1 Kafka的工具类
1.1 从kafka消费数据的方法
- 消费者代码
def getKafkaDStream(ssc : StreamingContext , topic: String , groupId:String ) ={consumerConfigs.put(ConsumerConfig.GROUP_ID_CONFIG , groupId)val kafkaDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](Array(topic), consumerConfigs))kafkaDStream}
- 注意点
- consumerConfigs是定义的可变的map的类型的,具体如下
private val consumerConfigs: mutable.Map[String, Object] = mutable.Map[String,Object](// kafka集群位置ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> MyPropsUtils(MyConfig.KAFKA_BOOTSTRAP_SERVERS),// kv反序列化器ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer",ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer",// groupId// offset提交 自动 手动ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG -> "true",//自动提交的时间间隔//ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG// offset重置 "latest" "earliest"ConsumerConfig.AUTO_OFFSET_RESET_CONFIG -> "latest"// .....)
-
consumerConfigs.put(ConsumerConfig.GROUP_ID_CONFIG , groupId)是为了不限制groupId特意写的传参
-
是使用自带的kafka工具类createDirectStream方法去消费kafak 的数据,详细参数解释如下
在`KafkaUtils.createDirectStream`方法中,后续传递的参数的含义如下:1. `ssc`:这是一个`StreamingContext`对象,用于指定Spark Streaming的上下文。
2. `LocationStrategies.PreferConsistent`:这是一个位置策略,用于指定Kafka消费者的位置策略。`PreferConsistent`表示优先选择分区分布均匀的消费者。
3. `ConsumerStrategies.Subscribe[String, String]`:这是一个消费者策略,用于指定Kafka消费者的订阅策略。`Subscribe[String, String]`表示按照指定的泛型主题字符串数组订阅消息,键和值的类型都为`String`。
4. `Array(topic)`:这是一个字符串数组,用于指定要订阅的Kafka主题。
5. `consumerConfigs`:这是一个`java.util.Properties`类型的对象,其中配置了一些Kafka消费者的属性。总之,在`KafkaUtils.createDirectStream`方法中,这些参数组合被用于创建一个Kafka直连流(Direct Stream),该流可以直接从Kafka主题中消费消息,并将其转换为`InputDStream[ConsumerRecord[String, String]]`类型的DStream。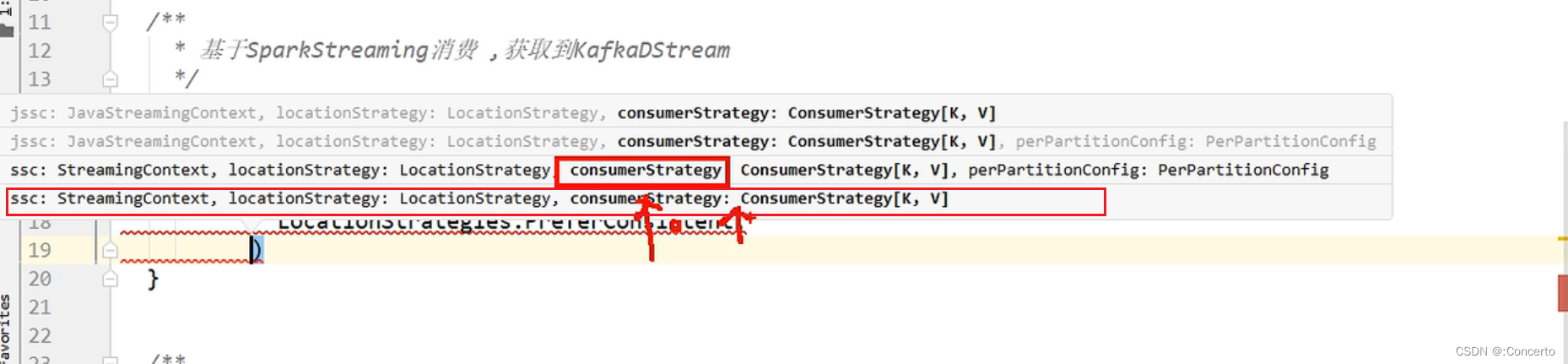
- Subscribe传参需要指定泛型,这边指定string,表示指定主题的键和值的类型,即Array(topic), consumerConfigs传参是string

- 最后方法返回一个kafkaDStream
1.2 kafka的生产数据的方法
- 生产者代码
- 创建与配置
/*** 生产者对象*/val producer : KafkaProducer[String,String] = createProducer()/*** 创建生产者对象*/def createProducer():KafkaProducer[String,String] = {val producerConfigs: util.HashMap[String, AnyRef] = new util.HashMap[String,AnyRef]//生产者配置类 ProducerConfig//kafka集群位置//producerConfigs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092,hadoop104:9092")//producerConfigs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,MyPropsUtils("kafka.bootstrap-servers"))producerConfigs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,MyPropsUtils(MyConfig.KAFKA_BOOTSTRAP_SERVERS))//kv序列化器producerConfigs.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG , "org.apache.kafka.common.serialization.StringSerializer")producerConfigs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG , "org.apache.kafka.common.serialization.StringSerializer")//acksproducerConfigs.put(ProducerConfig.ACKS_CONFIG , "all")//batch.size 16kb//linger.ms 0//retries//幂等配置producerConfigs.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG , "true")val producer: KafkaProducer[String, String] = new KafkaProducer[String,String](producerConfigs)producer}
- 生产方法
/*** 生产(按照默认的黏性分区策略)*/def send(topic : String , msg : String ):Unit = {producer.send(new ProducerRecord[String,String](topic , msg ))}/**或者!* 生产(按照key进行分区)*/def send(topic : String , key : String , msg : String ):Unit = {producer.send(new ProducerRecord[String,String](topic , key , msg ))}
- 关闭生产
/*** 关闭生产者对象*/def close():Unit = {if(producer != null ) producer.close()}/*** 刷写 ,将缓冲区的数据刷写到磁盘**/def flush(): Unit ={producer.flush()}
2 消费数据
2.1 消费到数据
单纯的使用返回的ConsumerRecord不支持序列化,没有实现序列化接口
因此需要转换成通用的jsonobject对象
//3. 处理数据//3.1 转换数据结构val jsonObjDStream: DStream[JSONObject] = offsetRangesDStream.map(consumerRecord => {//获取ConsumerRecord中的value,value就是日志数据val log: String = consumerRecord.value()//转换成Json对象val jsonObj: JSONObject = JSON.parseObject(log)//返回jsonObj})
2.2 数据分流发送到对应topic
- 提取错误数据并发送到对应的topic中
jsonObjDStream.foreachRDD(rdd => {rdd.foreachPartition(jsonObjIter => {for (jsonObj <- jsonObjIter) {//分流过程//分流错误数据val errObj: JSONObject = jsonObj.getJSONObject("err")if(errObj != null){//将错误数据发送到 DWD_ERROR_LOG_TOPICMyKafkaUtils.send(DWD_ERROR_LOG_TOPIC , jsonObj.toJSONString )}else{}}}}
- 将公共字段和页面数据发送到DWD_PAGE_DISPLAY_TOPIC
else{// 提取公共字段val commonObj: JSONObject = jsonObj.getJSONObject("common")val ar: String = commonObj.getString("ar")val uid: String = commonObj.getString("uid")val os: String = commonObj.getString("os")val ch: String = commonObj.getString("ch")val isNew: String = commonObj.getString("is_new")val md: String = commonObj.getString("md")val mid: String = commonObj.getString("mid")val vc: String = commonObj.getString("vc")val ba: String = commonObj.getString("ba")//提取时间戳val ts: Long = jsonObj.getLong("ts")// 页面数据val pageObj: JSONObject = jsonObj.getJSONObject("page")if(pageObj != null ){//提取page字段val pageId: String = pageObj.getString("page_id")val pageItem: String = pageObj.getString("item")val pageItemType: String = pageObj.getString("item_type")val duringTime: Long = pageObj.getLong("during_time")val lastPageId: String = pageObj.getString("last_page_id")val sourceType: String = pageObj.getString("source_type")//封装成PageLog,这边还写了bean实体类去接收var pageLog =PageLog(mid,uid,ar,ch,isNew,md,os,vc,ba,pageId,lastPageId,pageItem,pageItemType,duringTime,sourceType,ts)//发送到DWD_PAGE_LOG_TOPICMyKafkaUtils.send(DWD_PAGE_LOG_TOPIC , JSON.toJSONString(pageLog , new SerializeConfig(true)))//scala中bean没有set和get方法,这边是直接操作字段}