尝试使用PaddleOCR方法,如何使用自定义的模型方法,参数怎么配置,图片识别尝试简单提高识别率方法。
目前仅仅只是初步学习下如何使用PaddleOCR的方法。
一,测试识别图片:
1.png :

正确文本内容为“哲学可以帮助辩别现代科技创新发展的方向”
二,测试代码:
paddleocr_test2.py : 结合使用了之前学习的PIL和NumPy库,自定义模型实际还是使用的官网提供的最新版本模型,我还没学习如何自己训练模型,只是为了学习如何使用参数变量。
from paddleocr import PaddleOCR
from PIL import Image,ImageDraw
import numpy as np'''
自定义模型测试ocr方法
'''
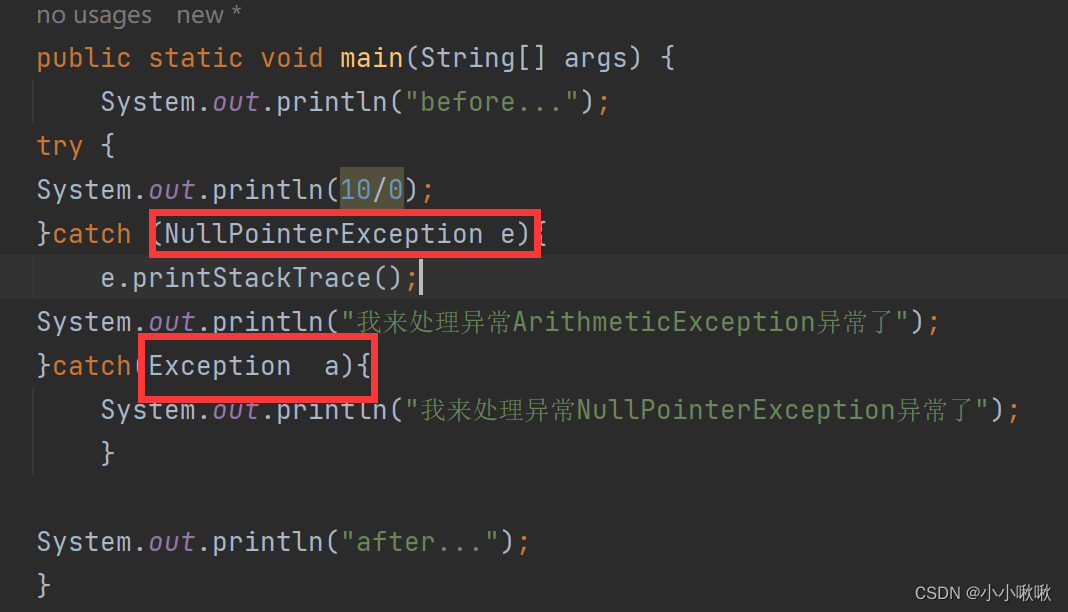
def test_model_ocr(img):# paddleocr 目前支持的多语言语种可以通过修改lang参数进行切换# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`# 使用CPU预加载,不用GPU# 模型路径下必须包含model和params文件,目前开源的v3版本模型 已经是识别率很高的了# 还要更好的就要自己训练模型了。ocr = PaddleOCR(det_model_dir='./inference/ch_PP-OCRv3_det_infer/',rec_model_dir='./inference/ch_PP-OCRv3_rec_infer/',cls_model_dir='./inference/ch_ppocr_mobile_v2.0_cls_infer/',use_angle_cls=True, lang="ch", use_gpu=False)# 识别图片文件result = ocr.ocr(img, cls=True)return result# 打印所有结果信息
def print_ocr_result(result):# print(result)for index in range(len(result)):rst = result[index]for line in rst:points = line[0]text = line[1][0]score = line[1][1]print('points : ', points)print('text : ', text)print('score : ', score)print('==========================================')# 转换图片
def convert_image(image, threshold=None):# 阈值 控制二值化程度,不能超过256,[200, 256]# 适当调大阈值,可以提高文本识别率,经过测试有效。if threshold is None:threshold = 200print('threshold : ', threshold)# 首先进行图片灰度处理image = image.convert("L")pixels = image.load()# 在进行二值化for x in range(image.width):for y in range(image.height):if pixels[x, y] > threshold:pixels[x, y] = 255else:pixels[x, y] = 0return imageif __name__ == "__main__":img_path = "1.png"# 1,直接识别图片文本print('1,直接识别图片文本')result1 = test_model_ocr(img_path)# 打印所有结果信息print_ocr_result(result1)# 2,转换为ndarray数组 识别图片文本print('2,转换为ndarray数组 识别图片文本')# 打开图片img1 = Image.open(img_path)# Image图像转换为ndarray数组img_1 = np.array(img1)# print(img_1)result2 = test_model_ocr(img_1)# 打印所有结果信息print_ocr_result(result2)# 3,转换图片, 识别图片文本print('3,转换图片,阈值=200时,再转换为ndarray数组, 识别图片文本')# 转换图片img2 = convert_image(img1, 200)# img2.show()# img2.save("11.png")# Image图像转换为ndarray数组img_2 = np.array(img2)# print(img_2)# 识别图片result3 = test_model_ocr(img_2)# 打印所有结果信息print_ocr_result(result3)# 4,转换图片, 识别图片文本print('4,转换图片,阈值=220时,再转换为ndarray数组, 识别图片文本')# 转换图片img3 = convert_image(img1, 220)# Image图像转换为ndarray数组img_3 = np.array(img3)# 识别图片result4 = test_model_ocr(img_3)# 打印所有结果信息print_ocr_result(result4)三,测试结果:
1,直接识别图片文本
[2023/06/25 10:38:41] ppocr DEBUG: Namespace(alpha=1.0, benchmark=False, beta=1.0, cls_batch_num=6, cls_image_shape='3, 48, 192', cls_model_dir='./inference/ch_ppocr_mobile_v2.0_cls_infer/', cls_thresh=0.9, cpu_threads=10, crop_res_save_dir='./output', det=True, det_algorithm='DB', det_box_type='quad', det_db_box_thresh=0.6, det_db_score_mode='fast', det_db_thresh=0.3, det_db_unclip_ratio=1.5, det_east_cover_thresh=0.1, det_east_nms_thresh=0.2, det_east_score_thresh=0.8, det_limit_side_len=960, det_limit_type='max', det_model_dir='./inference/ch_PP-OCRv3_det_infer/', det_pse_box_thresh=0.85, det_pse_min_area=16, det_pse_scale=1, det_pse_thresh=0, det_sast_nms_thresh=0.2, det_sast_score_thresh=0.5, draw_img_save_dir='./inference_results', drop_score=0.5, e2e_algorithm='PGNet', e2e_char_dict_path='./ppocr/utils/ic15_dict.txt', e2e_limit_side_len=768, e2e_limit_type='max', e2e_model_dir=None, e2e_pgnet_mode='fast', e2e_pgnet_score_thresh=0.5, e2e_pgnet_valid_set='totaltext', enable_mkldnn=False, fourier_degree=5, gpu_mem=500, help='==SUPPRESS==', image_dir=None, image_orientation=False, ir_optim=True, kie_algorithm='LayoutXLM', label_list=['0', '180'], lang='ch', layout=True, layout_dict_path=None, layout_model_dir=None, layout_nms_threshold=0.5, layout_score_threshold=0.5, max_batch_size=10, max_text_length=25, merge_no_span_structure=True, min_subgraph_size=15, mode='structure', ocr=True, ocr_order_method=None, ocr_version='PP-OCRv3', output='./output', page_num=0, precision='fp32', process_id=0, re_model_dir=None, rec=True, rec_algorithm='SVTR_LCNet', rec_batch_num=6, rec_char_dict_path='C:\\Users\\86159\\AppData\\Local\\Programs\\Python\\Python37\\lib\\site-packages\\paddleocr\\ppocr\\utils\\ppocr_keys_v1.txt', rec_image_inverse=True, rec_image_shape='3, 48, 320', rec_model_dir='./inference/ch_PP-OCRv3_rec_infer/', recovery=False, save_crop_res=False, save_log_path='./log_output/', scales=[8, 16, 32], ser_dict_path='../train_data/XFUND/class_list_xfun.txt', ser_model_dir=None, show_log=True, sr_batch_num=1, sr_image_shape='3, 32, 128', sr_model_dir=None, structure_version='PP-StructureV2', table=True, table_algorithm='TableAttn', table_char_dict_path=None, table_max_len=488, table_model_dir=None, total_process_num=1, type='ocr', use_angle_cls=True, use_dilation=False, use_gpu=False, use_mp=False, use_npu=False, use_onnx=False, use_pdf2docx_api=False, use_pdserving=False, use_space_char=True, use_tensorrt=False, use_visual_backbone=True, use_xpu=False, vis_font_path='./doc/fonts/simfang.ttf', warmup=False)
[2023/06/25 10:38:41] ppocr DEBUG: dt_boxes num : 1, elapse : 0.022063255310058594
[2023/06/25 10:38:41] ppocr DEBUG: cls num : 1, elapse : 0.007994413375854492
[2023/06/25 10:38:42] ppocr DEBUG: rec_res num : 1, elapse : 0.22030949592590332
points : [[17.0, 14.0], [514.0, 14.0], [514.0, 33.0], [17.0, 33.0]]
text : 哲学可以帮助辨别现代科技创新发展的方声
score : 0.8344171047210693
==========================================
2,转换为ndarray数组 识别图片文本
[2023/06/25 10:38:42] ppocr DEBUG: Namespace(alpha=1.0, benchmark=False, beta=1.0, cls_batch_num=6, cls_image_shape='3, 48, 192', cls_model_dir='./inference/ch_ppocr_mobile_v2.0_cls_infer/', cls_thresh=0.9, cpu_threads=10, crop_res_save_dir='./output', det=True, det_algorithm='DB', det_box_type='quad', det_db_box_thresh=0.6, det_db_score_mode='fast', det_db_thresh=0.3, det_db_unclip_ratio=1.5, det_east_cover_thresh=0.1, det_east_nms_thresh=0.2, det_east_score_thresh=0.8, det_limit_side_len=960, det_limit_type='max', det_model_dir='./inference/ch_PP-OCRv3_det_infer/', det_pse_box_thresh=0.85, det_pse_min_area=16, det_pse_scale=1, det_pse_thresh=0, det_sast_nms_thresh=0.2, det_sast_score_thresh=0.5, draw_img_save_dir='./inference_results', drop_score=0.5, e2e_algorithm='PGNet', e2e_char_dict_path='./ppocr/utils/ic15_dict.txt', e2e_limit_side_len=768, e2e_limit_type='max', e2e_model_dir=None, e2e_pgnet_mode='fast', e2e_pgnet_score_thresh=0.5, e2e_pgnet_valid_set='totaltext', enable_mkldnn=False, fourier_degree=5, gpu_mem=500, help='==SUPPRESS==', image_dir=None, image_orientation=False, ir_optim=True, kie_algorithm='LayoutXLM', label_list=['0', '180'], lang='ch', layout=True, layout_dict_path=None, layout_model_dir=None, layout_nms_threshold=0.5, layout_score_threshold=0.5, max_batch_size=10, max_text_length=25, merge_no_span_structure=True, min_subgraph_size=15, mode='structure', ocr=True, ocr_order_method=None, ocr_version='PP-OCRv3', output='./output', page_num=0, precision='fp32', process_id=0, re_model_dir=None, rec=True, rec_algorithm='SVTR_LCNet', rec_batch_num=6, rec_char_dict_path='C:\\Users\\86159\\AppData\\Local\\Programs\\Python\\Python37\\lib\\site-packages\\paddleocr\\ppocr\\utils\\ppocr_keys_v1.txt', rec_image_inverse=True, rec_image_shape='3, 48, 320', rec_model_dir='./inference/ch_PP-OCRv3_rec_infer/', recovery=False, save_crop_res=False, save_log_path='./log_output/', scales=[8, 16, 32], ser_dict_path='../train_data/XFUND/class_list_xfun.txt', ser_model_dir=None, show_log=True, sr_batch_num=1, sr_image_shape='3, 32, 128', sr_model_dir=None, structure_version='PP-StructureV2', table=True, table_algorithm='TableAttn', table_char_dict_path=None, table_max_len=488, table_model_dir=None, total_process_num=1, type='ocr', use_angle_cls=True, use_dilation=False, use_gpu=False, use_mp=False, use_npu=False, use_onnx=False, use_pdf2docx_api=False, use_pdserving=False, use_space_char=True, use_tensorrt=False, use_visual_backbone=True, use_xpu=False, vis_font_path='./doc/fonts/simfang.ttf', warmup=False)
[2023/06/25 10:38:42] ppocr DEBUG: dt_boxes num : 1, elapse : 0.018141746520996094
[2023/06/25 10:38:42] ppocr DEBUG: cls num : 1, elapse : 0.007776021957397461
[2023/06/25 10:38:43] ppocr DEBUG: rec_res num : 1, elapse : 0.23012638092041016
points : [[16.0, 14.0], [514.0, 14.0], [514.0, 33.0], [16.0, 33.0]]
text : 哲学可以帮助辨别现代科技创新发展的方户
score : 0.8683586120605469
==========================================
3,转换图片,阈值=200时,再转换为ndarray数组, 识别图片文本
threshold : 200
[2023/06/25 10:38:43] ppocr DEBUG: Namespace(alpha=1.0, benchmark=False, beta=1.0, cls_batch_num=6, cls_image_shape='3, 48, 192', cls_model_dir='./inference/ch_ppocr_mobile_v2.0_cls_infer/', cls_thresh=0.9, cpu_threads=10, crop_res_save_dir='./output', det=True, det_algorithm='DB', det_box_type='quad', det_db_box_thresh=0.6, det_db_score_mode='fast', det_db_thresh=0.3, det_db_unclip_ratio=1.5, det_east_cover_thresh=0.1, det_east_nms_thresh=0.2, det_east_score_thresh=0.8, det_limit_side_len=960, det_limit_type='max', det_model_dir='./inference/ch_PP-OCRv3_det_infer/', det_pse_box_thresh=0.85, det_pse_min_area=16, det_pse_scale=1, det_pse_thresh=0, det_sast_nms_thresh=0.2, det_sast_score_thresh=0.5, draw_img_save_dir='./inference_results', drop_score=0.5, e2e_algorithm='PGNet', e2e_char_dict_path='./ppocr/utils/ic15_dict.txt', e2e_limit_side_len=768, e2e_limit_type='max', e2e_model_dir=None, e2e_pgnet_mode='fast', e2e_pgnet_score_thresh=0.5, e2e_pgnet_valid_set='totaltext', enable_mkldnn=False, fourier_degree=5, gpu_mem=500, help='==SUPPRESS==', image_dir=None, image_orientation=False, ir_optim=True, kie_algorithm='LayoutXLM', label_list=['0', '180'], lang='ch', layout=True, layout_dict_path=None, layout_model_dir=None, layout_nms_threshold=0.5, layout_score_threshold=0.5, max_batch_size=10, max_text_length=25, merge_no_span_structure=True, min_subgraph_size=15, mode='structure', ocr=True, ocr_order_method=None, ocr_version='PP-OCRv3', output='./output', page_num=0, precision='fp32', process_id=0, re_model_dir=None, rec=True, rec_algorithm='SVTR_LCNet', rec_batch_num=6, rec_char_dict_path='C:\\Users\\86159\\AppData\\Local\\Programs\\Python\\Python37\\lib\\site-packages\\paddleocr\\ppocr\\utils\\ppocr_keys_v1.txt', rec_image_inverse=True, rec_image_shape='3, 48, 320', rec_model_dir='./inference/ch_PP-OCRv3_rec_infer/', recovery=False, save_crop_res=False, save_log_path='./log_output/', scales=[8, 16, 32], ser_dict_path='../train_data/XFUND/class_list_xfun.txt', ser_model_dir=None, show_log=True, sr_batch_num=1, sr_image_shape='3, 32, 128', sr_model_dir=None, structure_version='PP-StructureV2', table=True, table_algorithm='TableAttn', table_char_dict_path=None, table_max_len=488, table_model_dir=None, total_process_num=1, type='ocr', use_angle_cls=True, use_dilation=False, use_gpu=False, use_mp=False, use_npu=False, use_onnx=False, use_pdf2docx_api=False, use_pdserving=False, use_space_char=True, use_tensorrt=False, use_visual_backbone=True, use_xpu=False, vis_font_path='./doc/fonts/simfang.ttf', warmup=False)
[2023/06/25 10:38:43] ppocr DEBUG: dt_boxes num : 1, elapse : 0.017957448959350586
[2023/06/25 10:38:43] ppocr DEBUG: cls num : 1, elapse : 0.008005380630493164
[2023/06/25 10:38:43] ppocr DEBUG: rec_res num : 1, elapse : 0.21948766708374023
points : [[16.0, 14.0], [513.0, 14.0], [513.0, 33.0], [16.0, 33.0]]
text : 哲学可以帮助孵别现代科技创新发展的方向
score : 0.8875740170478821
==========================================
4,转换图片,阈值=220时,再转换为ndarray数组, 识别图片文本
threshold : 220
[2023/06/25 10:38:43] ppocr DEBUG: Namespace(alpha=1.0, benchmark=False, beta=1.0, cls_batch_num=6, cls_image_shape='3, 48, 192', cls_model_dir='./inference/ch_ppocr_mobile_v2.0_cls_infer/', cls_thresh=0.9, cpu_threads=10, crop_res_save_dir='./output', det=True, det_algorithm='DB', det_box_type='quad', det_db_box_thresh=0.6, det_db_score_mode='fast', det_db_thresh=0.3, det_db_unclip_ratio=1.5, det_east_cover_thresh=0.1, det_east_nms_thresh=0.2, det_east_score_thresh=0.8, det_limit_side_len=960, det_limit_type='max', det_model_dir='./inference/ch_PP-OCRv3_det_infer/', det_pse_box_thresh=0.85, det_pse_min_area=16, det_pse_scale=1, det_pse_thresh=0, det_sast_nms_thresh=0.2, det_sast_score_thresh=0.5, draw_img_save_dir='./inference_results', drop_score=0.5, e2e_algorithm='PGNet', e2e_char_dict_path='./ppocr/utils/ic15_dict.txt', e2e_limit_side_len=768, e2e_limit_type='max', e2e_model_dir=None, e2e_pgnet_mode='fast', e2e_pgnet_score_thresh=0.5, e2e_pgnet_valid_set='totaltext', enable_mkldnn=False, fourier_degree=5, gpu_mem=500, help='==SUPPRESS==', image_dir=None, image_orientation=False, ir_optim=True, kie_algorithm='LayoutXLM', label_list=['0', '180'], lang='ch', layout=True, layout_dict_path=None, layout_model_dir=None, layout_nms_threshold=0.5, layout_score_threshold=0.5, max_batch_size=10, max_text_length=25, merge_no_span_structure=True, min_subgraph_size=15, mode='structure', ocr=True, ocr_order_method=None, ocr_version='PP-OCRv3', output='./output', page_num=0, precision='fp32', process_id=0, re_model_dir=None, rec=True, rec_algorithm='SVTR_LCNet', rec_batch_num=6, rec_char_dict_path='C:\\Users\\86159\\AppData\\Local\\Programs\\Python\\Python37\\lib\\site-packages\\paddleocr\\ppocr\\utils\\ppocr_keys_v1.txt', rec_image_inverse=True, rec_image_shape='3, 48, 320', rec_model_dir='./inference/ch_PP-OCRv3_rec_infer/', recovery=False, save_crop_res=False, save_log_path='./log_output/', scales=[8, 16, 32], ser_dict_path='../train_data/XFUND/class_list_xfun.txt', ser_model_dir=None, show_log=True, sr_batch_num=1, sr_image_shape='3, 32, 128', sr_model_dir=None, structure_version='PP-StructureV2', table=True, table_algorithm='TableAttn', table_char_dict_path=None, table_max_len=488, table_model_dir=None, total_process_num=1, type='ocr', use_angle_cls=True, use_dilation=False, use_gpu=False, use_mp=False, use_npu=False, use_onnx=False, use_pdf2docx_api=False, use_pdserving=False, use_space_char=True, use_tensorrt=False, use_visual_backbone=True, use_xpu=False, vis_font_path='./doc/fonts/simfang.ttf', warmup=False)
[2023/06/25 10:38:44] ppocr DEBUG: dt_boxes num : 1, elapse : 0.019538402557373047
[2023/06/25 10:38:44] ppocr DEBUG: cls num : 1, elapse : 0.00800013542175293
[2023/06/25 10:38:44] ppocr DEBUG: rec_res num : 1, elapse : 0.22036981582641602
points : [[15.0, 14.0], [515.0, 14.0], [515.0, 33.0], [15.0, 33.0]]
text : 哲学可以帮助辩别现代科技创新发展的方向
score : 0.8834166526794434
==========================================通过测试结果可以看出,图片经过二值化转换后,再转换为ndarray数组,最后再调用PaddlerOCR识别方法,返回的识别文本最为准确。
之前也了解过OCR识别的步骤流程,后面还要继续深入学习下,从这几个方面提高图片识别率。
=====================================================================
步骤流程:
1. 图像输入、预处理:
不同的图像格式有不同的存储、压缩方式,目前有OpenCV、CxImage等。
2. 二值化:
如今数码摄像头拍摄的图片大多是彩色图像,彩色图像所含信息量巨大,不适用于OCR技术。为了让计算机更快的、更好地进行OCR相关计算,
我们需要先对彩色图进行处理,使图片只剩下前景信息与背景信息。二值化也可以简单地将其理解为“黑白化”。
3. 图像降噪:
对于不同的图像根据噪点的特征进行去噪的过程称为降噪。
4. 倾斜校正:
由于一般用户,在拍照文档时,难以拍摄得完全符合水平平齐与竖直平齐(我本人就经常拍的歪歪扭扭),
因此拍照出来的图片不可避免的产生倾斜,这就需要图像处理软件进行校正。
5. 版面分析:
将文档图片分段落,分行的过程称为版面分析。
6. 字符切割:
由于拍照、书写条件的限制,经常造成字符粘连、断笔,直接使用此类图像进行OCR分析将会极大限制OCR性能。
因此需要进行字符切割,即:将不同字符之间分割开。
7. 字符识别:
早期以模板匹配为主,后期以结合深度网络的特征提取为主。版面还原:将识别后的文字像原始文档图片那样排列,
段落、位置、顺序不变地输出到Word文档、PDF文档等,这一过程称为版面还原。
8. 后期处理:根据特定的语言上下文的关系,对识别结果进行校正。
9. 输出:将识别出的字符以某一格式的文本输出。
=====================================================================