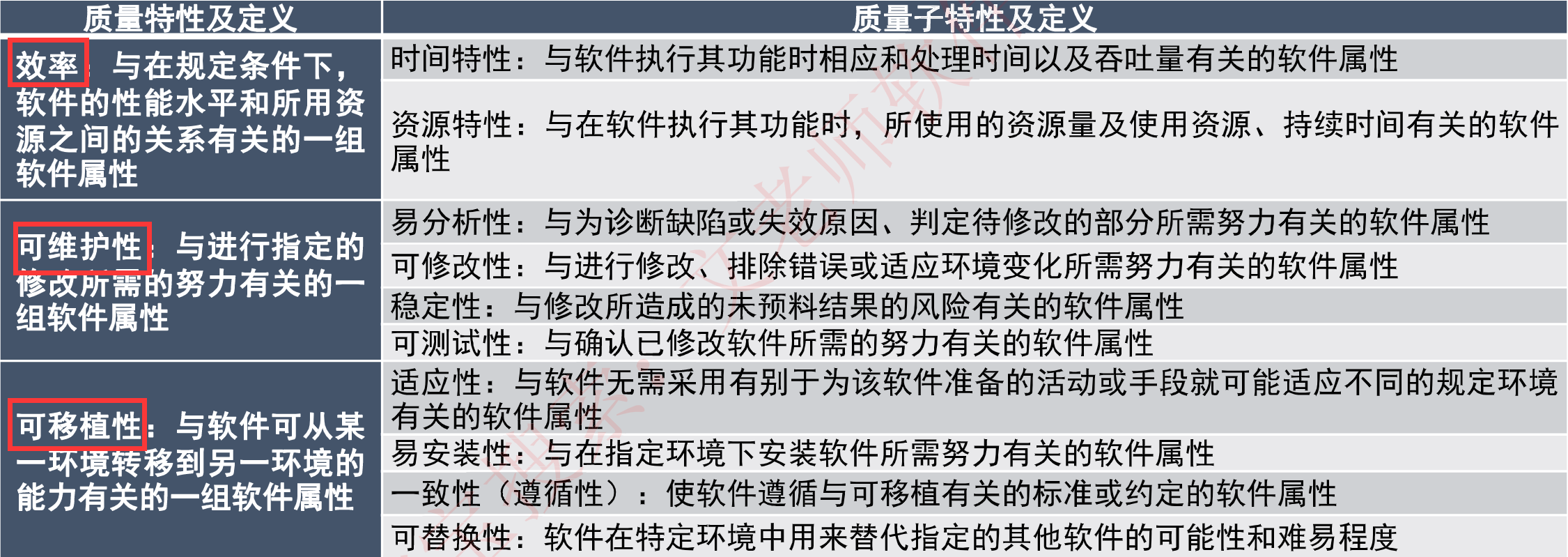
文章目录
- 1. 通过系统调用获取进程标示符(PID)
- 1.1 进程id(PID)
- 1.2 父进程id(PPID)
- 2. bash也是一个进程
- 3. 通过系统调用创建进程-fork初识
- 3.1 批量化注释
- 3.2 取消注释
- 3.3 fork创建子进程
- 3.4 fork的返回值
- 3.5 fork 之后通常要用 if 进行分流
- 3.6 父子进程代码共享,数据写时拷贝(实现相互独立)
- 3.7 如何理解fork两个返回值的问题
1. 通过系统调用获取进程标示符(PID)
上一篇文章我们了解了进程的概念,并学会了创建进程和查看进程,在查看进程的时候,我们重点了解了一个属性叫做PID,即进程标识符。
1.1 进程id(PID)
那我们能否单独获取到一个进程的PID呢?可以的:
我们可以通过一个系统调用来获取,这个系统调用叫做
getpid
我们可以通过man手册学习一下
getpid没有参数,直接调用即可获取(返回)当前进程的pid,返回值是pid_t类型,其实就是一个有符号整数类型

那我们来试一下:
首先给我们的源文件修改一下
保存退出
然后我们重新make,接着运行生成的可执行程序
就成功打印了PID是19490
另外我们也可以通过命令查看一下
没问题,就是19490

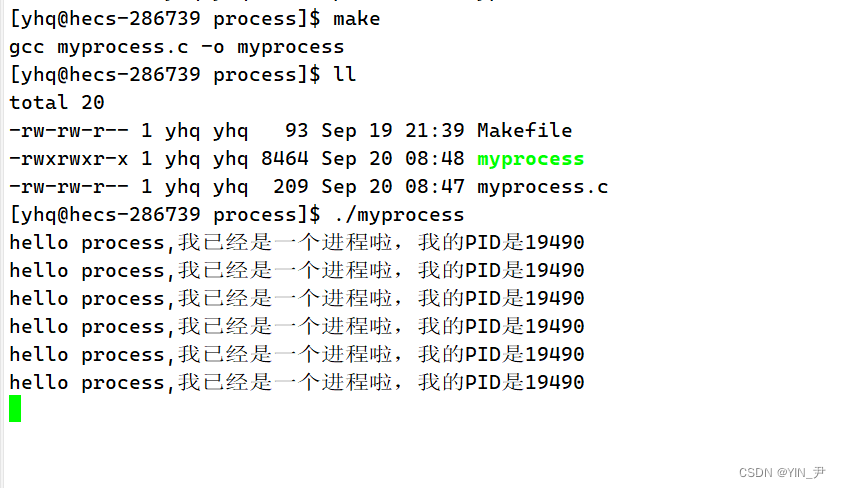

然后:
我把它终止掉,再反复多启动终止几次
我们发现,它每次的PID可能都是不同的,是会变化的,进程的PID是由操作系统维护的。

1.2 父进程id(PPID)
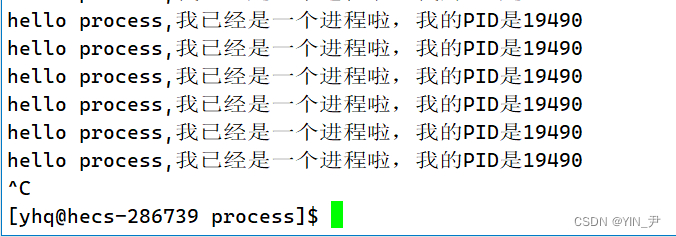
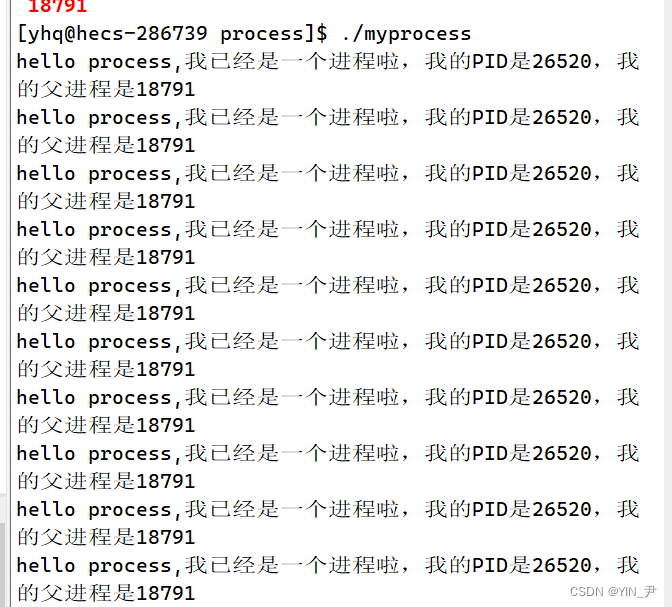
我们再来看一下这张图:
除了上面我们讨论的PID之外,前面还有一个PPID,这个是什么呢?
🆗,PPID,第一个P表示parent的意思,PPID代表当前进程的父进程的PID。
是的,进程也是有父子关系的。
那我们如何获取父进程的PID即PPID呢?
用另一个系统调用——getppid
我们来试一下:
重新make运行
然后我们再多运行几次
我们会发现当前进程的PID每次都是不一样的,但是其父进程的PID是一直不变的


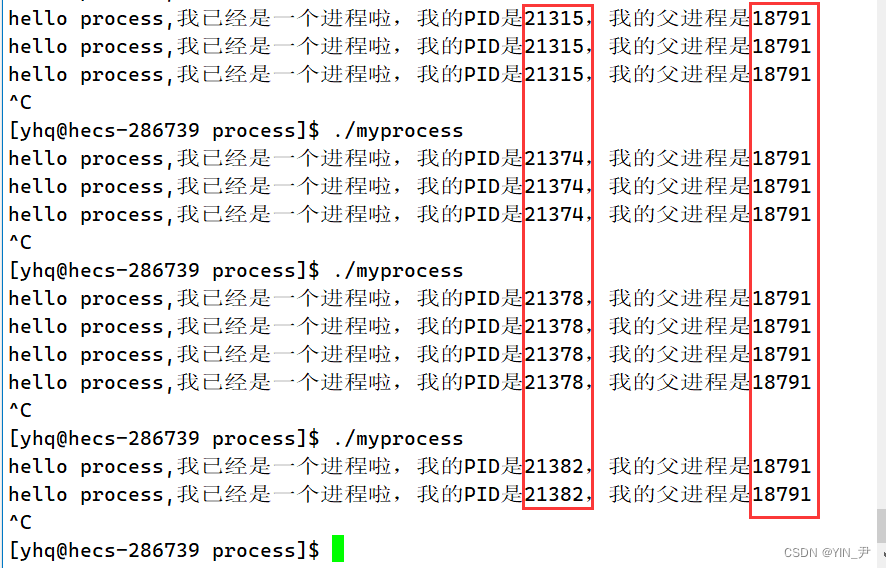
那它的父进程是谁呢,为什么PID一直不变呢?
那我们可以查一下:
上面父进程的PID是18791
我们看到PID为18791的对应的是-bash
那bash是啥?
是不是Linux上的命令行解释器啊,这个我们之前学过。

2. bash也是一个进程
所以,我们可以得出一些结论:
命令行解释器bash也是一个进程!
其次,我们发现上面每次运行起来进程的父进程都是bash,所以,结论2:
命令行启动的所有程序,最后变成进程其对应的父进程都是bash(也有特殊情况,我们目前先不考虑)。
至于如何做到得,我们后面再说。
那为什么bash启动的程序,最终生成的进程它们的父进程都是bash呢?
🆗,大家还记不记得之前在讲解shell的那篇文章里面,我们举了一个王婆说媒的例子( link)
那在文章最后,我们就提出了——shell执行命令时,是创建子进程去执行的
所以上面我们发现进程的父进程都是bash。
那它为什么要这样做呢?
原因很简单,因为bash怕我们自己写到程序有问题,有bug。
所以bash就创建子进程去执行来保证自己的安全。
就对应我们之前讲的王婆自己去给小帅说媒怕不成功影响了自己的名声,所以找实习生去说。
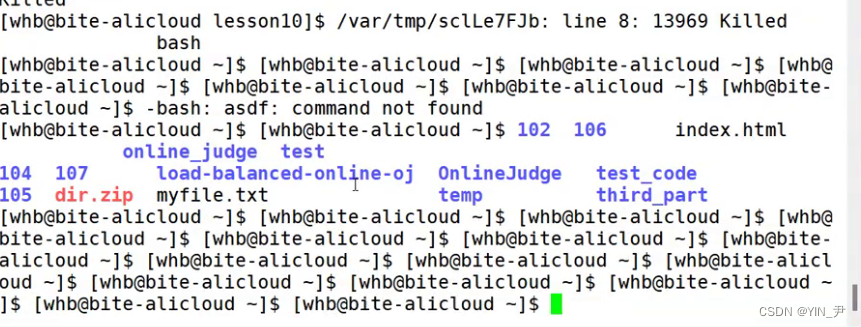
那既然bash也是一个进程,那我们能不能把它干掉呢?
我们知道一个进程运行的时候我们可以输入CTRL+c终止这个进程。
那除此之外,还有一个命令——kill -9 PID可以强制杀死进程或者说强制终止进程。
试一下
那我们把bashkill掉呢?
我们kill之后会发现bash就不能正常工作了
那出现这种情况的话我们把xshell关掉重新登陆就行了。

bash创建子进程去帮它执行命令,那下一个问题,如何创建子进程呢?
3. 通过系统调用创建进程-fork初识
经过之前的学习我们知道我们可以通过运行一个程序使之变成进程,那有没有其它产生新进程的方法呢?
有的,我们可以通过系统调用来创建进程。
这个系统调用叫做fork
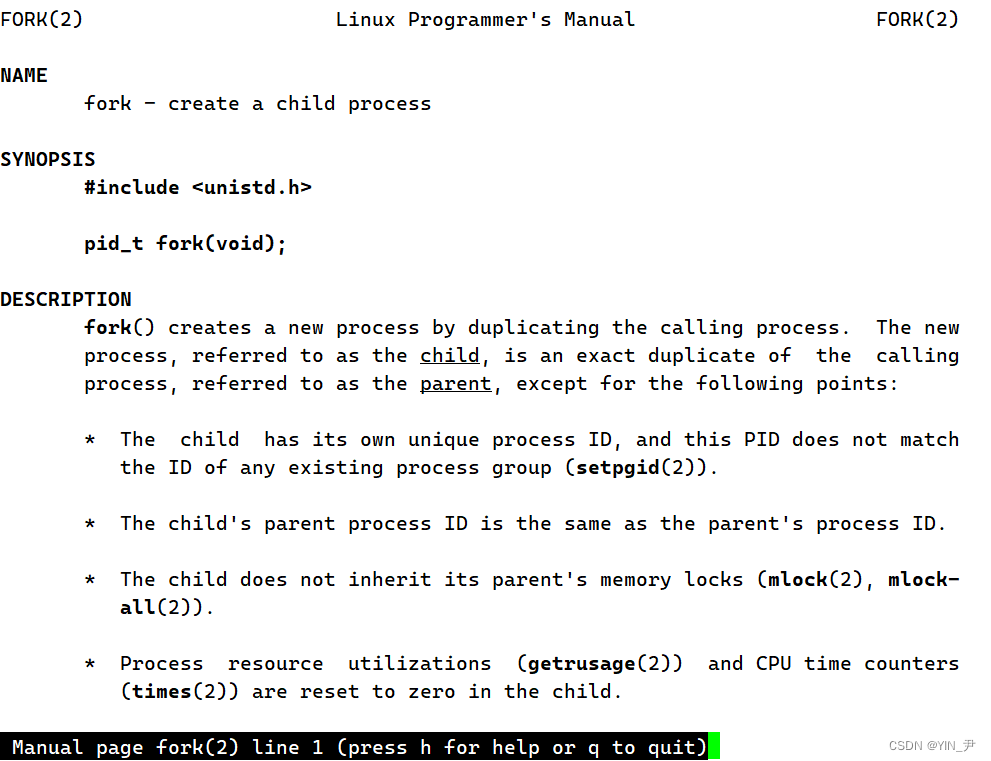
那我们先来学习一个fork怎么用:
man fork
它在当前进程的基础上创建一个新的子进程
3.1 批量化注释
那我们再重新写一段代码
把之前的注释掉,那这里再教大家一下如何批量化注释
怎么做呢?
我们用vim打开代码文件,进入之后默认在命令模式下,然后我们按CTRL+V
会看到下面显示一个V-BLOCK
然后我们按j就可以向下选中下面的行
选中完要注释的代码之后将输入切成大写
然后输入I
然后输入//注释第一行
接着按Esc
批量化注释就完成了

3.2 取消注释
那如何取消批量化注释呢?
首先还是CTRL+V(要在命令模式下)
然后按l,按一次选中一列,那我们这里按两次就可以了
接着再按j向下选择行
选好之后按d就可以取消注释

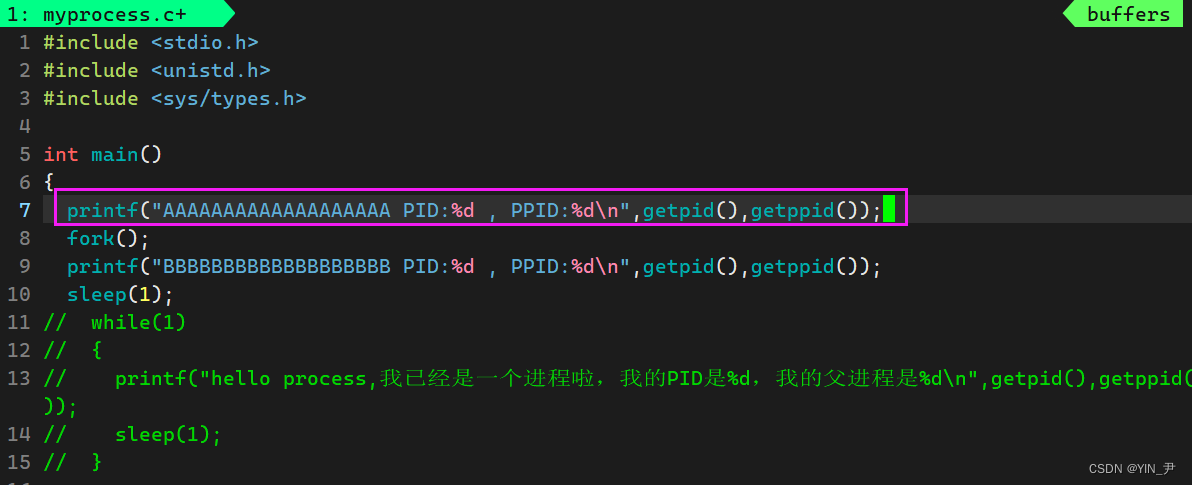
3.3 fork创建子进程
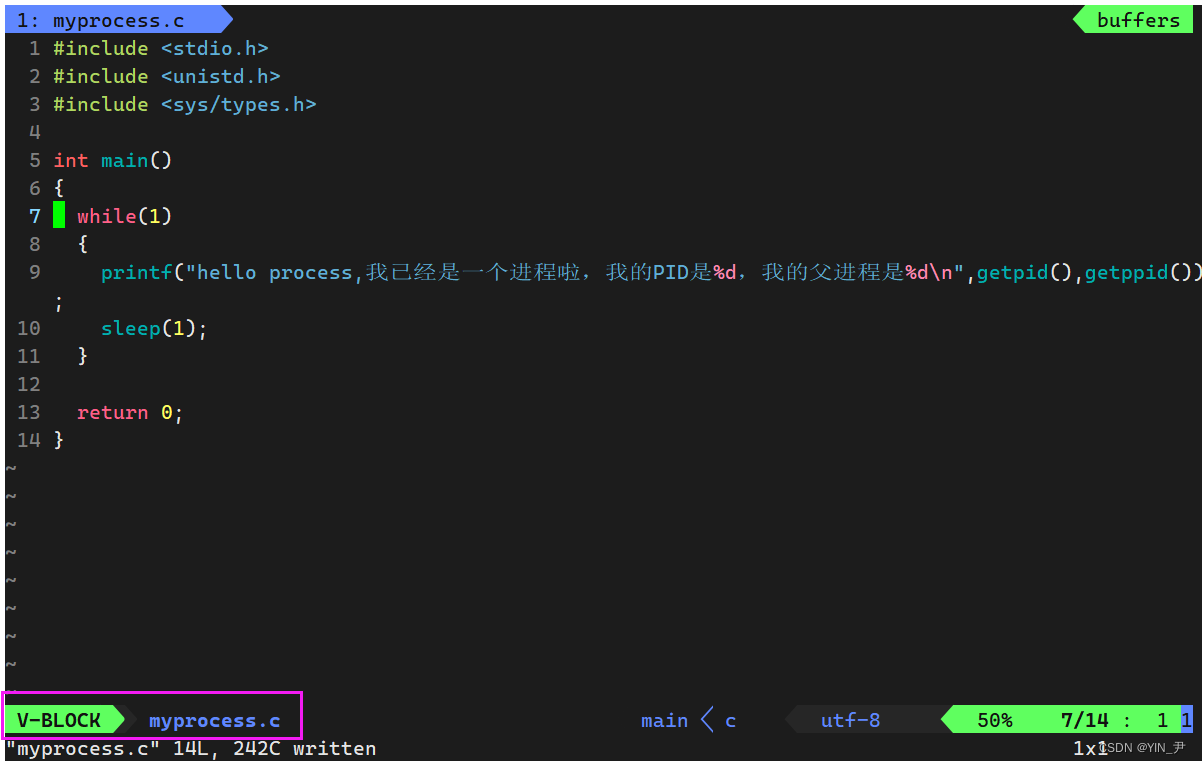
然后我们写一下新的代码:
我们来写这样一个代码
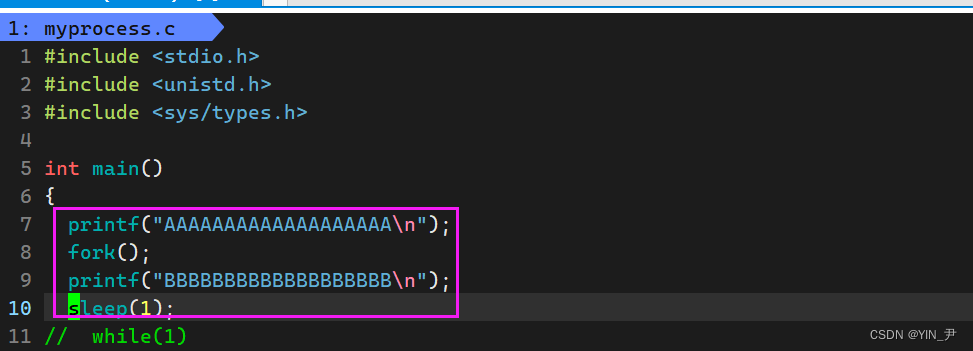
fork也没有参数,我们直接调
如果不加fork的话,那这个程序运行就是打印两个字符串,这没什么好说的,很简单
然后我们运行一下:
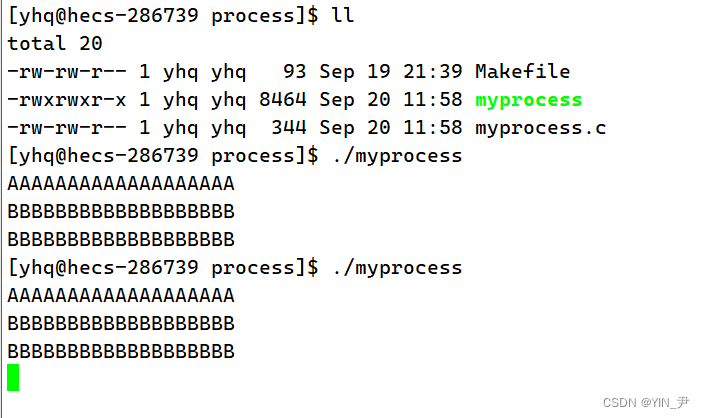
看一下结果,我们发现我们代码里的第二个字符串被打印了两次。
而我们的代码里只打印了一次,但是它前面有一个fork的调用
为什么会这样呢?
我们测试第二个打印应该被执行了两次,因为fork又创建了一个子进程,所以有两个进程,那就有两个执行流去执行第二个打印,所以打印了两次。
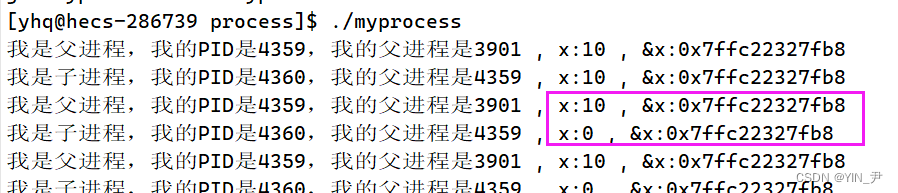
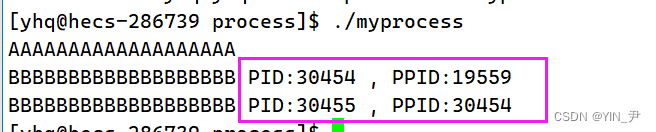
我们可以在打印一下当前进程和其父进程的PID观察一下:
我们发现这两个PID是不一样的。
那这也证明了两次执行第二个printf对应的不是一个进程,这里是有两个进程的
另外呢,我们还发现:
第一次打印对应的进程的PID刚好是第二次打印对应进程的PPID。
那这也证实了它们两个是父子进程关系,fork的作用就是创建当前进程的子进程,而PID为30455的这个进程就是被创建的子进程。

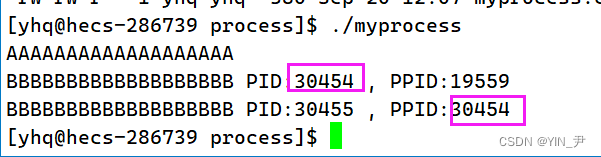
那大家再思考一下,如果我把第一个printf打印对应的PID也打印出来,它应该跟哪一个一样呢?
🆗,它肯定跟前面那个相同,因为执行第一个打印的时候还没有执行fork()创建子进程呢。
那当然这里19559对应的肯定就是bash了

那对上面做一个简单的总结:
如果没有fork的话,那程序运行起来就只有一个进程,这个进程是bash的子进程,那就只有一个执行流,所以两个printf就都只打印一次;但是现在第一个打印后面有一个fork,它去创建了一个当前进程的子进程,所以就变成两个执行流,第二个printf就被打印了两次。
3.4 fork的返回值
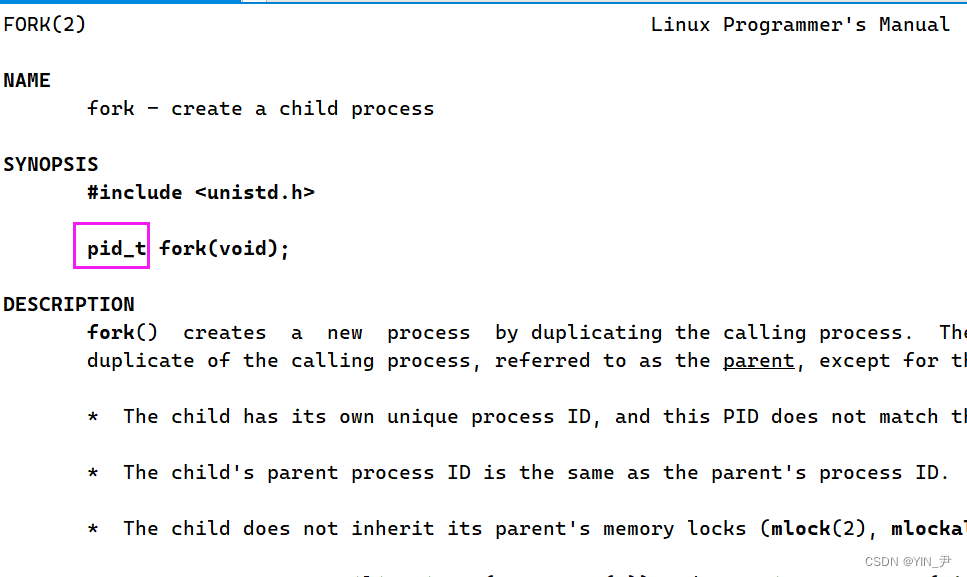
接下来我们再来研究一个东西——fork的返回值:
从man手册上看fork的返回值也是一个pid_t类型,这个我们上面说了,就是一个有符号整数类型
但是我们不能只看一个类型,我们来看一下他返回的到底是什么:
翻译一下就是:
fork成功的话,在父进程中返回子进程的PID,在子进程中返回0。失败的话,-1在父进程中返回,不会创建任何子进程,并且正确设置了errno(C语言中一个用于表示错误码的全局变量,Linux内核时C语言写的)。
也就是说fork成功的话,返回值会有两个。

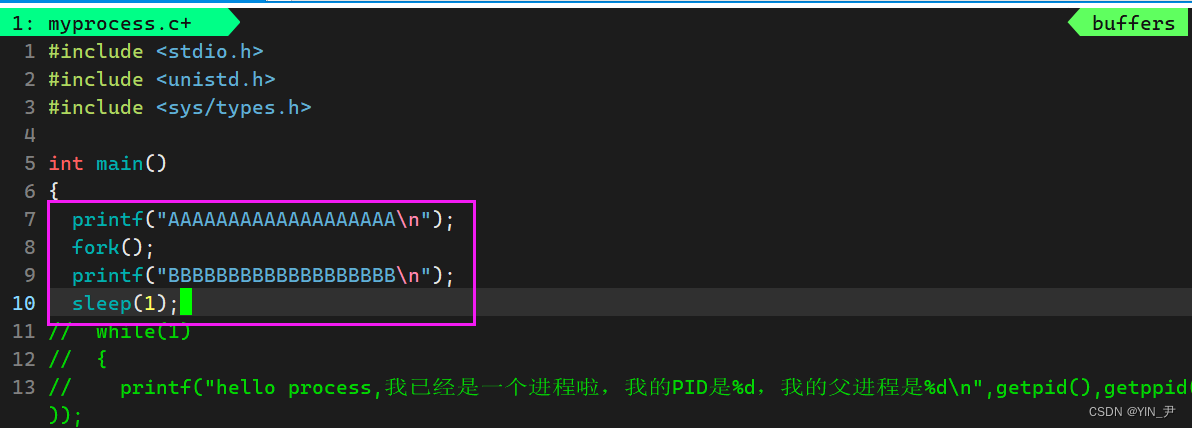
大家可能还不是特别理解,我们再写这样一个代码:
其实还是上面那个代码,我们接收一下fork的返回值保存到变量ret,并打印一下ret和&ret

我们运行一下看看结果:
大家先自己看一下这个结果。
然后这里再补充一下就是:
操作系统中,fork成功之后,父进程和子进程哪一个先运行完全是随机的,是不清楚的,因为fork成功创建子进程之后,父子进程谁先运行是取决于操作系统的调度策略
然后我们来分析一下这个结果:
那根据fork的返回结果这里第一次打印BBB…这个字符串调用printf的是父进程,后面打印调用printf的就是fork创建出来的子进程
那我们看到fork的两个返回值是不一样的,但是它们的地址&ret却是一样的。那这个问题呢我们现在还说不清楚,等到后面学进程地址空间的时候我们会再谈这个问题。

3.5 fork 之后通常要用 if 进行分流
fork 之后通常要用 if 进行分流,这样可以根据需要在父子进程中执行不同的操作。
所以我们一般要这样写:
通过ifelse语句让父子进程执行不同的操作

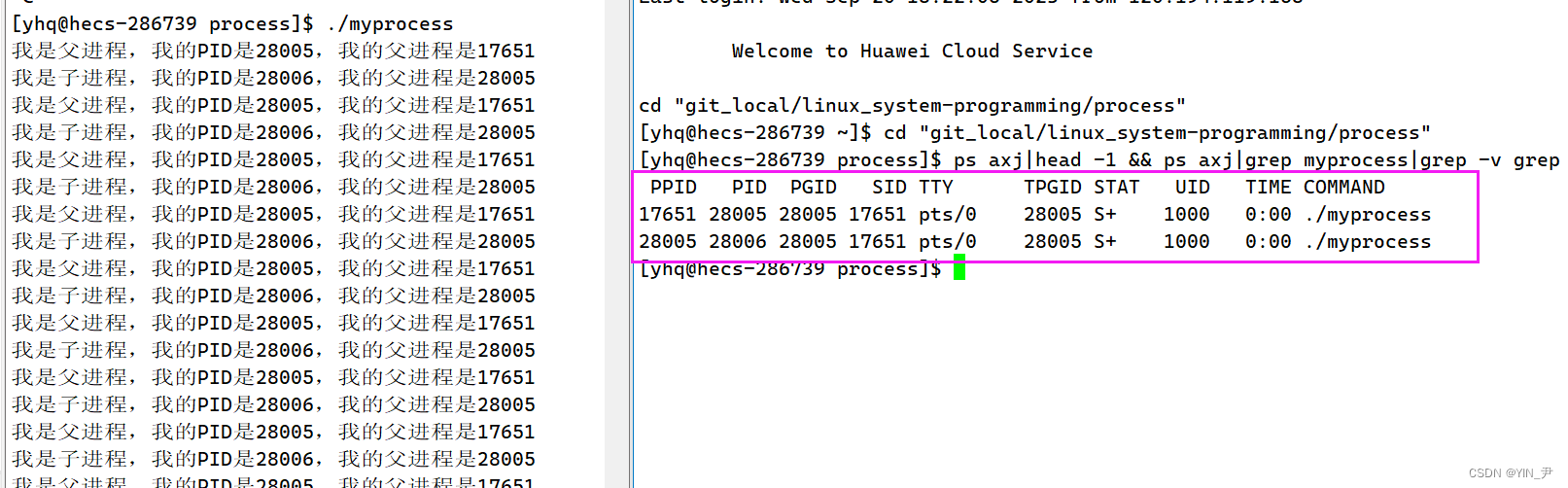
然后我们运行一下看看:
我们看到,父进程和子进程都是在执行的。
我们也能查看到当前是有两个myprocess进程的。
但是我们之前写的代码出现过if和elseif两个条件同时满足的吗?
并没有,但是这里if和elseif里面的语句都执行了,两个while循环同时在执行。
那为什么可以这样呢?
因为fork成功的话有两个返回值。
所以在多执行流的情况下if和elseif是可以同时执行的。

那简单总结一下上面的内容,可以得出一些结论:
fork成功之后,执行流会变成两个(父进程和子进程同时执行)
fork成功之后,父进程和子进程的执行顺序是不确定的,取决于操作系统的调度策略。
fork成功之后,父进程和子进程代码共享(我们上面fork之后父子进程都执行了第二个打印就可以证实这一点),通常我们要使用if语句进行代码块分流。
3.6 父子进程代码共享,数据写时拷贝(实现相互独立)
通过前面的学习,我们可以得出:
fork成功之后,父子进程是共享一份代码的。比如我们上面演示的fork之后父子进程都执行了同一句printf语句。
那我们再看这样的代码:
来运行一下


我们看到:
两个进程打印对应的x的值和x的地址都是一样的,所以我们可以暂且认为父子进程的数据也是共享的。
然后问大家一个问题:
就比如我们现在电脑上打开了这么多应用,那就对应了这么多的进程。
那如果现在我们把QQ退出了,会影响我的xshell吗。
这当然是不会的,凭我们平时的使用经验我们也知道。
所以呢:
程序的运行是具有独立性的!每个进程在执行时都相对独立,不会相互干扰或影响彼此的运行状态。
那同样的,对于父子进程也是这样,我们可以验证一下:
我们在再把这个程序跑起来
我们看到现在父子进程是都在运行的,然后我们把子进程杀掉
我们看到后面就只剩父进程在运行了,它们互相不会影响。

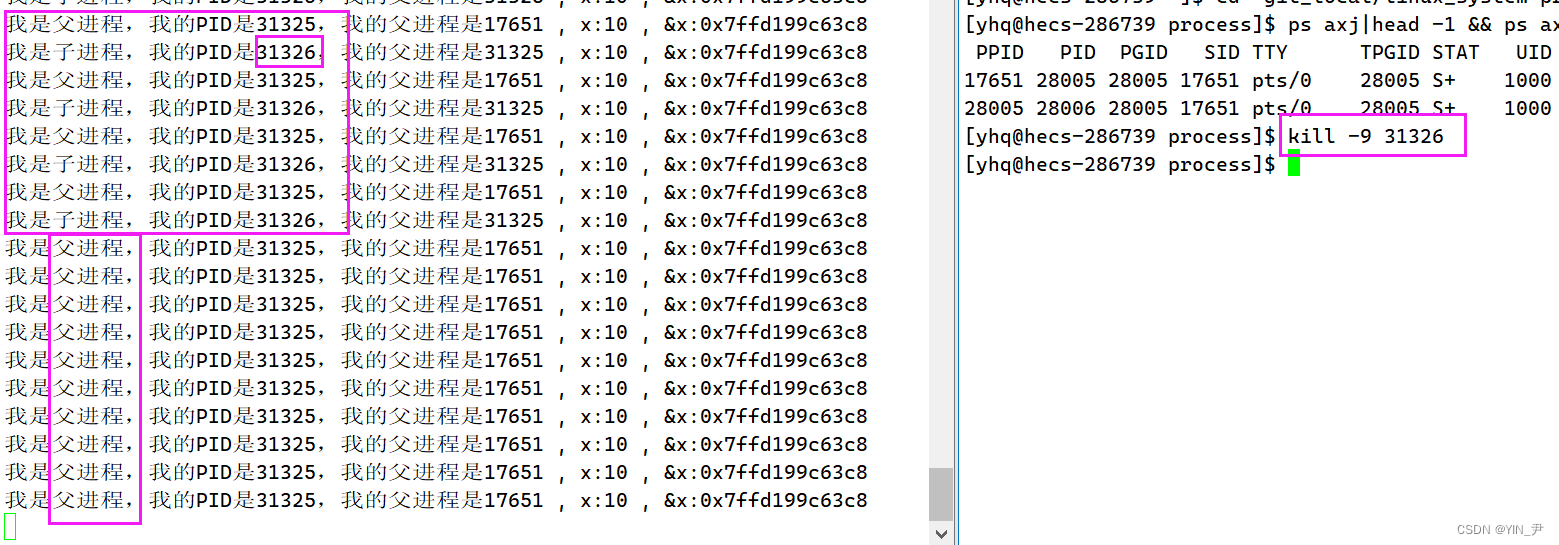
但是呢,有一个问题:
对于父子进程来说,按照我们上面的分析,父子进程共享一份代码和数据,那他是如何做到相互独立呢?
那首先对于代码来说,好像是没什么问题的。
虽然父子进程共享一份代码,但是可以实现独立啊,就算其中一个进程被干掉了,那代码还是在的啊(在程序运行时,代码段通常被视为只读的,以确保程序的完整性和安全性)。所以你不会影响我另一个进程的执行啊。
这没什么问题。
但是数据呢?
我一个进程在自己的执行流里执行代码的时候是可以修改代码里面的数据的(比如某个变量的值)
像这样
那我们运行一下看看
我们看到修改之后呢,它们打印的x的值确实是不一样了,但是我们看到两个x的地址依然是一样的。
那这里如何做到同一个变量地址相同但是值不同的,我们目前还不能解释,后面再说。


但是我们现在要说的是:
对于父子进程的数据,并不是真正的共享一份,而是写时拷贝
那写时拷贝的概念我们其实之前在C++里面string模拟实现那篇文章提到过。
其实就是只有在修改数据的时候才进行拷贝,然后修改你自己拷贝的数据,而不会影响原始数据。
那这样就做到了在数据层面上也可以实现进程间的独立性。
所以,可以理解为:
当子进程被创建时,起初操作系统只为其分配一个新的进程控制块(PCB),用于维护子进程的相关信息。
并不会立即复制父进程的整个地址空间,包括代码段和数据段。相反,父进程的地址空间会被标记为共享,并且只有在子进程或父进程试图修改共享数据时,才会进行写时拷贝。
这时,操作系统会将要修改的内存页复制到一个新的物理页中,然后对于的进程将修改后的数据写入这个新的页中,使得子进程和父进程的数据相互独立。
3.7 如何理解fork两个返回值的问题
首先大家来思考一个问题:一个函数将要return的时候,它完成的主体功能是否已经执行完了?
当然是的!
比如有一个求和的函数,那当它return的时候,这个和肯定已经求出来了,而return是要把这个结果返回给函数调用的地方。
那对于fork来说:
它是一个系统调用,那其实就是操作系统提供的一个函数嘛。
那在fork最后将要return的时候,那它的主体功能即创建子进程当然已经完成了。所以此时的执行流就已经变成两个了,上面我们也说了,fork成之后,父子进程是共享代码的。
那对于fork的return,他也是一句代码,一个语句啊。
所以这个return语句就会被子进程和子进程都执行,被执行了两次,而在我们看来就好像是fork返回了两个值。
那还有一个问题:
这里return执行了两次,所以返回了两个值,但是:
我们接收返回值只用了一个变量接收啊。
一个变量怎么同时接收两个值的?
很简单,ret第二次接收的时候,相当于要对数据进行修改。
那这时会发生什么?
🆗,上面说过了,这时就会发生写时拷贝。
所以呢?
虽然我们看到这两个x的地址是一样的,但是其实它们是两个不同的变量,占用不同的存储空间。
那为什么地址看到的是一样的呢?
那其实这里我们看到的地址并不是底层真实的物理地址,那关于这方面的问题我们后面也会讲到,大家现在先了解一下就行了。