图解直接映射(Direct mapped)、全相联(Fully-associative)和组相联(Set-associative)cache
- 一,直接映射缓存(Direct mapped caches)
- 1.1 直接映射示例
- 1.2 直接映射原理
- 1.3 cache颠簸(cache thrashing)
- 二,全相联映射(Fully-associative)
- 2.1 全相联映射示例
- 2.2 全相联映射原理
- 三,组相联映射(Set associative caches)
- 3.1 组相联映射示例
- 3.2 组相联映射原理
- 四,直接映射、全相联和组相联的优缺点以及应用范围
- 4.1 直接映射优缺点
- 4.2 全相联映射优缺点
- 4.3 组相联映射优缺点
- 五, 参考文档
一,直接映射缓存(Direct mapped caches)
在介绍直接映射、全相联和组相联映射之前,我们以停车场停车作为例子,先把这三种结构的特点简单地概括出来,便于读者了解。
- 停车场 - cache
- 停车 - linefill
- 取车 - read cache line
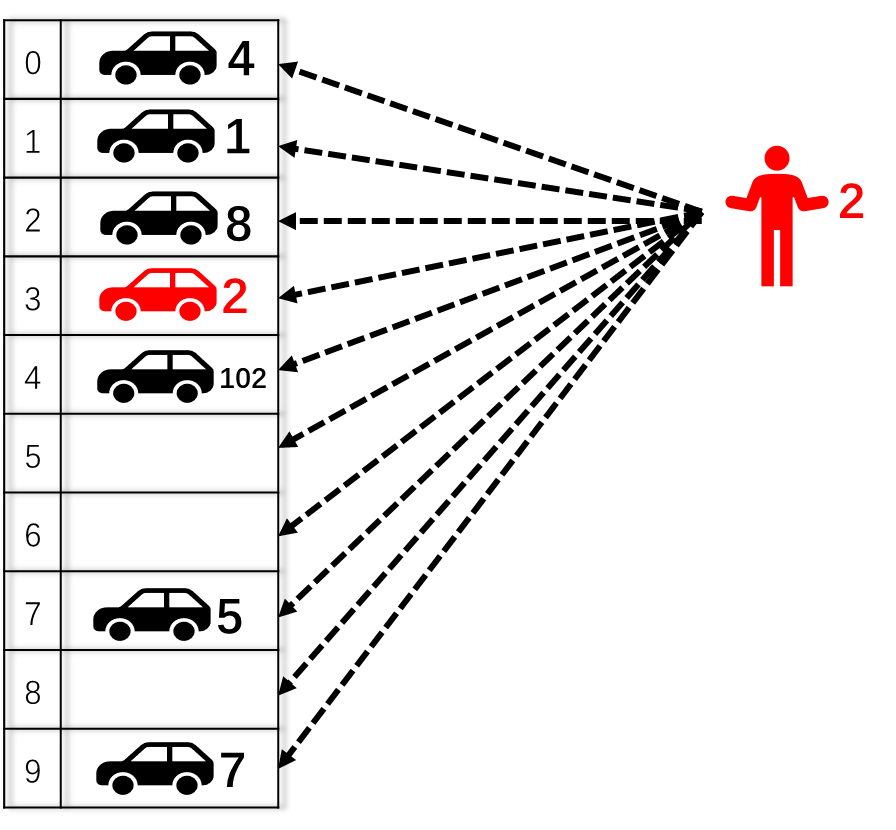
1.1 直接映射示例
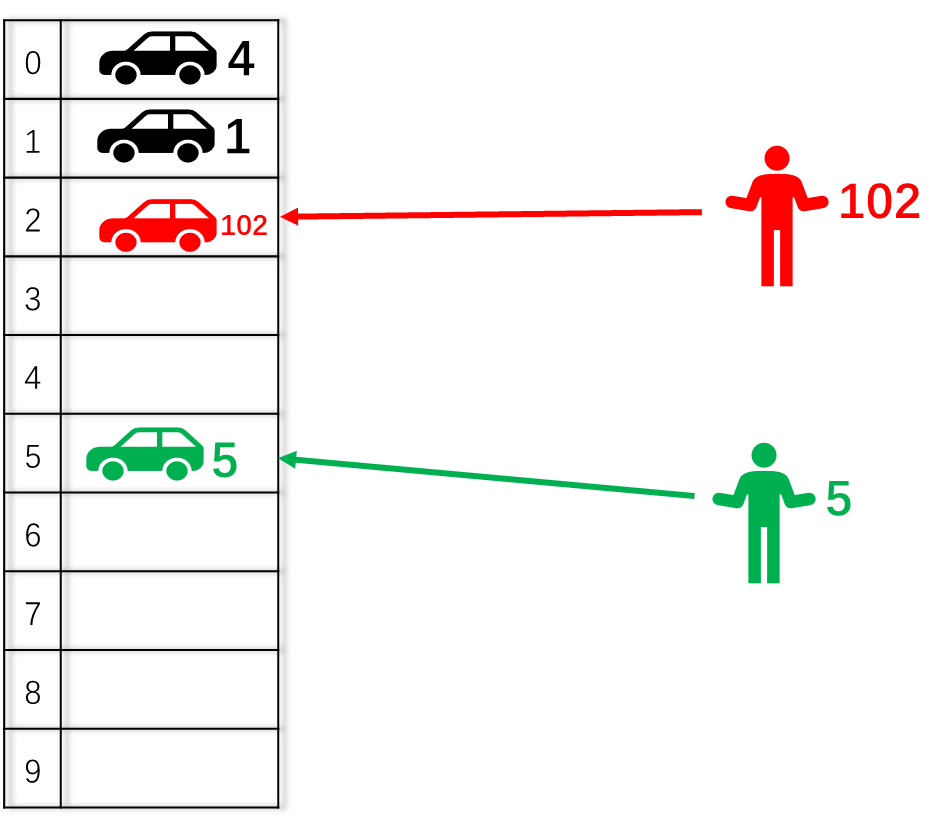
假如所有人的车都被赋予了一个独一无二的车牌号A(A=0,1,2,…,100,101,…),现在有一个共N=10个车位的停车场,每个车位号从0开始依次递增。现在规定车牌号为A的车子只能停在 停车位 n = A % N = A%10 的位置。如下图所示,车牌号为2的车子停在2号车位,车牌号为5的车子停在5号车位。按照这种规则,如果又来了一辆车牌号为102的车子,即使其他车位上还有空位,102号车子也只能停2号车位,如果2号车位已经有2号车占了,按照直接映射的规则,102车(newer)会把2号车(older)给驱逐(evict)出去。
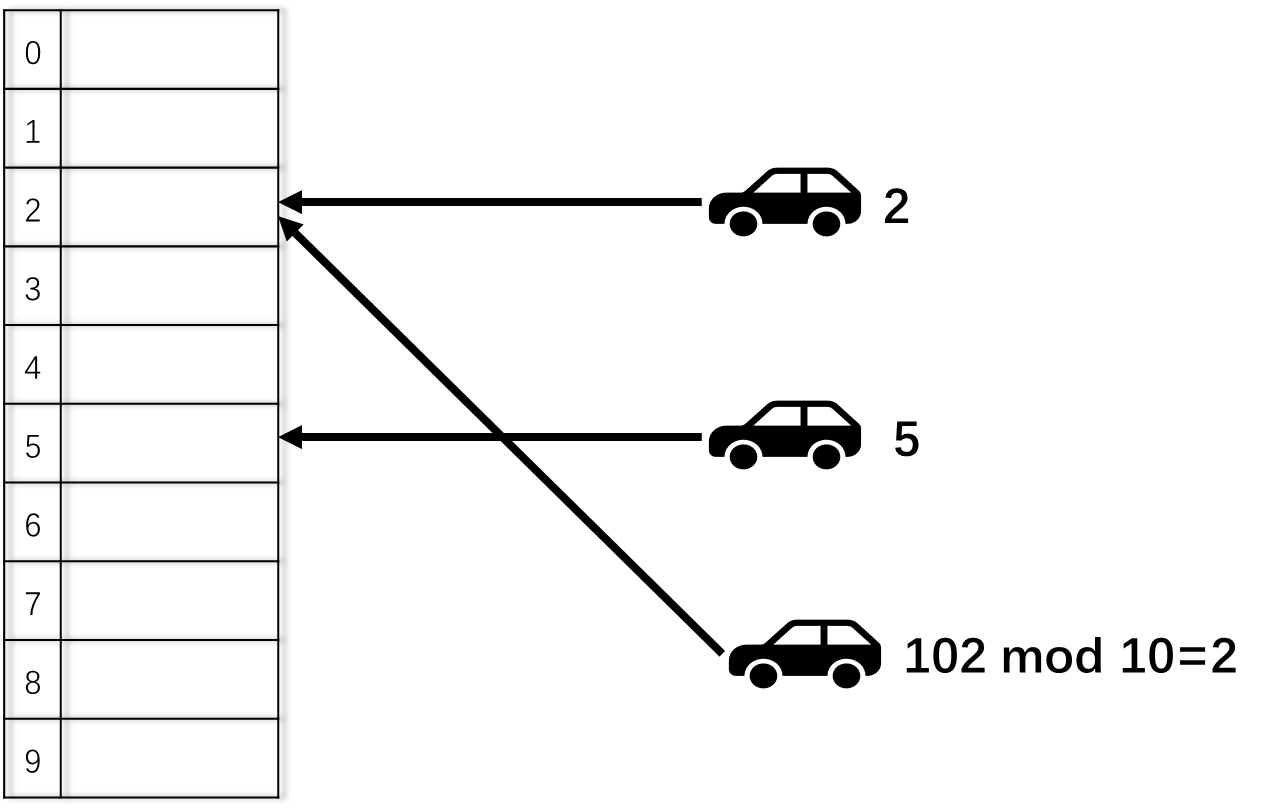
上图描述了按照直接映射规则停车的过程,下图则是车主取车的过程(也就是从cache 中读取数据)。
假设我是102号车主,通过简单计算停车位 n =102%10 =2,很容易知道我的车子停在2号车位。
总结:直接映射规则下的停车场,每个车位都与车牌号直接对应,即使停车场还有大量空位,2号车和102号车也只能停2号车位。并按照后来者居上的原则,102号车会把2号车给驱逐出去,如果又来一辆52号车,102号车也会被52号车挤出去。所以驱逐现象(eviction)会频繁发生。
直接映射其优势在于车主很容易就知道自己的车子停在哪个车位,不用进行look-up来确认是否 miss还是hit。
1.2 直接映射原理
在众多的cache实现方式中,直接映射方式是最简单的。主存中的每个地址都能在cache中找到对应的cache line,不过主存空间是远远大于cache的存储空间的,所以它必须按照上述直接映射停车场的规则:n= A % N,将所有满足n= A % N的地址A放入cache下边为n的cache line。如下图所示的cahce,N=4,一个cache line大小为4个word,主存地址为0x0、0x40、0x80、…、的数据都将放在该cache的第0个cache line,以此类推。
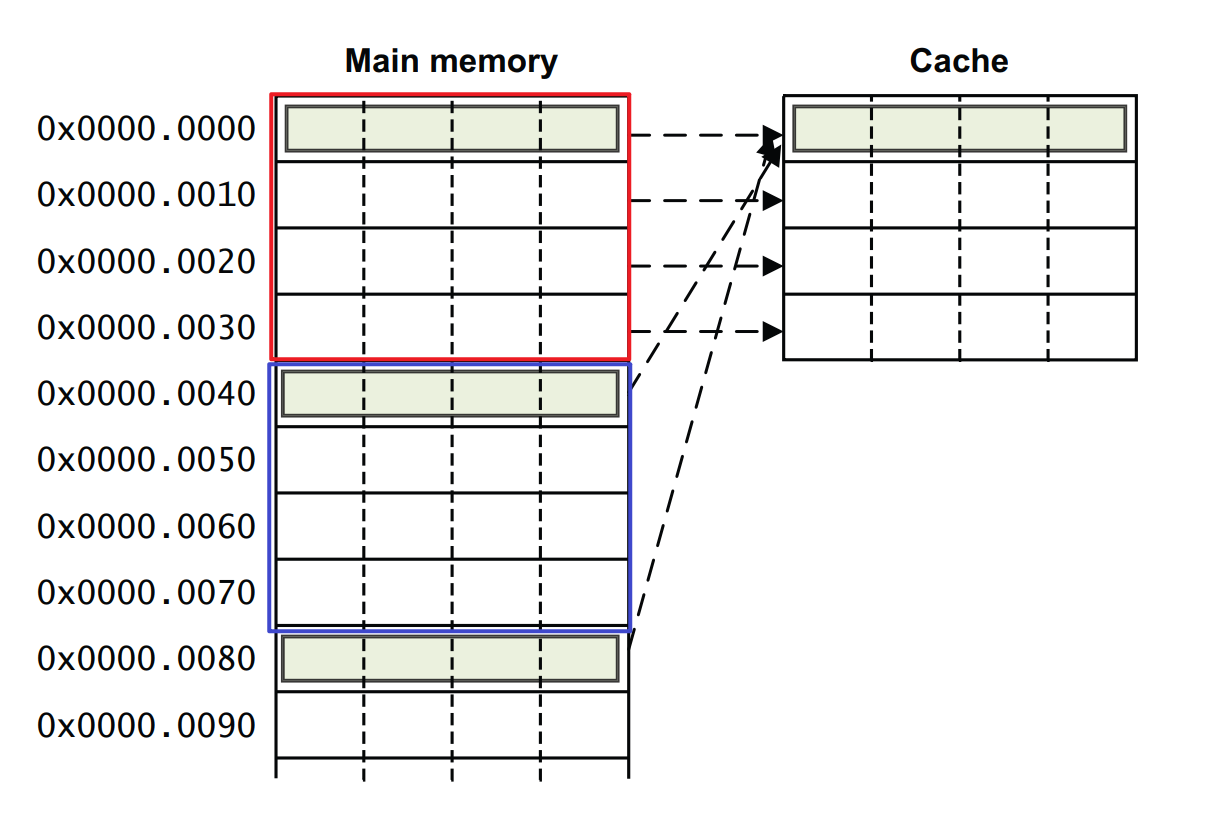
我们可以推算出一个主存的地址如何被划分成 cache 地址,如下图所示,
- 由于该cache只有4个cache line,所以只需2个bit即可描述cache line的index(0b00 \ 0b01 \ 0b10 \ 0b11),这里我们使用地址的bits [5:4]。
- 一个cache line有4个word,也只需2个bit即可描述每个word的具体位置(0b00 \ 0b01 \ 0b10 \ 0b11),这里我们使用地址的[3:2]。
- 地址的bits [31:6]我们用作Tag 信息,即告诉cache controler该地址来自主存的何处,用于判断hit or miss。

当CPU读写一个地址时,cache controler会将该地址按照上图结构划分,并且进行如下操作:
- 首先抽取该地址的index位,直接去找cache中对应index的cache line。
- 然后抽取该地址的tag信息,如果与当前cache line里的tag一致,并且该cache line的valid bit为1(该cache line里的数据有效),即说明发生了 hit。如果valid bit为1,但是tag信息不一致,说明当前cache line保存的数据是其他地址的,接着需要将当前cache line里的数据驱逐到下一级内存中,并将新的地址上的数据填充进来。
- 如果是hit,接着把该地址的Line偏移量,可能还有bytes偏移量取出,在对应的cache line中提取数据。
**所以内存中所有地址的bits [5:4] 相同的地址,都会映射到同一个位置的cache line。**但是在某个时刻,同一个cache line只能存放其中一个地址的数据,就像车位上某个时刻只能停一辆车一样。
1.3 cache颠簸(cache thrashing)
直接映射的一大副作用就是cache颠簸(cache thrashing),下面笔者用一个示例来解释这种现象。
有如下函数:
void add_array(int *data1, int *data2, int *result, int size)
{
int i;
for (i=0 ; i<size ; i++) {
result[i] = data1[i] + data2[i];
}
}
功能很简单,传入三个int类型指针:int *data1, int *data2, int *result,并在有限的size个循环内求和:result[i] = data1[i] + data2[i]。
假如传入如下参数:
add_array(0x40, 0x80, 0x00, 16);
即:
int *data1 = 0x40
int *data2 = 0x80
int *result = 0x00
int size = 16
在一个直接映射cache实现下会发生什么呢,完成求和运算result[i] = data1[i] + data2[i],会经过如下步骤:
- 假设当前 i=0, 首先会读取data1[0],也就是 0x40上的数据,先发生 read miss,然后linefill,将0x40 到0x4F一个cache line大小的数据填充到 cache的第0行。

- 首先会读取data2[0],也就是 0x80上的数据,地址0x80按照规则,其数据也将放在第0个cache line。先发生 read miss,由于第0行已经存放了0x40的有效数据,所以会先进行evict,然后再把0x80上的数据替换进来:

- 最后进行求和操作data1[0] + data2[0],并将结果保存在result[0],也就是地址0x00,0x00其数据也将放在第0个cache line。先发生 write miss,由于第0行已经存放了0x80的有效数据,所以还会先进行evict,然后再把求和结果0x00上的数据写进cache line。

我们可以发现,仅仅是在一个求和result[i] = data1[i] + data2[i]循环中,就发生了2次eviction。cache里同一个cache line里的数据经常被写入写出(linefill and evict),这就是cache thrashing。这样的现象会严重影响系统的性能,因此在ARM系列处理器中,直接映射类型的主缓存基本上没有,但是可以在一些,比如ARM1136 处理器的分支目标地址缓存中看到直接映射缓存。
二,全相联映射(Fully-associative)
2.1 全相联映射示例
全相联映射规则下的停车场类似与现实生活中的停车场。如下图所示,任意车牌号的车可以停任何车位,有空位就可以停。
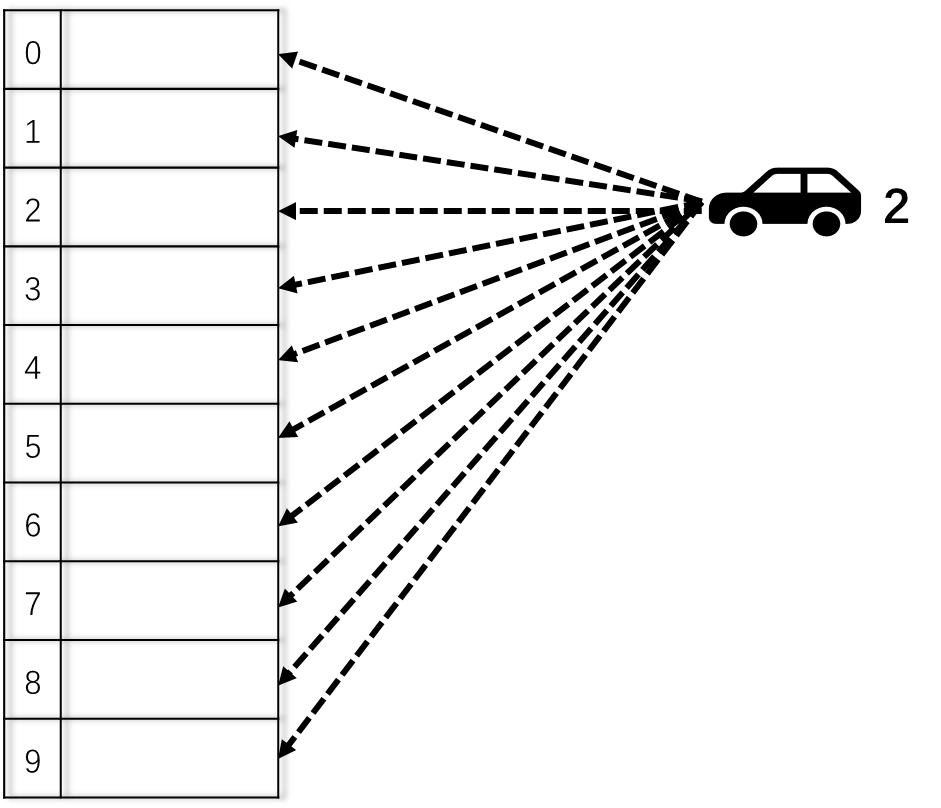
假设当前车位0,1,2都有车子占了,2号车子来了,它会按照一定的策略(replacement policy)来找空车位,本示例中是按照顺序查找。当它发现3号车位是空的时候,就把车子进去。102号车也是如此,停在了4号车位。
问题随之而来,当车主想要取车时,并不知道自己的车子停在了哪个车位。在最坏的情况下,需要遍历整个停车场(比较9次)才能找到自己的车。
总结: 全相联映射规则停车场的优势在于停车方便,车位利用率高,只要有空车位就能停进去。缺点是取车时比较困难,有可能需要遍历整个停车场才能找到自己的车。
2.2 全相联映射原理
主存中的任意一个地址可被映射进cache中的任意cache line,这就是全相联映射。正如上面的全相联映射停车场一样,虽然cache的利用率提高了,但是CPU 读写一个地址时,cache controler需要进行cache look-up才能知道是否发生hit 或者miss。在最坏的情况下,需要遍历整个cache,逐一比较才能得出是否hit的结论。

三,组相联映射(Set associative caches)
3.1 组相联映射示例
直接映射和全相联映射其实很好理解,铺垫了这么久其实是为了让同学们更加深刻地理解组相联映射的工作原理。直接映射是找车方便,全相联映射是停车方便。而组相联映射正是直接映射和全相联映射的组合解决方案。如下图所示,为一个组相联映射的停车场示意图。组相联映射有set 和way的概念,我们先简单理解为set就是行,way就是列。
组相联映射的停车规则如下:
- 停车时先选行,再选列。
- 行号n = 车牌号A % 停车场总行数 N。(直接映射规则)
- 确定了行号n后,车子可以停在n行的任意一列。(全相联映射规则)
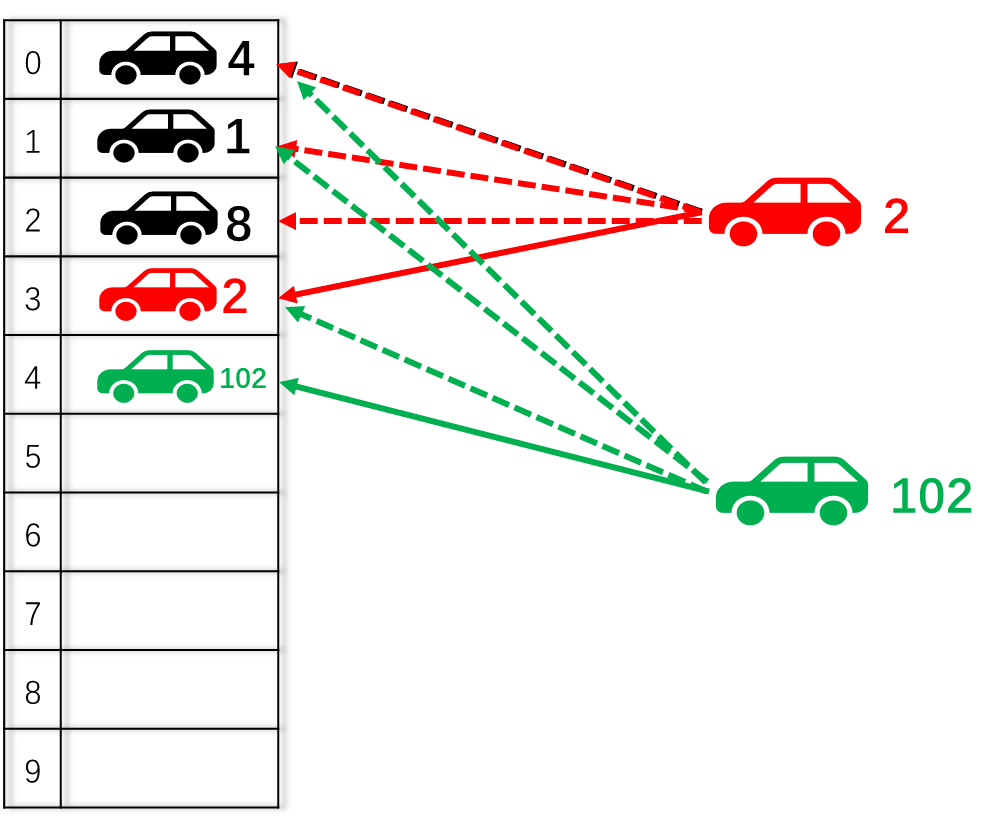
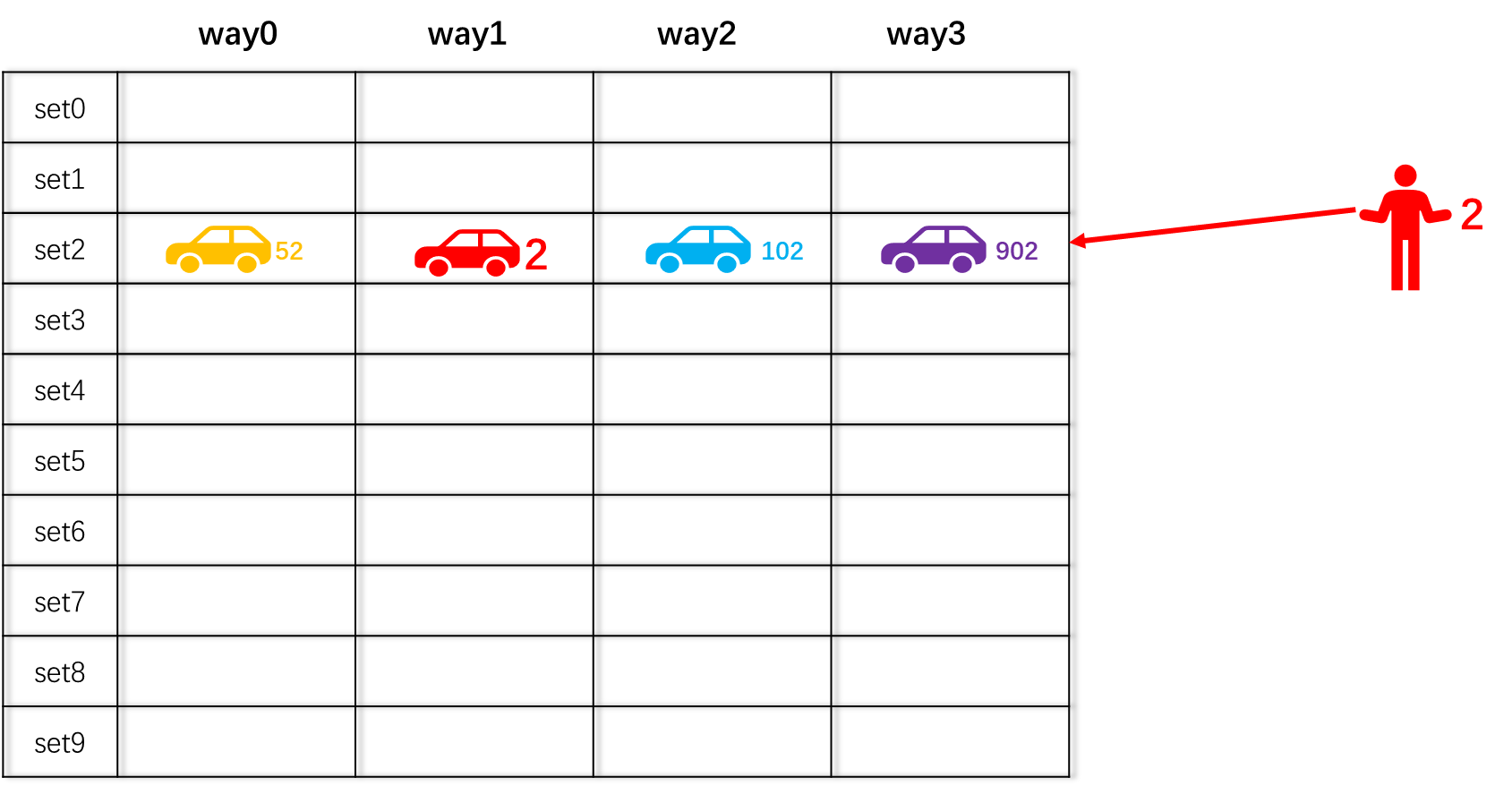
下图中,车牌号为2的车子只能停在set2,但是在set2里,可以任意选择一个way,即way0,way1,way2,way3中只要有空位又可以停。同理,车牌号为5的车子也只能停在set5。
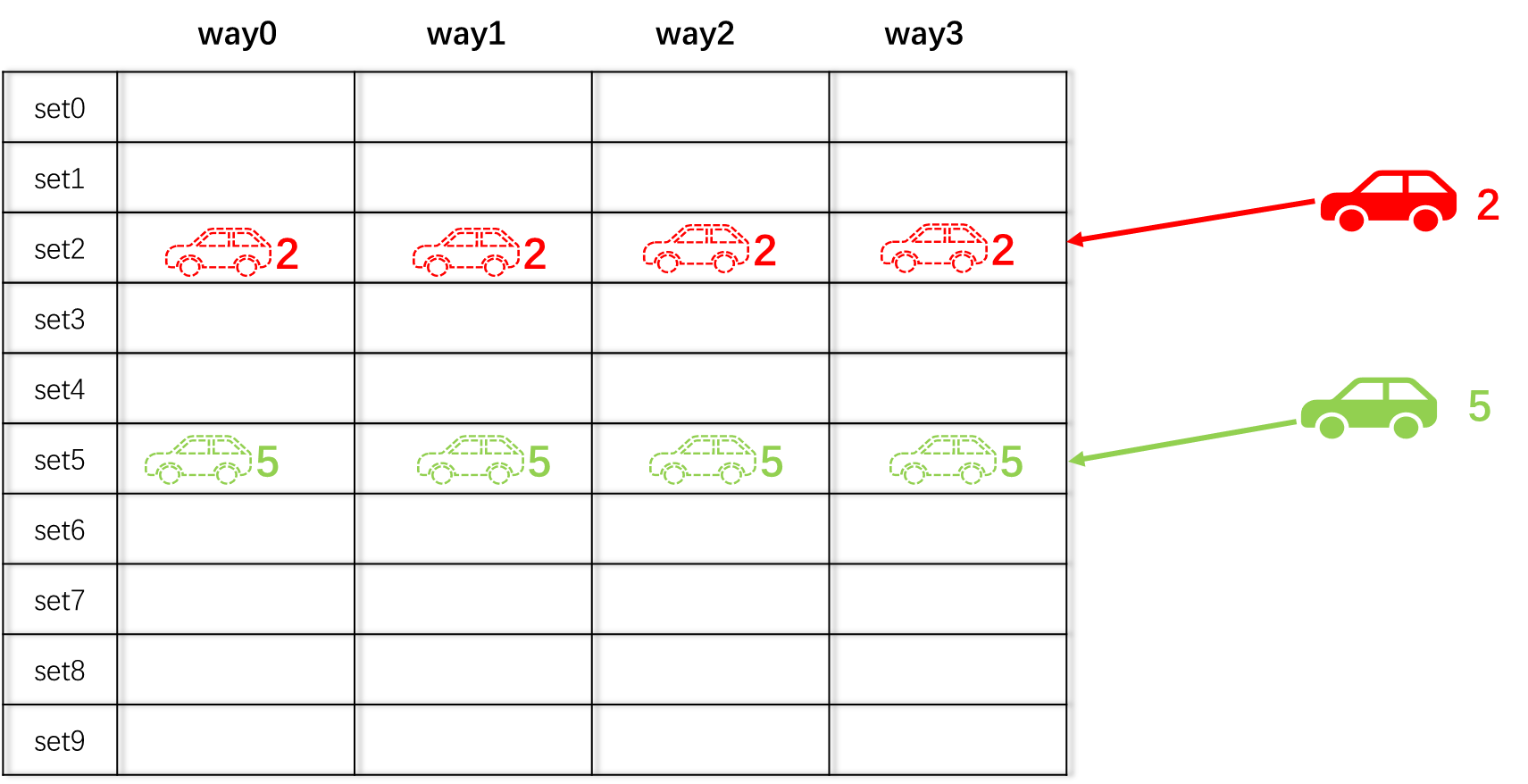
当2号车停在了set2+way1的位置,102号车按照规则必须停在set2,所以102号车可以停在way0、way2和way3中的任意位置。
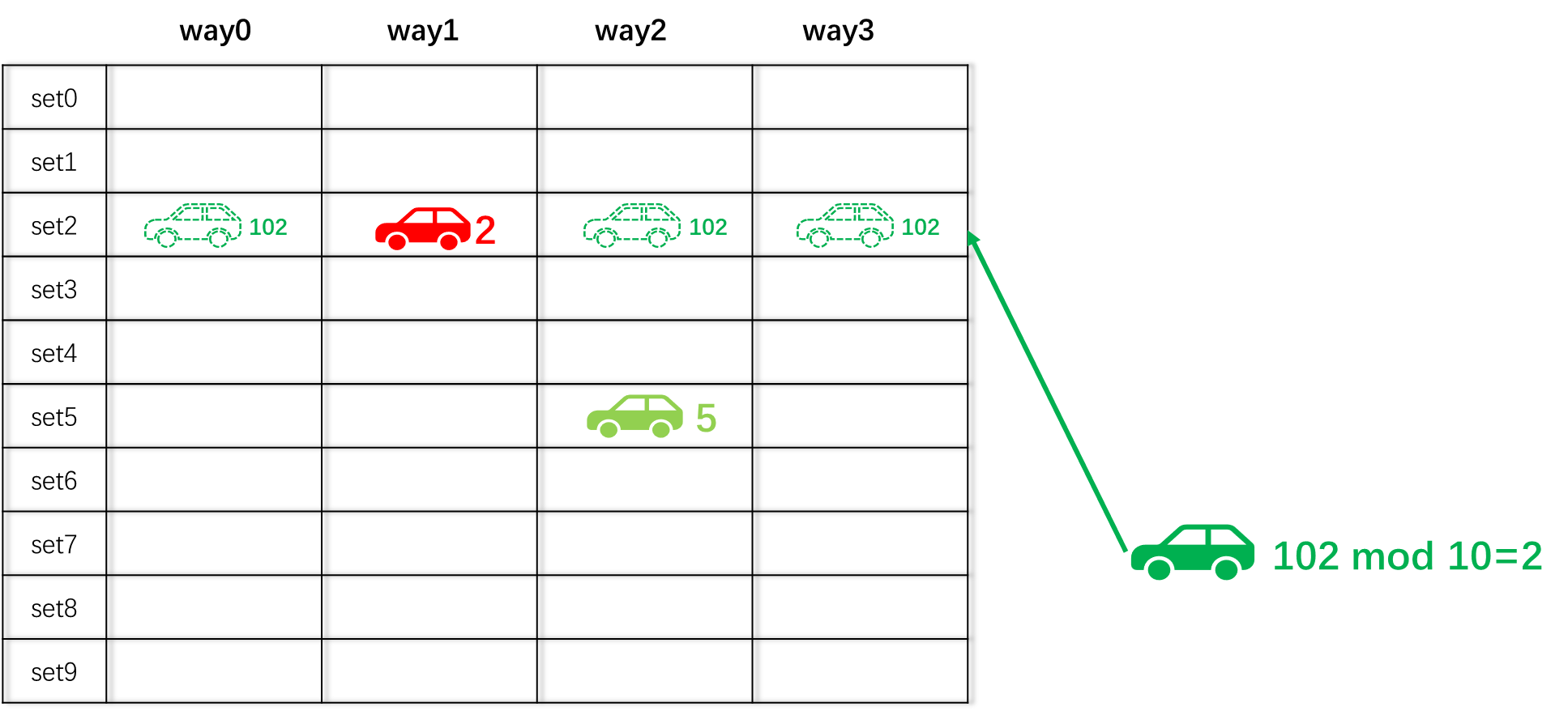
不同于直接映射的停车场,同一个set中甚至可以把所有way都填满,才会发生驱逐现象。如下图所示,72号车会根据替换策略,随机选择一个way,将这个way上的车子驱逐出去,然后停进来。
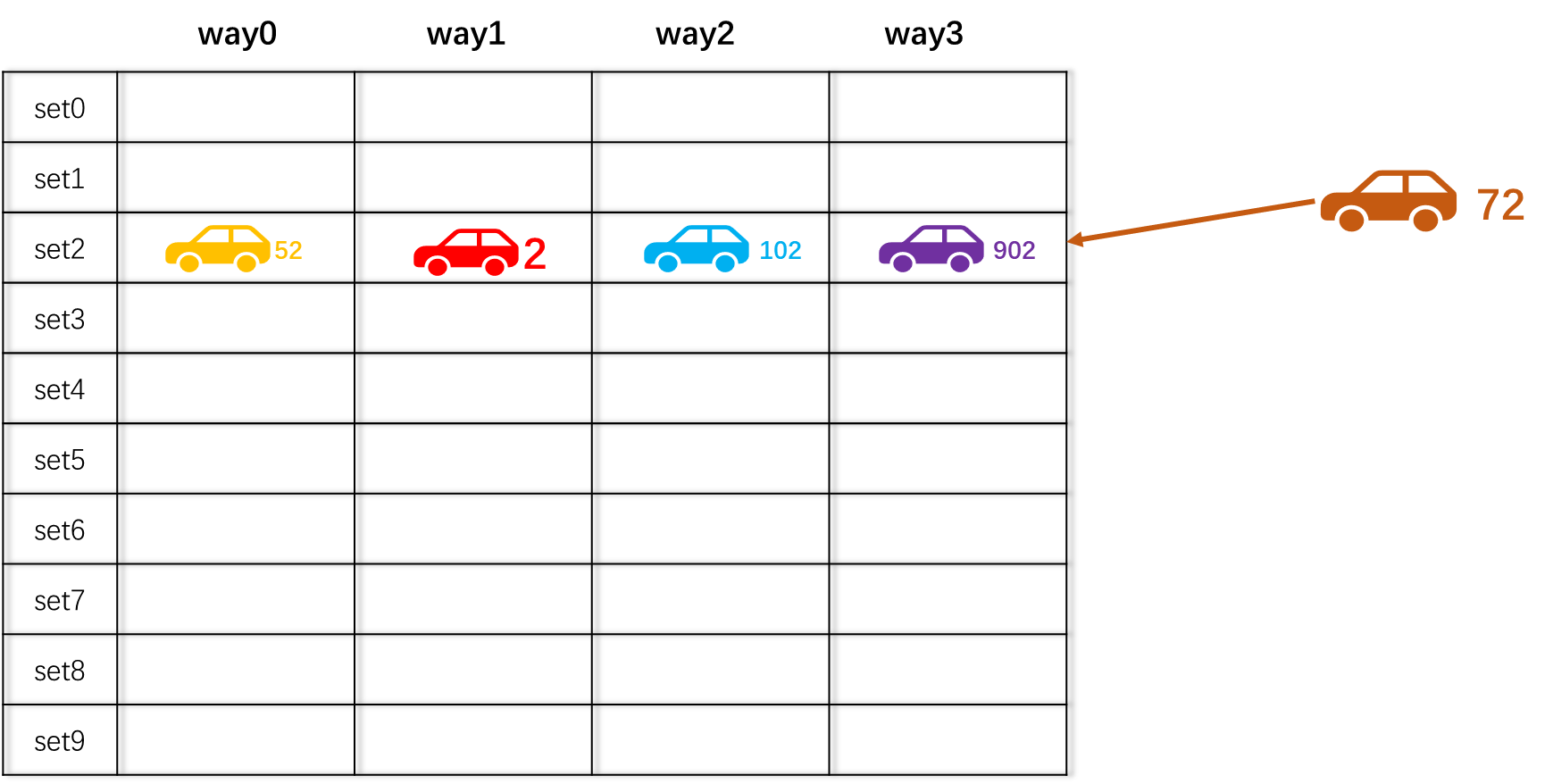
当要找车时,2号车的车主,根据直接映射规则直接去set2里找,虽然他不知道车子在哪个way中,但是即使是最坏的情况,车主也只需比较4次(停车场的列数)即可发现自己的2号车在不在当前停车场(hit 或者miss)。
3.2 组相联映射原理
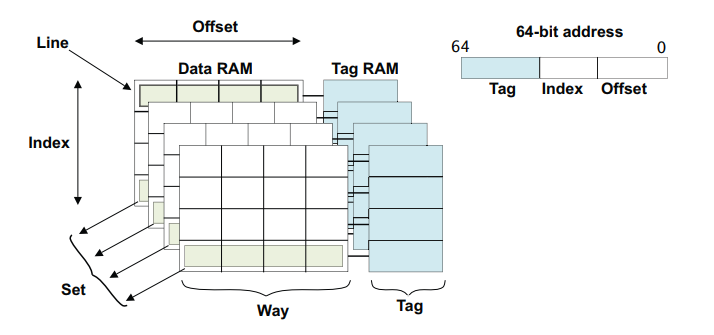
如下图所示,为一个组相联cache的结构,其中有三个概念需要理解:
- way: 组相联cache 将cache分成几个大小相等的几片,每一片称为一个way,下图为一个 4-way的cache。
- index:cache 的index其实就是cache line的行号。
- set:index相同的cache line的集合称为一个set。比如way0、way1、way2和way3中index等于0的cache line称为set0。
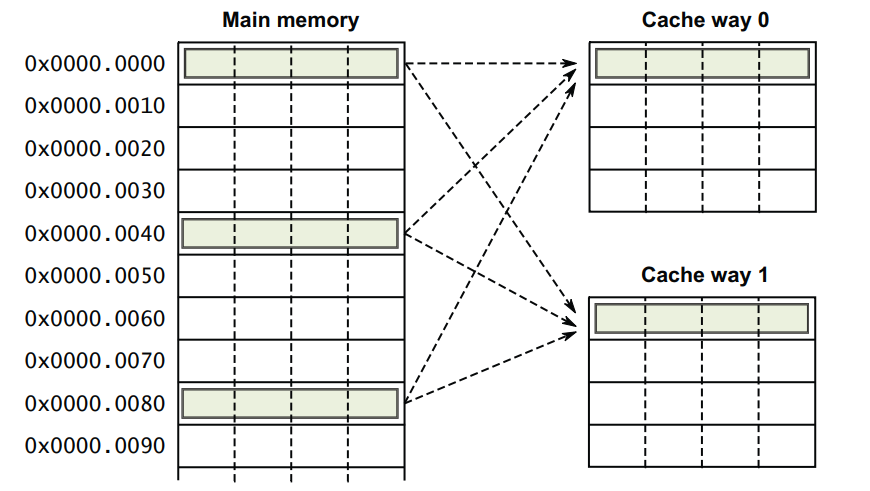
上文组相联映射停车场示例中提到过,组相联映射实际上是直接映射与全相联映射的组合实现。也需要将一个地址分成如下三部分,其中地址的index部分就是该地址在cache中所在的set 号。主存中index相同的地址将映射到同一个set(直接映射),但是一个set内有多个位于不同way的cache line,地址上的数据可以放入任意一个way中的cache line(全相联映射)。

如下图所示为一个2 way的cache结构。假设主存中地址 0x00、0x40、0x80的index都为0,按照组相联映射规则,0x00、0x40、0x80上的数据必须要存放在set0,但是可以在way0和way1中任意选择:
四,直接映射、全相联和组相联的优缺点以及应用范围
4.1 直接映射优缺点
- 优点: 硬件实现简单,成本低.
- 缺点: 灵活性差。每个主存块只有一个固定的行可以存放,因此即便cache中有大量空闲cache line可用,某个cache line上的data仍可能被替换出去。如果cache容量比较小,则非常容易发生冲突,频繁替换(cache trashing),效率大大降低。
- 适用范围:直接映射方式一般用于大容量的cache中。
4.2 全相联映射优缺点
- 优点: 全相联映射方式比较灵活,主存的地址可以映射到Cache的任一cache line中,Cache的利用率高,cache line冲突概率低。
- 缺点: 硬件成本高,Cache比较电路的设计和实现比较困难。
- 适用范围:只适合于小容量Cache。
4.3 组相联映射优缺点
- 优点:cache line的冲突概率比较低,比较的硬件电路比全相联方式简单些,而且空间利用率比直接映射方式要高。
- 缺点:实现难度和造价要比直接映射方式高。
- 适用范围:绝大部分cache都采用这种折中方案。
五, 参考文档
cache地址映射,全相连、直接、组相联
主存到Cache直接映射、全相联映射和组相联映射



![MongoDB【部署 02】mongodb使用配置文件启动、添加为系统服务及自启动(一个报错:[13436][NotMasterOrSecondary])](https://img-blog.csdnimg.cn/d9f243d80b764bb6b382c6393a64d803.jpeg#pic_center)