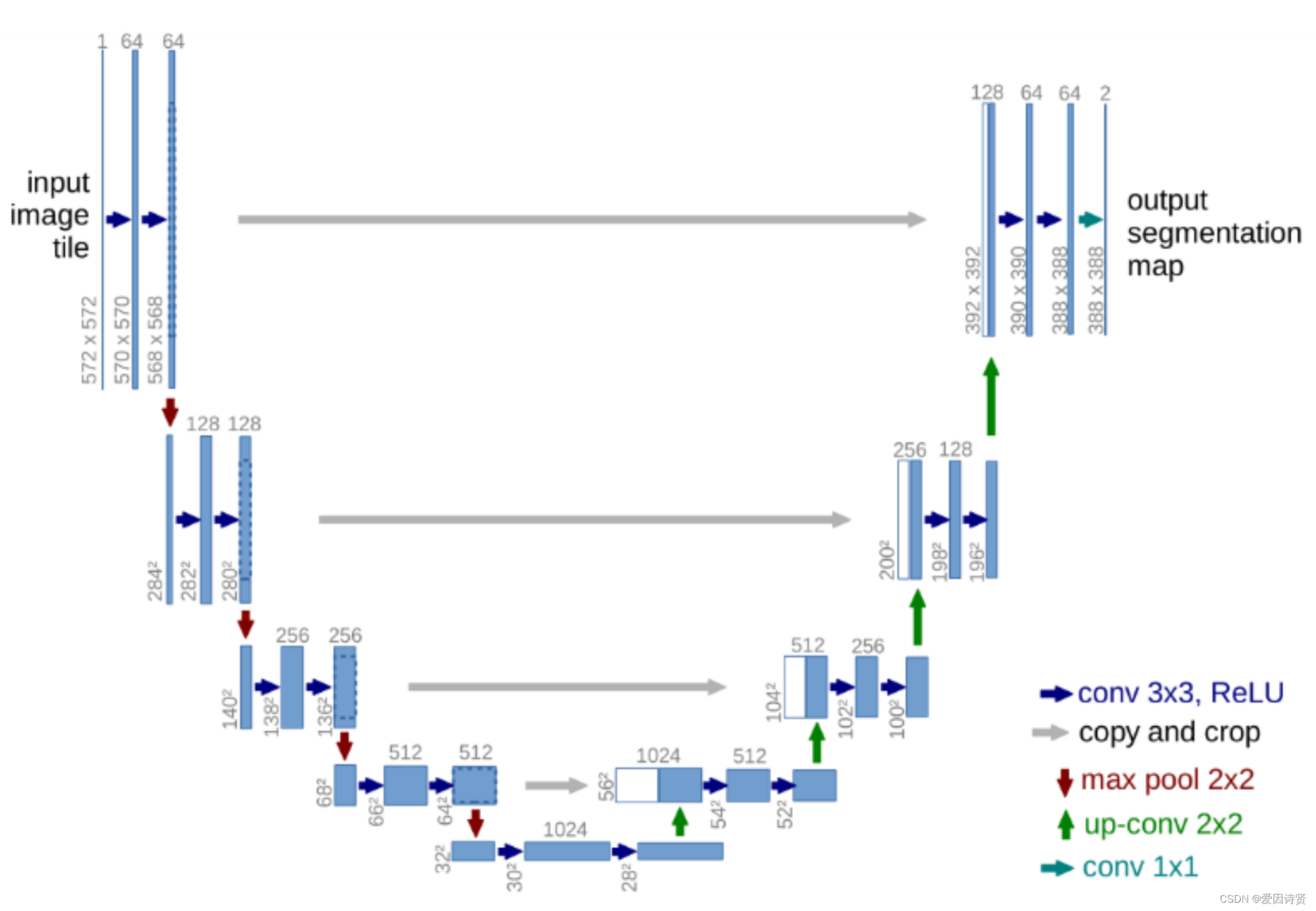
分布式系统架构与负载均衡
针对向量数据规模庞大的问题,单机无法满足存储、计算需求, 所以必须要使用分布式系统。例如下图是腾讯云向量数据库分布式架构图,客户的请求通过负载均衡分发到各节点上,每个节点均可直接进行读/写操作,负责数据的计算及存储。

向量索引技术
向量数据维度很高,直接进行全量扫描或者基于树结构 的索引会导致效率低下或者内存爆炸。向量索引技术是一种专门用于向量数据的索引方法,旨在加快对向量数据的相似度搜索和查询操作。 首先对向量数据进行向量化计算,将每个向量映射到一个高维空间中。然后根据向量之间的相似度定义构建索引结构。常用的向量索引方法包括:
- FLAT:在FLAT 索引中,向量会以浮点型的方式进行存储,不做任何压缩处理。搜索向量会遍历所有向量与目标向量进行比较。当查询数量较少时,它是最有效的索引方法。当数据集非常大时,FLAT 的性能会明显下降。FLAT 适用于数据量小,且需要精确匹配的场景等。
- HNSW:是一种基于图的算法,它在高维空间中能够保持较高的精度。HNSW 通过建立一个多层级的图结构来组织数据集,并且使用随机游走来搜索最近邻。HNSW 的构建过程比 FLAT 更为复杂,需要更多的计算资源,但检索速度更快。HNSW 适用于需要快速近似匹配的场景等。
- IVF系列:IVF 系列索引的核心思想是将高维空间划分为多个聚类,并为每个聚类构建一个倒排文件。通过这种方法,IVF 系列索引可以在大规模高维向量数据中实现高效的相似性搜索。
腾讯云向量数据库的优势
以上种种技术难点一定程度上阻碍了向量数据库的大规模落地和使用,全球很多顶尖高科技公司和组织都在投入这个领域的研究。例如国际市场上,Zilliz与Nvidia、IBM、 Mircosoft等公司展开合作;Pinecone先后上架Google云和AWS,逐步打开市场。在国内市场腾讯云向量数据库(Tencent Cloud VectorDB)无疑是表现最抢眼的产品之一,凭借着强悍的性能、超高的稳定性和可靠性、超高性价比吸引了越来越多的用户。
强悍性能
腾讯云向量数据库单索引支持10亿级向量数据规模,在同等向量维度下和数据量级下,相比于开源向量数据库有极大的性能提升,博主在下一节也亲手测试体验了强悍的性能表现。
如此强大的性能能力建立在云原生的分布式架构基础上,做了大量的负载均衡优化、向量检索优化、向量分析优化等,体现了腾讯云深厚的技术功底。
超高性价比
腾讯云向量数据库从诞生之初就是基于云原生而设计的,得益于腾讯云完善的基础设施,用户直接在云上操作,可以大大减少机器成本和运维成本。所以选择腾讯云向量数据库无疑是超高性价比的选择。
高兼容性
向量数据库支持多种类型和格式的向量数据,同时提供多种语言和平台的接口和工具,具备高度的兼容性,方便用户进行集成和使用。腾讯云向量数据库提供了Python SDK和HTTP SDK两种SDK,例如使用Python SDK只需要执行下面的pip命令安装 tcvectordb库即可。
| Shell |
Python SDK提供了创建表格、写入数据、查询数据、相似性检索等API接口,使用起来非常方便。用户可以在官方手册中找到更多的教程和示例。
性能实测:128维向量查询
准备工作
最近腾讯云向量数据库也开放了产品内测功能,大家可以去官网按照产品手册的指导,亲手内测体验一下吧!博主很幸运率先体验到了腾讯云向量数据库,并亲手测了大家最关心的数据库性能、稳定性和可靠性,没来得及体验的朋友就请先跟着博主的视角一睹为快吧!

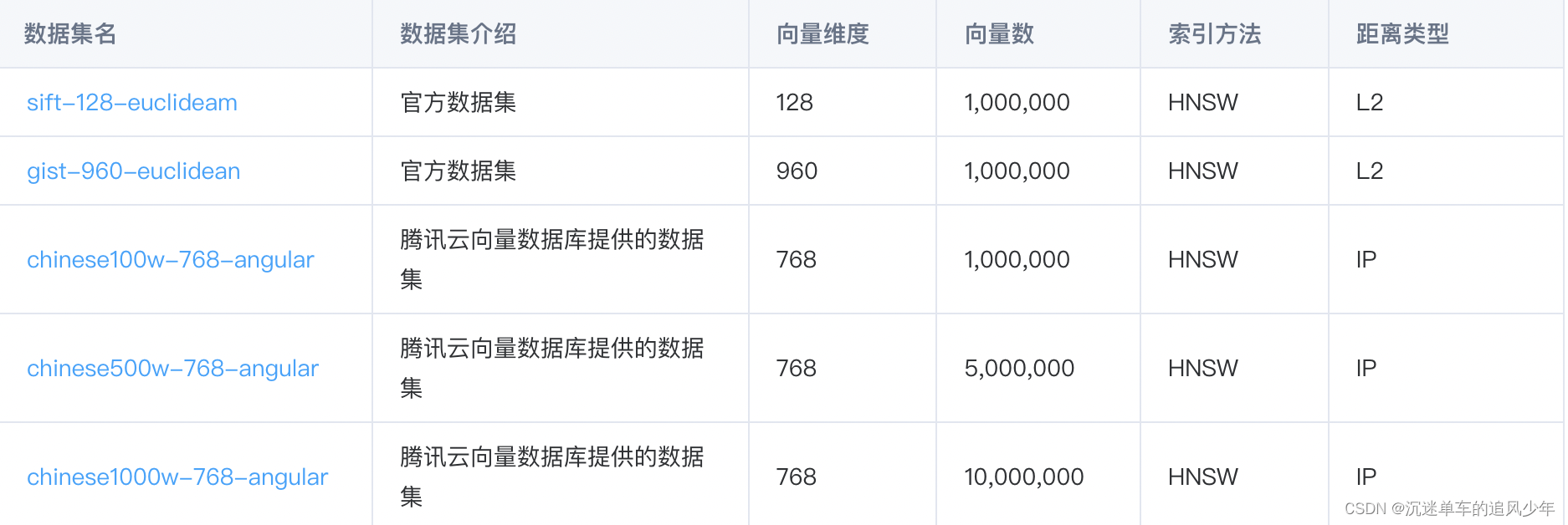
在正式测评前,先介绍以下我们的测试工具ann-benchamrk 。这是是一个用于评估近似最近邻(ANN)搜索库的性能测试工具,包含了多个真实数据集,其中包括图像、文本、生物信息学等领域的数据。每个数据集都有一个已知的最近邻集合,可以用作性能评估的标准。此外,ANN-Benchmarks还提供了一些常用的评估指标,如精确度、查询时间和内存消耗等,用于衡量不同算法在近似最近邻搜索任务中的性能。具体数据集信息如下表所示:
我们首先在控制台新建一个向量数据库:

在新建完数据库后,我们可以点进实例列表查看我们刚才新建实例的基本信息、规格信息和架构图:

为了测试需要,我们还需要购买一台CVM云服务器,可以根据自身需求购买不同配置的服务器:
购买时博主选择了按量计费的模型,配置如下:

执行测试
在开通完CVM之后,我们启动机器,打开我们的测试工具ann-benchamrk,安装测试环境依赖的包:


然后我们拷贝ann_benchmarks/algorithms/vector_db/config.yml 路径下的配置文件,重新命名为mytest.yml。查看我们刚才创建的向量数据库,配置数据库实例内网 IP 地址与端口。

接下来运行run.py执行128维向量性能测试:

多进程压测结果
我们用L2 euclidean欧式距离做衡量,在数据集量级100w和128维向量检索的条件下,获取最相似的 Top10的文档,比较QPS数据。腾讯云向量数据库的HNSW 索引都可以达到99%以上的召回率,QPS大约在13800以上,开源的向量数据库Faiss、Elasticsearch等在同等测试条件下,QPS都不超过4000,所以腾讯云向量数据库取得了至少3倍以上的性能提升。
结语
大模型的热潮宣告着人工智能的又一波高潮已经到来,向量数据库作为人工智能时代的基座,必将迎来一个飞速发展的新阶段。博主亲手体验了腾讯云向量数据库,能够切实解决传统数据库的诸多难点,强悍的性能和稳定性令我大受震撼。未来必定是属于AI的时代,让我们一起拥抱AI,拥抱向量数据库吧!