Producer是Kakfa模型中生产者组件,也就是Kafka架构中数据的生产来源,虽然其整体是比较简单的组件,但依然有很多细节需要细品一番。比如Kafka的Producer实现原理是什么,怎么发送的消息?IO通讯模型是什么?在实际工作中,怎么调优来实现高效性?
简单的生产者程序:

一、客户端初始化 KafkaProducer
new KafkaProducer() 是Producer初始化过程,比如Interceptor、Serializer、Partitioner、RecordAccumulator等。当我们使用KafkaProducer发送消息的时候,消息会经过拦截器(Interceptor)、序列化器(Serializer)和分区器(Partitioner),最后会暂存到消息收集器(RecordAccumulator)中,最终读取按批次发送。
以下跟踪比较核心的机制流程:
1、 初始化RecordAccumulator记录累加器
简单介绍:RecordAccumulator可以理解为Producer发送数据缓冲区,Producer数据发送时并不会直接连接Broker后,一条一条的发送,而是会将数据(Record)放入RecordAccumulator中按批次发送。
2、初始化Sender的Iothread,在Producer在初始化过程中,会额外的创建一个ioThread。


二、Send方法
到此位置Kafka只是做了一些初始化的工作,没有与kafka集群建立连接,更没有相关元数据信息。那继续看send中的doSend方法。
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {TopicPartition tp = null;try {try {// waitOnMetadata更新元数据clusterAndWaitTime = this.waitOnMetadata(record.topic(),record.partition(), this.maxBlockTimeMs);} catch (KafkaException var19) {Cluster cluster = clusterAndWaitTime.cluster;........byte[] serializedKey;try {// 序列化serializedKey = this.keySerializer.serialize(record.topic(), record.headers(), record.key());} catch (ClassCastException var18) {........byte[] serializedValue;try {serializedValue = this.valueSerializer.serialize(record.topic(), record.headers(), record.value());} // 获取元数据中partition信息int partition = this.partition(record, serializedKey, serializedValue, cluster);// ..........// 数据append到accumulator中RecordAppendResult result = this.accumulator.append(tp, timestamp, serializedKey, serializedValue, headers, interceptCallback, remainingWaitMs);..........return result.future;1、WaitonMetadat元数据更新
方法内部会优先判断当前Cluster是否存在元数据partitions,如果不存在意味着还没有建立连接获取元数据,此时它会wakeup唤醒sender线程。

注意:此时Cluster并不是完全时空的,它已经有指定的Node列表信息。
![]()
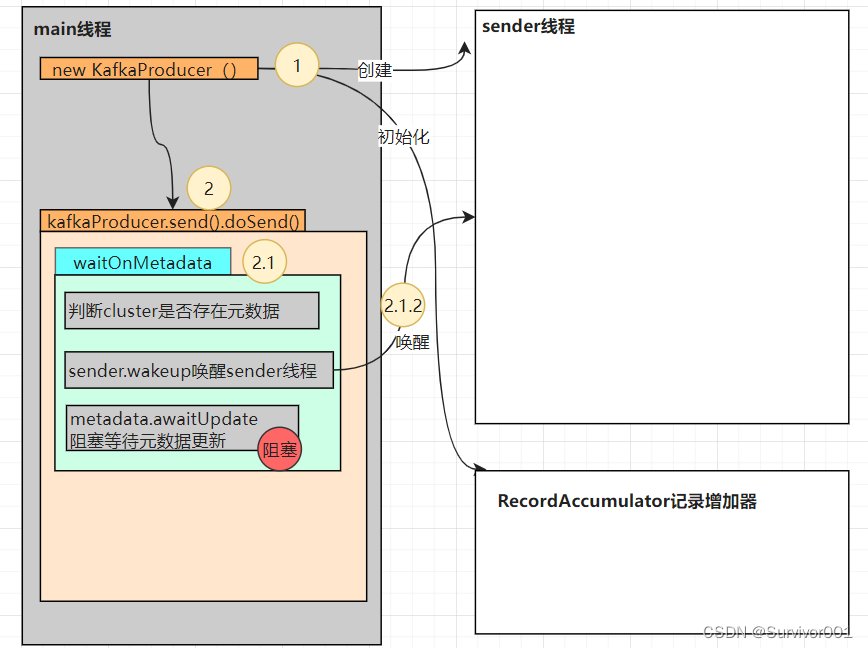
在早期版本的时候元数据是存储在zookeeper中的, 元数据指的是集群中分区信息、节点信息、以及节点、主题、分区的映射关系等。在生产者启动的时候没有元数据的支撑,是无法进行数据的发送的,等于瞎子。但是zookeeper存储元数据,在并发场景下会对zookeeper产生网卡压力,那就意味着要保障Kakfa可靠性的前提就要保障zookeeper的可靠性。
所以在1.0版本之后,Kafka将元数据维护在了Broker节点中。Producer可以通过Borker获取元数据,减少对zookeeper的依赖。只有一些核心的内容交给zookeeper做分布式协调。
2、Sender线程run方法
Sender线程中run方法,一个while(runing),这是一中Loop过程一种常见的响应式编程方式,比如Redis服务中也是一种EventLoop事件轮询过程。

其内部核心方法NetWorkClient.poll实现了客户端连接、数据发送、事件处理工作。

metadataUpdater.maybeUpdate方法在第一次被执行时,因为没有元数据节点信息,会执行this.maybeUpdate(now, node)方法,方法内部实现了initiateConnect方法用于客户端建立连接,其底层就是使用的Java Nio的Selector多路复用器。
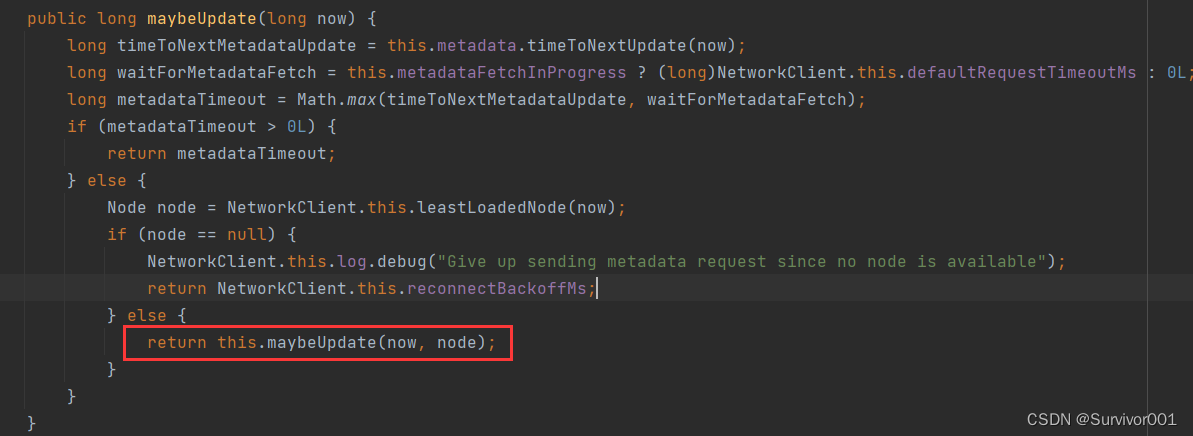

建立连接之后,nioSelector.select()等待事件响应。
之后触发handleCompletedReceives处理器进行元数据同步过程。
注意: 在完成元数据更新以后,metadata.update会调用 this.notifyAll(),唤醒阻塞的main线程,进行数据发送工作。

到此为止主线程waitOnMetadata方法完成元数据的更新。
之后main就开始处理Serializer序列化,获取partition元数据信息,以及数据发送工作。
3、RecordAccumulator 记录累加器
生产者在发送数据时,并不是建立连接后每消息发送的,而是会将消息按批次发送。RecordAccumulator 对象中batches会为每一个TopicPartition维护一个双端队列。用于缓存record数据。
ConcurrentMap<TopicPartition, Deque<ProducerBatch>> batches
TopicPartition 主题分区:缓冲区按照主题分为不同的双端队列
Deque<ProducerBatch> 双端队列,ProducerBatch:一批次的数据(多个数据,默认容量16k)
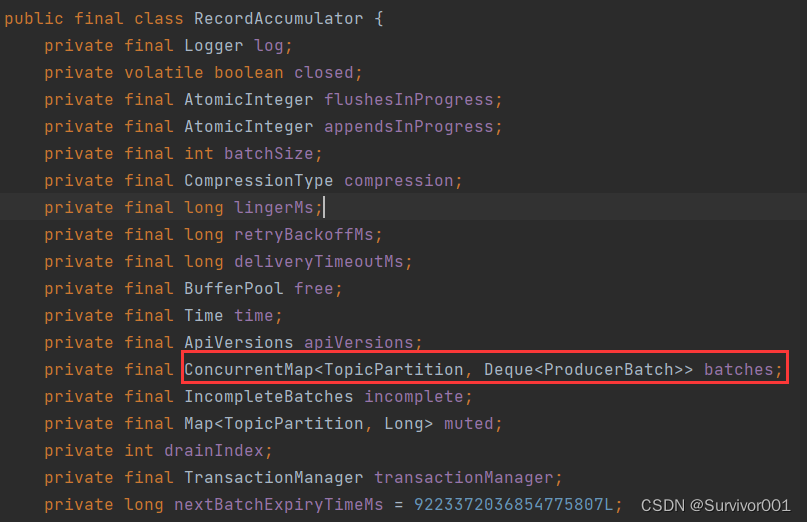
结构如下:

生产者在往batches中添加数据时,使用了Sychronized,所以Producer在多线程场景下是线程安全的。

为什么要有RecordAccumulator ?
RecordAccumulator的主要作用是暂存Main Thread发送过来的消息,然后Sender Thread就可以从RecordAccumulator中批量的获取到消息,减少单个消息获取的请求次数,减少网卡IO压力,提升性能效率。
相关参数配置以及调优点:
1、RecordAccumulator buffer.memory默认大小32mb
指每一个new KafkaProducer中RecordAccumulator的batches所有承载的最大buffer.memory=32mb。

设置方式:properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 3210241024);
如果RecordAccumulator 缓存空间满时,会进行阻塞,等待数据被消费,如果指定时间内消息没有发送除去,即仍然是满状态,则抛出异常,默认60s。
设置方式:properties.put(ProducerConfig.MAX_BLOCK_MS_CONFIG, 60*1000);
优化点: 根据业务需求,如果TopicPartition较多,而数据量很大时,这是及时单个TopicPartition中batche很少,可能总的容量也超过32mb,这时可以扩大buffer_memery大小。
2、Kafka中单个batche大小默认为16k。
指每个batche大小为16k。batche用于存储数据Record。
如果record < 16k,则batche可以存储多个数据,此时batche空间是会被重复利用的。
如果record > 16k,则当前record会额外申请存储空间,使用完后销毁。

优化点:batche大小需要根据业务评估,不要有过多大record存在,确保每一个batche可以容纳record,尽量减少内存空间的频繁申请和销毁,以及内存碎片化。
3、同步阻塞和非阻塞的选择
RecordAccumulator用于支持分批次发送数据。在KafkaProducer中send方法是异步接口,通过 send.get()方法可以使其阻塞,等待数据返回。
实现同步的发送数据,需要等待kafka接收了record后响应,producer才会进行下一个record发送。此时虽然会有更高一致性,但RecordAccumulator就失去了意义。
非阻塞send情况下,当生产和消费端IO不对称时,可以通过LINGRE_MS_CONFG 30 来要求sender线程每次拉取RecordAccumulator中数据时,等待一段时间再拉取,尽量确保按批次拉取,减少更多的网络IO。
设置方式:properties.put(ProducerConfig.LINGRE_MS_C0NFG , 0);
继续内容分析
到此当Main线程将数据append到RecordAccumulator容器后,其核心的工作就结束了,此时它也会调用sender.wakeup,告知已经有数据需要处理了,并确保sender线程不会select阻塞住。
Sender线程是一个Loop过程,在发送数据过程中,会从RecordAccumulator中拉取批次数据进行打包发送,并不是一个个batche发送。默认封装的包大小为1mb。
设置方式:pp.setProperty(ProducerConfig.MAX_REQUEST_SIZE_CONFIG , String.valueOf(1 * 1024 * 1024))
Sender线程在真正发送数据前,还额外存储了Request数据到InFilgntRequest(飞行中的包),InFilgntRequest 默认大小为5,意思是指生产者向kafka发送5个包request后,都没有回应时,则停止发送变成阻塞状态。
这种设计在同步发送过程没有作用的,因为同步过程是每请求返回的。

SEND_BUFFER_CONFIG 发送缓冲区配置、RECEIVE_BUFFER_CONFIG 接收缓冲区配置,这两个就是IO层的缓冲区配置了,不同的操作系统可能不一样。设置成-1,代表默认使用系统分配大小。
pp.setProperty(ProducerConfig.SEND_BUFFER_CONFIG , String.valueOf(32 * 1024)); pp.setProperty(ProducerConfig.RECEIVE_BUFFER_CONFIG , String.valueOf(32 * 1024));
查看内核默认配置:

到此Producer整个数据发送流程机制就清楚了,Ack的设定涉及到Broker数据同步和Consumer消费状态,这块单独再进行分析。
总结一下:
1、Producer的实现是由Main线程和Sender线程组合完成的。
Main线程核心完成了数据的输入、Producer初始化和数据append到RecordAccumulator工作,具体的元数据的更新、数据发送等IO操作都是都Sender线程完成。
Sender线程工作模式是中间件中比较常见的响应式编程模式。其在Loop过程中进行客户端连接、元数据更新、数据打包发送等工作。
2、Kakfa中IO操作封装了Java中Nio的实现(Selector),底层是多路复用器的实现,而不是netty。
3、Producer发送数据过程并不是简单的一条一条数据发送,其内部封装RecordAccumulator、Batche、Request包,可以实现按批次发送数据,减少IO次数。同时结合FilghtRequest飞行中请求大小限制,确保kafka未正常响应时,抛出异常防止数据丢失。在开发过程中,可以通过调整参数,来达到优化目的。