深度学习自然语言处理 原创
作者:wkk
为了改进LLM的推理能力,University of California联合Meta AI实验室提出将Contrastive Decoding应用于多种任务的LLM方法。实验表明,所提方法能有效改进LLM的推理能力。让我们走进论文一探究竟吧!
论文:Contrastive Decoding Improves Reasoning in Large Language Models
地址:https://arxiv.org/pdf/2309.09117.pdf
进NLP群—>加入NLP交流群
对比解码(Contrastive Decoding)
在走进论文之前首先介绍一下什么是对比解码,其是由Li等人在2022年提出的一种文本生成方法,具有简单、计算量小、训练自由等特点。它通过查找到最大化强模型和弱模型之间可能性差异的字符串来生成文本,从而产生更多且更高质量的文本。在对比解码中,弱模型可以是常规的贪心解码方法,如一些简单的采样方法,强模型可以是经过训练的大型语言模型。对比解码可以在很多推理任务上表现出色,包括算术推理和多项选择排名任务,可以提高语言模型的准确率。
本文创新点:探索对比解码在LLM上的应用。具体地,通过最大化专家模型和较弱的业余模型之间存在的可能性误差(如下图所示)来搜索字符串,避免了专家模型中的不良影响和贪婪解码会出现的采样误差问题。
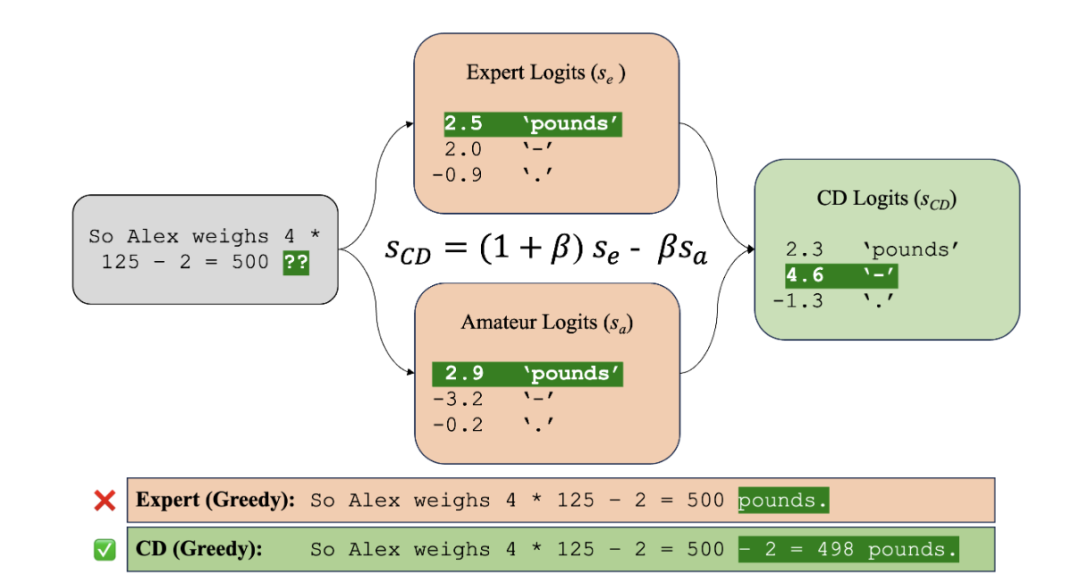
实验结论:通过在多种任务上的测试,本文证明了对比解码可以提高大型语言模型在推理和文本生成问题上的性能,这是第一种同时在推理和文本生成问题上实现最先进结果的生成算法。此外,还分析了对比解码的改进原因,并探讨了该方法在常识推理和事实检索方面的适用性。
实验
实验设置
模型:实验采用LLaMA家族的原始模型,其中专家模型为LLaMA-65B,业余模型为具有1.5B的LLaMA模型。此外,在消融实验中,本文还对FLAN-T5家族的模型进行实验分析。
解码参数:α=0.1,为原始论文中相同的超参数:专家模型分配的最大概率的比例,任何标记都分配了较低的概率被屏蔽掉。β=0.5是对应于业余惩罚强度的超参数。将前导 (1 + β) 系数包含在专家 logits 中,以将对比惩罚的强度与输出 logits 的预期尺度解耦,描述了用于采样的温度的对比权衡之间的对比权衡。
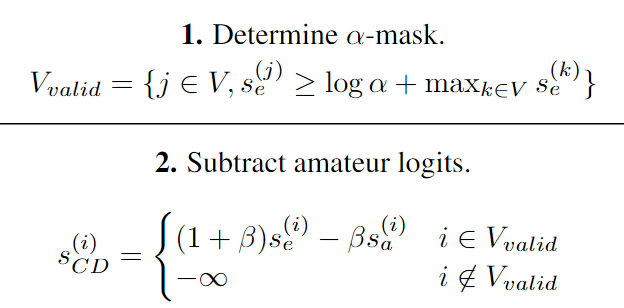
prompt:对于生成任务使用8-shot的CoT。
数据集:聚焦代数问题的AQuA、ASDiv、GSM8K、SVAMP和MATH数据集,针对常识推理的CommonsenseQA、StrategyQA数据集以及AI2 Reasoning Challenge、BooIQ、HellaSwag、MMLU、PIQA、SIQA和WinoGrande等基准数据集。
实验结果
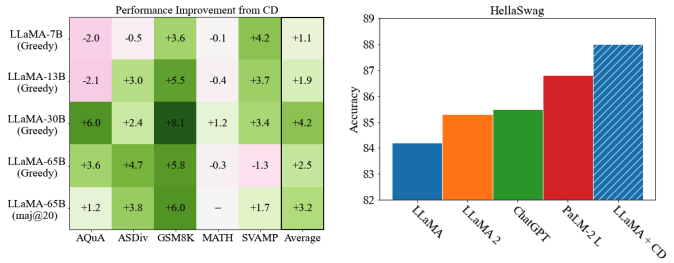
在GSM8K上的实验表明,β=0.5能获得更好的结果同时业余模型对于性能的提升可能大于专家模型。

对比解码往往有助于全面完成具有CoT提示的算术推理任务。其中一个例外是MATH数据集,它被证明对标准解码和对比解码都具有挑战性。作者推测因为对比解码放大了专家比业余模型学得更好的技能,所以它对远远超出专家模型的任务没有帮助。

在CommonsenseQA和StrategyQA数据集上实验发现对比解码会损害较小模型的性能。
对比解码的影响
本文还进行了一系列附加实验,研究表明,对比解码可以在大型语言模型中提高推理能力。在算术推理和多项选择排名任务上,包括LLaMA-65B这样的大型模型,都有普遍的改进,这表明对比解码可以使更大的模型受益。通过分析对比解码改进的原因。实证表明,与贪婪解码相比,对比解码从提示中复制的表面层次较少,错过的推理步骤也较少。这一结果表明,对比解码通过减少模型分布中的短、重复或其他不良模式来起作用。
结论
使用对比解码(Contrastive Decoding)方法可以显著提高大型语言模型在一系列推理任务中的准确性,这种方法不仅在生成文本方面表现优异,还可以在推理问题方面超越当前现有的各种模型。同时,该方法能够减少模型分布中的短、重复或其他不良模式,从而提高模型的推理能力。然而,该方法在常识推理任务中表现良莠不齐,需要进一步研究和改进。总的来说,对比解码方法在改善语言模型的生成和推理能力上具有广泛的应用前景。
进NLP群—>加入NLP交流群